Всем привет!
Недавно возникла задача — ускорить загрузку FPGA. От появления питания до рабочего состояния у нас есть не более 100 мс. Поскольку чип не самый новый (Altera Cyclone IV GX), просто подключить к нему быструю флешку типа EPCQ не получается. И мы решили задействовать режим FPP (Fast Passive Parallel), поставив снаружи CPLD Intel MAXV с FPL (Flash Parallel Loader). При старте CPLD загружает данные из флешки и формирует сигналы FPP на своих выходах.
Однако, перед тем, как совершить задуманное, собрали DIY-макет из того, что было под рукой, и взялись поэкспериментировать "на кошках". К сожалению, из-за соплей на плате пришлось снизить рабочие частоты, но суть работы FPP от этого не изменилась, зато отладка упростилась. О том, что получилось, и о том, как конфигурируется FPGA, я и решил написать в этой статье. Кому интересно, добро пожаловать под кат.

О чём я планирую рассказать:
- кратко о конфигурировании FPGA. Типовая временная диаграмма, какие бывают режимы
- из каких этапов состоит время загрузки FPGA
- что из себя представляет FPP
- про FPL, какова его роль
- про EPCQ и поддержку в FPL
- про результаты экспериментов, с картинками
Как конфигурируется FPGA?
Есть два типа загрузки FPGA — активный и пассивный. Активный подразумевает, что FPGA тактирует внешний flash и считывает оттуда прошивку. Пассивный — что есть некий хост (процессор, ПЛИС, контроллер), который загружает в FPGA прошивку.
Активный всем хорошо знаком, наверное: подключаем флешку EPCS/EPCQ, заливаем туда по JTAG прошивку и радуемся жизни, поскольку всю остальную работу по считыванию данных за нас сделает FPGA при включении питания.
Пассивный чуточку муторнее, поскольку требует реализации дополнительной логики: процессор должен откуда-то грузить прошивку, кто-то в него эту прошивку должен "положить", и т.д. Но пассивный режим зачастую быстрее. Например, в Cyclone IV в режиме Active Serial поддерживается DCLK 40 МГц и 1 бит данных, а в режиме FPP (Fast Passive Parallel) — 100 МГц и 8 бит данных, что в 20 раз быстрее.
Главные сигналы, которые отвечают за конфигурирование FPGA — это nCONFIG, nSTATUS, CONF_DONE:
- Вход nCONFIG позволяет сбросить FPGA (перепад из 1 в 0) и инициировать загрузку прошивки (перепад из 0 в 1)
- Выход nSTATUS позволяет узнать, готова ли FPGA принимать данные (уровень 1) и не произошло ли какой-то ошибки в ходе конфигурации или работы FPGA (перепад в ноль)
- Выход CONF_DONE позволяет понять, что FPGA сконфигурирована. Если быть точным — что FPGA получила все конфигурационные данные
Временная диаграмма в этих режимах не сильно отличается. Вот типовая для нашего случая — passive parallel:

В ней происходит следующее:
- внешний хост сбрасывает FPGA (nCONFIG: 1 -> 0)
- FPGA подтверждает, что готова, сначала установив nSTATUS в ноль, а затем отпустив его в 1. Также сигнал CONF_DONE сбрасывается в 0
- внешний хост инициирует конфигурирование FPGA (nCONFIG: 0 -> 1)
- внешний хост записывает данные (прошивку) до тех пор, пока не появится сигнал CONF_DONE (после CONF_DONE ещё нужно пару dummy-тактов)
Подробнее про конфигурирование см. здесь
Выбор режима конфигурирования производится специальными ножками FPGA — MSEL. В разных семействах количество режимов отличается. Например, в Cyclone V выбирается режим компресии и режим шифрования прошивки помимо Active/Passive. А в Cyclone IV — только Active/Passive и POR Fast/Standard

Как работает FPP
FPP (Fast Passive Serial) — это пассивный режим, в котором конфигурация загружается в FPGA словами (1 байт и больше) и синхронно, по тактам сигнала DCLK.
"Лёгкая версия" этого режима — это Passive Serial, где прошивка загружается побитово.
Для этого режима используются Dedicated pins, часть которых (старшие биты данных) впоследствии становится обычными I/O:
- DCLK
- DATA[7:0]
В чипах старших семейств (Stratix V, например) можно загружать прошивку по 2 (FPPx16) и по 4 (FPPx32) байта за такт.
Время загрузки FPGA
Давайте посчитаем время загрузки FPGA в пассивном режиме. Началом будем считать появление на чипе напряжения (когда оно достигает определённого значения), а концом — появление сигнала CONF_DONE.
Укрупнённо время складывается из следующих этапов:
- tPOR: power on reset. В режиме Fast занимает несколько миллисекунд, а в режиме Standard сотни миллисекунд (!). Однако, Fast предъявляет более жёсткие требования к системе питания, поскольку на старт тратится больше энергии
- Configuration Handshake: хост дожидается nSTATUS=1, сбрасывает FPGA (nCONFIG:1->0), инициирует (nCONFIG:0->1). Этот этап занимает доли миллисекунды и им можно смело пренебречь
- tCFG: отправка данных в FPGA и мониторинг CONF_DONE. Эта часть занимает основное время, которое пропорционально размеру прошивки и обратно-пропорционально частоте DCLK, на которой происходит запись данных
- tINIT: инициализация чипа загруженными в него данными. После завершения этого этапа ПЛИС полностью готова к работе (находится в USER MODE). Занимает меньше миллисекунды, поэтому тоже пренебрегаем
tPOR зависит исключительно от настроек MSEL. Естественно, там где время загрузки принципиально и схема питания позволяет, нужно устанавливать режим Fast (см. таблицы с MSEL выше).
С временем tCFG всё несколько хитрее, потому что оно зависит от:
- частоты DCLK. Она определяется возможностями FPGA и внешнего хоста. Для cyclone IV Fmax составляет 100 MHz
- размера прошивки. Определяется семейством FPGA и количеством логических ячеек в конкретном чипе. В каждом семействе всегда приводится таблица с максимальным размером прошивки для каждого чипа. Например, для Cyclone IV см сюда: link
- компрессии прошивки. В некоторых чипах (Cyclone V) определяется настройками MSEL, в некоторых (Cyclone IV) — только настройками конвертера прошивки. Типовой profit от компрессии составляет 50-70%, но никто не берётся давать 100% гарантий, что именно в вашем дизайне будет так. Поэтому "закладываться" на это число рискованно
Вот, что говорит документация о размере прошивки для Cyclone IV, Table 8-2:
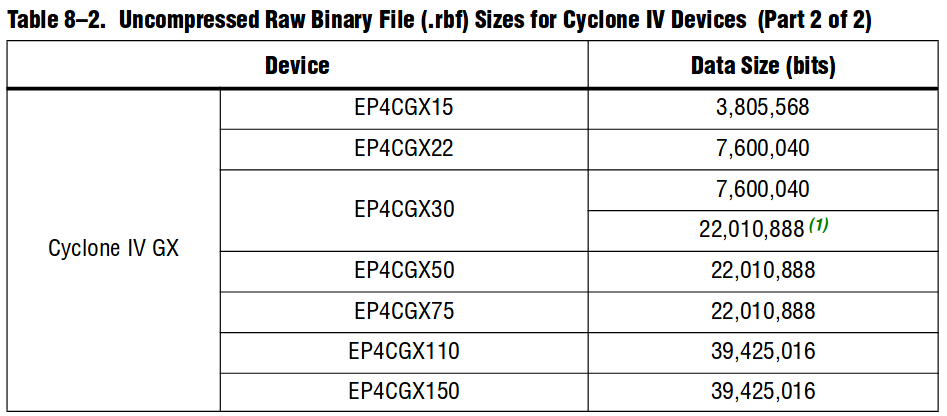
Например, для чипа EP4CGX75 максимальный размер прошивки без компресии составляет 22.010.888 бит = 2.751.361 байт. Если предположить, что внешний хост готов работать на частоте 100 МГц, то на загрузку максимальной прошивки потребуется 2.7e6 / 100e6 = 0.027 секунды = 27 миллисекунд. А если использовать компрессию, то это время можно снизить примерно вполовину, получив меньше 15 мс!
Однако, чтобы получить частоту DCLK = 100 MHz, нужно суметь прочитать прошивку как минимум на такой же частоте. Один из вариантов, предлагаемых Intel/Altera — использовать для этой цели CPLD MAX II/V. С одной стороны CPLD читает Flash, с другой — пишет в FPGA.
FPL
И для этой задачи в коллекции готовых IP-ядер есть Flash Parallel Loader. Это ядро поддерживает набор Flash-чипов с разными интерфейсами (QSPI, NxQSPI, CFI, etc...), позволяя не только прочитать из них прошивку, но и записать её, подключившись по JTAG.
Также оно позволяет записывать во Flash не одну прошивку, а несколько, организуя таким образом "откат" к стабильному образу в случае проблем с update'ом.
Более подробно смотри datasheet.
Мы выбрали режим Flash Programming & FPGA Configuration и в качестве Flash-ки — EPCQ. Это позволяет нам уложиться в требуемое время загрузки и иметь при этом возможность как прошить Flash по JTAG, так и прошить EPCQ с использованием другого хоста.
Скриншоты настроек, которые мы использовали:


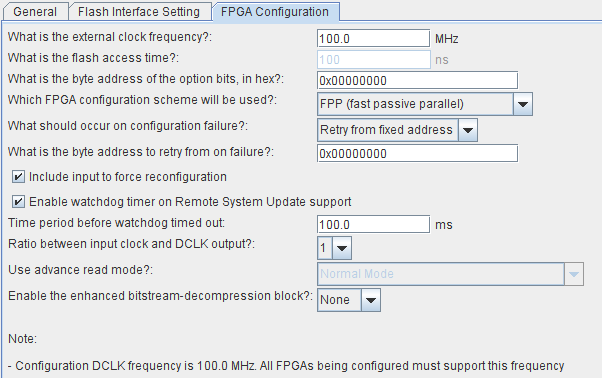
Прошивка CPLD занимает 1267 LE и практически на 100% занимает EPM1270F256C5 (MAX II) или 5M1270ZT144C5 (MAX V). Без опции прошивки Flash (скажем, если какой-то другой host может это сделать) ресурсов используется существенно меньше и появляется запас — 754 LE.
Вот схема включения CPLD:
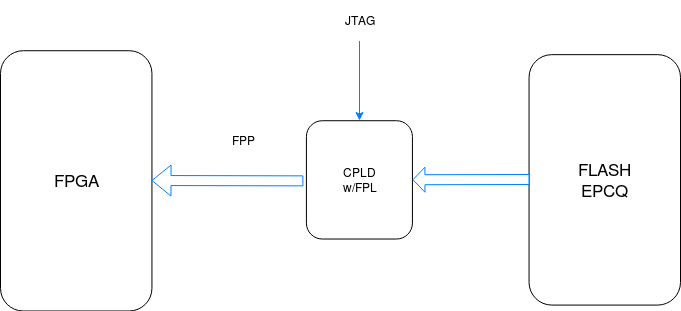
Как работает FPL (примерный алгоритм):
- по сигналу готовности (nSTATUS = 1) от FPGA он активирует nCONFIG в соответствии с диаграммой выше
- когда FPGA готова принимать данные (nSTATUS сделал перепад в ноль и обратно в единицу), FPL считывает служебный блок данных из Flash. В этом блоке прописаны адреса прошивки (или прошивок, если их несколько)
- FPL начинает загружать прошивку, которую ему указывает входной порт fpga_pgm[2:0]. Мы использовали две прошивки, поэтому на этот порт подавали 1
- Если в ходе загрузки произошла ошибка (такое может быть, если образ залит не полностью, "битый" или для другого чипа/семейства), то FPL "переключается" на factory default прошивку, которой по умолчанию считается нулевая
- FPL загружает нулевой образ в FPGA. Если и с ним всё не ОК, то он делает ещё несколько попыток и останавливается
Давайте посмотрим, какую производительность мы можем "выжать" из описанной конфигурации с одним EPCQ. Для этого нужно немного представлять, как EPCQ работает.
Как работает EPCQ
EPCQ (продвинутая версия EPCS) — это NOR-flash, которая имеет SPI-интерфейс для большинства команд и для некоторых команд — QuadSPI. Читается очень быстро, а пишется и стирается крайне неторопливо.
Команды (стирание, чтение, запись) всегда поступают во flash по обычному SPI, а дальше поведение флешки зависит от команды. Например:
- если мы запишем команду READ/FAST_READ, то чтение будет выполняться в одно-битном режиме
- если FASTDTRD, то в одно-битном режиме с DDR
- если 4READ, то в четырёх-битном режиме
- и т.д.
См. например, описание flash macronix
Максимальная производительность EPCQ на чтение достигается при использовании всех четырёх битов на максимальной частоте с DDR. Однако, при этом временные характеристики меняются нелинейно:
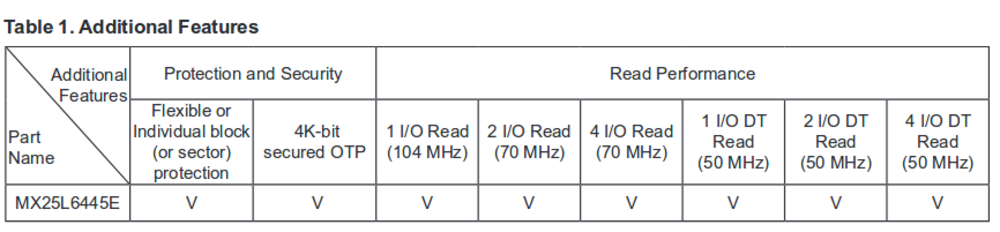
То есть throughput будет в приведённых в примере выше случаях следующим:
- READ — 104 Mbps
- FASTDTRD — 100 Mbps
- 4READ — 280 Mbps
- 4DTREAD — 400 Mbps
Есть флешки и пошустрее, например S25FL064L, в них частота не падает при увеличении разрядности чтения. Поэтому для "выжимания максималки" лучше ориентироваться на них.
Если пересчитать режимы 4READ/4DTREAD во время, необходимое для вычитывания нашей прошивки для Cyclone IV, то получается 78 мс / 55 мс. Напомню, что для того, чтобы "успеть" за FPP, нужно уложиться в 27 миллисекунд (см. выше).
Получается, что bottleneck-ом в нашей задаче является интерфейс чтения прошивки, а не сам FPP. И если бы требовалось получить не 100 мс, а существенно меньше, то нам бы пришлось использовать две флешки EPCQ. Но для нашего случая хватит и обычного режима 4READ.
Список поддерживаемых EPCQ приведён в документации на PFL, раздел 1.2.1.
Любопытно, что Intel/Altera не так давно отказались от выпуска своих EPCQ и теперь официально вместо своих поддерживают Micron'овские.
Настало время DIY!
Чтобы соединить теорию с практикой мы взяли в руки то, что было:
- kit Ethond c Cyclone V SoC (5CSEBA4U19C8SN)
- древний kit от Terasic c MAXII EPM2210f324 на борту
- EPCQ Micron N25Q256A13EF840
- паяльник, провода, "слепыш"
- человек с золотыми руками, припоем и флюсом
Чипы подключили по следующей схеме:

На слепыше навесным монтажом припаяли QSPI-флешку и получился макет:
После прохождения небольшого квеста (см. доку, раздел 1.4.1) по созданию прошивки, которая используется для заливки в EPCS через PFL (link) мы взялись измерять "времянки". При создании прошивки обратите внимание, что нужно указывать CFI-flash, как целевой, даже если используется EPCQ.
Увы, из-за навесного монтажа и "бороды", рабочая частота FPL получилась равной 6.25 МГц, а на EPCS уходит 25 МГц. Этот clock мы отрегулировали при помощи опции "Ratio between input clock and DCLK", установив значение 8 (input clock = 50 МГц). Вот как выглядит эпюра клоков FPP (синий) и EPCQ (жёлтый): видно, что на каждый такт FPP приходится два такта EPCQ DCLK, потому что разрядность FPP в два раза выше, чем EPCQ (8 против 4).

Вот так выглядит эпюра напряжения питания (жёлтый) и сигнала CONF_DONE(синий) в режиме Standard POR и без компрессии: видно, что общее время загрузки составляет 780 мс.

Между появлением питания и сигналом nSTATUS, сигнализирующем о готовности чипа принимать конфигурационные данные проходит около 100 мс:

А если включить режим Fast (меняем просто MSEL, см. таблицу выше), то POR происходит за считанные миллисекунды и загрузка уже занимает ~680 мс:

И последний шаг — включаем компресcию. Для этого ставим галочки в Quartus при добавлении файла прошивки в PFL и переключаем MSEL (в Cyclone IV MSEL трогать не надо). И получаем совсем другую картину:

По сравнению с исходным вариантом без сжатия и Fast POR имеем выигрыш в два раза — около 400 мс.
Объединяем теорию с практикой
Давайте посчитаем, сходятся ли измерения, сделанные при помощи осциллографа, с расчётами. Время tPOR считаем равным нулю, т.к. используем Fast POR. Поэтому нам остаётся только посчитать, насколько время загрузки ~680 мс сходится с размером прошивки и частотой FPP DCLK.
Размер прошивки нашего Cyclone V равен ~4 Мегабайтам (32 Мегабита). Тактовая частота FPP DCLK составляет 6.25 МГц. За такт передаётся 8 бит, то есть 1 байт. Поэтому расчётное время равно 4/6.25 = 0.64 секунды. Вуа-ля!
Если мы пропорционально увеличим частоту FPP DCLK, например в 8 раз — до 50 МГц, то получим время 80 мс. А если включим ещё и компрессию, то и того меньше.
Выводы
Теоретически ПЛИС может загрузиться за десятки миллисекунд, по нашим расчётам для Cyclone IV — примерно за 30 мс. Однако необходимо учитывать, что для этого хост, загружающий в FPGA данные, как и Flash, из которого данные грузятся, должны соответствовать по пропускной способности.
В более свежих чипахш FPGA флешку EPCQ можно подключить напрямую и использовать активный режим, а если в дизайне нет возможности перейти на новое семейство, то есть возможность поставить внешний loader и использовать пассивный режим. Для этого и используется Flash Parallel Loader, который мы использовали в нашем макете.
При описанном подходе с FPL и одной EPCQ вполне реально приблизить время загрузки FPGA к 50 мс.
Всем, кто дочитал до конца можно ставить памятник большое спасибо!

