Внедрение ИИ на уровне микросхем позволяет обрабатывать локально больше данных, потому что увеличение количества устройств уже не даёт прежнего эффекта
Производители микросхем работают над новыми архитектурами, которые значительно увеличивают объём обрабатываемых данных на ватт и такт. Готовится почва для одной из крупнейших революций в архитектуре чипов за последние десятилетия.
Все основные производители чипов и систем меняют направление развития. Они вступили в гонку архитектур, которая предусматривает изменение парадигмы во всём: от методов чтения и записи в память до их обработки и, в конечном счёте, компоновки различных элементов на чипе. Хотя миниатюризация продолжается, уже никто не делает ставку на масштабирование, чтобы справится со взрывным ростом данных от сенсоров и увеличения объёма трафика между машинами.
Среди изменений в новых архитектурах:
- Новые методы для обработки большего объёма данных за 1 такт, иногда с меньшей точностью или путём приоритета определённых операций, в зависимости от приложения.
- Новые архитектуры памяти, которые меняют способы хранения, чтения, записи и доступа к данным.
- Более специализированные модули обработки, размещённые по всей системе близко к памяти. Вместо центрального процессора ускорители выбираются в зависимости от типа данных и приложения.
- В области ИИ ведётся работа по объединению различных типов данных в виде шаблонов, что эффективно увеличивает плотность данных при минимизации расхождений между разными типами.
- Теперь компоновка в корпусе — основной компонент архитектуры, при этом всё большее внимание уделяется простоте изменения этих конструкций.
«Есть несколько тенденций, которые влияют на технический прогресс, — сказал Стивен Ву, выдающийся инженер Rambus. — В дата-центрах вы выжимаете максимум из железа и софта. Под таким углом владельцы дата-центров смотрят на экономику. Внедрение чего-то нового обходится дорого. Но узкие места меняются, поэтому внедряются специализированные чипы для более эффективных вычислений. И если вы уменьшаете потоки данных туда и обратно на ввод-вывод и к памяти, это может оказать большое влияние».
Изменения более очевидны на краю вычислительной инфраструктуры, то есть среди оконечных сенсоров. Производители внезапно осознали, что десятки миллиардов устройств будут генерировать слишком большое количество данных: такой объём невозможно отправить на обработку в облако. Но обработка всех этих данных на краю привносит другие проблемы: она требует серьёзных улучшений в производительности без сильного повышения энергопотребления.
«Заметна новая тенденция к снижению точности, — говорит Роберт Обер, ведущий архитектор платформы Tesla в компании Nvidia. — Это не просто вычислительные циклы. Это более интенсивная упаковка данных в памяти, где используется формат 16-битных команд».
Обер считает, что благодаря серии архитектурных оптимизаций можно в обозримом будущем удваивать скорость обработки каждые пару лет. «Мы увидим, кардинальное повышение производительности, — сказал он. — Для этого нужно сделать три вещи. Первое — вычисления. Второе — память. Третья область — пропускная способность хоста и пропускная способность ввода-вывода. Необходимо проделать большую работу по оптимизации хранения и сетевого стека».
Кое-что уже реализуется. В презентации на конференции Hot Chips 2018 Джефф Рупли, ведущий архитектор научно-исследовательского центра Samsung в Остине, указал на несколько крупных архитектурных изменений в процессоре M3. Одно включает больше инструкций на такт — шесть вместо четырёх в прошлом чипе M2. Кроме того, реализовано предсказание ветвлений на нейросетях и вдвое увеличена очередь инструкций.
Такие изменения смещают точку инноваций с непосредственного изготовления микросхем к архитектуре и дизайну с одной стороны и к компоновке элементов с другой стороны производственной цепочки. И хотя в технологических процессах инновации тоже будут продолжаться, но только за счёт него невероятно сложно добиться повышения производительности и мощности на 15−20% в каждой новой модели чипа — и этого недостаточно, чтобы совладать со стремительным ростом объёма данных.
«Изменения происходят с экспоненциальной скоростью, — сказал Виктор Пэн, президент и генеральный директор Xilinx, в выступлении на конференции Hot Chips — Каждый год будет генерироваться 10 зеттабайт [1021 байт] данных, и основная часть — в неструктурированном виде».
Новые подходы к памяти
Работа с таким большим количеством данных требует переосмысления каждого компонента в системе, от методов обработки данных до их хранения.
«Было много попыток создать новые архитектуры памяти, — сказал Карлос Мачин, старший директор по инновациям eSilicon EMEA. — Проблема в том, что нужно считывать все строки и выбрать по одному биту в каждой. Один из вариантов заключается в создании памяти, которую можно читать слева направо, а также вверх и вниз. Можно пойти ещё дальше и добавить вычисления к памяти».
Эти изменения включают в себя изменение методов чтения памяти, расположения и типа элементов обработки, а также внедрение ИИ для определения приоритетов хранения, обработки и перемещения данных по всей системе.
«Что, если в случае разреженных данных мы сможем читать из этого массива только по одному байту за раз — или, может быть, по восемь последовательных байтов из того же байтового тракта, не тратя энергию на другие байты или байтовые тракты, которые нас не интересуют? — спрашивает Марк Гринберг, директор по маркетингу продуктов Cadence. — В будущем такое возможно. Если посмотреть на архитектуру HBM2, например, то там стек организован в 16 виртуальных каналов по 64 бита каждый, и нужно получить только 4 последовательных 64-битных слова для доступа к любому виртуальному каналу. Таким образом, возможно создавать массивы данных шириной 1024 бита, записывать горизонтально, но читать вертикально по четыре 64-битных слова за раз».
Память — один из основных компонентов архитектуры фон Неймана, но сейчас она также стала одной из главных арен для экспериментов. «Главный враг — это системы виртуальной памяти, куда данные перемещаются более неестественными способами, — сказал Дэн Бувье, главный архитектор клиентских продуктов AMD. — Это трансляции трансляций. Мы привыкли к этому в области графики. Но если устранить конфликты в банке памяти DRAM, мы получим гораздо более эффективную потоковую передачу. Тогда отдельный GPU может использовать DRAM в диапазоне 90% эффективности, что очень неплохо. Но если наладить потоковую передачу без разрывов, CPU и APU тоже попадут в диапазон эффективности от 80% до 85%».
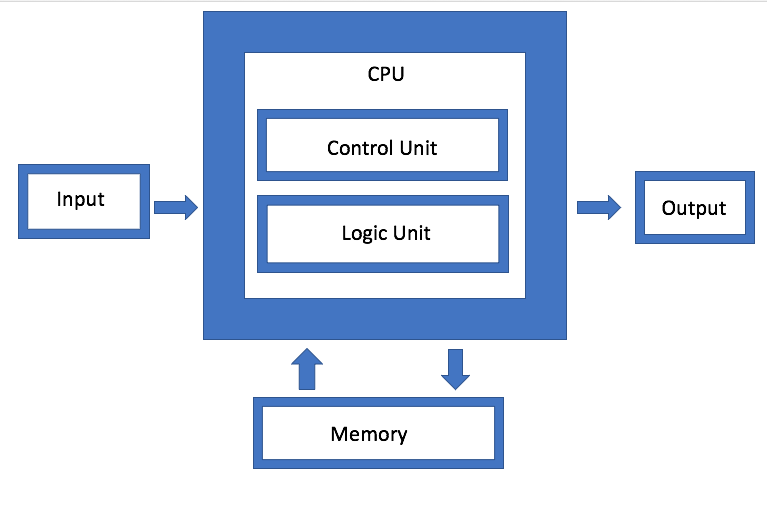
Рис. 1. Архитектура фон Неймана. Источник: Semiconductor Engineering
IBM разрабатывает иной тип архитектуры памяти, которая по сути является модернизированной версией объединения дисков. Цель состоит в том, чтобы вместо использования одного диска система могла произвольно использовать любую доступную память через коннектор, который Джефф Стучели, архитектор аппаратных систем IBM, называет «швейцарским армейским ножом» для связности элементов. Преимущество подхода в том, что он позволяет смешивать и сочетать различные типы данных.
«Процессор превращается в центр высокопроизводительного сигнального интерфейса, — говорит Стучели. — Если изменить микроархитектуру, то ядро выполняет больше операций за цикл на той же частоте».
Связность и пропускная способность должны обеспечить обработку кардинально возросшего объёма генерируемых данных. «Основные узкие места сейчас находятся в местах перемещения данных, — сказал Ву из Rambus. — Отрасль проделала большую работу, повысив скорость вычислений. Но если вы ожидаете данных или специализированных шаблонов данных, то нужно быстрее запускать память. Таким образом, если посмотреть на DRAM и NVM, производительность зависит от схемы трафика. Если данные идут потоком, то память обеспечит очень хорошую эффективность. Но если данные поступают случайными каплями, это менее эффективно. И что бы вы ни делали, с увеличением объёма всё равно придётся делать это быстрее».
Больше вычислений, меньше трафика
Проблема усугубляется тем, что существует несколько различных типов данных, генерируемых на разных частотах и скоростях устройствами на краю. Чтобы эти данные беспрепятственно перемещались между различными модулями обработки, управление должно стать гораздо эффективнее, чем в прошлом.
«Есть четыре основные конфигурации: «многие ко многим» (many-to-many), подсистемы памяти, маломощный IO, а также сетки и кольцевые топологии, — говорит Чарли Джанак, председатель и генеральный директор Arteris IP. — Вы можете разместить все четыре на одном чипе, что и происходит с ключевыми чипами IoT. Или можно добавить подсистемы HBM с высокой пропускной способностью. Но сложность огромна, потому что некоторые из этих рабочих нагрузок очень специфичны, а у чипа несколько разных рабочих задач. Если посмотреть на некоторые из этих микросхем, они получают огромные объёмы данных. Это в таких системах как автомобильные радары и лидары. Они не могут существовать без неких продвинутых межсоединений».
Задача в том, как минимизировать перемещение данных, но при этом максимизировать поток данных, когда это требуется — и как-то найти баланс между локальной и централизованной обработкой без излишнего роста энергопотребления.
«С одной стороны, это проблема пропускной способности, — сказал Раджеш Рамануджам, менеджер по маркетингу продуктов NetSpeed Systems. — Вы хотите по возможности уменьшить трафик, поэтому переносите данные ближе к процессору. Но если всё-таки нужно переместить данные, то желательно максимально их уплотнить. Но ничто не существует само по себе. Всё надо планировать с системного уровня. На каждом шаге нужно учитывать несколько взаимозависимых осей. Они определяют, используете вы память традиционным способом чтения-записи или вы используете новые технологии. В некоторых случаях может потребоваться изменить способ хранения самих данных. Если нужна более высокая производительность, это, как правило, означает увеличение площади микросхемы, что влияет на тепловыделение. И теперь с учётом функциональной безопасности нельзя допустить перегрузки данными».
Именно поэтому так много внимания уделяется обработке данных на краю и пропускной способности каналов различными модулями обработки данных. Но по мере разработки разных архитектур сильно отличается, как и где реализована эта обработка данных.
Например, Marvell представила контроллер SSD со встроенным ИИ, чтобы справиться с большой вычислительной нагрузкой на краю. Движок ИИ можно использовать для аналитики прямо внутри SSD-накопителя.
«Вы можете загружать модели непосредственно в аппаратное обеспечение и выполнять аппаратную обработку на контроллере SSD, — сказал Нед Варница, главный инженер Marvell. — Сегодня это делает сервер в облаке (хост). Но если каждый диск будет отправлять данные в облако, это создаст огромный объём сетевого трафика. Лучше выполнять обработку на краю, а хост выдаёт только команду, которая является просто метаданными. Чем больше у вас накопителей, тем больше вычислительной мощности. Это огромная выгода от сокращения трафика».
В этом подходе особенно интересно, что он адаптируется под разные данные в зависимости от приложения. Так, хост может генерировать задачу и отправлять её на устройство хранения для обработки, после чего обратно отправляются только метаданные или результаты вычислений. В другом сценарии устройство хранения может хранить данные, предварительно обрабатывать их и генерировать метаданные, теги и индексы, которые затем извлекаются хостом по мере необходимости для дальнейшей аналитики.
Это один из возможных вариантов. Есть и другие. Рупли из Samsung подчеркнул важность идиом обработки и слияния, способных декодировать две инструкции и объединять их в одну операцию.
ИИ занимается контролем и оптимизацией
На всех уровнях оптимизации применяется Искусственный Интеллект — это один из действительно новых элементов в архитектуре чипов. Вместо того, чтобы позволить операционной системе и промежуточному ПО управлять функциями, эта контролирующая функция распределяется по чипу, между чипами и на системном уровне. В некоторых случаях внедряются аппаратные нейросети.
«Дело не столько в том, чтобы упаковывать вместе больше элементов, сколько в изменении традиционной архитектуры, — говорит Майк Джанфанья, вице-президент по маркетингу eSilicon. — С помощью ИИ и машинного обучения вы можете распределить элементы по системе, получив более эффективную обработку с прогнозированием. Или можно использовать отдельные чипы, независимо функционирующие в системе или в модуле».
Компания ARM разработала свой первый чип машинного обучения, который планирует выпустить в конце этого года для нескольких рынков. «Это новый тип процессора, — сказал Ян Брэтт, заслуженный инженер ARM. — Он включает в себя фундаментальный блок — это вычислительный движок, а также движок MAC, движок DMA с контрольным модулем и широковещательной сетью. Всего там 16 вычислительных ядер, сделанных по техпроцессу 7 нм, которые выдают 4 TeraOps на частоте 1 ГГц».
Поскольку ARM работает с партнёрской экосистемой, её чип более универсальный и настраиваемый, чем другие разрабатываемые чипы AI/ML. Вместо монолитной структуры он разделяет обработку по функциям, поэтому каждый вычислительный модуль работает на отдельной карте признаков. Брэтт назвал четыре ключевых ингридиента: статическое планирование, эффективное свёртывание, механизмы сужения полосы и запрограммированная адаптация к будущим изменениям дизайна.

Рис. 2. Архитектура процессора ML от ARM. Источник: ARM/Hot Chips
Между тем Nvidia избрала другую тактику: создание выделенного движка глубокого обучения рядом с GPU для оптимизации обработки изображений и видео.
Заключение
Используя некоторые или все эти подходы, производители микросхем рассчитывают удваивать производительность каждые пару лет, не отставая от взрывного роста данных, оставаясь при этом в жёстких рамках бюджетов энергопотребления. Но это не просто больше вычислений. Это изменение платформы проектирования чипов и систем, когда главным фактором становится растущий объём данных, а не ограничения аппаратного и программного обеспечения.
«Когда в компаниях появились компьютеры, многим показалось, что мир вокруг ускорился, — сказал Аарт де Гес, председатель и один из исполнительных директоров Synopsys. — Они производили бухгалтерский учёт на бумажках со стопками бухгалтерских книг. Бухгалтерская книга превратилась в стопку перфокарт для распечатки и вычисления. Произошло колоссальное изменение, и мы видим это снова. С появлением простых компьютеров-вычислителей ментально алгоритм действий не изменился: вы могли проследить каждый шаг. Но сейчас происходит другое, что может привести к новому ускорению. Это как на сельскохозяйственном поле включать полив и вносить определённый вид удобрения только в определённый день, когда температура достигнет нужного уровня. Такое использование машинного обучения является оптимизацией, которая не была очевидна в прошлом».
Он не одинок в этой оценке. «Новые архитектуры будут приняты, — сказал Уолли Райнс, президент и генеральный директор Mentor, Siemens Business. — Они будут спроектированы. Машинное обучение будет использоваться во многих или большинстве случаев, потому что ваш мозг учится на своём опыте. Я посетил 20 или больше компаний, которые разрабатывают специализированные процессоры ИИ того или иного рода, и у каждой из них — своя собственная маленькая ниша. Но вы всё чаще увидите их применение в конкретных приложениях, и они будут дополнять традиционную архитектуру фон Неймана. Нейроморфные вычисления станут мейнстримом. Это большой шаг в эффективности вычислений и снижении стоимости. Мобильные устройства и сенсоры начнут делать работу, какую сегодня выполняют серверы».

