От переводчика: Так как я не являюсь биологом, возможны неточности в переводе терминов (и не только :). Оригинал находится здесь.
Это всего лишь размышления программиста о ДНК. Я не являюсь молекулярным генетиком.
Находится здесь. Это не шутка. Исходники можно просмотреть с использованием замечательного набора скриптов Perl под названием "Ensembl". Геном человека занимает приблизительно 3 гигабайта, которые можно сократить до 750 мегабайт, если отбросить шелуху. Немного печалит, что это всего лишь 2.8 браузеров Mozilla Firefox.
ДНК похожа скорее не на исходники на языке C, а на байт-код для виртуальной машины под названием «ядро клетки». Крайне сомнительно, что существуют исходники, которые можно скомпилировать в этот байт-код: то, что мы видим, – это всё, что у нас есть.
 Язык ДНК является цифровым, но не двоичным. Двоичный код использует 0 и 1 (поэтому его и называют бинарным), ДНК же использует 4 значения: T, C, G и A.
Язык ДНК является цифровым, но не двоичным. Двоичный код использует 0 и 1 (поэтому его и называют бинарным), ДНК же использует 4 значения: T, C, G и A.
В то время как двоичный байт состоит в основном из 8 двоичных цифр, ДНК-«байт» (именуемый кодо́ном) содержит 3 символа. И так как каждый символ может иметь одно из четырёх значений, кодон ДНК имеет 64 возможных значения, в отличии от 256 значений двоичного байта.
Типичный пример кодона ДНК — это «GCC», который кодирует аминокислоту Аланин. Соединение большого числа этих аминокислот называется полипептидом или белком, и является химически активной составляющей всего живого. Подробнее о кодонах.
Код динамически подключаемых библиотек (.so в системах Unix, .dll в Windows) не может внутри себя использовать статические адреса, так как этот код может быть расположен в разных частях памяти в разных ситуациях. ДНК так же имеет подобную функцию, называемую «транспозирование кода»:
Большинство клеток используют только крайне малую долю из предполагаемых 20000-30000 генов человеческого генома, – что является разумным, ведь клетка печени не нуждается в ДНК-коде, составляющем нейроны.
Но ввиду того, что все клетки содержат в себе полную копию («дистрибутив») генома, необходима система, которая позволит пометить
Именно поэтому "стволовые клетки" сейчас так популярны – этот вид клеток обладает способностью превращаться во что угодно. Код ещё не за
Выражаясь более точно, в стволовых клетках не включено всё подряд – они не являются одновременно и клетками печени, и нейронами. Клетки могут быть представлены в виде конечного автомата, начинающегося из состояния стволовой клетки. В ходе жизненного цикла клетки, во время которого она может делиться (
Каждая клетка может принять (или быть побуждённой к принятию) решение о своём будущем, каждое из таких решений делают её более специализированной. Эти решения сохраняются при делении с использованием факторов транскрипции и модификации пространственного способа хранения ДНК (стерические эффекты).
Клетка печени в общем случае не может функционировать в качестве клетки кожного покрова, несмотря на то, что она содержит в себе все необходимые генетические инструкции для этого. Тем не менее, существуют признаки того, что клетки можно «вывести» вверх по иерархии, сделав их плюрипотентными.
Несмотря на то, что полноценные изменения ДНК в организме крайне редко происходят в пределах одного поколения, существенные поправки вносятся путём активации или деактивации частей нашего генома без изменения самого кода.
Если проводить аналогию, это подобно ядру Linux, которое во время загрузки обнаруживает процессор, на котором оно запущено, и отключает части своего двоичного кода в случае (к примеру), если оно запущено на однопроцессорной системе. Это не просто что-то вроде
Похожим образом, по мере развития эмбриона в утробе матери, его ДНК существенно редактируется для снижения скорости его роста и размера плаценты. Таким способом балансируются противоположные интересы отца («большой сильный ребёнок») и матери («пережить беременность»). Подобный «импринтинг» может происходить только внутри матери, так как геном отца не имеет представления о размерах матери.
С недавних пор также стало ясно, что метаболический статус родителей влияет на вероятность продолжительной жизни, возникновения рака и диабета у их внуков, что достаточно логично, ведь выживание в бедном пищей климате может потребовать совершенно иной метаболической стратегии в сравнении с жизнью в среде еды предостаточно.
Механизмы, стоящие за эпигенетикой и импринтингом, – «метилирование» – присоединяют группы метила к ДНК для переключения статуса активации отдельных участков, а также модификация гистонов, которая может свернуть участки ДНК, что приводит к деактивации этих участков.
Некоторые из этих правок ДНК являются наследуемыми и передаются потомству, другие формы воздействуют только на отдельное животное.
Эта область науки всё ещё быстро развивается, и может так оказаться, что наши ДНК гораздо более динамичны, чем мы думали.
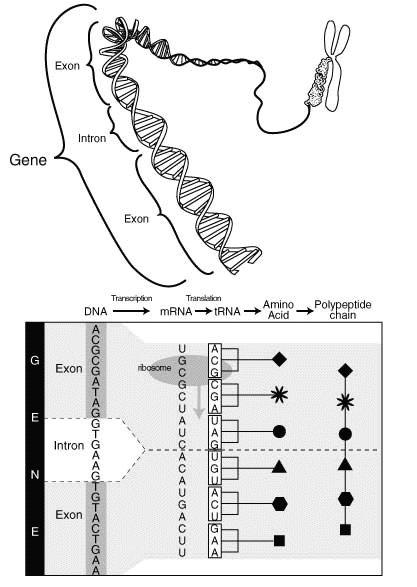 Геном засорён старыми копиями генов и неудачных экспериментов в в недалёком прошлом (около полумиллиона лет назад). Этот код всё ещё в ДНК, но неактивен. Его называют «псевдогенами».
Геном засорён старыми копиями генов и неудачных экспериментов в в недалёком прошлом (около полумиллиона лет назад). Этот код всё ещё в ДНК, но неактивен. Его называют «псевдогенами».
Более того, 97% вашего ДНК закомментировано. ДНК линейна и читается от начала до конца. Те участки, которые не нужно декодировать, отчётливо помечены, совсем как комментарии в C. Остальные 3%, которые используются по прямому предназначению, образуют так называемые «экзоны». Комментарии, которые расположены «между» называются «интронами».
Эти комментарии очаровательны по-своему. Как и комментарии C, они имеют маркеры начала (наподобие
Однако, из-за последующего разрезания, требуется некий клей, которым будут соединены код перед комментарием с кодом после комментария, что делает эти комментарии больше похожими на комментарии в HTML, которые несколько длиннее: – конец.
Так что, на самом деле промежуток ДНК с экзонами и интронами может выглядеть примерно так:
С началом комментария всё просто, за ним следует огромный объём некодирущей ДНК. Где-нибудь недалеко от окончания комментария находится участок ветвления, который означает, что комментарий скоро закончится. После него идёт ещё немного комментария, и затем настоящий ограничитель комментария.
Непосредственно вырезание комментариев происходит после того, как ДНК транскрибируется в РНК и выполняется путём скручивания комментариев в петлю и совмещения таким образом кусков настоящего кода. После этого РНК обрезается на участках ветвления около окончания комментария, затем «донор» (начало комментария) и «акцептор» (окончание) связываются друг с другом.
Так для чего же нужны эти комментарии? Эта тема для холивара силы сопоставимой с противостоянием vim/emacs. При сравнении разных видов, мы узнаём, что некоторые интроны содержат меньше различий в коде, чем соседствующие экзоны. Это наталкивает на мысль, что комментарии выполняют некую важную функцию.
Существует множество вероятных объяснений существования огромного количества некодирующей ДНК – одно из которых, наиболее привлекательное (для программиста), затрагивает «сворачивание» (folding propensity). ДНК должно храниться в сильно свёрнутой форме, но не все коды в ДНК справляются с этим в полной мере.
Отчасти это может напоминать RLL- или MFM-кодирование. На жёстком диске биты кодируются наличием или отсутствием инверсии полярности. При наивном способе кодирования мы записали бы 0 как «нет инверсии» и 1 как «инверсия».
Закодировать последовательность 000000 при таком способе крайне легко — достаточно оставить магнитную фазу неизменной на протяжении нескольких микрометров. Однако, при декодировании мы столкнёмся с неоднозначностью — сколько микрометров мы прочитали? Соответствует ли это 6 нулям или 5? Чтобы предотвратить эти проблему, данные записываются таким образом, что подобные непрерывные участки без инверсии не будут встречаться.
Если мы видим последовательность «нет инверсии, нет инверсии, инверсия, инверсия» на диске, мы можем быть уверены, что она соответствует «0011» – крайне маловероятно, что наш процесс чтения настолько неточен, чтобы мы могли трактовать её как «00011» или «00111». Таким образом, нам нужно вставить разделители, чтобы предотвратить недостаточное количество переходов. Такой подход называется «ограничением длины хода» (Run Length Limiting, RLL) на магнитных носителях.
Подчеркнём ещё раз, что порой необходимо вставить переходы (инверсии) для того, чтобы хранение данных было надёжным. Возможно, интроны выполняют подобную функцию, позволяя конечному коду сворачиваться подобающим образом.
Как бы там ни было, молекулярная биология – это минное поле! Бушуют споры и критика вокруг вариантов с волнующими названиями наподобие «ранних интронов» или «поздних интронов», а также таких солидных слов, как «сворачивание» и «потенциал образования шпилек» (stem-loop potential). Полагаю, лучше дать этим дебатам бушевать и дальше.
Апдейт от автора: десять лет спустя, эти дебаты всё ещё не утихли. Теперь совершенно очевидно, что «мусорная ДНК» является некорректным названием, но что касается её непосредственной функции консенсус так и не достигнут.
Как и в случае unix-а, клетки не «порождаются» – они делятся. Все клетки в вашем организме имеют начало в виде яйцеклетки, которая с тех пор делилась несметное количество раз. Подобно процессам, обе половины, возникающие в результате
Как и в unix, существенные проблемы возникают, когда клетки продолжают
Клетка не может клонировать себя до тех пор, пока не будут выполнены крайне строгие условия – настройки "безопасность по умолчанию". И только если все эти защитные механизмы дадут сбой, возможно развитие опухоли. Так же как и в компьютерной безопасности, сложно найти баланс между безопасностью («ни одна клетка не может делиться») и удобством использования.
Можно сравнить это с известной проблемой с остановкой, впервые описанной основоположником информатики Аланом Тьюрингом. Похоже, что предсказать, завершится ли программа когда-либо, ничуть не легче, чем создать функциональный геном, который никогда не приведёт к раку?
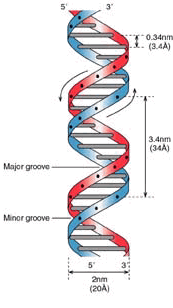 Каждая спираль ДНК избыточна сама по себе – она похожа на скрученную лестницу, в которой каждая ступенька содержит два основания – отсюда слово «пара оснований». Если одно из этих оснований отсутствует, его можно вывести из основания с другой стороны «ступеньки». T всегда связано с A, C – всегда с G. Так что мы можем утверждать, что геном зеркалируется внутри спирали, подобно RAID-1.
Каждая спираль ДНК избыточна сама по себе – она похожа на скрученную лестницу, в которой каждая ступенька содержит два основания – отсюда слово «пара оснований». Если одно из этих оснований отсутствует, его можно вывести из основания с другой стороны «ступеньки». T всегда связано с A, C – всегда с G. Так что мы можем утверждать, что геном зеркалируется внутри спирали, подобно RAID-1.
Более того, хромосомы всегда представлены в двух экземплярах – по одной от каждого родителя, за одним примечательным исплючением – Y-хромосомы, которая бывает только у самцов. Хоть детали и несколько сложнее, можно считать, что мы имеем по две копии большинства генов. В случае если один повредится или мутирует в бесполезное состояние, у нас остаётся вторая, независимая копия. Обычно мы такое называем отказоустойчивостью.
В ходе взаимодействия внутри клетки, белки́ полагаются на характеристики друг-друга. В 2001-2002 годах были опубликованы исследования, что протеины, взаимодействующие с большим числом других протеинов, не способны эволюционировать или, по крайней мере, делают это крайне медленно (журнал Nature от 28 июня 2001, а также M. Kimura, T. Ohta в журнале Science от 26 апреля 2002).
Авторы исследований предполагают, что это связано с огромным количеством внутренних зависимостей, которые препятствуют изменению «контракта» белка́. Также было отмечено, что эволюция всё же происходит, но очень медленно, так как обе стороны зависимости должны одновременно эволюционировать совместимым образом.
Недавно, в ходе беседы, кто-то предположил, что было бы действительно круто взломать геном и скомпрометировать путём вставки кода, который копировал бы себя в другие геномы, используя тело-носитель в качестве транспорта. «Совсем как червь Nimda!»
Вскоре он осознал, что именно это делают биологические вирусы на протяжении миллионов лет. И они весьма хороши в этом.
Большое число подобных вирусов стали неотъемлимой частью нашего генома и катаются вместе со всеми нами. Для этого им приходится прятаться от вирусного сканера, который стремится обнаружить чужой, вредоносный код и не допустить его проникновение в ДНК.
Центральная догма:
На заре открытий основ генетики, учёным приходилось сталкиваться со множеством химикалий, взаимосвязь которых была неочевидной. Момент, когда стало ясно, из чего что получается, был провозглашён великим триумфом и получил название «Центральная догма».
Эта догма говорит нам, что ДНК нужен для получения РНК, а РНК необходим для получения белков, подобно тому, как из .c-файл превращается в объектный файл .o, который затем может быть скомпилирован в исполняемый файл (a.out/exe). Кроме того, она сообщает нам, что это единственный порядок, в котором следует информационный поток.
И всё же, Центральная догма недавно слегка поблекла. Как и при любой миллиардлетней разработке проекта, происходило множество хаков, из-за которых информация иногда течёт в обратном направлении. Иногда РНК патчит ДНК, а бывает, что ДНК модифицируется белка́ми, созданными ранее.
Но, в целом, зависимости ясны, так что Центральная догма всё ещё остаётся важной.
Проделывать махинации с ДНК довольно просто. Существуют фирмы, которым вы можете отправить файл с ДНК, записанным ASCII-символами, и они синтезируют вам соответствующие материалы. Мы даже можем составить ДНК зародышей животных или растений.
Гораздо сложнее «пропатчить» «исполняемый файл» прямо во время выполнения, и это подтвердит любой программист. Так же дела обстоят и с геномом. Чтобы изменить запущенную копию (человека, например), необходимо отредактировать каждый экземпляр гена, который вы хотите «пропатчить», в организме.
На протяжении многих лет медицинская наука пыталась патчить людей, страдающих тяжёлым комбинированным иммунодефицитом (SCID, Severe Combined Immunodefeciency) – крайне неприятным заболеванием, которое, по сути, отключает иммунную систему, что делает пациента тяжелобольным. Достаточно давно стало понятно, какие именно буквы в ДНК необходимо исправить для исцеления этих людей.
Было осуществлено много попыток пропатчить «работающих» людей при помощи вирусов, которые вставляли бы новую ДНК в живых организмах, но этот подход оказался слишком сложным. Геном крайне хорошо защищён, чтобы такой простой подход сработал, – клетки хранят свой код надёжнее, чем Microsoft!
Тем не менее, недавно был найден подходящий вирус, который способен прорваться сквозь защиту и исправить поломки в ДНК, что, вроде бы, исцеляет больного.
По мере исправления багов в компьютерных программах, мы зачастую привносим новые баги. Геном изобилует подобными багами. Афроамериканцы обладают иммунитетом к малярии, но взамен подвержены серповидноклеточной анемии:
И это не единственный пример подобной регрессии.
Как и компьютерный накопитель, ДНК (и его промежуточная форма – РНК) может быть повреждена. Для предотвращения распространённых «однобитных ошибок» кодирование протеина в символах ДНК избыточно. Существует 4 символа РНК: U, C, G и A – другими словами, «байт» имеет длину в 2 бита. Три символа соответствуют аминокислоте.
Теоретически, 6 бит могли бы соответствовать 64 аминокислотам, однако существует только 20 стандартных аминокислот. К примеру, UCU, UCC, UCA и UCG – кодируют один и тот же серин, тогда как только UGG соответствует триптофану.
Тогда, выходит, что некоторые наиболее вероятные «опечатки» (UCU -> UCC) в коде приведут к синтезу одной и той же аминокислоты. Подробнее об этом явлении можно прочитать в книге "Metamagical Themas" за авторством Дугласа Хофстадтера (Douglas Hofstadter).
Некоторые участки кода священны. Мы можем не помнить, кто или зачем написал его, мы просто знаем, что он работает. Парень, который его написал, возможно, уже давно покинул компанию. С таким кодом лучше не связываться.
В ДНК известна концепция «молекулярных часов». Некоторые части генома активно меняются, а некоторые – неприкосновенны. Отличным примером последнего являются гистоновые гены H3 и H4.
Эти гены лежат в основе того, как геном хранится, а потому имеют первостепенную важность. Любой сбой в их коде ведёт к нежизнеспособному организму.
Поэтому можно предположить, что этот код не меняется на скорую руку, и, судя по всему, так оно и есть. Гены H3 и H4 обладают нулевым эффективным темпом мутации у людей. Но всё заходит ещё дальше. Этот код является общим для всех, начиная с человека, заканчивая травой или плесенью.
Судя по всему, существуют два способа, с помощью которых геном может удостовериться в отсутствии мутации кода. Первый способ был описан ранее: использовать аминокислоты, кодировка которых очень избыточна, что позволит получать один и тот же результат даже в случае «опечаток».
Второй способ заключается в том, что гены могут быть скопированы в начале или конце процесса репродукции клетки, что обеспечивает более или менее благоприятные условия копирования. Помимо этого, используются огромное количество подобных условий.
Похоже, что H3 и H4 были весьма тщательно проработаны, так как в них допустимо множество «синонимичных» изменений, которые благодаря вышеописанным хитрым техникам не приводят к изменению результата.
Эта последовательность, очевидно, описывает 8-битные значения 1, 2 и 3. Я добавил пробелы, чтобы было видно, где байт начинается и заканчивается. Множество последовательных устройств используют стоповые и стартовые биты для обозначения, откуда вам нужно начинать чтение. Если мы немного сдвинем эту последовательность:
она внезапно начнёт обозначать 2, 4, 6! Во избежание подобного, в ДНК применяются выработаны сигналы, которые сообщают клетке, где начинать чтение. Любопытно, что существуют участки генома, которые можно начинать читать с нескольких стартовых точек, и каждый раз получать полезный (но разный) результат. Вот что я называю крутым хаком!
Каждый способ прочтения подобного участка ДНК называется открытой рамкой считывания и их обычно 6, по 3 в каждую сторону.
И всё-таки, ДНК не похожа на язык программирования. Она действительно им не является. Тем не менее, есть несколько больших схожестей. Можно рассматривать каждую клетку в качестве центрального процессора, на каждом из которых запущено своё ядро ОС. Каждая клетка обладает полной копией ядра, но активирует только соответствующие части – свои модули и драйвера, так сказать.
Когда клетке требуется выполнить что-либо («вызвать функцию»), она находит необходимую часть генома и транскрибирует её в РНК. РНК затем переводится в последовательность аминокислот, которые в совокупности дадут белок, который был закодирован в ДНК. А теперь самая крутая часть!
Этот белок будет помечен адресом доставки. Он представлен в виде маркера, состоящего из нескольких аминокислот, который сообщает клетке, куда именно нужно доставить этот белок. Внутри клетки есть целый механизм, который выполняет эти инструкции и способен доставить белок по адресу, который может оказаться даже снаружи самой клетки.
После доставки эта инструкция отрывается и осуществляются несколько этапов пост-обработки, которые могут, например, активировать белок, ведь транспортировать активный белок через места, для которых он не предназначен, – не лучшая затея.
Организмы обычно начинают своё существование с одной клетки, которая, как было сказано ранее, содержит две полноценные копии генома. Своеобразный tar-файл, в котором все файлы уже распакованы, готовые к употреблению. Что же дальше?
Встречайте гомеобокс. Клетки должны быть скопированы и каждой нужно назначить её цель существования. Гены, которые содержат гомеобокс, начинают выстраивать цепочку зависимостей «сверху вниз», которая означает «начинать с головы». Для того, чтобы это сработало, образуется химический градиент, благодаря которому клетки могут почувствовать, где они находятся, и определить свои дальнейшие действия, требуемые для образования головы или для образования нотохорда.
Впервые обнаруженные в 1983, на данный момент гены гомеобокса являются одной из самых захватывающих областей для изучения. Отметим любопытный факт, что как и makefile, гены «HOX» только отвечают за включение разных вещей в других генах и сами по себе ничего не образуют.
Похоже, что «синтаксис» гомеобокса является «священным» в смысле, описанном выше. Что случится, если вы скопируете часть «HOX» мышинного гена, являющийся «селектором ноги» в гомеообокс дрозофилы?
Геномы дрозофилы и человека разветвились не миллионы, а сотни миллионов лет назад. И всё же вы можете скопировать участки («селекторы» на языке генетики) makefile-а и они будут работать. Прошу отметить, что процедура «выращивание ноги» у фруктовой мушки совершенно иная, нежели у мыши, но «селектор» способен корректно запустить необходимые инструкции.
Все живые организмы имеют ДНК, иногда организованные в несколько хромосом («библиотеки»), иногда только одну (как правило, закольцованную в таких случаях). Это касается и большинства бактерий. И по соседству с этим большим основным геномом такие бактерии зачастую содержат «плазмиды» – крохотные кольца ДНК с определёнными функциями.
Эти плазмиды отчасти совместимы с разными видами и при помощи разнообразных механизмов они передаются по горизонтали. Таким способом, например, даже неидентичные бактерии могут «учиться» резистентности к антибиотику друг у друга.
Если сравнивать с миром программирования, плазмиды не являются добровольным приобретением, и подобны загрузке .so при помощи LD_PRELOAD или её аналогом на других платформах. И в самом деле, плазмиды зачастую инъектируются с целью исследования. Их можно ввести в любой вид бактерии и сразу же приступать к работе.
Плазмиды копируют себя независимо от главной хромосомы, поэтому становятся постоянной составляющей бактерии. Для достижения этого, плазмида обладает геном с великолепным названием «точка начала репликации», который срабатывает, когда клетка собирается делиться.
Если ты – молоток, то во всём увидишь гвоздь
Это всего лишь размышления программиста о ДНК. Я не являюсь молекулярным генетиком.
Исходный код
Находится здесь. Это не шутка. Исходники можно просмотреть с использованием замечательного набора скриптов Perl под названием "Ensembl". Геном человека занимает приблизительно 3 гигабайта, которые можно сократить до 750 мегабайт, если отбросить шелуху. Немного печалит, что это всего лишь 2.8 браузеров Mozilla Firefox.
ДНК похожа скорее не на исходники на языке C, а на байт-код для виртуальной машины под названием «ядро клетки». Крайне сомнительно, что существуют исходники, которые можно скомпилировать в этот байт-код: то, что мы видим, – это всё, что у нас есть.
Язык ДНК является цифровым, но не двоичным. Двоичный код использует 0 и 1 (поэтому его и называют бинарным), ДНК же использует 4 значения: T, C, G и A.В то время как двоичный байт состоит в основном из 8 двоичных цифр, ДНК-«байт» (именуемый кодо́ном) содержит 3 символа. И так как каждый символ может иметь одно из четырёх значений, кодон ДНК имеет 64 возможных значения, в отличии от 256 значений двоичного байта.
Типичный пример кодона ДНК — это «GCC», который кодирует аминокислоту Аланин. Соединение большого числа этих аминокислот называется полипептидом или белком, и является химически активной составляющей всего живого. Подробнее о кодонах.
Позиционно-независимый код
Код динамически подключаемых библиотек (.so в системах Unix, .dll в Windows) не может внутри себя использовать статические адреса, так как этот код может быть расположен в разных частях памяти в разных ситуациях. ДНК так же имеет подобную функцию, называемую «транспозирование кода»:
Почти половина генома человека состоит из транспозируемых (или «подвижных») генетических элементов. Эти элементы впервые были обнаружены в 1940-х годах доктором Барбарой МакКлинток (Barbara McClintock) при изучении своеобразных схем наследования, найденых в цветах индийской кукурузы. Идея подвижного ДНК заключается в том, что некоторые участки являются нестабильными и «транспозируемыми», то есть они могут перемещаться – внутри и между хромосомами.
Условная компиляция
Большинство клеток используют только крайне малую долю из предполагаемых 20000-30000 генов человеческого генома, – что является разумным, ведь клетка печени не нуждается в ДНК-коде, составляющем нейроны.
Но ввиду того, что все клетки содержат в себе полную копию («дистрибутив») генома, необходима система, которая позволит пометить
#ifdef ненужные вещи. И именно так всё и работает. Генетический код кишит директивами #if/#endif.Именно поэтому "стволовые клетки" сейчас так популярны – этот вид клеток обладает способностью превращаться во что угодно. Код ещё не за
#ifdefен, так сказать.Выражаясь более точно, в стволовых клетках не включено всё подряд – они не являются одновременно и клетками печени, и нейронами. Клетки могут быть представлены в виде конечного автомата, начинающегося из состояния стволовой клетки. В ходе жизненного цикла клетки, во время которого она может делиться (
fork()) множество раз, она специализируется. Каждая специализация может рассматриваться как выбор ветки в дереве.Каждая клетка может принять (или быть побуждённой к принятию) решение о своём будущем, каждое из таких решений делают её более специализированной. Эти решения сохраняются при делении с использованием факторов транскрипции и модификации пространственного способа хранения ДНК (стерические эффекты).
Клетка печени в общем случае не может функционировать в качестве клетки кожного покрова, несмотря на то, что она содержит в себе все необходимые генетические инструкции для этого. Тем не менее, существуют признаки того, что клетки можно «вывести» вверх по иерархии, сделав их плюрипотентными.
Эпигенетика и импринтинг: патчи во время выполнения
Несмотря на то, что полноценные изменения ДНК в организме крайне редко происходят в пределах одного поколения, существенные поправки вносятся путём активации или деактивации частей нашего генома без изменения самого кода.
Если проводить аналогию, это подобно ядру Linux, которое во время загрузки обнаруживает процессор, на котором оно запущено, и отключает части своего двоичного кода в случае (к примеру), если оно запущено на однопроцессорной системе. Это не просто что-то вроде
if (numcpus > 1), этот код по-настоящему заменяется nop-ами. Крайне важно, что nop-ирование происходит в памяти, а не в образе на диске.Похожим образом, по мере развития эмбриона в утробе матери, его ДНК существенно редактируется для снижения скорости его роста и размера плаценты. Таким способом балансируются противоположные интересы отца («большой сильный ребёнок») и матери («пережить беременность»). Подобный «импринтинг» может происходить только внутри матери, так как геном отца не имеет представления о размерах матери.
С недавних пор также стало ясно, что метаболический статус родителей влияет на вероятность продолжительной жизни, возникновения рака и диабета у их внуков, что достаточно логично, ведь выживание в бедном пищей климате может потребовать совершенно иной метаболической стратегии в сравнении с жизнью в среде еды предостаточно.
Механизмы, стоящие за эпигенетикой и импринтингом, – «метилирование» – присоединяют группы метила к ДНК для переключения статуса активации отдельных участков, а также модификация гистонов, которая может свернуть участки ДНК, что приводит к деактивации этих участков.
Некоторые из этих правок ДНК являются наследуемыми и передаются потомству, другие формы воздействуют только на отдельное животное.
Эта область науки всё ещё быстро развивается, и может так оказаться, что наши ДНК гораздо более динамичны, чем мы думали.
«Мёртвый» код, раздутый код, комментарии (мусор в ДНК)
Геном засорён старыми копиями генов и неудачных экспериментов в в недалёком прошлом (около полумиллиона лет назад). Этот код всё ещё в ДНК, но неактивен. Его называют «псевдогенами».Более того, 97% вашего ДНК закомментировано. ДНК линейна и читается от начала до конца. Те участки, которые не нужно декодировать, отчётливо помечены, совсем как комментарии в C. Остальные 3%, которые используются по прямому предназначению, образуют так называемые «экзоны». Комментарии, которые расположены «между» называются «интронами».
Эти комментарии очаровательны по-своему. Как и комментарии C, они имеют маркеры начала (наподобие
/*) и маркеры окончания (*/). Но они имеют более сложную структуру. Ведь, как вы помните, ДНК похожа на ленту, соответственно, комментарии нужно вырезать физически! Начало комментария практически всегда указывается буквами «GT», что можно сопоставить с /*, окончание обозначается символами «AG», которые, соответственно, аналогичны */.Однако, из-за последующего разрезания, требуется некий клей, которым будут соединены код перед комментарием с кодом после комментария, что делает эти комментарии больше похожими на комментарии в HTML, которые несколько длиннее: – конец.
Так что, на самом деле промежуток ДНК с экзонами и интронами может выглядеть примерно так:
настоящий код<!-- бла бла бла бла ---- бла -->настоящий код
| | | | | |
экзон 1 донор* интрон 1 ветвь акцептор** экзон 2
* начало комментария
** окончание комментария
С началом комментария всё просто, за ним следует огромный объём некодирущей ДНК. Где-нибудь недалеко от окончания комментария находится участок ветвления, который означает, что комментарий скоро закончится. После него идёт ещё немного комментария, и затем настоящий ограничитель комментария.
Непосредственно вырезание комментариев происходит после того, как ДНК транскрибируется в РНК и выполняется путём скручивания комментариев в петлю и совмещения таким образом кусков настоящего кода. После этого РНК обрезается на участках ветвления около окончания комментария, затем «донор» (начало комментария) и «акцептор» (окончание) связываются друг с другом.
Так для чего же нужны эти комментарии? Эта тема для холивара силы сопоставимой с противостоянием vim/emacs. При сравнении разных видов, мы узнаём, что некоторые интроны содержат меньше различий в коде, чем соседствующие экзоны. Это наталкивает на мысль, что комментарии выполняют некую важную функцию.
Существует множество вероятных объяснений существования огромного количества некодирующей ДНК – одно из которых, наиболее привлекательное (для программиста), затрагивает «сворачивание» (folding propensity). ДНК должно храниться в сильно свёрнутой форме, но не все коды в ДНК справляются с этим в полной мере.
Отчасти это может напоминать RLL- или MFM-кодирование. На жёстком диске биты кодируются наличием или отсутствием инверсии полярности. При наивном способе кодирования мы записали бы 0 как «нет инверсии» и 1 как «инверсия».
Закодировать последовательность 000000 при таком способе крайне легко — достаточно оставить магнитную фазу неизменной на протяжении нескольких микрометров. Однако, при декодировании мы столкнёмся с неоднозначностью — сколько микрометров мы прочитали? Соответствует ли это 6 нулям или 5? Чтобы предотвратить эти проблему, данные записываются таким образом, что подобные непрерывные участки без инверсии не будут встречаться.
Если мы видим последовательность «нет инверсии, нет инверсии, инверсия, инверсия» на диске, мы можем быть уверены, что она соответствует «0011» – крайне маловероятно, что наш процесс чтения настолько неточен, чтобы мы могли трактовать её как «00011» или «00111». Таким образом, нам нужно вставить разделители, чтобы предотвратить недостаточное количество переходов. Такой подход называется «ограничением длины хода» (Run Length Limiting, RLL) на магнитных носителях.
Подчеркнём ещё раз, что порой необходимо вставить переходы (инверсии) для того, чтобы хранение данных было надёжным. Возможно, интроны выполняют подобную функцию, позволяя конечному коду сворачиваться подобающим образом.
Как бы там ни было, молекулярная биология – это минное поле! Бушуют споры и критика вокруг вариантов с волнующими названиями наподобие «ранних интронов» или «поздних интронов», а также таких солидных слов, как «сворачивание» и «потенциал образования шпилек» (stem-loop potential). Полагаю, лучше дать этим дебатам бушевать и дальше.
Апдейт от автора: десять лет спустя, эти дебаты всё ещё не утихли. Теперь совершенно очевидно, что «мусорная ДНК» является некорректным названием, но что касается её непосредственной функции консенсус так и не достигнут.
fork() и fork-бомбы (опухоли)
Как и в случае unix-а, клетки не «порождаются» – они делятся. Все клетки в вашем организме имеют начало в виде яйцеклетки, которая с тех пор делилась несметное количество раз. Подобно процессам, обе половины, возникающие в результате
fork() поначалу (почти) идентичны, но в дальнейшем они решают заняться разными делами.Как и в unix, существенные проблемы возникают, когда клетки продолжают
forkаться. Достаточно скоро они исчерпают ресурсы, что может привести к смерти. Это называется опухолью. Клетки нашпигованы ulimit и сторожевыми таймерами (watchdogs) для предотвращения развития подобного сценария. К примеру, количество делений ограничивается укорачиванием теломер.Клетка не может клонировать себя до тех пор, пока не будут выполнены крайне строгие условия – настройки "безопасность по умолчанию". И только если все эти защитные механизмы дадут сбой, возможно развитие опухоли. Так же как и в компьютерной безопасности, сложно найти баланс между безопасностью («ни одна клетка не может делиться») и удобством использования.
Можно сравнить это с известной проблемой с остановкой, впервые описанной основоположником информатики Аланом Тьюрингом. Похоже, что предсказать, завершится ли программа когда-либо, ничуть не легче, чем создать функциональный геном, который никогда не приведёт к раку?
Зеркалирование, отказоустойчивость
Каждая спираль ДНК избыточна сама по себе – она похожа на скрученную лестницу, в которой каждая ступенька содержит два основания – отсюда слово «пара оснований». Если одно из этих оснований отсутствует, его можно вывести из основания с другой стороны «ступеньки». T всегда связано с A, C – всегда с G. Так что мы можем утверждать, что геном зеркалируется внутри спирали, подобно RAID-1.Более того, хромосомы всегда представлены в двух экземплярах – по одной от каждого родителя, за одним примечательным исплючением – Y-хромосомы, которая бывает только у самцов. Хоть детали и несколько сложнее, можно считать, что мы имеем по две копии большинства генов. В случае если один повредится или мутирует в бесполезное состояние, у нас остаётся вторая, независимая копия. Обычно мы такое называем отказоустойчивостью.
Нагромождение API, ад зависимостей
В ходе взаимодействия внутри клетки, белки́ полагаются на характеристики друг-друга. В 2001-2002 годах были опубликованы исследования, что протеины, взаимодействующие с большим числом других протеинов, не способны эволюционировать или, по крайней мере, делают это крайне медленно (журнал Nature от 28 июня 2001, а также M. Kimura, T. Ohta в журнале Science от 26 апреля 2002).
Авторы исследований предполагают, что это связано с огромным количеством внутренних зависимостей, которые препятствуют изменению «контракта» белка́. Также было отмечено, что эволюция всё же происходит, но очень медленно, так как обе стороны зависимости должны одновременно эволюционировать совместимым образом.
Вирусы, черви
Недавно, в ходе беседы, кто-то предположил, что было бы действительно круто взломать геном и скомпрометировать путём вставки кода, который копировал бы себя в другие геномы, используя тело-носитель в качестве транспорта. «Совсем как червь Nimda!»
Вскоре он осознал, что именно это делают биологические вирусы на протяжении миллионов лет. И они весьма хороши в этом.
Большое число подобных вирусов стали неотъемлимой частью нашего генома и катаются вместе со всеми нами. Для этого им приходится прятаться от вирусного сканера, который стремится обнаружить чужой, вредоносный код и не допустить его проникновение в ДНК.
Центральная догма: .c -> .o -> a.out/.exe
На заре открытий основ генетики, учёным приходилось сталкиваться со множеством химикалий, взаимосвязь которых была неочевидной. Момент, когда стало ясно, из чего что получается, был провозглашён великим триумфом и получил название «Центральная догма».
Эта догма говорит нам, что ДНК нужен для получения РНК, а РНК необходим для получения белков, подобно тому, как из .c-файл превращается в объектный файл .o, который затем может быть скомпилирован в исполняемый файл (a.out/exe). Кроме того, она сообщает нам, что это единственный порядок, в котором следует информационный поток.
И всё же, Центральная догма недавно слегка поблекла. Как и при любой миллиардлетней разработке проекта, происходило множество хаков, из-за которых информация иногда течёт в обратном направлении. Иногда РНК патчит ДНК, а бывает, что ДНК модифицируется белка́ми, созданными ранее.
Но, в целом, зависимости ясны, так что Центральная догма всё ещё остаётся важной.
Бинарные патчи, aka «генная терапия»
Проделывать махинации с ДНК довольно просто. Существуют фирмы, которым вы можете отправить файл с ДНК, записанным ASCII-символами, и они синтезируют вам соответствующие материалы. Мы даже можем составить ДНК зародышей животных или растений.
Гораздо сложнее «пропатчить» «исполняемый файл» прямо во время выполнения, и это подтвердит любой программист. Так же дела обстоят и с геномом. Чтобы изменить запущенную копию (человека, например), необходимо отредактировать каждый экземпляр гена, который вы хотите «пропатчить», в организме.
На протяжении многих лет медицинская наука пыталась патчить людей, страдающих тяжёлым комбинированным иммунодефицитом (SCID, Severe Combined Immunodefeciency) – крайне неприятным заболеванием, которое, по сути, отключает иммунную систему, что делает пациента тяжелобольным. Достаточно давно стало понятно, какие именно буквы в ДНК необходимо исправить для исцеления этих людей.
Было осуществлено много попыток пропатчить «работающих» людей при помощи вирусов, которые вставляли бы новую ДНК в живых организмах, но этот подход оказался слишком сложным. Геном крайне хорошо защищён, чтобы такой простой подход сработал, – клетки хранят свой код надёжнее, чем Microsoft!
Тем не менее, недавно был найден подходящий вирус, который способен прорваться сквозь защиту и исправить поломки в ДНК, что, вроде бы, исцеляет больного.
Регрессия кода
По мере исправления багов в компьютерных программах, мы зачастую привносим новые баги. Геном изобилует подобными багами. Афроамериканцы обладают иммунитетом к малярии, но взамен подвержены серповидноклеточной анемии:
В тропических регионах мира, где распространена малярия, разносимая паразитами, люди, обладающие одной копией конкретной генетической мутации, имеют преимущество в выживании.
…
В то время как унаследование одной копии этой мутации приносит пользу, унаследование двух копий приводит к трагедии. Ребёнок, рождённый с двумя копиями генетической мутации, обладает серповидноклеточной анемией, болезненным заболеванием, которое влияет на красные клетки крови.
Источник
И это не единственный пример подобной регрессии.
Коды Рида-Соломона: Прямая коррекция ошибок
Как и компьютерный накопитель, ДНК (и его промежуточная форма – РНК) может быть повреждена. Для предотвращения распространённых «однобитных ошибок» кодирование протеина в символах ДНК избыточно. Существует 4 символа РНК: U, C, G и A – другими словами, «байт» имеет длину в 2 бита. Три символа соответствуют аминокислоте.
Теоретически, 6 бит могли бы соответствовать 64 аминокислотам, однако существует только 20 стандартных аминокислот. К примеру, UCU, UCC, UCA и UCG – кодируют один и тот же серин, тогда как только UGG соответствует триптофану.
Тогда, выходит, что некоторые наиболее вероятные «опечатки» (UCU -> UCC) в коде приведут к синтезу одной и той же аминокислоты. Подробнее об этом явлении можно прочитать в книге "Metamagical Themas" за авторством Дугласа Хофстадтера (Douglas Hofstadter).
Священный код: /* от вас не требуется понимание этого кода */
Некоторые участки кода священны. Мы можем не помнить, кто или зачем написал его, мы просто знаем, что он работает. Парень, который его написал, возможно, уже давно покинул компанию. С таким кодом лучше не связываться.
В ДНК известна концепция «молекулярных часов». Некоторые части генома активно меняются, а некоторые – неприкосновенны. Отличным примером последнего являются гистоновые гены H3 и H4.
Эти гены лежат в основе того, как геном хранится, а потому имеют первостепенную важность. Любой сбой в их коде ведёт к нежизнеспособному организму.
Поэтому можно предположить, что этот код не меняется на скорую руку, и, судя по всему, так оно и есть. Гены H3 и H4 обладают нулевым эффективным темпом мутации у людей. Но всё заходит ещё дальше. Этот код является общим для всех, начиная с человека, заканчивая травой или плесенью.
Темп замены нуклеотидов в пересчёте на сайт на 1 миллиард лет между различными протеин-кодирующими генами человека и грызуна с разбросом в 80 миллионов лет, на основании ископаемых доказательств:
Ген Кол-во кодонов Эффективный темп Гистон 3 135 0.00 Гистон 4 101 0.00 Инсулин 51 0.13 Гамма-интерферон 136 2.79
Источник
Судя по всему, существуют два способа, с помощью которых геном может удостовериться в отсутствии мутации кода. Первый способ был описан ранее: использовать аминокислоты, кодировка которых очень избыточна, что позволит получать один и тот же результат даже в случае «опечаток».
Второй способ заключается в том, что гены могут быть скопированы в начале или конце процесса репродукции клетки, что обеспечивает более или менее благоприятные условия копирования. Помимо этого, используются огромное количество подобных условий.
Похоже, что H3 и H4 были весьма тщательно проработаны, так как в них допустимо множество «синонимичных» изменений, которые благодаря вышеописанным хитрым техникам не приводят к изменению результата.
Ошибки кадрирования: стартовые и стоповые биты
...0 0000 0001 0000 0010 0000 0011 0...Эта последовательность, очевидно, описывает 8-битные значения 1, 2 и 3. Я добавил пробелы, чтобы было видно, где байт начинается и заканчивается. Множество последовательных устройств используют стоповые и стартовые биты для обозначения, откуда вам нужно начинать чтение. Если мы немного сдвинем эту последовательность:
...00 0000 0010 0000 0100 0000 0110 ...она внезапно начнёт обозначать 2, 4, 6! Во избежание подобного, в ДНК применяются выработаны сигналы, которые сообщают клетке, где начинать чтение. Любопытно, что существуют участки генома, которые можно начинать читать с нескольких стартовых точек, и каждый раз получать полезный (но разный) результат. Вот что я называю крутым хаком!
Каждый способ прочтения подобного участка ДНК называется открытой рамкой считывания и их обычно 6, по 3 в каждую сторону.
Массовая многопроцессорность: каждая клетка – это вселенная
И всё-таки, ДНК не похожа на язык программирования. Она действительно им не является. Тем не менее, есть несколько больших схожестей. Можно рассматривать каждую клетку в качестве центрального процессора, на каждом из которых запущено своё ядро ОС. Каждая клетка обладает полной копией ядра, но активирует только соответствующие части – свои модули и драйвера, так сказать.
Когда клетке требуется выполнить что-либо («вызвать функцию»), она находит необходимую часть генома и транскрибирует её в РНК. РНК затем переводится в последовательность аминокислот, которые в совокупности дадут белок, который был закодирован в ДНК. А теперь самая крутая часть!
Этот белок будет помечен адресом доставки. Он представлен в виде маркера, состоящего из нескольких аминокислот, который сообщает клетке, куда именно нужно доставить этот белок. Внутри клетки есть целый механизм, который выполняет эти инструкции и способен доставить белок по адресу, который может оказаться даже снаружи самой клетки.
После доставки эта инструкция отрывается и осуществляются несколько этапов пост-обработки, которые могут, например, активировать белок, ведь транспортировать активный белок через места, для которых он не предназначен, – не лучшая затея.
Makefile
Организмы обычно начинают своё существование с одной клетки, которая, как было сказано ранее, содержит две полноценные копии генома. Своеобразный tar-файл, в котором все файлы уже распакованы, готовые к употреблению. Что же дальше?
Встречайте гомеобокс. Клетки должны быть скопированы и каждой нужно назначить её цель существования. Гены, которые содержат гомеобокс, начинают выстраивать цепочку зависимостей «сверху вниз», которая означает «начинать с головы». Для того, чтобы это сработало, образуется химический градиент, благодаря которому клетки могут почувствовать, где они находятся, и определить свои дальнейшие действия, требуемые для образования головы или для образования нотохорда.
Впервые обнаруженные в 1983, на данный момент гены гомеобокса являются одной из самых захватывающих областей для изучения. Отметим любопытный факт, что как и makefile, гены «HOX» только отвечают за включение разных вещей в других генах и сами по себе ничего не образуют.
Похоже, что «синтаксис» гомеобокса является «священным» в смысле, описанном выше. Что случится, если вы скопируете часть «HOX» мышинного гена, являющийся «селектором ноги» в гомеообокс дрозофилы?
По факту, в случае вставки гена мыши HOX-B6 в геном дрозофилы, она может заменить гены antennapedia и вырастить ноги на месте антенн.
Источник
Геномы дрозофилы и человека разветвились не миллионы, а сотни миллионов лет назад. И всё же вы можете скопировать участки («селекторы» на языке генетики) makefile-а и они будут работать. Прошу отметить, что процедура «выращивание ноги» у фруктовой мушки совершенно иная, нежели у мыши, но «селектор» способен корректно запустить необходимые инструкции.
Плагины: Плазмиды
Все живые организмы имеют ДНК, иногда организованные в несколько хромосом («библиотеки»), иногда только одну (как правило, закольцованную в таких случаях). Это касается и большинства бактерий. И по соседству с этим большим основным геномом такие бактерии зачастую содержат «плазмиды» – крохотные кольца ДНК с определёнными функциями.
Эти плазмиды отчасти совместимы с разными видами и при помощи разнообразных механизмов они передаются по горизонтали. Таким способом, например, даже неидентичные бактерии могут «учиться» резистентности к антибиотику друг у друга.
Если сравнивать с миром программирования, плазмиды не являются добровольным приобретением, и подобны загрузке .so при помощи LD_PRELOAD или её аналогом на других платформах. И в самом деле, плазмиды зачастую инъектируются с целью исследования. Их можно ввести в любой вид бактерии и сразу же приступать к работе.
Плазмиды копируют себя независимо от главной хромосомы, поэтому становятся постоянной составляющей бактерии. Для достижения этого, плазмида обладает геном с великолепным названием «точка начала репликации», который срабатывает, когда клетка собирается делиться.

