Предыстория
Лет 15 назад я узнал о существовании фундаментальных путей — групп, которые могут различать топологические пространства по связности. Дальше будет не о них, но они натолкнули на идею регрессора и классификатора — без всяких оптимизаций, основанного на запоминании выборки.
Далее подробнее.
Идеи и домыслы
Поскольку фундаментальные пути — это петли из выбранной точки, и эквивалентность на них, то как можно найти такие петли в данных? И надо ли?
Идея пришла по аналогии с KNN и SVM — «аналогисткими» алгоритмами. Что если петлю заменить на «трубу», цилиндр из одной данных точки в другую, и то, что попало в трубу — относить к тому же классу что и эти две точки пути (уже не фундаментального)? «Труба» должна быть такой ширины, чтобы правильно относить классы… и в пределе — это прямая. Расстояние до новой, неизвестной точки должно быть минимальным в пути, тогда мы сможем отнести её к тому же классу, что и путь.
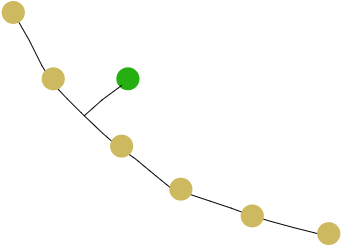
Регрессор можно построить по проекции точки на прямую между точками данных, и интерполировать соответствующие точкам данных целевые значения тем же соотношением, в котором проекция делит путь.
Этот способ по построению запоминает всю выборку и выдает точные предсказания на тренировочном множестве.
Примитивная реализация
Как построить путь? Я взял максимальный по норме элемент, и стал искать ближайший к нему, соединяя получил путь. В конце — замкнул с началом (спорно конечно, но вот так).
Estimator
Это самая первая версия кода, смотрите ниже обновленный notebook.
class PathMachine(BaseEstimator): def __init__(self, norm=np.linalg.norm, classify=False): self.norm = norm self.classify = classify def find_start(self, X): index_max = None value_max = -np.inf for index, x in enumerate(X): value = self.norm(x) if value > value_max: index_max = index value_max = value return index_max def find_next(self, point, target, X, y): index_min = None value_min = np.inf for index, x in enumerate(X): if self.classify and (y[index] != target): continue value = self.norm(x - point) if value < value_min: index_min = index value_min = value return index_min def fit(self, X, y): X = np.copy(X) y = np.copy(y).flatten() self.paths = {} if self.classify else [] start_index = self.find_start(X) start_value = X[start_index] start_target = y[start_index] X = np.delete(X, start_index, axis=0) y = np.delete(y, start_index, axis=0) while len(X) > 0: next_index = self.find_next(start_value, start_target, X, y) if self.classify and next_index is None: start_index = self.find_start(X) start_value = X[start_index] start_target = y[start_index] continue next_target = y[next_index] if self.classify: if not next_target in self.paths: self.paths[next_target] = [] self.paths[next_target].append({ 'start': start_value, 'next': X[next_index] }) else: self.paths.append({ 'start': start_value, 'next': X[next_index], 'value': start_target, 'target': next_target }) start_value = X[next_index] start_target = y[next_index] X = np.delete(X, next_index, axis=0) y = np.delete(y, next_index, axis=0) if self.classify: self.paths[start_target].append({ 'start': start_value, 'next': self.paths[start_target][0]['start'] }) else: self.paths.append({ 'start': start_value, 'next': self.paths[0]['start'], 'value': start_target, 'target': self.paths[0]['target'] }) return self def predict(self, X): result = [] for x in X: if self.classify: predicted = None min_distance = np.inf for target in self.paths: for path in self.paths[target]: point = x - path['start'] line = path['next'] - path['start'] if np.allclose(self.norm(line), 0): continue direction = line / self.norm(line) product = np.dot(point, direction) projection = product * direction distance = self.norm(projection - point) if distance < min_distance: predicted = target min_distance = distance result.append(predicted) else: predicted = None min_distance = np.inf for path in self.paths: point = x - path['start'] line = path['next'] - path['start'] if np.allclose(self.norm(line), 0): continue direction = line / self.norm(line) product = np.dot(point, direction) projection = product * direction parameter = np.sign(product) * self.norm(projection) /\ self.norm(line) distance = self.norm(projection - point) if distance < min_distance: predicted = (1 - parameter) * path['value'] +\ parameter * path['target'] min_distance = distance result.append(predicted) return np.array(result) def score(self, X, y): if self.classify: return f1_score(y.flatten(), self.predict(X), average='micro') else: return r2_score(y.flatten(), self.predict(X))
Теоретически (и технически), возможно так же сделать и predict_proba — как 1 — отнормированные расстояния. Но как вероятности толком протестировать я сходу не придумал, поэтому…
Некоторые тесты
Начал я с классических Boston Housing и Iris, и за baseline выбрал Ridge и LogisticRegression. Ну а что, а вдруг.
Вообще, предлагаю посмотреть jupyter notebook.
Вкратце: регрессор сработал хуже, классификатор сработал лучше.
update: после StandardScaler, регрессор заработал лучше.
Покатал я также и на синтетических датасетах. Там вообще что в лес, что дрова.
Но было подмечено вот что:
- Регрессор неплохо работает на пространствах малых размерностей,
- И регрессор, и классификатор — чувствительны к шумам, начиная с некоторого порога,
- Регрессор, в отличие от линейки, заподозрил мультимодальность (в Boston Housing),
- По построению, классификатор хорошо отработал (лучше всех...:)) на линейно неразделимом множестве moons.
Выводы, плюсы-минусы и применимость
Плюсов лично я не особо вижу в текущей реализации. Как технически, так и математически. Возможно, это можно доработать до чего-то более толкового. Соответственно и применимости особой тоже не вижу. Разве что без препроцессинга работать с очень малыми данными…
Минусов много: требуется держать весь датасет в памяти, обобщающая способность построена на экстраполяции, основной и единственный гиперпараметр — норма — не поддается особым подборам-переборам.
Но, так или иначе, для меня полученное было сюрпризом, чем и я решил здесь поделиться.

