
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Преимущество — в сочетании функциональности и скорости работы. Бесспорно, есть ряд существующих решений, однако они либо работают медленно — например эластик, либо плохо реализуют "fuzzy" поиск с опечатками и словоформами, либо не имею своего хранилища.
Если говорить, про bleve — я полгода назад его пробовал. Опыты закончились тем, что он вставлял 10к записей по 1кб примерно 5 минут, а попытка вставить 100к записей закончилась OOM на машине с 16GB ОЗУ. Возможно сейчас что-то изменилось.
На мой взгляд, эта проблема как раз уходит корнями в заметный оверхед golang на GC — для БД вообще, и для поиска в частности, требуется развесистая структура данных, состоящая из множества мелких элементов. Это как раз одна из причин, почему выбран C++ тут уже отвечал подробно, почему C++
В конфигурации с reindexer сервером в docker-е, установка C++ компилятора не требуется, т.к. в docker образе все необходимое для работы уже собрано.
А для сборки golang приложения с сетевым коннектором к реиндексеру — C++ тулчейн не требуется.
Если говорить про sphinx — у 2.x нет своего стораджа, и от application требуется много телодвижений для хранения данных отдельном хранилище и поддержания синхронизации. Это большая проблема, например, ребята из ivi в итоге пожертвовали производительностью и перешли со sphinx на elastic.
А 3.0 по моему до сих пор closed-source, да и на момент когда мы начинали делать свой — его вообще не было.
А так, да мы конечно не изобрели какую то инопланетную технологию, однако если сравнивать с эластик и co, у нас скорость поиска в 10 раз выше, при ± сравнимом качестве.
Это большая проблема, например, ребята из ivi в итоге пожертвовали производительностью и перешли со sphinx на elastic.
А так, да мы конечно не изобрели какую то инопланетную технологию, однако если сравнивать с эластик и co, у нас скорость поиска в 10 раз выше, при ± сравнимом качестве.
Можете пояснить фразу «примитивный алгоритм»
у нас скорость поиска в 10 раз выше, при ± сравнимом качестве
Описанное это очень базовый алгоритм, который был у нас в первой версии год назад, и действительно был написан чуть ли не за пару вечеров.
Но это не fuzzy поиск, а простой поиск по точным вхождениям + вхождения словоформ.
На шаге 3 битмапа не достаточно, требуется хранить не просто факт вхождения терм-ы в документ, а еще и список позиций вхождения (как минимум это требуется для bm25), и для вычисления релевантности по дистанции между словами.
на шаге 4 — k-v очень неэффективная структура для хранения индекса слов. Дело в том, что по ней дорого искать с опечатками/суффиксами/транслитами. Прийдется либо раздувать индекс до гигантских размеров на весь хабр получилось бы примерно ~ 100м записей с суффикасми/транслитами/опечатками/корнями, либо на каждом запросе сканировать огромные ренжи по k-v. И то и то очень затратно, и как следствие поиск будет работать очень медленно. И при построении индекса аллоцировать огромное количество мелких участков памяти.
У нас в этом месте используется suffix array.
Пункт 5 — это самый томный момент. По каждой term у нас есть N вариантов опечаток/словоформ (N может доходить до нескольких 10-ков) * M слов из индекса, в которых встречается каждый вариант (M может доходить до 100-тысяч, при поиске суффиксов из 2-3 букв) * K документов, в которых эти слова встречаются * T — количество терм в запросе.
И вот это все надо пересечь и вычислить релевантность каждого сочетания.
С bm25 кстати, тоже не все так просто — оригинальная bm25 не учитывает, что у документа может быть несколько полей, по каждому из которых нужно вести отдельный учет статистики, и что финальные результаты формулы нужно нормализовать с учетом весов полей.
Ничего гениального в этом конечно нет. Но реализация требует далеко не один человеко-месяц, на разработку минимально алоцирующих/быстрых контейнеров, на тщательную оптимизацию и отладку работы формул — и тд. и тп.
Тут как говорится, весь дьявол — в деталях.
Кстати, про 10x от сфинса лично я никогда не утверждал, более того в предыдущей статье есть конкретные цифры:
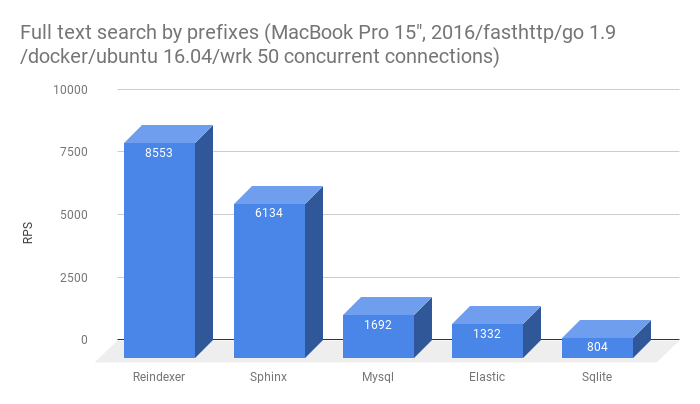
Как видите, Reindexer не принципиально быстрее Sphinx, но существенно быстрее всех остальных.
Если говорить про sphinx — у него проблема в отсутствии своего storage, т.е.
Т.е. sphinx 2.x не умеет хранить и отдавать документы целиком, а грубо говоря, может отдавать только ID документов. Поэтому, рядом со sphinx нужно держать какой нибуть K-V, и постоянно синхронизировать данные, что зачастую очень накладно.
но существенно быстрее всех остальных
Т.е. sphinx 2.x не умеет хранить и отдавать документы целиком, а грубо говоря, может отдавать только ID документов.
Репликация и кластеризация у нас в есть в ближайших планах. Правда пока с большим упором на репликацию, недели чем на кластеризацию.
Кластер хорош, когда объем данным заведомо больше, чем поместится в RAM одного сервера — например это актуально для поиска по террабайтам. В этой нише, действительно эластик хорош, а у reindexer в текущем виде для этой задачи не подойдет.
Однако, если говорить про задачу поиска по контенту сайта (или например, сервиса с VoD/TV контентом), то пока индекс целиком влезает в RAM одного сервера — это самая быстрая и эффективная конфигурация по критерию — количество обслуживаемых системой пользователей/количество используемых серверов.
Sphinx не хранит всю строчку с сущностью, а только те поля на которые накинуты полнотекстовые индексы. Это не равно всему документу....
Да, весь индекс впихнуть в память. Противоречия, на самом деле нет — есть разные пути решения задачи.
в соседнем комментарии написал детали
Преимущество — в сочетании функциональности и скорости работы. Бесспорно, есть ряд существующих решений, однако они либо работают медленно — например эластик, либо плохо реализуют «fuzzy» поиск с опечатками и словоформами, либо не имею своего хранилища.
однако они либо работают медленно — например эластик
Если говорить, про bleve — я полгода назад его пробовал. Опыты закончились тем, что он вставлял 10к записей по 1кб примерно 5 минут, а попытка вставить 100к записей закончилась OOM на машине с 16GB ОЗУ. Возможно сейчас что-то изменилось.
По моим тестам в bleve не влезет и 10% habrhabra — закончится RAM.
Поэтому преимущество Reindexer на этой задаче такое — он работает, а bleve нет.
По моим тестам в bleve не влезет и 10% habrhabra — закончится RAM.
С bleve последний раз пробовал что то делать ~полгода назад. на основании примера из этой статьи https://habrahabr.ru/post/333714/ и оригинальной документации.
По воспоминаниям, пробовал разные бэкенды. Но сама суть такова: на объеме данных 100к x 1к через 10-20 минут индексации получал OOM на машине с 16GB.
По позиционировании очень просто — Reindexer очень быстрая in-memory DB общего назначения с богатыми возможностями поиска и фильтрации.
Сравнительные характеристики по скорости работы были в предыдущей статье — их можно посмотреть и сделать выводы. (bleve туда не попал, потому что не смог переварить тестовый датасет)
Оценить качество и скорость поиска можно в демке из этой статьи.
Поэтому преимущество Reindexer на этой задаче такое — он работает, а bleve нет.
однако если сравнивать с эластик и co, у нас скорость поиска в 10 раз выше, при ± сравнимом качестве.
Вы так сконцентрировались на опечатках, что нет способа искать по точному слову.
Написал "scala" functional получил scalar, escalation
Скорость впечатляет.
Перестарались :)
За замечание — спасибо, попробуем подтюнить — ведь это параметр настройки. Коэффициенты релевантности вхождения по опечаткам/словоформам/транслиту можно аккуратно крутить в обе стороны.
Внимательно посмотрел на результаты запроса "scala" functional. На первых 3-ех страницах ответы только про Scala, дальше начинают попадаться результаты со scalar и прочими опечатками.
На мой вкус — это ожидаемое поведение поиска: в начале выдачи разместить точные совпадения, а потом шлейф разультатов с разнообразными словоформами.
Я вот еще обратил внимание по логам сервера, что был запрос по слову scala с сортировкой по времени поста. Могу предположить, что речь идет именно про этот запрос. При сортировке по времени релевантность не учитывается, и на первых местах могут быть слабо-релевантные ответы.
Есть несколько способов избежать этого эффекта. Можно, например, увеличить порог релевантности, тем самым убрав слабо-релевантные ответы.
Можно явно задать поиск по точному совпадению, вообще исключив из выдачи все опечатки/суффиксы — это делается просто, на уровне преобразования поискового запроса в DSL
Спасибо за отзвыв!
Индексирование произвольного сайта в интернете, с произвольной структурой страниц — это задача поискового робота — в этом случае, робот не вникает в сущности которые есть на сайте, а оперирует набором страниц и текстов — нормализуя любой контент в вид удобный для индексации, это весьма сложная задача, которую решают Яндекс и Гугл. А делать аналог Яндекс-а или Гугла — не входит в наши планы :)
Другой подход — скраппинг сайта — когда предварительно анализируются модели данных использующиеся сайтом, и индексация сайта сводится к типизированному парсингу страниц сайта. В результате мы получаем набор структурированных данных, близкий к внутреннему формату БД сайта.
В данном случае мы пошли этим путем. Он дает лучшие результаты — т.к. исходные данные структурированы. Однако этот подход не универсальный и требует немного реверс инженеринга и реализации парсера/логики обхода страниц для каждого конкретного сайта.
В этом как раз многие не уверены. Есть запросы с нулевой выдачей:)
Простите, не удержался,
Но на вашем уровне оценки сложности алгоритмов, у яндекса и гугла тоже все просто:
"запрос — учитываем искаженные словоформы — пропускаем через нейронку — мап-редьюус ответ"
реализовать студент вполне себе должен смочь.
но полезной информации для себя я не смог подчерпнуть, к сожалению.
Все это делает для меня этот продукт интересным для его дальнейшего использования.
То есть, по вашему, наличие нейронной сети в полнотексте сразу сделает алгоритм сложным?
Если бы в Reindexer'е было реализовано нечто подобное, то вы бы все равно поравли статью на цитаты ровно так же
Исчерпывающая документация, привлекательные бенчмарки, понятный исходный код и экзамплы
Вы явно недооцениваете студентов!
То есть, по вашему, наличие нейронной сети в полнотексте сразу сделает алгоритм сложным?
Будь здесь алгоритм сложнее, использующий нейронные сети, то мы бы точно так же читали подобные скептические сообщения от вас.
Со Sphinx Reindexer сравнивать влоб не совсем корректно. Reindexer это полноценная БД, позволяющая работать с данными, например вставлять/удалять/делать сложные выборки с JOIN, а Sphinx это движок полнотекстового поиска.
Полнотекстовый поиск это одна из фич Reindexer, а не основное предназначение.
На берегу, когда мы проектировали систему, а задачи у нас ± такие же как у ivi, только данных побольше (есть TV контент и поддержка IPTV приставок со своей горой специфики усложняющей логику), мы не планировали тащить в Reindexer полнотекстовый поиск, а думали как и ivi использовать тот же sphinx сбоку.
Однако анализ показал, что это решение будет крайне накладным. Основные причины, такие же как у ivi:
На задаче, когда количество контента небольшое (а фильмы+сериалы+TV каналы+TV программа + все их метаданные — это всего лишь несколько сотен тысяч-несколько миллионов строчек БД) — размазывание индексов по кластеру — лишний оверхед. Весь контент со всеми индексами гарантированно влезут в RAM одного сервера с огромным запасом.
Тут нет никакого бонуса от кластеризации и распределения индексов по нодам.
В итоге конфигурация ~10 серверов Reindexer даст такую же производительность, как кластер эластик со ~100 серверами.
PS. Да, сейчас у нас репликация данных между Reindexer нодами реализована на уровне приложения, и это увы на практике работает не очень хорошо. Поэтому мы и планируем перенести репликацию данных в сам Reindexer.
Поиск по сайту с Reindexer — это просто. Или как сделать «instant search» по всему Хабрахабр-у