
В очередной раз проезжая на машине по родному городу и объезжая очередную яму я подумал: а везде ли в нашей стране такие «хорошие» дороги и решил — надо объективно оценить ситуацию с качеством дорог в нашей стране.
Формализация задачи
В России требования к качеству дорог описываются в ГОСТ Р 50597-2017 «Дороги автомобильные и улицы. Требования к эксплуатационному состоянию, допустимому по условиям обеспечения безопасности дорожного движения. Методы контроля». Этот документ определяет требования к покрытию проезжей части, обочинам, разделительным полосам, тротуарам, пешеходным дорожкам и т.п., а так же устанавливает типы повреждений.
Поскольку задача определения всех параметров дорог достаточно обширна, а решил для себя ее сузить и остановиться только на задаче определения дефектов покрытия проезжей части. В ГОСТ Р 50597-2017 выделяются следующие дефекты покрытия проезжей части:
- выбоины
- проломы
- просадки
- сдвиги
- гребенки
- колея
- выпотевание вяжущего
Выявлением этих дефектов я и решил заняться.
Сбор датасета
Где взять фотографии на которых изображены достаточно большие участки дорожного полотна, да еще с привязкой к геолокации? Ответ пришел стразу — панорамы на картах Яндекса (или Гугла), однако, немного поискав, нашел еще несколько альтернативных вариантов:
- выдача поисковиков по картинкам для соответствующих запросов;
- фотографии на сайтах для приема жалоб (Росяма, Сердитый гражданин, Добродел и пр.)
- на Opendatascience подсказали проект по детектированию дефектов дорог с размеченным датасетом — github.com/sekilab/RoadDamageDetector
К сожалению, анализ этих вариантов показал, что они не очень-то мне подходят: выдача поисковиков обладает большим шумом (много фотографий, не являющихся дорогами, различных рендеров и тп), фотографии с сайтов для приема жалоб содержат только фотографии с большими нарушениями асфальтового покрытия, фотографий с небольшими нарушения покрытия и без нарушений на этих сайтах довольно мало, датасет из проекта RoadDamageDetector собран в Японии и не содержит образцов с большими нарушения покрытия, а также дорог без покрытия вообще.
Раз альтернативные варианты не подходят будем использовать панорамы Яндекса (вариант панорам Гугла я исключил, т. к. сервис представлен в меньшем количестве городов России и обновляется реже). Данные решил собирать в городах с населением более 100 тыс. человек, а также в федеральных центрах. Составил список названий городов — их оказалось 176, позже выяснится, что панорамы есть только в 149 из них. Не буду углубятся в особенности парсинга тайлов, скажу что в итоге у меня получилось 149 папок (по одной для каждого города) в которых суммарно находилось 1.7 млн фотографий. К примеру для Новокузнецка папка выглядела вот так:

По количеству скачанных фотографий города распределились следующим образом:
Таблица
| Город |
Количество фотографий, шт |
|---|---|
| Москва |
86048 |
| Санкт-Петербург |
41376 |
| Саранск |
18880 |
| Подольск |
18560 |
| Красногорск |
18208 |
| Люберцы |
17760 |
| Калининград |
16928 |
| Коломна |
16832 |
| Мытищи |
16192 |
| Владивосток |
16096 |
| Балашиха |
15968 |
| Петрозаводск |
15968 |
| Екатеринбург |
15808 |
| Великий Новгород |
15744 |
| Набережные Челны |
15680 |
| Краснодар |
15520 |
| Нижний Новгород |
15488 |
| Химки |
15296 |
| Тула |
15296 |
| Новосибирск |
15264 |
| Тверь |
15200 |
| Миасс |
15104 |
| Иваново |
15072 |
| Вологда |
15008 |
| Жуковский |
14976 |
| Кострома |
14912 |
| Самара |
14880 |
| Королёв |
14784 |
| Калуга |
14720 |
| Череповец |
14720 |
| Севастополь |
14688 |
| Пушкино |
14528 |
| Ярославль |
14464 |
| Ульяновск |
14400 |
| Ростов-на-Дону |
14368 |
| Домодедово |
14304 |
| Каменск-Уральский |
14208 |
| Псков |
14144 |
| Йошкар-Ола |
14080 |
| Керчь |
14080 |
| Мурманск |
13920 |
| Тольятти |
13920 |
| Владимир |
13792 |
| Орёл |
13792 |
| Сыктывкар |
13728 |
| Долгопрудный |
13696 |
| Ханты-Мансийск |
13664 |
| Казань |
13600 |
| Энгельс |
13440 |
| Архангельск |
13280 |
| Брянск |
13216 |
| Омск |
13120 |
| Сызрань |
13088 |
| Красноярск |
13056 |
| Щёлково |
12928 |
| Пенза |
12864 |
| Челябинск |
12768 |
| Чебоксары |
12768 |
| Нижний Тагил |
12672 |
| Ставрополь |
12672 |
| Раменское |
12640 |
| Иркутск |
12608 |
| Ангарск |
12608 |
| Тюмень |
12512 |
| Одинцово |
12512 |
| Уфа |
12512 |
| Магадан |
12512 |
| Пермь |
12448 |
| Киров |
12256 |
| Нижнекамск |
12224 |
| Махачкала |
12096 |
| Нижневартовск |
11936 |
| Курск |
11904 |
| Сочи |
11872 |
| Тамбов |
11840 |
| Пятигорск |
11808 |
| Волгодонск |
11712 |
| Рязань |
11680 |
| Саратов |
11616 |
| Дзержинск |
11456 |
| Оренбург |
11456 |
| Курган |
11424 |
| Волгоград |
11264 |
| Ижевск |
11168 |
| Златоуст |
11136 |
| Липецк |
11072 |
| Кисловодск |
11072 |
| Сургут |
11040 |
| Магнитогорск |
10912 |
| Смоленск |
10784 |
| Хабаровск |
10752 |
| Копейск |
10688 |
| Майкоп |
10656 |
| Петропавловск-Камчатский |
10624 |
| Таганрог |
10560 |
| Барнаул |
10528 |
| Сергиев Посад |
10368 |
| Элиста |
10304 |
| Стерлитамак |
9920 |
| Симферополь |
9824 |
| Томск |
9760 |
| Орехово-Зуево |
9728 |
| Астрахань |
9664 |
| Евпатория |
9568 |
| Ногинск |
9344 |
| Чита |
9216 |
| Белгород |
9120 |
| Бийск |
8928 |
| Рыбинск |
8896 |
| Северодвинск |
8832 |
| Воронеж |
8768 |
| Благовещенск |
8672 |
| Новороссийск |
8608 |
| Улан-Удэ |
8576 |
| Серпухов |
8320 |
| Комсомольск-на-Амуре |
8192 |
| Абакан |
8128 |
| Норильск |
8096 |
| Южно-Сахалинск |
8032 |
| Обнинск |
7904 |
| Ессентуки |
7712 |
| Батайск |
7648 |
| Волжский |
7584 |
| Новочеркасск |
7488 |
| Бердск |
7456 |
| Арзамас |
7424 |
| Первоуральск |
7392 |
| Кемерово |
7104 |
| Электросталь |
6720 |
| Дербент |
6592 |
| Якутск |
6528 |
| Муром |
6240 |
| Нефтеюганск |
5792 |
| Реутов |
5696 |
| Биробиджан |
5440 |
| Новокуйбышевск |
5248 |
| Салехард |
5184 |
| Новокузнецк |
5152 |
| Новый Уренгой |
4736 |
| Ноябрьск |
4416 |
| Новочебоксарск |
4352 |
| Елец |
3968 |
| Каспийск |
3936 |
| Старый Оскол |
3840 |
| Артём |
3744 |
| Железногорск |
3584 |
| Салават |
3584 |
| Прокопьевск |
2816 |
| Горно-Алтайск |
2464 |
Подготовка датасета для обучения
И так, датасет собран, как теперь имея фотографию участка дороги и прилагающих объектов узнать качество асфальта, изображенного на ней? Я решил вырезать кусок фотографии размером 350*244 пикселя по центру исходной фотографии чуть ниже середины. Затем уменьшить вырезанный кусок по горизонтали до размера 244 пикселя. Получившееся изображение (размером 244*244) и будет входным для сверточного энкодера:

Что бы лучше понять с какими данными я имею дело первых 2000 картинок я разметил сам, остальные картинки размечали работники Яндекс.Толоки. Перед ними я поставил вопрос в следующей формулировке.
Укажите, какое дорожное покрытие Вы видите на фотографии:
- Грунт/Щебень
- Брусчатка, плитка, мостовая
- Рельсы, ж/д пути
- Вода, большие лужи
- Асфальт
- На фотографии нет дороги/ Посторонние предметы/ Покрытие не видно из-за машин
Если исполнитель выбирал «Асфальт», то появлялось меню, предлагающее оценить его качество:
- Отличное покрытие
- Незначительные одиночные трещины/неглубокие одиночные выбоины
- Большие трещины/Сетка трещин/одиночные не значительные выбоины
- Большое количество выбоин/ Глубокие выбоины/ Разрушенное покрытие
Как показали тестовые запуски заданий, исполнители Я.Толоки добросовестностью работы не отличаются – случайно кликают мышкой по полям и считают задание выполненным. Пришлось добавлять контрольные вопросы (в задании было 46 фотографий, 12 из которых были контрольными) и включить отложенную приемку. В качестве контрольных вопросов я использовал те картинки, которые разметил сам. Отложенную приемку я автоматизировал – Я.Толока позволяет выгружать результаты работы в CSV-файл, и загружать результаты проверки ответов. Проверка ответов работала следующим образом – если в задании более 5% неверных ответов на контрольные вопросы, то оно считается невыполненным. При этом, если исполнитель указал ответ, логически близкий к верному, то его ответ считается верным.
В результате я получил около 30 тысяч размеченных фотографий, которые я решил распределить в три класса для обучения:
- «Good» – фотографии с метками «Асфальт: Отличное покрытие» и «Асфальт: Незначительные одиночные трещины»
- «Middle» — фотографии с метками «Брусчатка, плитка, мостовая», «Рельсы, ж/д пути» и «Асфальт: Большие трещины/Сетка трещин/одиночные не значительные выбоины»
- «Large» — фотографии с метками «Грунт/Щебень», «Вода, большие лужи» и «Асфальт: Большое количество выбоин/ Глубокие выбоины/ Разрушенное покрытие»
- Фотографии с метками «На фотографии нет дороги/ Посторонние предметы/ Покрытие не видно из-за машин» оказалось очень мало (22 шт.) и я их исключил из дальнейшей работы
Разработка и обучение классификатора
Итак, данные собраны и размечены, переходим к разработке классификатора. Обычно для задач классификации изображений, особенно при обучении на небольших датасетах, используют готовый сверточный энкодер, к выходу которого подключают новый классификатор. Я решил использовать простой классификатор без скрытого слоя, входной слой размером 128 и выходной слой размером 3. В качестве энкодеров решил сразу использовать несколько готовых вариантов, обученных на ImageNet:
- Xception
- Resnet
- Inception
- Vgg16
- Densenet121
- Mobilenet
Вот так выглядит функция, создающая Keras-модель с заданным энкодером:
def createModel(typeModel): conv_base = None if(typeModel == "nasnet"): conv_base = keras.applications.nasnet.NASNetMobile(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "xception"): conv_base = keras.applications.xception.Xception(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "resnet"): conv_base = keras.applications.resnet50.ResNet50(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "inception"): conv_base = keras.applications.inception_v3.InceptionV3(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "densenet121"): conv_base = keras.applications.densenet.DenseNet121(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "mobilenet"): conv_base = keras.applications.mobilenet_v2.MobileNetV2(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "vgg16"): conv_base = keras.applications.vgg16.VGG16(include_top=False, input_shape=(224,224,3), weights='imagenet') conv_base.trainable = False model = Sequential() model.add(conv_base) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_regularizer=regularizers.l2(0.0002))) model.add(Dropout(0.3)) model.add(Dense(3, activation='softmax')) model.compile(optimizer=keras.optimizers.Adam(lr=1e-4), loss='binary_crossentropy', metrics=['accuracy']) return model
Для обучения использовал генератор с аугментацией (т.к. возможностей встроенной в Keras аугментации мне показались недостаточными, то я воспользовался библиотекой Augmentor):
- Наклоны
- Случайные искажения
- Повороты
- Замена цвета
- Сдвиги
- Изменение контраста и яркости
- Добавление случайного шума
- Кропы
После аугментации фотографии выгладили так:

Код генератора:
def get_datagen(): train_dir='~/data/train_img' test_dir='~/data/test_img' testDataGen = ImageDataGenerator(rescale=1. / 255) train_generator = datagen.flow_from_directory( train_dir, target_size=img_size, batch_size=16, class_mode='categorical') p = Augmentor.Pipeline(train_dir) p.skew(probability=0.9) p.random_distortion(probability=0.9,grid_width=3,grid_height=3,magnitude=8) p.rotate(probability=0.9, max_left_rotation=5, max_right_rotation=5) p.random_color(probability=0.7, min_factor=0.8, max_factor=1) p.flip_left_right(probability=0.7) p.random_brightness(probability=0.7, min_factor=0.8, max_factor=1.2) p.random_contrast(probability=0.5, min_factor=0.9, max_factor=1) p.random_erasing(probability=1,rectangle_area=0.2) p.crop_by_size(probability=1, width=244, height=244, centre=True) train_generator = keras_generator(p,batch_size=16) test_generator = testDataGen.flow_from_directory( test_dir, target_size=img_size, batch_size=32, class_mode='categorical') return (train_generator, test_generator)
В коде видно, что для тестовых данных аугментация не используется.
Имея настроенный генератор можно заняться обучением модели, его будем проводить в два этапа: сначала обучать только наш классификатор, затем полностью всю модель.
def evalModelstep1(typeModel): K.clear_session() gc.collect() model=createModel(typeModel) traiGen,testGen=getDatagen() model.fit_generator(generator=traiGen, epochs=4, steps_per_epoch=30000/16, validation_steps=len(testGen), validation_data=testGen, ) return model def evalModelstep2(model): early_stopping_callback = EarlyStopping(monitor='val_loss', patience=3) model.layers[0].trainable=True model.trainable=True model.compile(optimizer=keras.optimizers.Adam(lr=1e-5), loss='binary_crossentropy', metrics=['accuracy']) traiGen,testGen=getDatagen() model.fit_generator(generator=traiGen, epochs=25, steps_per_epoch=30000/16, validation_steps=len(testGen), validation_data=testGen, callbacks=[early_stopping_callback] ) return model def full_fit(): model_names=[ "xception", "resnet", "inception", "vgg16", "densenet121", "mobilenet" ] for model_name in model_names: print("#########################################") print("#########################################") print("#########################################") print(model_name) print("#########################################") print("#########################################") print("#########################################") model = evalModelstep1(model_name) model = evalModelstep2(model) model.save("~/data/models/model_new_"+str(model_name)+".h5")
Вызываем full_fit() и ждем. Долго ждем.
По результату будем иметь шесть обученных моделей, точность этих моделей проверять будем на отдельной порции размеченных даны я получил следующие:
Название модели |
Точность, % |
Xception |
87.3 |
Resnet |
90.8 |
Inception |
90.2 |
Vgg16 |
89.2 |
Densenet121 |
90.6 |
Mobilenet |
86.5 |
В общем-то, не густо, но при такой маленькой обучающей выборке ожидать большего не приходится. Чтобы еще немного поднять точность я объединил выходы моделей за счет усреднения:
def create_meta_model(): model_names=[ "xception", "resnet", "inception", "vgg16", "densenet121", "mobilenet" ] model_input = Input(shape=(244,244,3)) submodels=[] i=0; for model_name in model_names: filename= "~/data/models/model_new_"+str(model_name)+".h5" submodel = keras.models.load_model(filename) submodel.name = model_name+"_"+str(i) i+=1 submodels.append(submodel(model_input)) out=average(submodels) model = Model(inputs = model_input,outputs=out) model.compile(optimizer=keras.optimizers.Adam(lr=1e-4), loss='binary_crossentropy', metrics=['accuracy']) return model
Итоговая точность получилась 91,3 %. На таком результате я решил остановиться.
Использование классификатора
Наконец-то готов классификатор и его можно запустить в дело! Подготавливаю входные данные и запускаю классификатор — чуть больше суток и 1,7 млн. фотографий обработаны. Теперь самое интересное – результаты. Сразу привожу первую и последнюю десятку городов по относительному количеству дорог с хорошим покрытием:
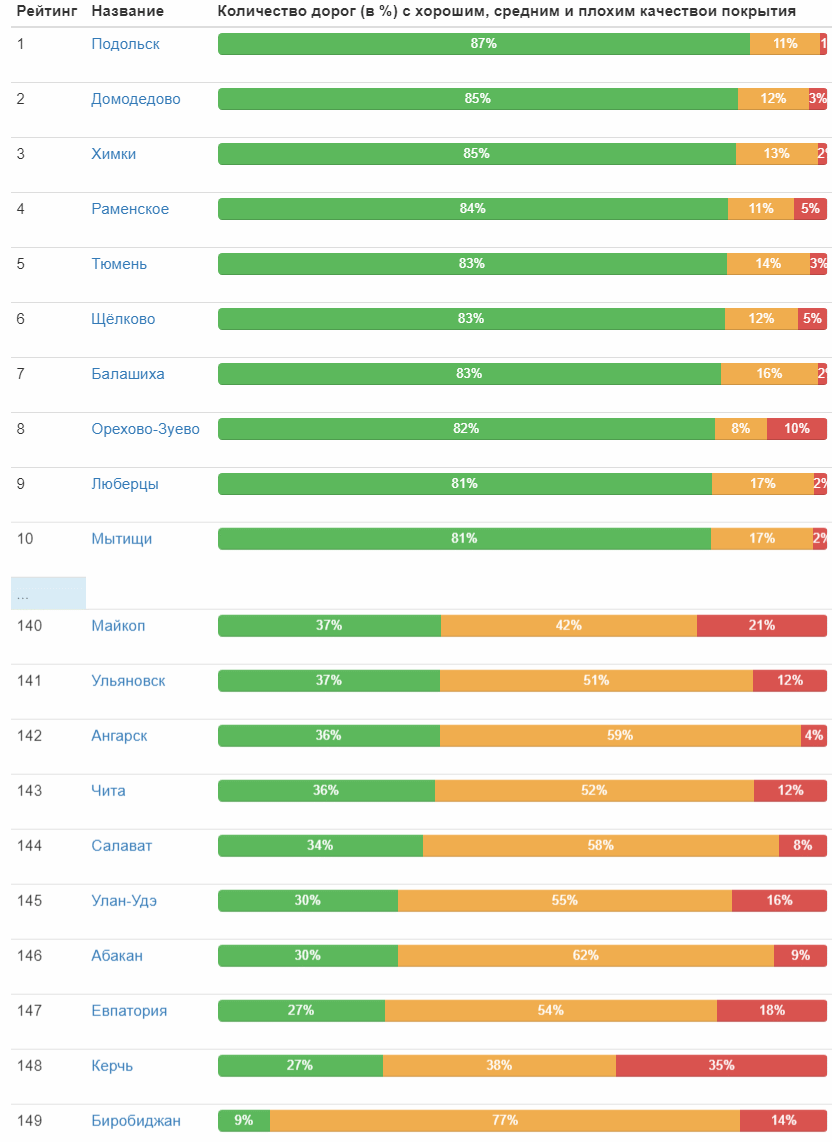
Полная таблица (картинка кликабельна)

А вот рейтинг качества дорог по субъектам федерации:
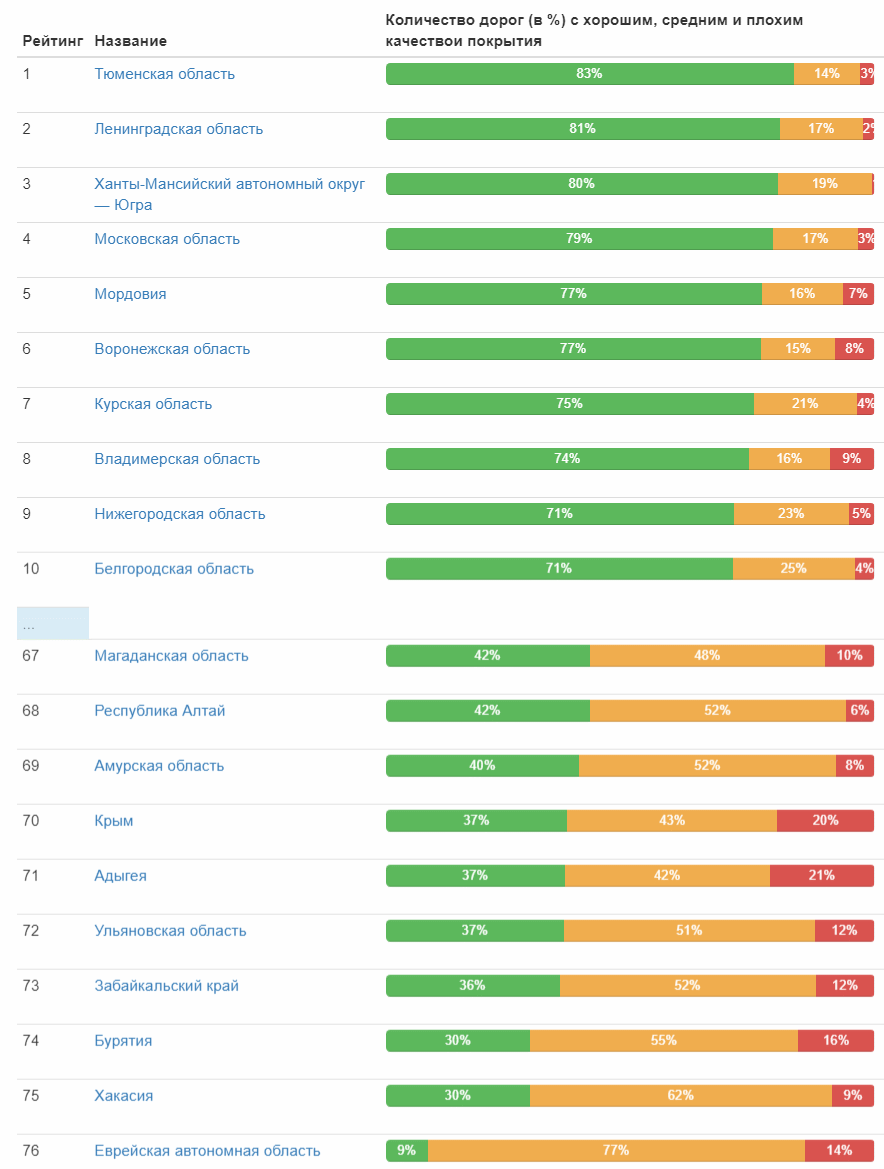
Полная таблица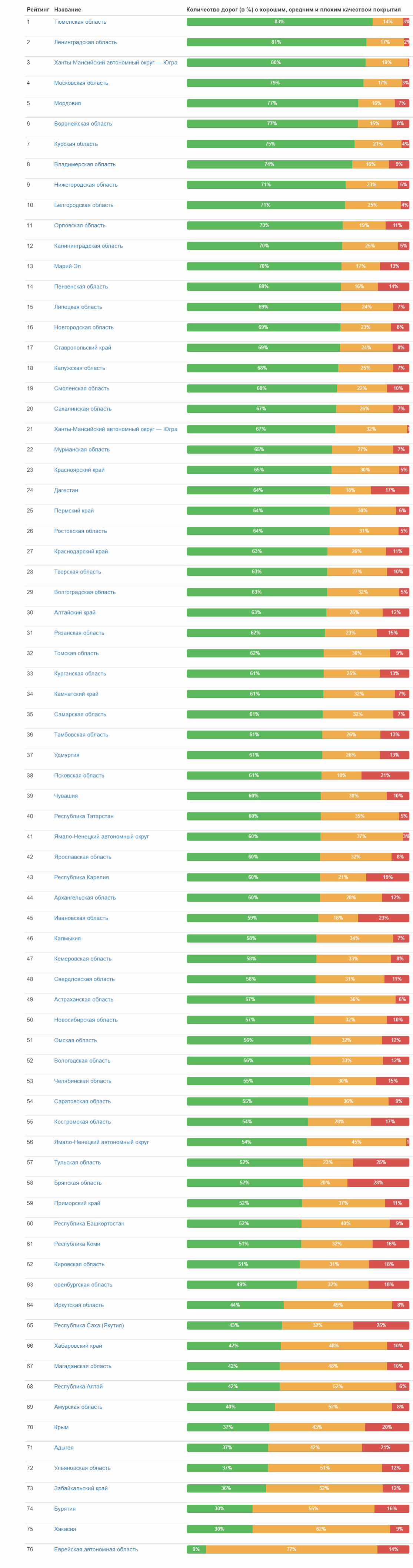
Рейтинг по федеральным округам:
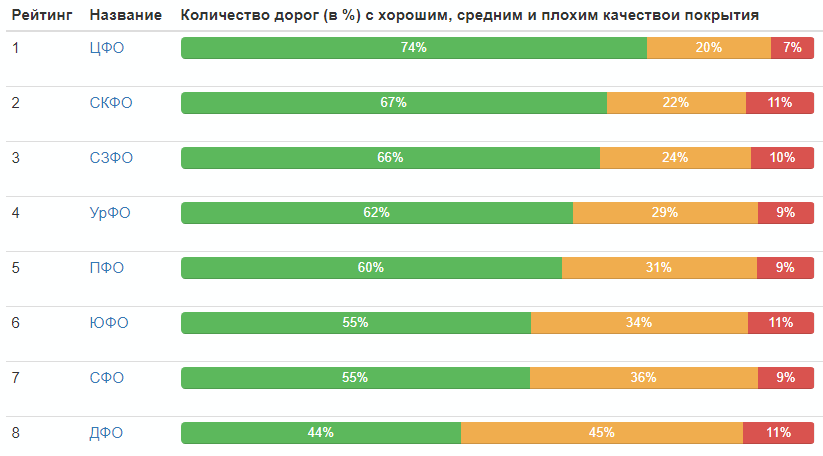
Распределение качества дорог по России в целом:

Ну, вот и все, выводы каждый может сделать сам.
Напоследок приведу лучшие фотографии в каждой категории (которые получили максимальное значение в своем классе):
Картинка
P.S. В комментариях совершенно справедливо указали на отсутствие статистики по годам получения фотографий. Исправляюсь и привожу таблицу:
Год |
Количество фотографий, шт |
| 2008 | 37 |
| 2009 | 13 |
| 2010 | 157030 |
| 2011 | 60724 |
| 2012 | 42387 |
| 2013 | 12148 |
| 2014 | 141021 |
| 2015 | 46143 |
| 2016 | 410385 |
| 2017 | 324279 |
| 2018 | 581961 |

