
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
ALTER ROLE some_user SET session_preload_libraries TO 'auto_explain';
ALTER ROLE some_user SET "auto_explain.log_min_duration" TO '100ms';диск 100%
при этом их запрос убивается количеством FilteredАга, и ещё гигантские выборки могут отлично страдать от Recheck Cond
min/max filtered. И эта чиселка в общем случае будет алертом для админа/разработчика
[типовой в общем-то] случай когда все запросы оптимизированы и один-два запросов пошли вдруг к базе без индексов
Ну а в целом любой проект имеет конечное число уникальных запросов к БД, количество которых сводится всего к нескольким десяткам, ну максимум к сотням
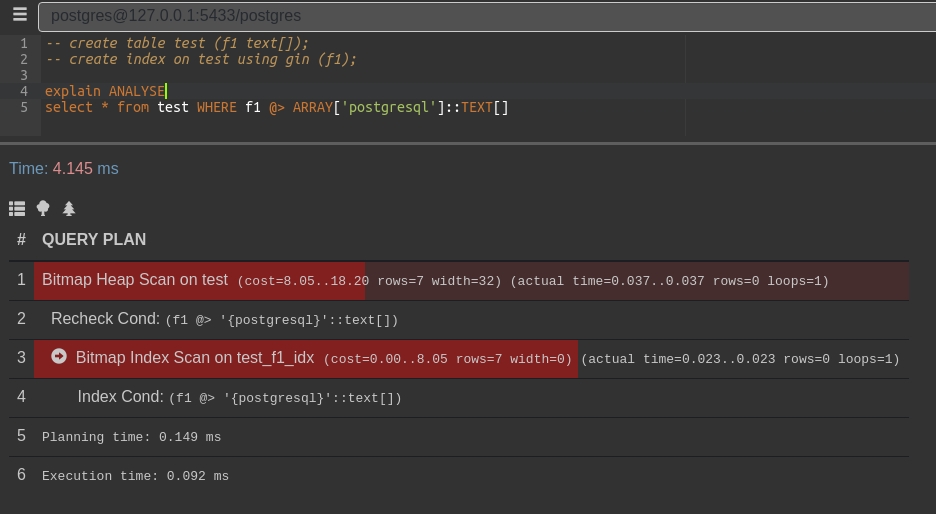
Особенность метода доступа gin состоит в том, что результат всегда возвращается в виде битовой карты: выдавать TID-ы по одному этот метод не умеет. Именно поэтому все планы запросов, которые встречаются в этой части, используют сканирование по битовой карте (bitmap scan)
create table test (f1 text[]);
create index on test using gin (f1);
insert into test VALUES(ARRAY['postgresql']);
insert into test VALUES(ARRAY['postgresql2', 'mysql']);
insert into test VALUES(ARRAY['postgresql2', 'mysql', 'mssql']);
explain ANALYSE
select * from test WHERE f1 @> ARRAY['postgresql']::TEXT[];
{kind=link}
{kind=link}
Postgres auto_explain: автолог плана запроса