Секвенирование ДНК в последние десятилетия превратилось из узкой области, которой занималось небольшое число ученых, в одну из самых стремительно развивающихся технологий. Рост производительности и падение стоимости даже опережают закон Мура, и, из-за большой конкуренции на рынке и огромного спроса, развитие и дальше будет идти высокими темпами. Кроме того, развитие секвенирования привело к такому же буму в биоинформатике и коренным образом изменило биологию, и, постепенно, также основательно меняет медицину.

По катом я подробнее рассказываю, как это делают.
Что такое ДНК
Для начала, чтобы понимать сам процесс, немного необходимой теории.
ДНК — это полимерная цепь, состоящая из мономеров четырех типов, называемых нуклеотидами, последовательность которых и кодирует информацию об организме. Иначе говоря, ДНК можно представить как текст, написанный четырехбуквенным алфавитом. ДНК — молекула, состоящая из двух цепочек, и, хотя, последовательность нуклеотидов у них разная, последовательность одной цепочки можно однозначно восстановить, если известна последовательность другой. Поэтому цепочки называют комплементарными. (англ. Complement – дополнение) Это свойство используется при копировании клетки, когда цепочки ДНК расплетаются, и, на каждой, как на матрице, синтезируется вторая, и каждая из двух дочерних клеток получает свою двуцепочечную ДНК. Вся последовательность ДНК организма называется геномом. Например, геном человека состоит из 46 хромосом.
Несмотря на большое количество разнообразных, как экспериментальных, так и устаревших методов, мейнстримовые коммерческие методы довольно похожи, и, чтобы не делать оговорки каждый раз, сразу скажу, что речь дальше будет идти именно об этих мейнстримовых методах.
Как это выглядит в общем
Перед описанием технологии секвенирования, для интуитивного понимания, проведу следующую аналогию: стопку одинаковых газет взрывают так, что они разлетаются на небольшие кусочки с отрывками текста, а, затем, каждый из этих кусочков читают и, из этих прочтений восстанавливают текст первоначальной газеты.
Чтобы секвенировать ДНК, сначала ее выделяют из исследуемого образца, затем режут на небольшие фрагменты случайным образом, фрагменты называются ридами. От каждого рида оставляют по одной цепочке, и на этой цепочке, как на матрице, синтезируют вторую, причем, тип каждого следующего присоединяющегося нуклеотида как-то детектируют. Таким образом, записывая последовательность присоединившихся нуклеотидов, восстанавливают их последовательность в каждом риде. Затем, из последовательностей ридов с помощью компьютерных программ реконструируют геном.
Важный момент. Суммарная длина ридов должна многократно превышать длину исследуемой ДНК. Делается это потому, что, когда ДНК выделяют из образца, и когда ее режут, часть ее теряется, так что никто не гарантирует, что каждый ее участок попадет хотя бы в один рид. Поэтому, чтобы каждый участок гарантированно был бы прочтен, ДНК берут с большим запасом. Кроме того, при секвенировании возможны ошибки, и, чтобы более надежно прочитать ДНК, каждый ее участок следует прочитать несколько раз.

ДНК разрезают на риды, которые читают, и из них восстанавливают первоначальную последовательность
Такая методика используется не от хорошей жизни. Она добавляет множество трудностей, и, если бы исследователи могли взять и прочитать за раз целую последовательность генома, то они были бы счастливы, однако, это на данный момент невозможно.
У этого есть 2 причины. Первая — это ошибки, происходящие при чтении каждого нуклеотида. Они постепенно накапливаются, и, каждый следующий нуклеотид читается хуже предыдущего, и, в какой-то момент качество чтения настолько снижается, что дальше продолжать процесс бессмысленно. У разных методов секвенирования длина рида, которы они могут хорошо прочитать, составляет порядка десятков или сотен нуклеотидов. Вторая заключается в том, что ДНК — это очень длинная молекула, и, при скрупулезном чтении каждой буквы друг за дружкой, секвенирование заняло бы неприлично много времени, а в данном случае этот процесс легко распараллеливается, и можно одновременно читать миллионы и миллиарды ридов.

Illumina
Такая схема в общих чертах описывает все популярные методики секвенирования. Различаются они лишь методами детекции присоединившихся нуклеотидов при синтезе, и методикой подготовки материала.
На сегодняшний день самым распространенным является метод, который используется в секвенаторах компании Illumina. В этом методе сначала множество различных ридов прикрепляется к стеклянной пластине. Затем, с каждого рида делают множество копий на поверхности пластины так, чтобы на каждом ее небольшом участке располагались лишь одинаковые копии. Это делается для того, чтобы при последующем секвенировании получать сигнал не от одиночной молекулы, а от группы одинаковых молекул, располагающихся рядом. Так и сигнал легче считывать, и надежность считывания увеличивается. Эти молекулы являются одноцепочечными ДНК, и на них в процессе секвенирования синтезируются комплементарные цепи. Реакцию синтеза проводят следующим образом: К началу каждой молекулы присоединяется по одному нуклеотиду. Этот нуклеотид химически блокирован так, что после его присоединения синтез дальше не идет. Кроме того, к нему присоединена метка, которая под действием лазера люминесцирует. Причем, для каждого типа нуклеотидов цвет люминесценции разный. После присоединения нуклеотида пластину освещают лазером и фотокамера фиксирует цвета, которыми люминесцирует пластина. После этого блокировку снимают, метку также снимают, и присоединяют таким же образом следующий нуклеотид. Последовательность световых сигналов на каждом участке пластины в компьютере переводится в последовательность нуклеотидов, и, на выходе получается файл, содержащий последовательности ридов.
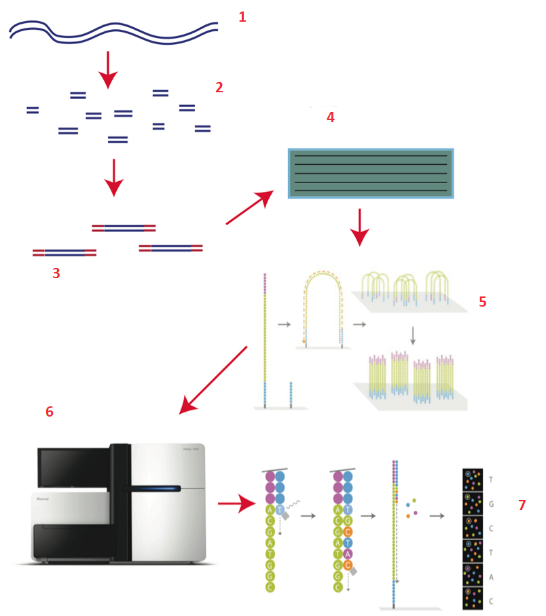
Секвенирование по методу Illumina
1 — геномная ДНК 2 — разрезается на риды 3 — к ридам прикрепляются адаптеры, с помощью которых они приклеиваются на 4 — пластину 5 — размножение ридов на пластине 6 — засовывам в секвенатор и 7 — секвенируем
Сборка и аннотирование генома
Если геномы близких организмов раньше не секвенировались, то из ридов, затем, с помощью программ, пытаются собрать единую последовательность нуклеотидов. Риды частично перекрываются, и, с помощью этих перекрытий пытаются выстроить единую последовательность. Здесь есть множество моментов, которые существенно осложняют дело. Например, можно загрязнить образец, и программа будет пытаться выстроить одну последовательность из ДНК разных организмов. Секвенатор может ошибиться при чтении рида, или неверно связать два места в геноме, потому что они очень похожи. На самом деле, сложностей так много, что всех тут не перечислишь. И, некоторые из них настолько сложно поддаются устранению, что, даже геном человека, самый важный и широко исследуемый геном, все еще не секвенирован до конца.

риды и внизу последовательность генома, которая реконструирована на их основе
Когда последовательность генома собрана, то нужно понять, что она значит. На ней находят участки, которые похожи на гены. Делается это следующим образом: В начале и конце генов находятся определенные «метки» из нуклеотидов, и, если на ДНК находят такие последовательности на таком растоянии, что между ними может уместиться ген, то такое место заносится в список потенциальных генов. Затем, этого претендента сравнивают с базой данных уже известных генов других организмов, и, если в ней находят ген, достаточно сильно похожий на этот участок, то ему присваивают функцию этого гена.
Если геном другого организма этого вида уже секвенировался, то его используют, для сборки. Так как геномы разных организмов одного вида различаются лишь незначительно, то для каждого рида находят место на секвенированном геноме, к которому он ближе всего, и на основе этого генома собирают новый.
По катом я подробнее рассказываю, как это делают.
Что такое ДНК
Для начала, чтобы понимать сам процесс, немного необходимой теории.
ДНК — это полимерная цепь, состоящая из мономеров четырех типов, называемых нуклеотидами, последовательность которых и кодирует информацию об организме. Иначе говоря, ДНК можно представить как текст, написанный четырехбуквенным алфавитом. ДНК — молекула, состоящая из двух цепочек, и, хотя, последовательность нуклеотидов у них разная, последовательность одной цепочки можно однозначно восстановить, если известна последовательность другой. Поэтому цепочки называют комплементарными. (англ. Complement – дополнение) Это свойство используется при копировании клетки, когда цепочки ДНК расплетаются, и, на каждой, как на матрице, синтезируется вторая, и каждая из двух дочерних клеток получает свою двуцепочечную ДНК. Вся последовательность ДНК организма называется геномом. Например, геном человека состоит из 46 хромосом.
Несмотря на большое количество разнообразных, как экспериментальных, так и устаревших методов, мейнстримовые коммерческие методы довольно похожи, и, чтобы не делать оговорки каждый раз, сразу скажу, что речь дальше будет идти именно об этих мейнстримовых методах.
Как это выглядит в общем
Перед описанием технологии секвенирования, для интуитивного понимания, проведу следующую аналогию: стопку одинаковых газет взрывают так, что они разлетаются на небольшие кусочки с отрывками текста, а, затем, каждый из этих кусочков читают и, из этих прочтений восстанавливают текст первоначальной газеты.
Чтобы секвенировать ДНК, сначала ее выделяют из исследуемого образца, затем режут на небольшие фрагменты случайным образом, фрагменты называются ридами. От каждого рида оставляют по одной цепочке, и на этой цепочке, как на матрице, синтезируют вторую, причем, тип каждого следующего присоединяющегося нуклеотида как-то детектируют. Таким образом, записывая последовательность присоединившихся нуклеотидов, восстанавливают их последовательность в каждом риде. Затем, из последовательностей ридов с помощью компьютерных программ реконструируют геном.
Важный момент. Суммарная длина ридов должна многократно превышать длину исследуемой ДНК. Делается это потому, что, когда ДНК выделяют из образца, и когда ее режут, часть ее теряется, так что никто не гарантирует, что каждый ее участок попадет хотя бы в один рид. Поэтому, чтобы каждый участок гарантированно был бы прочтен, ДНК берут с большим запасом. Кроме того, при секвенировании возможны ошибки, и, чтобы более надежно прочитать ДНК, каждый ее участок следует прочитать несколько раз.
ДНК разрезают на риды, которые читают, и из них восстанавливают первоначальную последовательность
Такая методика используется не от хорошей жизни. Она добавляет множество трудностей, и, если бы исследователи могли взять и прочитать за раз целую последовательность генома, то они были бы счастливы, однако, это на данный момент невозможно.
У этого есть 2 причины. Первая — это ошибки, происходящие при чтении каждого нуклеотида. Они постепенно накапливаются, и, каждый следующий нуклеотид читается хуже предыдущего, и, в какой-то момент качество чтения настолько снижается, что дальше продолжать процесс бессмысленно. У разных методов секвенирования длина рида, которы они могут хорошо прочитать, составляет порядка десятков или сотен нуклеотидов. Вторая заключается в том, что ДНК — это очень длинная молекула, и, при скрупулезном чтении каждой буквы друг за дружкой, секвенирование заняло бы неприлично много времени, а в данном случае этот процесс легко распараллеливается, и можно одновременно читать миллионы и миллиарды ридов.
Illumina
Такая схема в общих чертах описывает все популярные методики секвенирования. Различаются они лишь методами детекции присоединившихся нуклеотидов при синтезе, и методикой подготовки материала.
На сегодняшний день самым распространенным является метод, который используется в секвенаторах компании Illumina. В этом методе сначала множество различных ридов прикрепляется к стеклянной пластине. Затем, с каждого рида делают множество копий на поверхности пластины так, чтобы на каждом ее небольшом участке располагались лишь одинаковые копии. Это делается для того, чтобы при последующем секвенировании получать сигнал не от одиночной молекулы, а от группы одинаковых молекул, располагающихся рядом. Так и сигнал легче считывать, и надежность считывания увеличивается. Эти молекулы являются одноцепочечными ДНК, и на них в процессе секвенирования синтезируются комплементарные цепи. Реакцию синтеза проводят следующим образом: К началу каждой молекулы присоединяется по одному нуклеотиду. Этот нуклеотид химически блокирован так, что после его присоединения синтез дальше не идет. Кроме того, к нему присоединена метка, которая под действием лазера люминесцирует. Причем, для каждого типа нуклеотидов цвет люминесценции разный. После присоединения нуклеотида пластину освещают лазером и фотокамера фиксирует цвета, которыми люминесцирует пластина. После этого блокировку снимают, метку также снимают, и присоединяют таким же образом следующий нуклеотид. Последовательность световых сигналов на каждом участке пластины в компьютере переводится в последовательность нуклеотидов, и, на выходе получается файл, содержащий последовательности ридов.
Секвенирование по методу Illumina
1 — геномная ДНК 2 — разрезается на риды 3 — к ридам прикрепляются адаптеры, с помощью которых они приклеиваются на 4 — пластину 5 — размножение ридов на пластине 6 — засовывам в секвенатор и 7 — секвенируем
Сборка и аннотирование генома
Если геномы близких организмов раньше не секвенировались, то из ридов, затем, с помощью программ, пытаются собрать единую последовательность нуклеотидов. Риды частично перекрываются, и, с помощью этих перекрытий пытаются выстроить единую последовательность. Здесь есть множество моментов, которые существенно осложняют дело. Например, можно загрязнить образец, и программа будет пытаться выстроить одну последовательность из ДНК разных организмов. Секвенатор может ошибиться при чтении рида, или неверно связать два места в геноме, потому что они очень похожи. На самом деле, сложностей так много, что всех тут не перечислишь. И, некоторые из них настолько сложно поддаются устранению, что, даже геном человека, самый важный и широко исследуемый геном, все еще не секвенирован до конца.
риды и внизу последовательность генома, которая реконструирована на их основе
Когда последовательность генома собрана, то нужно понять, что она значит. На ней находят участки, которые похожи на гены. Делается это следующим образом: В начале и конце генов находятся определенные «метки» из нуклеотидов, и, если на ДНК находят такие последовательности на таком растоянии, что между ними может уместиться ген, то такое место заносится в список потенциальных генов. Затем, этого претендента сравнивают с базой данных уже известных генов других организмов, и, если в ней находят ген, достаточно сильно похожий на этот участок, то ему присваивают функцию этого гена.
Если геном другого организма этого вида уже секвенировался, то его используют, для сборки. Так как геномы разных организмов одного вида различаются лишь незначительно, то для каждого рида находят место на секвенированном геноме, к которому он ближе всего, и на основе этого генома собирают новый.

