В самом начале января coin и я бродили по холодным и дождливым улицам Лондона и говорили о технологиях, жизни и чём-то ещё. Я время от времени делал фотографии на свой старый Canon EOS 400D, и в какой-то момент мой друг сказал: “Вот ты фотографируешь, фотографируешь, а твои фотографии никто не лайкает”. Я не нашёл что ответить, но вернувшись домой, создал аккаунт в одной из соцсетей, где можно постить и лайкать фотографии, и составил план: за 100 дней набрать 10000 фолловеров и к концу этого срока получать 500 лайков за пост. После этого отобрал пару сотен интересных фотографий и запостил первую. И её лайкнуло только несколько человек. Этого было мало, нужно было придумать какой-то метод.

Чтобы увеличить число подписчиков, нужно чтобы тебя заметили. Это можно сделать разными способами, но самый простой и рабочий – это подписаться на кого-нибудь и полайкать его фотографии в надежде, что человек сделает то же самое в ответ. Бездумно это делать не охота по двум причинам: это очень похоже на спам, и на количество таких действий существует ограничение. Поэтому нужно было придумать, как фолловить только тех, кто с большой вероятностью подпишется в ответ.
Сначала я рандомно подписался на две-три тысячи человек, после этого я выписал в таблицу те три числа, которые есть в профиле пользователя: число постов Np, число подписок Nf и число подписчиков Nfd. В последний столбец M таблицы я занёс информацию о том, подписался ли пользователь на меня в ответ или нет.
Казалось правдоподобным следующее.
Эксперименты с визуализацией показали, что всё лучше выглядит в логарифмических координатах. Хотя облака точек сильно пересекаются, можно построить какой-нибудь классификатор и посмотреть, что получится.
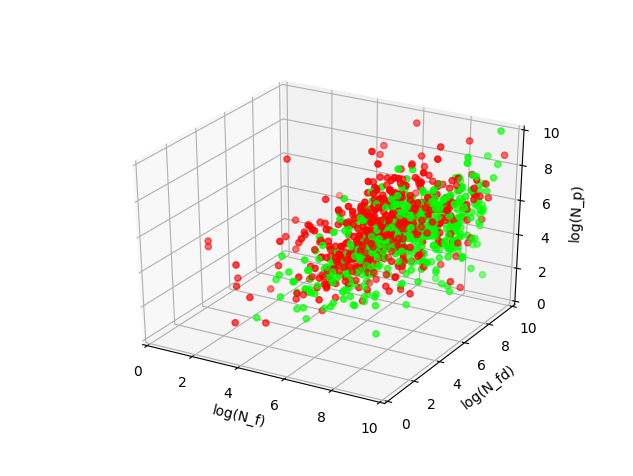
Воспользовавшись методом опорных векторов, я получил следующий линейный классификатор, который согласуется с тем, что ожидалось:
–0.19 log Nfd + 0.42 log Nf – 0.18 log Np > 0.57.
После этого дело пошло веселее: на процентов 20 больше подписывались на меня обратно, то есть примерно каждый четвёртый-пятый. Но это не тот результат, который я хотел. Нужно было придумать что-то лучшее.
На извлечение какой-то ещё информации, помимо названых трёх чисел, не хотелось тратить времени, поэтому я подумал, а что будет, если посмотреть снова на эти параметры, но через три дня.
Снова набрав данных, я стал играться с разными комбинациями этих величин. И оказалось, что очень хорошего результата можно достичь, добавляя всего один фактор — на сколько увеличилось число подписок у аккаунта. Оказывается, что чем больше человек зафолловил людей за три дня, тем больше шанс, что он зафолловит и меня.
Тут тоже всё лучше с логарифмами, поэтому новый фактор в итоге выглядит так: log+(N'f – Nf), где разность N'f – Nf — это изменение числа подписок за три дня,

Такая функция позволяет избежать проблем с логарифмированием отрицательных значений. Также люди, у которых число подписок уменьшается, нам скорее всего не интересны.

Метод опорных векторов даёт следующий линейный классификатор:
–0.06 log Nfd + 0.17 log Nf – 0.10 log Np + 0.16 log+(N'f – Nf) > 0.55.
Так как ошибка, когда мы не подпишемся на человека, который бы подписался на нас, нас особо не интересует, мы можем немного увеличить правую часть неравенства, чтобы ещё улучшить результат. В итоге, обратно подписывался на меня примерно каждый второй.
Ниже приведены ROC-кривые для двух полученных классификаторов.

Через 87 дней, заполучив 10000 подписчиков, я остановился. Среднее число лайков последних 15 постов оказалось равным 490, что почти равно числу, к которому я стремился. Учитывая, что я максимизировал число подписчиков, а не число лайков, то я считаю этот результат неплохим, тем более что он близок к среднему значению для подобного аккаунта.
Самым же интересным для меня в этом эксперименте оказался четвёртый фактор — изменение числа подписок за три дня. Он оказался очень простым и при этом неожиданно очень значимым.
Чтобы увеличить число подписчиков, нужно чтобы тебя заметили. Это можно сделать разными способами, но самый простой и рабочий – это подписаться на кого-нибудь и полайкать его фотографии в надежде, что человек сделает то же самое в ответ. Бездумно это делать не охота по двум причинам: это очень похоже на спам, и на количество таких действий существует ограничение. Поэтому нужно было придумать, как фолловить только тех, кто с большой вероятностью подпишется в ответ.
Сначала я рандомно подписался на две-три тысячи человек, после этого я выписал в таблицу те три числа, которые есть в профиле пользователя: число постов Np, число подписок Nf и число подписчиков Nfd. В последний столбец M таблицы я занёс информацию о том, подписался ли пользователь на меня в ответ или нет.
Казалось правдоподобным следующее.
- Чем больше у человека подписок, тем скорее пользователь и на меня подпишется.
- Чем больше отношение числа подписок на число постов, тем скорее пользователь на меня подпишется. (Так как чем больше постов, тем старее аккаунт. А если аккаунт создан давно, а подписок мало, то пользователь не заинтересован подписываться на других.)
- Чем больше отношение числа подписок на число подписчиков, тем скорее пользователь на меня подпишется. (Наблюдение показывает, что это число мало для магазинов, ботов, известных личностей и т. п. и близко к 1 для обычных людей.)
Эксперименты с визуализацией показали, что всё лучше выглядит в логарифмических координатах. Хотя облака точек сильно пересекаются, можно построить какой-нибудь классификатор и посмотреть, что получится.
Воспользовавшись методом опорных векторов, я получил следующий линейный классификатор, который согласуется с тем, что ожидалось:
–0.19 log Nfd + 0.42 log Nf – 0.18 log Np > 0.57.
После этого дело пошло веселее: на процентов 20 больше подписывались на меня обратно, то есть примерно каждый четвёртый-пятый. Но это не тот результат, который я хотел. Нужно было придумать что-то лучшее.
На извлечение какой-то ещё информации, помимо названых трёх чисел, не хотелось тратить времени, поэтому я подумал, а что будет, если посмотреть снова на эти параметры, но через три дня.
Снова набрав данных, я стал играться с разными комбинациями этих величин. И оказалось, что очень хорошего результата можно достичь, добавляя всего один фактор — на сколько увеличилось число подписок у аккаунта. Оказывается, что чем больше человек зафолловил людей за три дня, тем больше шанс, что он зафолловит и меня.
Тут тоже всё лучше с логарифмами, поэтому новый фактор в итоге выглядит так: log+(N'f – Nf), где разность N'f – Nf — это изменение числа подписок за три дня,
Такая функция позволяет избежать проблем с логарифмированием отрицательных значений. Также люди, у которых число подписок уменьшается, нам скорее всего не интересны.
Метод опорных векторов даёт следующий линейный классификатор:
–0.06 log Nfd + 0.17 log Nf – 0.10 log Np + 0.16 log+(N'f – Nf) > 0.55.
Так как ошибка, когда мы не подпишемся на человека, который бы подписался на нас, нас особо не интересует, мы можем немного увеличить правую часть неравенства, чтобы ещё улучшить результат. В итоге, обратно подписывался на меня примерно каждый второй.
Ниже приведены ROC-кривые для двух полученных классификаторов.
Через 87 дней, заполучив 10000 подписчиков, я остановился. Среднее число лайков последних 15 постов оказалось равным 490, что почти равно числу, к которому я стремился. Учитывая, что я максимизировал число подписчиков, а не число лайков, то я считаю этот результат неплохим, тем более что он близок к среднему значению для подобного аккаунта.
Самым же интересным для меня в этом эксперименте оказался четвёртый фактор — изменение числа подписок за три дня. Он оказался очень простым и при этом неожиданно очень значимым.

