История превью страниц.

Когда вы наводите курсор на ссылку, появляются карточки предварительного просмотра (и да, у меня на десктопе мобильный скин Википедии). Текст из статей Википедии об айсбергах и воде, CC BY-SA 3.0. Изображения слева направо, сверху вниз: #1 Ким Хансен, CC BY-SA 3.0; #2 Андреас Вайт, CC BY-SA 4.0; #3 Национальная библиотека Новой Зеландии, CC0
Несколько дней назад моя команда запустила функцию «предварительного просмотра страниц» (превью) в сотнях языковых версий Википедии. Наш API ежеминутно обрабатывает до полумиллиона вызовов для выдачи карточек превью, которые отображаются при наведении курсора на любую ссылку.
На первый взгляд всё очень просто. Такое есть на многих сайтах. На карточке размещается изображение и немного текста — и она отображается при наведении курсора на ссылку. Ничего инновационного… по крайней мере, так может показаться на первый взгляд.
Оригинальная идея этой функции появилась четыре года назад на основе идеи, которую один доброволец/редактор предложил за много лет до этого.
Таким образом, нам потребовалось несколько лет, чтобы выкатить фичу до всех. Это может показаться странным, но как и в айсберге, следует оценить подводную часть.
У нас несколько миллионов страниц — все хранятся в виде необработанного вики-текста. Нельзя было ожидать, что каждую статью отредактируют для выбранной миниатюры.
Ещё в 2012 году Макс Семеник, инженер-программист нашей группы Community Tech, разработал расширение, которое алгоритмически выдаёт наиболее подходящее изображение для статьи.
Как и во всех алгоритмах, он работал не идеально. И поскольку изначально не был предназначен для использования в превью, потребовал специальной настройки.
Пришлось произвести некоторые изменения, чтобы ограничить изображение первым разделом статьи. Работать с алгоритмами сложно, но в данном случае необходимо.
У нас несколько миллионов страниц в вики-тексте. Как сгенерировать резюме для каждой из них, не нагружая этой кропотливой работой наших редакторов?
Макс Семеник, который помог нам с миниатюрами, также является автором расширения для генерации выдержек из статей. Первоначально оно работало преимущественно с текстовым форматом. Мы использовали его в первых версиях превью, но вскоре поняли, что это не лучший вариант.
Тогда мы прекратили им пользоваться.
Мы поняли важность HTML. Например, в статьях по химии встречаются подстрочные знаки, что требует поддержки HTML.

HTML необходим для создания резюме контента, в котором важно наличие подстрочных символов. Текст из англоязычной статьи Википедии о воде, CC BY-SA 3.0; изображение Ким Хансена, CC BY-SA 3.0
Многие из наших статей начинаются с координат и информации о произношении слова. Значительная часть такого контента не входила в резюме, а для остального было не совсем ясно: что сюда включать, а что нет. После изучения множества вариантов дизайна мы определили, какой именно контент не должен отображаться в превью. Затем составили спецификацию, которая закрепляет требуемое поведение.

Координаты места указаны в начале многих статей, но их оказалось проблематично включить в резюме…

…как и информацию о произношении
В конце концов, мы решили работать поверх API, изначально разработанного для нативных приложений Википедии под Android и iOS. Специально для этого мы создали новый API.
Теперь резюме генерируется на основе целой HTML-страницы. Она разбирается как в браузере и согласно спецификации определяется первый «не пустой» параграф каждой статьи.
Одной из главных проблем стало избавиться от текста в скобках. Поскольку мы поддерживаем более 300 языков, то пришлось создавать локализованные решения (не все используют один и тот же набор символов!).
Конечно, некоторые скобки крайне важны… повсюду пограничные случаи. Пришлось продумать все варианты потенциального использования скобок и как лучше всего с ними поступить.
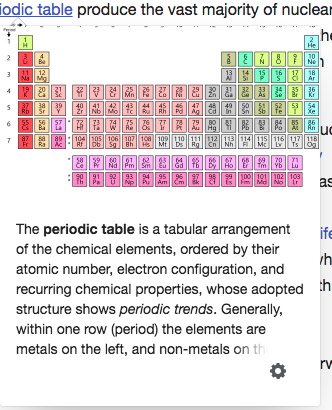
Иногда контент в скобках очень важен, как показывает этот пример. Трудно определить, когда именно он важен. Текст из англоязычной статьи Википедии о периодической таблице элементов, CC BY-SA 3.0; изображение Offnfopt, общественное достояние.
Очистка от скобок пользовательских HTML также оказалась довольно сложной. В текстовом формате нужно лишь простое регулярное выражение, но совсем другое дело разбирать вложенные уровни HTML.
Важно было убедиться, что после удаления контента в скобках содержание по-прежнему имеет смысл — и что мы не добавили никаких уязвимостей безопасности.
Спасибо нашей инфруструктурной группе за помощь в создании этого API.
Для сообщества очень важен результат. Вот почему они пишут для вас статьи в своё свободное время без денежного вознаграждения.
Мы пользовались их помощью на каждом этапе и неустанно работали с ними, разбирая каждый пограничный случай (будь то некорректные резюме или неподходящие изображения). Мы старались убедить их, что работа идёт правильным курсом, объясняли, зачем и почему продолжаем это делать.
Наша первоначальная версия оказалась недостаточно хороша. Сообщество попросило не выпускать её. Мы выслушали мнения и постарались улучшить превью.
Спасибо сообществу и тем пользователям, которые помогли наладить эту коммуникацию!
На него потратили немало времени. Наш дизайнер Нирзар написал отличную статью, так что я не буду здесь слишком углубляться в эту тему. Но работа над дизайном продолжалась на каждом этапе, будь то первоначальные прототипы (спасибо, Пратек Саксена!), обсуждение фич с группой по производительности, совершенствование эскизов и резюме или обсуждение с сообществом.
Спасибо вам, дизайн-команда!
Превью по ссылкам — значительное изменение в том, как люди взаимодействуют с контентом. Мы в Викимедиа очень заботимся о конфиденциальности. Вероятно, мы один из немногих крупных сайтов (единственный?!), который не устанавливает сторонние скрипты для отслеживания пользователей.
Наша политика конфиденциальности запрещает выдавать данные о посетителях.
Мы не приглашаем сторонние компании для проведения A/B-тестов или анализа поведения пользователей.
Несмотря на всё это, мы не срезаем углы и не хотим делать глупые рискованные изменения.
Каждый раз, когда мы разрабатываем что-то важное, то приходится создавать строить инфраструктуру для проведения измерений. Мы строим гипотезы и тесты для поверки этих гипотез. Разрабатываем. Тестируем. Изучаем данные. Адаптируем продукт. Снова тестируем.
Это означает, что мы совмещаем в себе обязанности групп разработки и аналитики. Наша команда разработчиков работает в нескольких ипостасях. Учитывая масштаб, встречаются баги. Иногда мы находим крупные баги в браузерах.
Последний A/B-тест Тилмана Байера ответил на многие вопросы. Это занимательное чтиво!
Учитывая результаты этого A/B-теста, мы решили добавить дополнительную метрику для просмотров страниц — просмотры через превью. Эта метрика генерирует 1000 событий в секунду, и наш отдел аналитики трудится в поте лица, пытаясь совладать с таким масштабом.
Спасибо аналитикам, спасибо аналитическому отделу!
Наш API обрабатывает 0,5 миллиона обращений в минуту.
Наш API обрабатывает 0,5 миллиона обращений в минуту.
Я написал дважды, потому что это реально большой трафик.
Наши традиционные API изначально создавались для ботов, которые подчищают ваши правки. Они не предназначались для читателей.
Сервисная группа Викимедиа оказалась жизненно важна для успеха этого проекта. Она предоставила инфраструктуру, обеспечила большой объём кэширования (мы в значительной степени полагаемся на Varnish) и обеспечила гарантии, что при редактировании контента генерируются новые резюме. Хорошо известно, что инвалидация кэша — одной из самых сложных проблем в информатике.
Спасибо, сервисная команда!
Любое законченное дело даёт чувство удовлетворения. Надеюсь, что вам понравятся эти «простые» превьюшки, разработанные моей командой при помощи многих других команд со всего Фонда Викимедиа.
В это дело были вовлечены многие — и мы гордимся результатом.
Мы ещё не закончили. Программное обеспечение никогда не бывает законченным.
Нужно ещё почистить кое-какой код и проверить новые идеи, что может вырасти из этой маленькой фичи.
Кто-то может сказать, что сейчас перед нами только верхушка айсберга.
Автор оригинала: Jon Robson; этот перевод распространяется на условиях лицензии CC BY 3.0
Когда вы наводите курсор на ссылку, появляются карточки предварительного просмотра (и да, у меня на десктопе мобильный скин Википедии). Текст из статей Википедии об айсбергах и воде, CC BY-SA 3.0. Изображения слева направо, сверху вниз: #1 Ким Хансен, CC BY-SA 3.0; #2 Андреас Вайт, CC BY-SA 4.0; #3 Национальная библиотека Новой Зеландии, CC0
Несколько дней назад моя команда запустила функцию «предварительного просмотра страниц» (превью) в сотнях языковых версий Википедии. Наш API ежеминутно обрабатывает до полумиллиона вызовов для выдачи карточек превью, которые отображаются при наведении курсора на любую ссылку.
На первый взгляд всё очень просто. Такое есть на многих сайтах. На карточке размещается изображение и немного текста — и она отображается при наведении курсора на ссылку. Ничего инновационного… по крайней мере, так может показаться на первый взгляд.
Оригинальная идея этой функции появилась четыре года назад на основе идеи, которую один доброволец/редактор предложил за много лет до этого.
Таким образом, нам потребовалось несколько лет, чтобы выкатить фичу до всех. Это может показаться странным, но как и в айсберге, следует оценить подводную часть.
Нужно было выбрать миниатюру
У нас несколько миллионов страниц — все хранятся в виде необработанного вики-текста. Нельзя было ожидать, что каждую статью отредактируют для выбранной миниатюры.
Ещё в 2012 году Макс Семеник, инженер-программист нашей группы Community Tech, разработал расширение, которое алгоритмически выдаёт наиболее подходящее изображение для статьи.
Как и во всех алгоритмах, он работал не идеально. И поскольку изначально не был предназначен для использования в превью, потребовал специальной настройки.
Пришлось произвести некоторые изменения, чтобы ограничить изображение первым разделом статьи. Работать с алгоритмами сложно, но в данном случае необходимо.
Нужно было сгенерировать резюме
У нас несколько миллионов страниц в вики-тексте. Как сгенерировать резюме для каждой из них, не нагружая этой кропотливой работой наших редакторов?
Макс Семеник, который помог нам с миниатюрами, также является автором расширения для генерации выдержек из статей. Первоначально оно работало преимущественно с текстовым форматом. Мы использовали его в первых версиях превью, но вскоре поняли, что это не лучший вариант.
Тогда мы прекратили им пользоваться.
Мы поняли важность HTML. Например, в статьях по химии встречаются подстрочные знаки, что требует поддержки HTML.
HTML необходим для создания резюме контента, в котором важно наличие подстрочных символов. Текст из англоязычной статьи Википедии о воде, CC BY-SA 3.0; изображение Ким Хансена, CC BY-SA 3.0
Многие из наших статей начинаются с координат и информации о произношении слова. Значительная часть такого контента не входила в резюме, а для остального было не совсем ясно: что сюда включать, а что нет. После изучения множества вариантов дизайна мы определили, какой именно контент не должен отображаться в превью. Затем составили спецификацию, которая закрепляет требуемое поведение.
Координаты места указаны в начале многих статей, но их оказалось проблематично включить в резюме…
…как и информацию о произношении
В конце концов, мы решили работать поверх API, изначально разработанного для нативных приложений Википедии под Android и iOS. Специально для этого мы создали новый API.
Теперь резюме генерируется на основе целой HTML-страницы. Она разбирается как в браузере и согласно спецификации определяется первый «не пустой» параграф каждой статьи.
Одной из главных проблем стало избавиться от текста в скобках. Поскольку мы поддерживаем более 300 языков, то пришлось создавать локализованные решения (не все используют один и тот же набор символов!).
Конечно, некоторые скобки крайне важны… повсюду пограничные случаи. Пришлось продумать все варианты потенциального использования скобок и как лучше всего с ними поступить.
Иногда контент в скобках очень важен, как показывает этот пример. Трудно определить, когда именно он важен. Текст из англоязычной статьи Википедии о периодической таблице элементов, CC BY-SA 3.0; изображение Offnfopt, общественное достояние.
Очистка от скобок пользовательских HTML также оказалась довольно сложной. В текстовом формате нужно лишь простое регулярное выражение, но совсем другое дело разбирать вложенные уровни HTML.
Важно было убедиться, что после удаления контента в скобках содержание по-прежнему имеет смысл — и что мы не добавили никаких уязвимостей безопасности.
Спасибо нашей инфруструктурной группе за помощь в создании этого API.
Мы работаем с сообществом
Для сообщества очень важен результат. Вот почему они пишут для вас статьи в своё свободное время без денежного вознаграждения.
Мы пользовались их помощью на каждом этапе и неустанно работали с ними, разбирая каждый пограничный случай (будь то некорректные резюме или неподходящие изображения). Мы старались убедить их, что работа идёт правильным курсом, объясняли, зачем и почему продолжаем это делать.
Наша первоначальная версия оказалась недостаточно хороша. Сообщество попросило не выпускать её. Мы выслушали мнения и постарались улучшить превью.
Спасибо сообществу и тем пользователям, которые помогли наладить эту коммуникацию!
Дизайн, дизайн, дизайн
На него потратили немало времени. Наш дизайнер Нирзар написал отличную статью, так что я не буду здесь слишком углубляться в эту тему. Но работа над дизайном продолжалась на каждом этапе, будь то первоначальные прототипы (спасибо, Пратек Саксена!), обсуждение фич с группой по производительности, совершенствование эскизов и резюме или обсуждение с сообществом.
Спасибо вам, дизайн-команда!
Надо было провести измерения
Превью по ссылкам — значительное изменение в том, как люди взаимодействуют с контентом. Мы в Викимедиа очень заботимся о конфиденциальности. Вероятно, мы один из немногих крупных сайтов (единственный?!), который не устанавливает сторонние скрипты для отслеживания пользователей.
Наша политика конфиденциальности запрещает выдавать данные о посетителях.
Мы не приглашаем сторонние компании для проведения A/B-тестов или анализа поведения пользователей.
Несмотря на всё это, мы не срезаем углы и не хотим делать глупые рискованные изменения.
Каждый раз, когда мы разрабатываем что-то важное, то приходится создавать строить инфраструктуру для проведения измерений. Мы строим гипотезы и тесты для поверки этих гипотез. Разрабатываем. Тестируем. Изучаем данные. Адаптируем продукт. Снова тестируем.
Это означает, что мы совмещаем в себе обязанности групп разработки и аналитики. Наша команда разработчиков работает в нескольких ипостасях. Учитывая масштаб, встречаются баги. Иногда мы находим крупные баги в браузерах.
Последний A/B-тест Тилмана Байера ответил на многие вопросы. Это занимательное чтиво!
Учитывая результаты этого A/B-теста, мы решили добавить дополнительную метрику для просмотров страниц — просмотры через превью. Эта метрика генерирует 1000 событий в секунду, и наш отдел аналитики трудится в поте лица, пытаясь совладать с таким масштабом.
Спасибо аналитикам, спасибо аналитическому отделу!
Надо был масштабировать API, чтобы поддержать вас
Наш API обрабатывает 0,5 миллиона обращений в минуту.
Наш API обрабатывает 0,5 миллиона обращений в минуту.
Я написал дважды, потому что это реально большой трафик.
Наши традиционные API изначально создавались для ботов, которые подчищают ваши правки. Они не предназначались для читателей.
Сервисная группа Викимедиа оказалась жизненно важна для успеха этого проекта. Она предоставила инфраструктуру, обеспечила большой объём кэширования (мы в значительной степени полагаемся на Varnish) и обеспечила гарантии, что при редактировании контента генерируются новые резюме. Хорошо известно, что инвалидация кэша — одной из самых сложных проблем в информатике.
Спасибо, сервисная команда!
Спасибо, спасибо, спасибо
Любое законченное дело даёт чувство удовлетворения. Надеюсь, что вам понравятся эти «простые» превьюшки, разработанные моей командой при помощи многих других команд со всего Фонда Викимедиа.
В это дело были вовлечены многие — и мы гордимся результатом.
Мы ещё не закончили. Программное обеспечение никогда не бывает законченным.
Нужно ещё почистить кое-какой код и проверить новые идеи, что может вырасти из этой маленькой фичи.
Кто-то может сказать, что сейчас перед нами только верхушка айсберга.
Автор оригинала: Jon Robson; этот перевод распространяется на условиях лицензии CC BY 3.0


{kind=link}
{kind=link}