Необходимое вступление
Я не гарантирую, что изложенные здесь трактовки общепринятых терминов и принципов совпадают с тем, что изложили в солидных научных статьях калифорнийские профессора во второй половине прошлого века. Я не гарантирую, что мои трактовки полностью разделялись или разделяются большинством IT-профессионалов в отрасли или научной среде. Я даже не гарантирую, что мои трактовки помогут вам на собеседовании, хоть и предполагаю, что будут небесполезны.
Но я гарантирую, что если отсутствие всякого понимания заменить моими трактовками и начать их применять, то код вами написанный будет проще сопровождать и изменять. Так же я прекрасно понимаю, что в комментариях мной написанное будут яростно дополнять, что позволит выправить совсем уж вопиющие упущения и нестыковки.
Столь малые гарантии поднимают вопросы о причинах, по которым статья пишется. Я считаю, что этим вещам должны учить везде, где учат программированию, вплоть до уроков информатики в школах с углублённым её изучением. Тем не менее, для меня стала пугающе нормальной ситуация, когда я узнаю, что собеседник мой коллега, причём работающий уже не первый год, но про инкапсуляцию «что-то там слышал». Необходимость собрать всё это в одном месте и давать ссылку при возникновении вопросов зрела давно. А тут ещё и мой «pet-project» дал мне изрядно пищи для размышлений.
Тут мне могут возразить, что учить эти вещи в школе рановато, и вообще на ООП свет клином не сошёлся. Во-первых, это смотря как учить. Во-вторых, 70% материала этой статьи применимо не только к ООП. Что я буду отмечать отдельно.
ООП вкратце
Это, наверное, самый сложный для меня раздел. Но всё-таки надо установить базу и описать совсем вкратце, в чём самая суть ООП, чтобы было понятно, почему именно инкапсуляция, полиморфизм, наследование и принципы SOLID усилили её. И сделаю я это, рассказав о том, как вообще можно было до такого додуматься.
Началось с Дейкстры, который доказал, что любой алгоритм можно выразить через три способа выбора следующей команды: линейное выполнение (по порядку), ветвление по условию, выполнение цикла пока выполняется условие. С помощью этих трёх соединений можно сконструировать любой алгоритм. Более того, было рекомендовано писать программы, ограничиваясь линейным расположением команд друг за другом, ветвлением и циклами. Это было названо "процедурнымструктурным программированием" (за уточнение спасибо sshikov).
Так же здесь отметим, что последовательности команд необходимо объединять в подпрограммы и каждая подпрограмма может выполняться с помощью одной команды.
Кроме порядка действий для нас важно и то, над чем выполняются действия. А выполняются они над данными, которые стало принято хранить в переменных. В переменных хранятся данные. Интерпретируются они исходя из их типа. Очевидно до зубовного скрежета, но потерпите чуть-чуть, пожалуйста.
С самого начала сформировался более-менее общий набор примитивных типов данных. Целые числа, вещественные числа, булевы переменные, массивы, строки. Алгоритмы + структуры данных = программы, как завещал Никлаус Вирт.
Также с самого начала времён был в разных ипостасях такой тип данных как подпрограмма. Или кусочек кода, если хотите. Кто-то может сказать, что использование подпрограмм в качестве переменных — прерогатива функционального программирования. Даже если так, то возможность делать кусочек кода переменной есть даже в ассемблере. Пусть эта возможность и сводится к «ну, вот тебе номер байта в оперативной памяти, где эта подпрограмма живёт, а дальше команду CALL со стеком вызова в зубы и крутись, как умеешь».
Само собой, нескольких типов данных было мало и люди начали думать над тем, чтобы добавить в различные ЯП возможность создавать свои типы. Одной из вариаций такой возможности были так называемые записи. Ниже два примера записи на несуществующем языке программирования (далее NEPL — Non-Existing Programming Language):
type Name: record consisting of FirstName: String, MiddleName: String, LastName: String. type Point: record consisting of X: Double, Y: Double.
То есть, вместо того, чтобы таскать за собой две-три связанные по смыслу переменные, вы группируете их в одну структуру с поименованными полями. Потом вы объявляете переменную типа Name и обращаетесь к полю FirstName, например.
Что такого ценного в этой «усиленной» переменной для нашей темы? То, что отсюда остаётся только один шажок до ООП. Я не просто так выделил целый жирный абзац на то, чтобы обозначить, что в переменные можно помещать и кусочки кода. Смотрите же, как переменные превращаются в объекты:
type Name: class consisting of FirstName: String, MiddleName: String, LastName: String, GetFullName: subprogram with no parameters returns String. type Point: class consisting of X: Double, Y: Double, ScalarMultiply: subprogram with (Double) parameters returns Point.
N.B. NEPL активно развивается и уже заменил ключевое слово record на class.
То есть, мы можем обратиться к полю «GetFullName» и вызвать его. А переменная содержит в себе не только данные, описывающие её состояние, но и поведение. Таким образом, переменная обращается в объект, который обладает некоторыми умениями и состоянием. И мы уже работаем не просто с переменными, а с маленькими системами, которым можно отдавать команды.
В юности эта идея меня восхищала. Просто вдумайтесь, можно создать любой тип данных. И вы работаете не с какими-то цифрами, а с объектами создаваемого вами мира. Никаких мучений со скучными массивами или хитросплетёнными наборами цифр. Работаем напрямую с объектами типов Player, Enemy, Bullet, Boss! Да, мне в юности хотелось делать видеоигры.
В реальности всё оказалось не так просто. И без некоторых «усиливающих» идей ООП превратит жизнь программиста в ад. Но перед тем, как двинуться дальше, дадим ещё несколько терминов:
- «Усиленные» своим поведением типы данных в ООП называются классами.
- Переменные этих типов называются объектами.
- А подпрограммы, которые задают поведение объектов называют методами. Как правило, набор методов свой у каждого класса, а не у каждого объекта. Чтобы каждый объект определённого класса вёл себя как и другие объекты того же класса. Буду рад узнать из комментариев о языках, где дело обстоит иначе.
«Святая троица»
Так уж исторически сложилось, что об этих вещах спрашивают на собеседованиях. О них пишут в любом учебнике по ООП-языку. Почему? Потому что если спроектировать ООП-программу без всякой оглядки на инкапсуляцию и полиморфизм, то получим «гроб, гроб, кладбище, несопровождаемость». Наследование уже не столь строго обязательно, но эта концепция позволяет понять ООП лучше и является одним из основных инструментов при проектировании с использованием ООП.
Инкапсуляция
Ну что, давайте со старта определение с википедии: «упаковка данных и функций в единый компонент». Определение кажется ясным, но в то же время слишком обобщённым. Поэтому давайте поговорим о том, зачем это вообще надо, что нам это даст, и как именно надо упаковывать данные и функции в единый компонент.
Я уже писал статью, которая касалась инкапсуляции. И там меня справедливо попрекнули тем, что я свёл инкапсуляцию к сокрытию информации, а это несколько разные вещи. В частности, EngineerSpock выдал такую изящную формулировку, как защита инварианта. Свою ошибку признаю, и тут объясню почему я её совершил.
А пока моё, предварительное определение принципа инкапсуляции, или если хотите, процесса инкапсулирования, которое даёт описание не только принципа инкапсуляции, но и того, что с его помощью предполагается достичь:
Любая программная сущность, обладающая нетривиальным состоянием, должна быть превращена в замкнутую систему, которую можно только перевести из одного корректного состояния в другое.
Про ту часть, где «любая программная сущность, обладающая нетривиальным состоянием» давайте чуть позже. Пока речь будем вести исключительно об объектах. И о второй части моего определения. Зачем нам это?
Тут всё просто: то, что можно только перевести из одного корректного состояния в другое, нельзя сломать. То есть, нам надо сделать так, чтобы любой объект нельзя было сломать. Звучит, мягко говоря, амбициозно. Как же этого добиться?
В-нулевых, всё, что касается объекта, должно лежать в одном месте, внутри одной архитектурной границы, скажем так. На случай, если получилось очень заумно, повторю определение из википедии: «упаковка данных и функций в единый компонент».
Во-первых, чётко разделить интерфейс и его реализацию. Думаю, всем моим коллегам знакома абревиатура API. Так вот, у каждого объекта должно быть своё API, или PI, если уж быть дотошным. То, ради чего его создают, и то, чем другие будут пользоваться, что именно будут вызывать. Каким он должен быть? Таким, чтобы никому даже в голову не пришло лезть внутрь объекта и использовать его неподходящим образом. Но не более того.
В какой-то книге, увы, не помню в какой, это объяснялось на примере микроволновки. На ней есть кнопки. Ручки. Они позволяют разогреть еду. Вам не надо раскручивать микроволновку, и что-то там паять, чтобы разогреть вчерашний суп. У вас есть интерфейс, кнопки. Поставь тарелку, нажми пару кнопок, подожди минуту и будь счастлив.
Вот подумайте, какие кнопки пользователю вашего объекта надо нажать, и отделите их от внутренних потрохов. И ни в коем случае не добавляйте лишних кнопок! Это было во-первых.
Во-вторых, уважайте границу между интерфейсом и реализацией и заставляйте других её уважать. В принципе, эта мысль интуитивно понятна и витает среди народных мудростей во множестве форм. Взять хотя бы «если вы воспользовались чем-то недокументированным, а у вас потом что-то сломалось, сами виноваты». Думаю, с «не раскручивай микроволновку, пока она работает так, как тебе надо», всё понятно. Теперь о том, как заставить других уважать пресловутую границу.
Тут-то и приходит на помощь то самое сокрытие информации. Да, всегда можно договориться, попросить, установить code conventions, указывать на код-ревью, что так нельзя. Но сама возможность залезть за эту границу-то останется. Тут-то то самое сокрытие информации и приходит на помощь.
Мы не можем пересечь пресловутую границу, если наш код не может узнать о её существовании и о том, что за ней лежит. А даже если и узнает, то компилятор сделает вид, что такого поля или метода нет, а даже если и есть, то трогать его не положено, компилироваться я отказываюсь, и вообще кто вы такие, мы вас не звали, пользуйтесь интерфейсной частью.

Вот тут-то и вступают в игру всякие разные public, private и прочие модификаторы доступа из вашего любимого языка. То самое «сокрытие информации» является самым надёжным способом не пустить по ветру выгоды инкапсуляции. Как ни крути, нет смысла группировать всё, что касается одного класса, в одном месте, если код использует что захочет и откуда захочет. А вот с сокрытием информации такая ситуация уже не должна возникать в принципе. И способ этот настолько надёжный, что в сознании тысяч и тысяч программистов (включая меня, чего уж там) разница между инкапсуляцией и сокрытием информации как-то изглаживается.
Что делать, если ваш любимый ЯП не позволяет скрывать информацию вот вообще никак? На эту тему можно весело поперекидываться комментариями. Я же вижу, следующий выход. По нарастающей:
- Документировать только интерфейсную часть и считать, всё, что не документировано, реализацией.
- Отделять реализацию от интерфейса через code-convention (пример — в python есть переменная __all__, которая указывает, что именно будет импортировано из модуля, когда попросишь импортировать всё).
- Сделать эти самые code-conventions достаточно строгими, чтобы их можно было проверять автоматически, после чего любое их нарушение приравнять к ошибке компиляции и упавшему билду.
Ещё разок:
- Всё, что касается одного класса, пакуется в один модуль.
- Между классами проводятся строгие архитектурные границы.
- У любого класса отделяется интерфейсная часть от реализации этой самой интерфейсной части.
- Границы между классами надо уважать самому и заставлять их уважать других!
Закончу примером на NEPL, который всё ещё очень активно развивается и уже спустя десять абзацев обзавёлся модификаторами доступа:
type Microwave: class consisting of private fancyInnerChips: List of Chip, private foodWarmingThing: FoodWarmerController, private buttonsPanel: ButtonsPanel, public GetAccessToControlPanel: subprogram with no parameters returns ButtonsPanel, public OpenDoor: subprogram with no parameters returns nothing, public Put: subprogram with (Food) parameters return nothing, public CloseDoor: subprogram with no parameters returns nothing. type ButtonsPanel: class consisting of private buttons: List of ButtonState, public PressOn: subprogram with no parameters returns nothing, public PressOff: subprogram with no parameters returns nothing, public PressIncreaseTime: subprogram with no parameters returns nothing, public PressDecreaseTime: subprogram with no parameters returns nothing, public PressStart: subprogram with no parameters returns nothing, public PressStop: subprogram with no parameters returns nothing.
Я надеюсь, что из кода ясно, в чём суть примера. Уточню только один момент: GetAccessToControlPanel проверяет, можно ли нам вообще микроволновку трогать. А вдруг она сломана? Тогда нажимать ничего нельзя. Можно только получить сообщение об ошибке.
Ну и тот факт, что ButtonsPanel стало отдельным классом плавно подводит нас к важному вопросу: а что такое «единый компонент» из определения инкапсуляции по википедии? Где и как должны пролегать границы между классами? Мы обязательно вернёмся к этому вопросу чуть позже.
Использование за пределами ООП
Очень много программистов узнало об инкапсуляции из учебника по Java/C++/C#/подставьте ваш первый ООП-язык. Поэтому инкапсуляция в массовом сознании как-то связалась с ООП. Но давайте вернёмся к двум определениям инкапсуляции.
Упаковка данных и функций в единый компонент.
Любая программная сущность, обладающая нетривиальным состоянием, должна быть превращена в замкнутую систему, которую можно только перевести из одного корректного состояния в другое.
Заметили? Там вообще ничего о классах и объектах!
Итак, пример. Вы DBA. Ваша работа — присматривать за какой-то реляционной базой данных. Пускай она будет, например, на MySQL. Вашей драгоценной базой данных пользуется несколько программ. Над некоторыми из них вы не имеете контроля. Что делать?
Создаём набор хранимых процедур. Компонуем их в одну схему, которую назовём interface. Создаём для наших программ по одному пользователю без всяких прав. Это команда CREATE USER. Затем с помощью команды GRANT даёт пользователям только право на выполнение этих хранимых процедур из схемы interface.
Всё. У нас есть база данных, та самая программная сущность с нетривиальным состоянием, которую сломать достаточно легко. И мы, чтобы её не ломали, создаём интерфейс из хранимых процедур. И после средствами самого MySQL делаем так, чтобы сторонние сущности могли использовать только этот интерфейс.
Заметьте, пресловутая инкапсуляция, как она есть, и как она описывалась, используется во весь рост. А ведь между реляционным представлением данных и объектами пропасть такая, что её приходится закрывать громоздкими ORM-фреймворками.
Именно поэтому в определении инкапсуляции не фигурируют классы и объекты. Идея куда шире, чем ООП. И она приносит слишком много пользы, чтобы говорить в ней только в учебниках по ООП-языкам.
Полиморфизм
Полиморфизм имеет много форм и определений. Достаточно, чтобы меня хватил Кондратий, когда я открыл википедию. Здесь я буду говорить о полиморфизме, как его сформулировал Страуструп: один интерфейс — множество реализаций.
В таком виде идея полиморфизма может очень сильно усилить позиции пишущих программы с оглядкой на инкапсуляции. Ведь если мы отделилили интерфейс от реализации, то тому, кто пользуется интерфейсом необязательно знать о том, что в реализации что-то поменялось. Тому, кто пользуется интерфейсом (в идеале) необязательно даже знать о том, что реализация вообще поменялась! И это открывает безграничные возможности для расширения и модификации. Ваш предшественник решил, что еду лучше всего греть военным радаром? Если этот безумный гений отделил интерфейс от реализации и чётко его формализовал, то военный радар можно приспособить под иные нужды, а его интерфейс для разогрева еды реализовать с помощью микроволновки.
NEPL стремительно развивается и под влиянием C# обзаводится (осторожно, не споткнитесь об формулировку) таким типом типов данных, как интерфейс.
type FoodWarmer: interface consisting of GetAccessToControlPanel: no parameters returns FoodWarmerControlPanel, OpenDoor: no parameters returns nothing, Put: have (Food) parameters returns nothing, CloseDoor: no parameters returns nothing. type FoodWarmerControlPanel: interface consisting of PressOn: no parameters returns nothing, PressOff: no parameters returns nothing, PressIncreaseTime: no parameters returns nothing, PressDecreaseTime: no parameters returns nothing, PressStart: no parameters returns nothing, PressStop: no parameters returns nothing. type EnemyFinder: interface consisting of FindEnemies: no parameters returns List of Enemy. type Radar: class implementing FoodWarmer, EnemyFinder and consisting of private secretMilitaryChips: List of Chip, private giantMicrowavesGenerator: FoodWarmerController, private strangeControlPanel: AlarmClock, public GetAccessToControlPanel: subprogram with no parameters returns FoodWarmerControlPanel, public OpenDoor: subprogram with no parameters returns nothing, public Put: subprogram with (Food) parameters return nothing, public CloseDoor: subprogram with no parameters returns nothing, public FindEnemies: subprogram with no parameters returns List of Enemy. type AlarmClock: class implementing FoodWarmerControlPanel and consisting of private mechanics: List of MechanicPart, public PressOn: subprogram with no parameters returns nothing, public PressOff: subprogram with no parameters returns nothing, public PressIncreaseTime: subprogram with no parameters returns nothing, public PressDecreaseTime: subprogram with no parameters returns nothing, public PressStart: subprogram with no parameters returns nothing, public PressStop: subprogram with no parameters returns nothing. type Microwave: class implementing FoodWarmer and consisting of private fancyInnerChips: List of Chip, private foodWarmingThing: FoodWarmerController, private buttonsPanel: ButtonsPanel, public GetAccessToControlPanel: subprogram with no parameters returns FoodWarmerControlPanel, public OpenDoor: subprogram with no parameters returns nothing, public Put: subprogram with (Food) parameters return nothing, public CloseDoor: subprogram with no parameters returns nothing. type ButtonsPanel: class implementing FoodWarmerControlPanel and consisting of private buttons: List of ButtonState, public PressOn: subprogram with no parameters returns nothing, public PressOff: subprogram with no parameters returns nothing, public PressIncreaseTime: subprogram with no parameters returns nothing, public PressDecreaseTime: subprogram with no parameters returns nothing, public PressStart: subprogram with no parameters returns nothing, public PressStop: subprogram with no parameters returns nothing.
Итак, если класс объявлен, как реализующий интерфейс, то он обязан реализовать все методы из этого интерфейса. Иначе компилятор скажет нам «фи». И у нас есть два интерфейса: FoodWarmer и FoodWarmerControlPanel. Посмотрите на них внимательно, а потом давайте разберём реализации.
В наследство от тяжкого советского прошлого мы получили класс двойного назначения Radar, которым можно и еду разогреть, и врага найти. А вместо панели управления используется будильник, потому что план перевыполнен, а их надо куда-то девать. Но, к счастью, безымянный МНС из НИИ Химии, Удобрений и Ядов, на которого это спихнули, реализовал интерфейсы FoodWarmer для радара и FoodWarmerControlPanel для будильника.
Спустя поколение кому-то пришло в голову, что еду лучше греть микроволновкой, а управлять микроволновкой лучше кнопочками. И вот созданные классы Microwave и ButtonsPanel. И они реализуют те же интерфейсы. FoodWarmer и FoodWarmerControl. Что нам это даёт?
Если мы везде в своём коде использовали для разогрева еды переменную типа FoodWarmer, то мы можем просто заменить реализацию на более современную, и никто ничего не заметит. То есть, коду, использующему интерфейс нет никакого дела до деталей реализации. Или до того факта, что она поменялась целиком и полностью. Мы можем даже сделать класс FoodWarmerFactory, который выдаёт разные реализации FoodWarmer в зависимости от конфигурации вашего приложения.
Ещё посмотрите на закрытые поля в класс Microwave и Radar. Там у нас будильник и панель с кнопочками. Но наружу мы отдаём переменную типа FoodWarmerControlPanel.
Где-то на Пикабу была история о том, как некий кандидат объяснял принцип полиморфизма следующим образом:
Вот у меня есть ручка. Я могу ей написать свое имя, а могу воткнуть ее вам в глаз. Это и есть принцип полиморфизма.Картинка смешная, ситуация страшная, а объяснение принципа полиморфизма никудышное.
Принцип полиморфизма не в том, что класс ручки с какого-то перепугу реализует интерфейсы канцелярского изделия и холодного оружия одновременно. Принцип полиморфизма в том, что всё, что может колоть, можно воткнуть в глаз. Потому что этим можно колоть. И результат будет отличаться, но в идеале должен выдавать лишение зрения. И метод полиморфизма позволяет отразить этот факт в модели, которую вы строите для своего мира.
Использование за пределами ООП
Есть такой весёлый и забавный во всех смыслах этих слов язык как Erlang. И в нём есть такая фича как behaviour. Следите за руками:
Код там делится на модули. В качестве переменной можно использовать имя модуля. То есть, можно написать вызов функции из модуля так:
%option 1 foobar:function(), %option 2 Module = foobar, Module:function().
Для того, чтобы быть уверенным в том, что модуль имеет определённые функции, есть такая фича языка, как behaviour. В модуле, который использует другие модули, вы задаёте с помощью декларации behaviour_info требования к модулям-переменным. А потом модули, который ваш батька-модуль, задавший behaviour_info, будет использовать, с помощью декларации behaviour говорят компилятору: «мы обязуемся реализовать это поведение, чтобы батька-модуль мог нас использовать».
Например, модуль gen_server позволяет создать сервер, который синхронно или асинхронно в отдельном процессе (в Erlang нет никаких потоков, только тысячи маленьких параллельных процессов), выполняет запросы других процессов. И в gen_server собрана вся логика, касающаяся запросов других процессов. А вот непосредственно обработка этих запросов делается теми, кто реализует поведение gen_server. И пока другие модули его реализуют правильно (пусть там и пустые заглушки), gen_server-у вообще плевать, как эти запросы обрабатываются. Более того, обрабатывающий модуль можно сменить «на лету».
Один интефейс — множество реализаций. Как Страуструп нам завещал. Как пишется в умных книжках по ООП. А теперь цитата из википедии в студию:
Erlang — функциональный язык программирования с сильной динамической типизацией, предназначенный для создания распределённых вычислительных систем.
Просто идея «один интерфейс — множество реализаций» слишком красивая и базовая, скажем так, чтобы ограничить её применение исключительно ООП.
Пример номер два. Есть такой фреймворк .NET. И он позволяет взаимодействовать множеству программ на разных языках между собой. За это отвечает CLR. И этот самый CLR Microsoft не стали запирать на миллиард юридических замков, а описали, что оно должно уметь, в достаточно суровом техническом стандарте (гуглить ECMA-335).
.NET и программы, на нём написанные работали на Windows, Windows Phone, XBox (гуглить XNA, и всё, что с ним связано), на любой платформе. Если её держит Microsoft. Но так как есть открытый стандарт, есть интерфейс, там описанный. то нашлись люди, которые его реализовали в виде Mono Project. Их реализация работала на линуксах и позволяла запускать программы на .NET. на линуксе.
Казалось бы, на этом всё. Но потом ребята из Microsoft решили, что тоже хотят сделать .NET для линукса. И сделали. С открытым кодом, оптимизированный по самое не могу, весь из себя красивый .NET Core. И в будущем, этот самый .NET Core станет пятой версией .NET Framework, а всё древнее легаси, которое писалось, начиная с начала нулевых отправится в утиль. Да, пример с новой микроволновкой в реальной жизни.
Я описал тут эту ситуацию, потому что это выход идеи «один интерфейс — множество реализаций» на какой-то космический уровень. Полиморфизм в масштабе целой программной платформы, откуда объекты и классы даже в телескоп не видны.
Наследование
Красивая концепция, которая позволяет объединить переиспользование кода и силу полиморфизма. Но, само собой, это не панацея, а один из инструментов. Не всегда уместный, но иногда весьма и весьма полезный.
Суть в том, что можно создать новый класс на основе уже существующего и дополнить его, или частично изменить его поведение. Окей, мне тяжело дальше двигаться без примера, поэтому продолжим развивать NEPL. Сначала возникшая проблема. Помните класс Name? Вот улучшенная версия, которая сообщает нам имя в вежливой форме. Класс EtiquetteInfo находится где-то в другом месте.
import class EtiquetteInfo from Diplomacy. type PoliteName: class consisting of private FirstName: String, private MiddleName: String, private LastName: String, for descendants GetPoliteFirstName: subprogram with (EtiquetteInfo) parameters returns String, for descendants GetPoliteMiddleName: subprogram with (EtiquetteInfo) parameters returns String, for descendants GetPoliteLastName: subprogram with (EtiquetteInfo) parameters returns String, public GetFullName: subprogram with (EtiquetteInfo) parameters returns String. subprogram GetPoliteFirstName.PoliteName with (EtiquetteInfo _EtiquetteInfo) parameters returning String implemented as return _EtiquetteInfo.PoliteFirstName(FirstName). subprogram GetPoliteMiddleName.PoliteName with (EtiquetteInfo _EtiquetteInfo) parameters returning String implemented as return _EtiquetteInfo.PoliteMiddleName(MiddleName). subprogram GetPoliteLastName with (EtiquetteInfo _EtiquetteInfo) parameters returning String implemented as return _EtiquetteInfo.PoliteLastName(LastName). subprogram GetFullName with (EtiquetteInfo _EtiquetteInfo) parameters returning String implemented as return GetPoliteFirstName(_EtiquetteInfo) + GetPoliteMiddleName(_EtiquetteInfo) + GetPoliteLastName(_EtiquetteInfo).
Допустим, в методе GetFullName у нас была какая-то достаточно сложная логика, касающаяся обработки имени (сделаем вид, что она сложная, хорошо?). Мы пользовались этим классом, были сравнительно счастливы, но потом у нас случился клиент из каких-то дальних краёв. Где с именами всё, мягко говоря, сложно. Есть те же имя и фамилия, к ним применяются те же, назовём их так, модификаторы вежливости, но вот добавочных имён там может быть много. Возможно, даже очень много. Наш класс PoliteName становится неудобным. Написать отдельный класс ExoticPoliteName с общим интерфейсом — это создавать кучу повторяющегося кода. То, сколько приносит это боли и страданий при сопровождении, я тут рассказывать не буду.
Тут-то наследование и вступает в игру. Мы создаём класс ExoticPoliteName, который расширяет класс PoliteName, и использует его реализацию. Ниже реализация класса PoliteExoticName. Будем считать, что он в одном модуле с PoliteName.
import class EtiquetteInfo from Diplomacy. type PoliteExoticName: class extending PoliteName and consisting of private MoreMiddleNames: List of String, for descendants overridden GetPoliteMiddleName: subprogram with (EtiquetteInfo) parameters returns String, public overriden GetFullName: subprogram with (EtiquetteInfo) parameters returns String. subprogram GetPoliteMiddleName.PoliteExoticName with (EtiquetteInfo _EtiquetteInfo) parameters returning String implemented as String AggregatedMiddleName = String.Join(" ", MoreMiddleNames), return base.GetPoliteMiddleName(_EtiquetteInfo + AggregatedMiddleName). subprogram GetFullName with (EtiquetteInfo _EtiquetteInfo) parameters returning String implemented as String Prefix = "", String FirstName = GetFirstName(_EtiquetteInfo), if _EtiquetteInfo.ComplimentIsAppropriate(FirstName) then Prefix = "Oh, joy of my heart, dear ", return Prefix + base.GetFullName(_EtiquetteInfo).
На всякий случай: класс PoliteName в отношении наследования называется базовым. А класс PoliteExoticName является классом-наследником.
Переиспользование кода у нас проявляется в том, что мы используем логику из базового класса там, где не задано никакой логики в классе наследнике. То есть, нам не надо писать заново методы GetPoliteFirstName и GetPoliteLastName. Они у нас уже есть. И когда мы хотим добавить немножко логики к методу GetFullName, мы её добавляем, а не воссоздаём заново.
Полиморфность наследования же в том, что мы можем там, где от нас просят класс PoliteName, дать объект типа PoliteExoticName, и спокойно дёрнуть метод GetFullName. Компилятор поймёт, что нам подсунули наследника PoliteName, и посмотрит, нет ли у него своей реализации этого метода. Обратите внимание, внутри реализации на такую конструкцию, как base.GetFullName(etiquetteInfo). Это означает, что мы вызываем реализацию этого метода из базового класса, чтобы не дублировать логику оттуда.
Тут надо сказать, что между базовым классом и его наследником таким образом устанавливается отношение "является". Вежливое имя остаётся вежливым именем, даже если оно экзотическое. Классический пример: квадрат является фигурой, как и круг. И их можно нарисовать. Но по разному.
ООП считается настоящим, если всё в программе является объектом. Вообще всё. Да, переменная типа Boolean, которой хватает для существования одного бита, тоже. Наследование позволяет нам зафиксировать это в языке, сделав все классы наследниками одного класса Object. Во многих языках это наследование неявно. То есть, если вы не укажете, от какого класса вы наследуетесь, то компилятор решит, что от Object, и разрешит вызывать его методы.
Давайте будем считать, что в NEPL такая система тоже действует. Тогда класс PoliteName является наследником класса Object, а PoliteExoticName являетя наследником класса PoliteName и наследником класса Object одновременно. Это значит, что эти строчки на NEPL допустимы:
subprogram Foo.Bar with no parameters returning nothing implemented as PoliteExoticName _PoliteExoticName = GetSomePoliteExoticName(), PoliteName _PoliteName = _PoliteExoticName, Object _Object = _PoliteExoticName.
Мы не можем, правда, после этого написать _Object.GetFullName, так как там может быть всё, что угодно. Но если PoliteName или PoliteExoticName переопределит что-то из интерфейса класса Object, и мы потом дёрнем это что-то у переменной _Object, компилятор сначала начнёт искать реализацию этого метода у наследников.
К чему я это подводил? К тому, что наследование может быть многоуровневым. И число уровней ограничивается только здравым смыслом. Который обычно подсказывает, что если три уровня (не считая неявный Object) вам ещё простят, то за четыре-пять уже могут побить после код-ревью.
Ну, и естественно, от одного класса может отнаследоваться несколько классов, что даёт нам уже не просто цепочку, а дерево наследования. А что может пойти не так с деревом наследования? То, что от одного класса зависит множество. И если мы в базовом классе что-то сломаем или изменим, это повлияет на всех. Это известно как проблема хрупких базовых классов. Из-за этого иногда говорят, что наследование нарушает инкапсуляцию.
Так ли это? Мне кажется, что не совсем. Наследование добавляет соблазна и делает разрушение архитектурных границ лёгким и незаметным. Но наследование не обязательно нарушает инкапсуляцию. Главное помнить, что несмотря на отношение «является» между базовым классом и его наследником, между ними должна пролегать архитектурная граница. Что я имею в виду?
Что даже наследникам не положено копаться в потрохах базового класса без всяких ограничений. Обратите внимание на то, что в NEPL появился новый модификатор доступа for descendants.
type PoliteName: class consisting of private FirstName: String, private MiddleName: String, private LastName: String, for descendants GetPoliteFirstName: subprogram with (EtiquetteInfo) parameters returns String, for descendants GetPoliteMiddleName: subprogram with (EtiquetteInfo) parameters returns String, for descendants GetPoliteLastName: subprogram with (EtiquetteInfo) parameters returns String, public GetFullName: subprogram with (EtiquetteInfo) parameters returns String.
Если класс PoliteExoticName попытается получить доступ к переменной FirstName, компилятор скажет «нельзя, эта переменная слишком важная, и от правильного доступа к ней зависит работоспособность класса, не трогай, пожалуйста». А вот метод GetPoliteFirstName создан специально для защищённого доступа к FirstName.
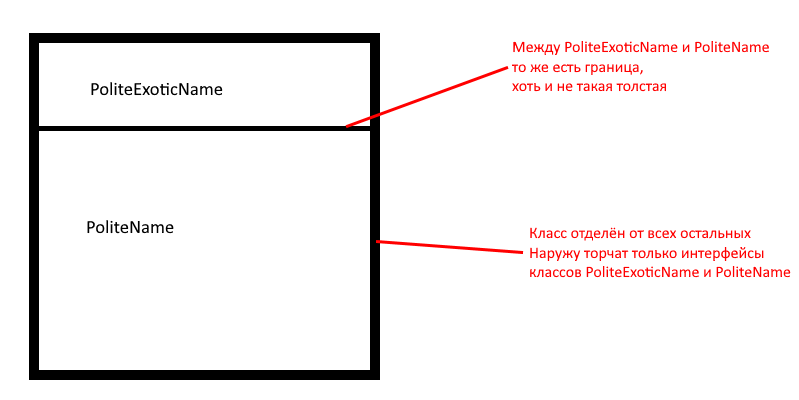
Да, кажется разумным, что если Square это Shape, то и полный доступ к Shape для Square проблемой не будет. Пока оба этих класса просты, не будет. Но как только Shape станет достаточно сложным, то есть станет программной сущностью с нетривиальным состоянием, его придётся отделить от остальных классов. Даже от Square, который дополняет класс Shape. Зачем? Чтобы он дополнял, а не изменял класс Shape, то есть не мог просто так его сломать.
Тут может возникнуть вопрос. Если забор слишком высок, то в использовании наследования смысла будет мало? Во-первых, высота забора между базовым классом и не наследниками будет ещё больше. Во-вторых, да, действительно мало, и возможно, наследование в этом случае использовать не стоит. Сформированное эмпирически правило гласит, что если можно переиспользовать код без наследования, то лучше так и сделать.
Наследование следует использовать только тогда, когда оно делает вашу программу проще. Это случается не слишком часто, если честно. Почему тогда наследование является одним из «трёх китов»? Потому что там где оно применимо, оно очень сильно упростит вашу программную систему. Но с большой силой приходит и большая ответственность. В нашем случае, большой гемморой при неправильном использовании.
Напоследок буквально пара абзацев о множественном наследовании. Так называется практика, когда у нас несколько базовых классов. В реализации нескольких интерфейсов, где не предполагается никакого поведения по умолчанию, никаких проблем нет. Там мы имеем просто набор контрактов без заданной реализации. И даже если они пересекутся, проблем будет мало. В крайнем случае, в язык добавляется конструкция, которая позволяет сделать две реализации одного и того же метода для двух разных интерфейсов.
Но когда мы наследуемся от нескольких классов, то дело резко осложняется тем, что дерево наследования превращается в полноценный граф. И искать в нём правильную реализацию того или иного метода становится очень тяжело. Если с деревом всё однозначно (двигаемся к корню, пока не найдём реализацию), то с графом, включающим множественное наследование становятся возможны разные варианты. Несколько корней, и не вполне понятно, куда надо двигаться. Плюс к тому, если наследование реализовано через вложение объектов друг в друга, повторяющиеся базовые классы добавляют неприятных вопросов. Просто погуглите про ромбовидное наследование.
Я не буду в это углубляться дальше потому, что а) статья и так уже разрослась, б) множественное наследование редко позволяет упрощать программы, так что если вы решите, что оно вам здесь не нужно, в 999 случаях из 1000 не ошибётесь. О том, насколько этот инструмент полезен красноречиво говорит тот факт, что во многих ЯП множественное наследование запрещено.
(Не)использование за пределами ООП
Если инкапсуляция и полиморфизм не предполагают наличия объектов и классов, то концепция наследования вертится именно вокруг них. Я бы мог притянуть что-нибудь похожее за уши, но не буду этого делать. Просто скажу, что наследование крутится вокруг объектов и классов, а потому пытаться найти его за пределами ООП смысла мало. Но если у вас вдруг есть какие-то примеры, делитесь в комментариях.
SOLID
Три кита — это хорошо, но иногда не вполне понятно, как их использовать. Где-то в начале нулевых Роберт Мартин собрал пять принципов проектирования ООП в красивую абревиатуру. SOLID — это такая своеобразная инструкция по использованию трёх китов, призванная объяснить, как с их помощью делать ваши программы… Твёрдыми? Солидными? Ладно, скажем так, сопровождаемыми.
S — The Single Responsibility Principle
Принцип единственной ответственности можно считать этакой инструкцией к инкапсуляции. Давайте на секундочку вернёмся к её определению.
Упаковка данных и функций в единый компонент.
Остался без ответа вопрос как много данных и функций должно входить в этот самый единый компонент. И как их отделять друг от друга. Уже само название принципа даёт некоторые подсказки.
Достаточно очевидно, что каждый «единый компонент» должен быть занят чем-то одним. Выполнять одну задачу. Но тогда встаёт в полный рост вопрос «что считать одной задачей?». Как вообще дробить то, что мы делаем, на задачи? Практика подарила нам иной подход.
Встречайте, SRP в формулировке Роберта Мартина:
У программной сущности должна быть только одна причина для изменения.
Почему именно причина для изменения, а не задача? Потому что главное в программировании — минимизировать сложность, уменьшать объём боли и страданий при разработке. А что является основным источником боли и страданий при разработке? Причины для изменений. И речь не только о внезапно падающем как снег на голову «эта фича нужна нам вчера». Речь о разработке вообще, в процессе которой вы постоянно меняете программу по определённым причинам. Вам повезло иметь чётко структурированные требования? Их можно легко рассматривать как набор причин для изменений.
Что будет, если класс имеет две причины для изменений? Возьмём пример пожёстче для большей наглядности. Класс, который запрашивает данные из БД и выводит их в определённом формате в .txt-файл. Так как всё внутри одного класса, вы пишете всё это вместе, спокойно мешая код работающий с БД, с кодом пишущим в .txt-файл. Проходит какое-то время, и появляется необходимость сменить БД. Вы рвёте волосы во всех возможных местах, перекапываете весь ваш класс, начинаете брать данные из другой БД и… У вас ломается вывод в .txt-файл. Почему? Ведь они никак не должны быть связаны. Тем не менее, у вас есть класс, который запрашивает данные из БД И выводит их в определённом формате в .txt-файл.
N.B. Если в описании маленькой программной сущности (класс или метод, например) фигурирует союз «И», это такой большой красный флаг с надписью «у тебя будут проблемы, если ты не перепроверишь этот кусок кода».

Теперь вернёмся назад во времени и сделаем немного по другому. Класс, который запрашивает данные из БД, и класс, который выводит их в определённом формате в .txt-файл. Прилетает такое же требование поменять БД. Собственно, нам нужно изменить один из наших двух классов. Мы всё так же чертыхаясь, перекапываем целый класс. Но! Во-первых, класс, который мы перекапываем уже намного меньше, чем в прошлый раз. Во-вторых, сломать вещи, которые не связаны с работой с БД теперь стало намного сложнее, так что изменения связанные с БД мы вносим в программу с куда меньшим страхом и трепетом.
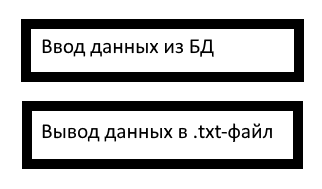
И тут, внезапно, ещё два требования. От нас хотят теперь, чтобы данные выводились а) в одном из двух форматов на выбор, б) в .html-файл. А в нашем втором классе такой плотный клубок, что если мы меняем формат, то ломается вывод в .txt/.html.
А теперь представьте, что перед тем, как садиться за эти классы мы подумаем и прикинем, что у нас могут измениться. Итак, нам надо брать данные из БД, и выводить их в определённом формате в .txt-файл. Что может пойти не так?
- БД. Мы не можем знать наверняка, подойдёт ли нам текущая. Даже если не изменится БД, может измениться библиотека, который мы загребаем данные. Как и ещё миллиард нюансов, связанных с БД, которые могут стать достаточно значимыми причинами, чтобы породить отдельный класс, метод, модуль, библиотеку и т. д.
- То, в каком формате нам нужны данные. 900 USD или 900.00$? 20190826T130000 или час дня двадцать шестого августа 2019 года? А не захотят ли от нас, чтобы эти моменты были настраиваемыми?
- Почему .txt-файл? Не лучше ли будет .csv? Нет, сейчас просят .txt. Но не попросят ли поменять через три дня? И обязательно один файл? Не сломается ли вывод на двух-трёх гигабайтах? А будут ли два-три гигабайта на продакшене? То есть, станут ли они причиной изменения?
Какой отсюда вывод? Один из самых нужных программисту навыков — умение предсказывать будущее. Но магию за пределами Хогвартса использовать запрещено, поэтому нам пришлось делегировать прорицание и телепатию бизнес-аналитикам.
А если серьёзно, то если подумать о том, как и почему меняется ваша программа, то удастся избежать многих проблем. И чем раньше вы об этом подумаете, тем больше проблем избежите.
DRY — Don't Repeat Yourself
Принцип единственной ответственности можно развернуть в другую сторону:
Если несколько программных сущностей изменяются вместе по одним и тем же причинам, то на самом деле это одна программная сущность. Объедините их немедленно.
Программной сущностью тут могут быть классы, методы, но чаще всего это несколько строчек, где вы повторяете логику из-за недосмотра или потому, что так проще. Если две одинаковые строчки меняются по разным причинам, то это вполне может быть совпадением, а не тупым копипастом.
Использование за пределами ООП
SRP применим не только к классам. Таким образом можно раздрабливать методы, модули, системы и подсистемы. Следует учитывать, что вместе с масштабом программной сущности меняется и масштаб понятия «причина для изменения». Причина для изменения, приводящая к разделению метода из десяти строк, и причина для изменения, приводящая к разделению двух подсистем на три — это две большие разницы.
Закончу ещё одним примером космического масштаба. На заре развития веба разметка HTML определяла структуру документа и его внешний вид. Возможно, у вас тут при виде союза «и» уже задёргался глаз. К сожалению, для разработчиков HTML в начале 90-х это было не очевидно. Тогда вообще мало кто представлял, во что это всё выльется. В какой-то момент стало ясно, что изменения структуры документа и изменения внешнего вида документа очень разные причины для изменения. Настолько разные, что для задания внешнего вида HTML-документов создали отдельный язык. И назвали его CSS.
Что это дало? Во-первых, CSS специально сделан так, чтобы сфокусироваться на задании «рюшечек» без возможности влезть в структуру документа. Окей, без удобной возможности влезть в структуру документа по крайней мере. Во-вторых, на один CSS-файл теперь можно сослаться во всех html-файлах по всему сайту, а не править какой-нибудь атрибут типа text-color по всем его вхождениям. Разные причины для изменения — разные языки. Разделение ответственности в самой радикальной форме.
O — The Open/Closed Principle
Мне тяжело дался этот раздел, потому что вещи, которые тут рассказываются слишком очевидны и слишком глубоко въедаются в подкорку любому, кто использует ООП не через пень-колоду хотя бы пару лет. Это как объяснять, что такое «слово» или «буква». Принцип открытости/закрытости отличается от остальной пятёрки тем, что не объясняет, как использовать инкапсуляцию и полиморфизм отдельно. Он накрывает всю «святую троицу» сразу. Смотрите сами:
Программные сущности должны быть открыты для расширения и закрыты для модификации.
Тут речь о программных сущностях начиная с класса и крупнее. Почему они должны быть закрыты для модификации мы уже выяснили, когда беседовали об инкапсуляции. Если один из использующих программную сущность бесконтрольно меняет её, то для остальных работа с этой программной сущностью становится непредсказуемой. А вот открытость для расширения возвращает то, что строгое соблюдение инкапсуляции может отнять у нас — гибкость.
Мы знаем, как закрыть программную сущность для модификации. Это делается с помощью всё той же инкапсуляции. Как открыть программную сущность для расширения? Здесь уже полиморфизм и наследование наши лучшие друзья. Давайте смотреть, как это делается.
- Чётко определить точки, где вы дадите расширять вашу программную сущность. Мы уже успели сойтись на том, что нельзя давать менять всё подряд. Тогда необходимо определить, что именно можно и/или нужно.
- Определиться с механизмами, которыми будете расширять программную сущность. На уровне классов это может быть базовый класс, доступный для наследования. Или поле/параметр метода/конструктора, куда вы положите объект с логикой расширяющей ваш класс. N.B. Тут всплывает старая добрая диллема наследование/композиция. Статья и так уже распухла по самое не могу, поэтому просто повторю: в любой непонятной ситуации делай выбор в пользу композиции.
- Если выбрали наследование, помните о проблеме хрупких базовых классов. Предок должен быть закрыт от наследников настолько, насколько это возможно.
- Если даёте возможность для расширения, выделив какую-то часть логики в отдельный объект, то раскрывайте расширяемому классу минимум информации о том, кто его расширяет. В идеале только контракт(ы), который(е) наш «расширитель» умеет выполнять.
- Определитесь с реализацией по умолчанию. Какое поведение должно быть в точке расширения, если не указано, чем надо расширяться? Возможно, никакого. Возможно, вам стоит заставить пользователя вашей программной сущности задать её поведение в этой точке. Некоторые языки имеют механизм абстрактных классов, которые изначально неполны и требуют для использования создания наследников и заполнения недостающих точек.
Думаю, здесь уже нужен пример. Сравните.
Плохо
type SpellChecker: class consisting of public DoSpellCheck: subprogram with (String) parameters returns String. type CorporativeStyleChecker: class consisting of public DoCorporativeStyleCheck: subprogram with (String) parameters returns String. type TextProcessor: class consisting of private Text: String, private SpellChecker: SpellChecker, private CorporativeStyleChecker: CorporativeStyleChecker, public Process: subprogram with no parameters returns String. subprogram TextProcessor.Process with no parameters returning String implemented as String ProcessedText = Text, ProcessedText = SpellChecker.DoSpellCheck(ProcessedText), ProcessedText = CorporativeStyleChecker.DoCorporativeStyleCheck(ProcessedText), return ProcessedText.
Чуть лучше, но всё ещё плохо
type TextChecker: interface consisting of Check: have (String) parameters returns String. type SpellChecker: class implementing TextChecker and consisting of public Check: subprogram with (String) parameters returns String. type CorporativeStyleChecker: class implementing TextChecker and consisting of public Check: subprogram with (String) parameters returns String. type TextProcessor: class consisting of private Text: String, private SpellChecker: SpellChecker, private CorporativeStyleChecker: CorporativeStyleChecker, public Process: subprogram with no parameters returns String. subprogram TextProcessor.Process with no parameters returning String implemented as String ProcessedText = Text, List of SpellChecker Checkers = (SpellChecker, CorporativeStyleChecker), for each SpellChecker SpellChecker in Checkers do ProcessedText = SpellChecker.Check(ProcessedText) and nothing else, return ProcessedText.
А вот здесь уже O/CP уже соблюдается. Я опустил реализацию TextCheckersSupplier, но суть должна быть понятна и без неё.
type TextChecker: interface consisting of Check: have (String) parameters returns String. type SpellChecker: class implementing TextChecker and consisting of public Check: subprogram with (String) parameters returns String. type CorporativeStyleChecker: class implementing TextChecker and consisting of public Check: subprogram with (String) parameters returns String. type TextCheckersSupplier: class consisting of public GetCheckers: subprogram with no parameters returns List of TextChecker. type TextProcessor: class consisting of private Text: String, private CheckersSupplier: TextCheckersSupplier, public Process: subprogram with no parameters returns String. subprogram TextProcessor.Process with no parameters returning String implemented as String ProcessedText = Text, List of SpellChecker Checkers = CheckersSupplier.GetCheckers(), for each SpellChecker SpellChecker in Checkers do ProcessedText = SpellChecker.Check(ProcessedText) and nothing else, return ProcessedText.
Чем третья версия отличается от первой и от второй? То, что мы теперь можем проверять текст любым способом, каким нам захочется, а не двумя жёстко зафиксированными. И мы можем добавлять эти способы, не тронув ни единого бита в TextProcessor. Кстати, TextCheckerSupplier в настоящей системе, скорее всего, тоже станет абстракцией. Чтобы менять способ доставки наших TextChecker'ов безболезненно. Сначала захардкодить два стандартных чекера, потом загружать их согласно конфигурации системы, потом загружать из сторонних библиотек, которые называются плагинами. Или модами, если вы делаете видеоигру.
Использование за пределами ООП
Перечитайте ту часть, где я рассказываю о том, как расширять программные сущности, исключив оттуда те части, которые касаются наследования. Работает и для более крупных сущностей.
L — The Liskov Substitute Principle
Ну что, давайте сразу формулировку Роберта Мартина:
Функции, которые используют базовый тип, должны иметь возможность использовать подтипы базового типа, не зная об этом.
Без соответствия этому принципу наследование становится хуже, чем бесполезным, оно наносит вред. Зачем мы используем наследование?
- Переиспользование кода
- Мощь полиморфизма
- Чтобы нашу программу было проще понимать и читать
А теперь вернёмся чуть-чуть назад и вспомним эти строчки на NEPL:
type PoliteExoticName: class extending PoliteName and consisting of... subprogram Foo.Bar with no parameters returning nothing implemented as PoliteExoticName _PoliteExoticName = GetSomePoliteExoticName(), PoliteName _PoliteName = _PoliteExoticName, Object _Object = _PoliteExoticName.
Допустим, переменная _PoliteName передаётся куда-то дальше. И тот, кто её использует понятия не имеет о том, какая разновидность вежливого имени используется. Экзотическая, или не экзотическая. У него просто есть переменная типа PoliteName, которая позволяет нам работать с вежливыми именами всех возможных вариаций. И мы, естественно, ждём, что код работающий с PoliteName не будет нам преподносить сюрпризов. Так вот, суть принципа подстановки Лисков в том, чтобы наследники вашего класса могли использоваться везде, где используется базовый класс. Без всяких неожиданностей.
Кстати, ещё одна формулировка с помощью юнит-тестов, за которую спасибо пользователю allex (не пугайся, я просто нашёл твой комментарий девятилетней давности). Формулировка, по сравнению с оригиналом, немного упрощена:
Если базовый класс проходит определённый юнит-тест, то его должны проходить все наследники базового класса тоже.
А сейчас пример, который я подсмотрел у Роберта Мартина книге «Agile Principles, Patterns and Practices in C#». Но на NEPL, в котором появилась операция приведения типов.
Object _Object = GetObjectSomewhere(), PoliteExoticName IHopeItsActuallyName = _Object as PoliteExoticName,
Итак, было у Роберта Мартина два класса, которые позволяли в себе хранить множества. Но работали они по разному внутри. Оба позволяли добавлять объект в множество, удалять его и проверять наличие. Но производительность этих операций различалась из-за того, как они работали изнутри. То есть, использовать имело смысл оба. Но озадачивать весь код выбором между двумя было бы глупо и непрактично. Поэтому разницу между ними Мартин спрятал за такой вот иерархией классов (у нас новая фича в языке, alias для классов, импортируемых из других модулей):
from UnboundedCollections import UnboundedSet as ThirdPartyUnboundedSet. from BoundedCollections import BoundedSet as ThirdPartBoundedSet. type Set: interface consisting of Add: have (Object) parameters returns nothing, Delete: have (Object) parameters returns nothing, IsMember: have (Object) parameters returns Boolean. type UnboundedSet: class implementing Set and consisting of private ThirdPartySet: ThirdPartyUnboundedSet, public Add: subprogram with (Object) parameters returning nothing, public Delete: subprogram with (Object) parameters returning nothing, public IsMember: subprogram with (Object) parameters returning Boolean. type BoundedSet: class implementing Set and consisting of private ThirdPartySet: ThirdPartyBoundedSet, public Add: subprogram with (Object) parameters returning nothing, public Delete: subprogram with (Object) parameters returning nothing, public IsMember: subprogram with (Object) parameters returning Boolean. subprogram BoundedSet.Add with (Object O) parameters returning nothing implemented as ThirdPartSet.Add(O).
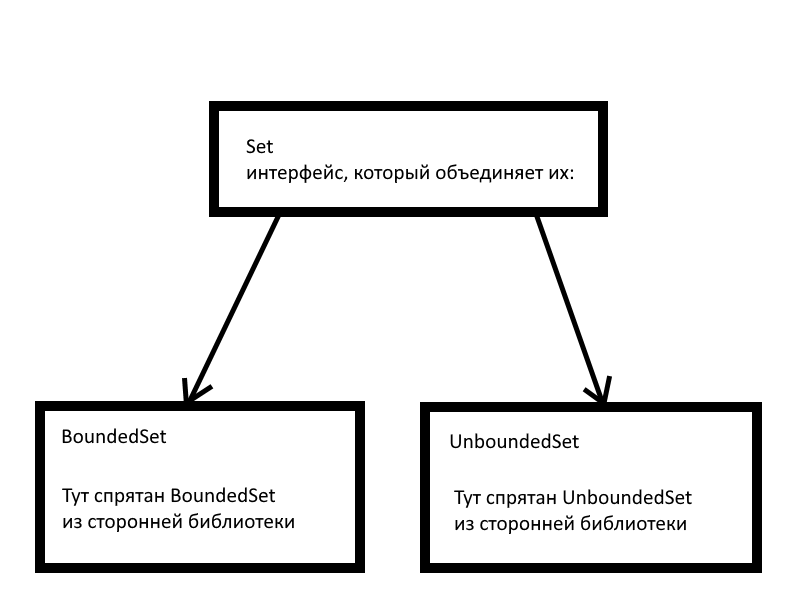
Опустим реализацию других методов. Сразу перейдём к интересному. К проблеме. Проблемой стал класс PersistentSet, который позволял сохранять множества где-то в оперативной памяти. Милая фича, но этот класс мог хранить в себе только объекты типа PersistentObject. И вот тут-то начались проблемы. С методами Delete и IsMember было всё нормально. Но вот Add...
from PersistentCollections import PersistentSet as ThirdPartyPersistentSet, PersistentObject. type PersistentSet: class implementing Set and consisting of private ThirdPartySet: ThirdPartyPersistentSet, public Add: subprogram with (Object) parameters returning nothing, public Delete: subprogram with (Object) parameters returning nothing, public IsMember: subprogram with (Object) parameters returning Boolean. subprogram PersistentSet.Add with (Object O) parameters returning nothing implemented as PersistentObject Po = O as PersistentObject, ThirdPartySet.Add(Po).

А теперь вообразите себе ситуацию. Если в PersistentSet добавить Object, то у нас будут проблемы. Но вот что действительно является катастрофой, так это то, что пользователи интерфейса Set и классов его реализующих скорее всего об этом не узнают, пока не нарвутся на ошибку в рантайме. В вышеупомянутой книге предлагается такое решение (у нас ещё одна фича с интерфейсами расширяющими друг друга):
type MemberContainer: interface consisting of Delete: have (Object) parameters returns nothing, IsMember: have (Object) parameters returns Boolean. type Set: interface extending MemberContainer and consisting of Add: have (Object) parameters returns nothing. type PersistentSet: interface extending MemberContainer and consisting of Add: have (PersistingObject) parameters returns nothing.
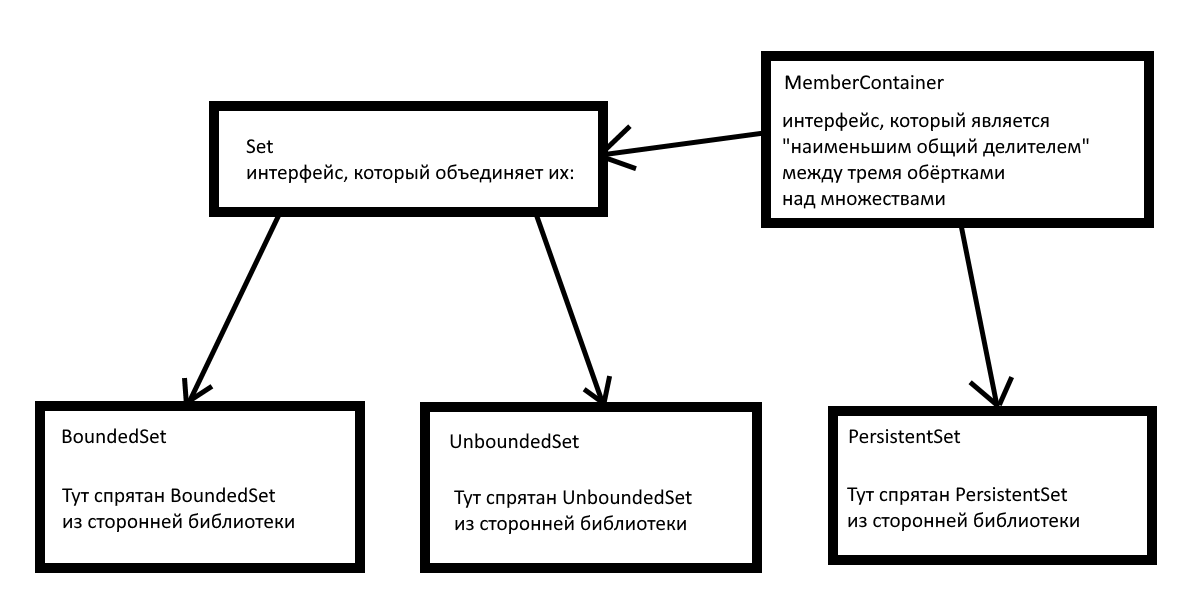
А ещё это можно решить с помощью аналога дженериков из C#.
У нас уже есть дженерики в NEPL. Вы могли видеть конструкцию типа List of String. Давайте дадим одну строчку для того, чтобы было проще понять пример.
type List: class generalized with (T) parameters consisting of
Теперь с помощью обобщения интерфейса Set ограничим наш PersistentSet.
from UnboundedCollections import UnboundedSet as ThirdPartyUnboundedSet. from BoundedCollections import BoundedSet as ThirdPartBoundedSet. from PersistentCollections import PersistentSet as ThirdPartyPersistentSet, PersistentObject. type Set: interface generalized with (T) parameters consisting of Add: have (T) parameters returns nothing, Delete: have (T) parameters returns nothing, IsMember: have (T) parameters returns Boolean. type UnboundedSet: class implementing Set of Object and consisting of private ThirdPartySet: ThirdPartyUnboundedSet, public Add: subprogram with (Object) parameters returning nothing, public Delete: subprogram with (Object) parameters returning nothing, public IsMember: subprogram with (Object) parameters returning Boolean. type BoundedSet: class implementing Set of Object and consisting of private ThirdPartySet: ThirdPartyBoundedSet, public Add: subprogram with (Object) parameters returning nothing, public Delete: subprogram with (Object) parameters returning nothing, public IsMember: subprogram with (Object) parameters returning Boolean. type PersistentSet: class implementing Set of PersistentObject and consisting of private ThirdPartySet: ThirdPartyPersistentSet, public Add: subprogram with (PersistentObject) parameters returning nothing, public Delete: subprogram with (PersistentObject) parameters returning nothing, public IsMember: subprogram with (PersistentObject) parameters returning Boolean.
(не)Использование за пределами ООП
С одной стороны принцип подстановки Барбары Лисков инструкция по применению наследования. С другой стороны, Роберт Мартин привёл нам пример, использующий «урезанную» версию наследования с объявлением контракта. То есть, даже без наследования реализации и с «один интерфейс — множество реализация» этот принцип надо соблюдать. Увы, никакой пример в голову не приходит. Надеюсь на помощь в комментариях.
I — The Interface Segregation Principle
Из названия принципа можно догадаться, что мы будем делить большие интерфейсы на маленькие. Интуитивно это кажется правильной вещью. Но давайте рассмотрим детали.
Использование за пределами ООП
Что, не ждали? Дело в том, что я хочу объяснить принцип разделения интерфейсов на примере из-за пределов ООП. Помните, когда мы говорили об инкапсуляции, я приводил в пример базу данных на SQL? Там у нас была база данных, которую использовало несколько приложений. И чтобы они не попортили нам наши драгоценные данные, мы сделали API из хранимых процедур. Собрали это API в одну схему, назвали её «interface», создали пользователей, которорым можно только вызывать эти хранимки. Инкапсулировали всё как надо. Что может пойти не так?
Одним не очень прелестным утром разработчики приложения, которое собирает личные данные пользователей из нашей БД, и на их основе что-то предлагает, постучались DBA в его любимый мессенджер. Начался поток жалоб, что из 100500 хранимых процедур не очень понятно, какие именно использовать. Но это ещё ладно. В нужное место в доках тыкнули, и на этом всё и успокоилось.
А потом разработчики другого приложения, которому вы дали доступ исключительно для того, чтобы они снимали деньги с пользователей, преподнесли «весёлый» сюрприз. Набрали под свои цели персональных данных, потому что «раз есть в interface, то почему бы не использовать». А потом несчастному DBA позвонил юр. отдел и рассказал подробно про GDPR, HIPAA и другие страшные слова, связанные с защитой персональных данных.
А потом третье приложение влезло куда-то не туда. И четвёртое подглядело то, что ему было бы лучше не видеть. И так далее.
Как избежать? Надо просто осознать, что разным приложениям могут быть нужны и разрешены разные вещи. И тогда принцип разделения интерфейса покажется простым и очевидным:
Программные сущности не должны зависеть от частей интерфейса, которые они не используют (и знать о них тоже не должны).
Что мы можем сделать в примере с базой данных? Вместо одной схемы interface использовать несколько схем вида «interface_billing», «interface_customer_data» и так далее. Тогда каждое приложение получит доступ только к необходимому.
Пример, который поближе к ООП, случился в моей практике не так давно. Есть у меня видеоигровой pet-project. И действующие лица в нём представлены интерфейсом IActor. Действующее лицо имеет физическое тело в виде прямоугольника, его можно нарисовать и обновить его состояние. Я выразил тот факт, что IActor имеет эти три свойства через три интерфейса: ICollidable, IDisplayble, IUpdatable. Что мне это дало?
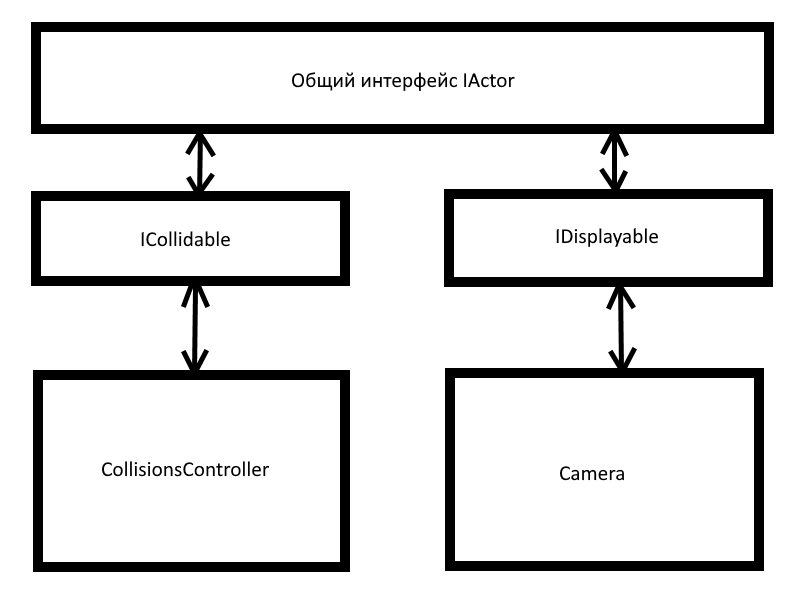
Камера (этот класс у меня так и называется, Camera), которая рисовала действующих лиц ничего знать не знала об их других свойствах. Она даже не знала, что там есть какие-то действующие лица. Она просто получала список того, что можно нарисовать. И когда мне понадобилось рисовать взрывы, которые в модель действующих лиц никак не вписывались, я просто реализовал сравнительно маленький IDisplayble у класса SpecEffect.
Класс CollisionsController в свою очередь, просто получал пачку хит-боксов в ICollidable. Когда мне понадобилось мастерить невидимые и недвижимые стены на основе ландшафта, случился поворотный момент, прямо вот осознание того, что SOLID действительно работает. Класс TileWall умел только возвращать прямоугольник хит-бокса, который передавался ему в конструкторе после анализа карты уровня. Но благодаря принципу разделения интерфейса классу CollisionsController этого было достаточно. О том, как бы я выкручивался, если бы я не догадался разделить интерфейс IActor на несколько частей, мне даже думать больно.

Мораль басни: давайте тем, кто пользуется вашей программной сущностью всё необходимое, но не более того.
D — The Dependency Inversion
Юнит-тесты. Хорошая, отличная вещь. Если не в курсе, что это такое, то сделайте паузу и погуглите. Вы просто пишите код, который убеждается, что ваш кусочек кода работает правильно. Это лучше, чем убеждаться в этом в процессе пошаговой отладки, гадая, правильно ли работает этот класс, или эту противную багу вызывает кто-то другой. Представьте, что у вас есть проект, где юнит-тестов до этого не было. В один прекрасный день вы решили, что больше так жить нельзя, и что с этим надо что-то делать.
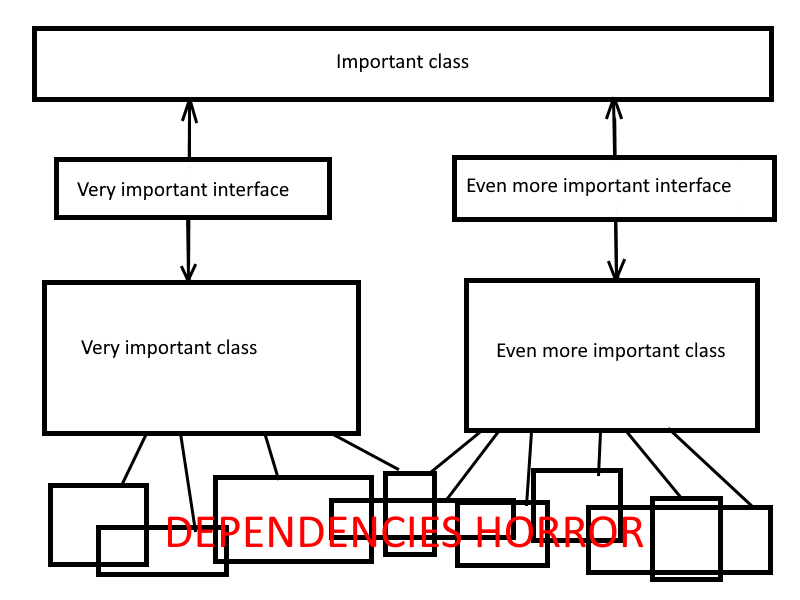
«Вот! Вот с этого класса начну.» — решаете вы и начинаете радостно продумывать тест-кейсы для вашего ImportantClass. Когда приходит пора писать тесты, выясняется, что вам для тестирования класса и его методов нужен рабочий объект этого класса. Дальше выясняется, что классу ImportantClass требуется для работы экземпляр класса VeryImportantClass, которому требуется ещё с пять объектов разных классов, из разных частей приложения, и экземпляр класса EvenMoreImportantClass, которому для работы вообще необходимо соединение с базой данных, доступ к файлам конфигурации и жабья лапка с кровью девственницы. Быстро становится ясно, что следом за тем, что мы хотим протестировать поднимается очень много вещей, которые мы тестировать не хотим. По крайней мере, не одним тестом. И процедура начинает казаться столь противной, что мы тяжко вздыхаем и возвращаемся к прошлой жизни.

Проблема тут в зависимости ImportantClass от VeryImportantClass и EvenMoreImportantClass. И решить нашу проблему с нетестируемостью ImportantClass можно через инверсию этой зависимости. Это делается с помощью абстракций, которые вклиниваются между вещами, которые надо разделить. Например, можно создать интерфейсы IVeryImportantClass и IEvenMoreImportantClass, где будут только методы необходимые ImportantClass.
Таким образом зависимость между ImportantClass и VeryImportantClass исчезает. И мы теперь можем тестировать наш ImportantClass в «сферическом ваакуме», дав ему вместо полноценных реализаций IVeryImportantClass тестовые заглушки.
Давайте теперь сформулируем принцип инверсии зависимостей. Ну как сформулирем, сдерём его с википедии, которая содрала его у Роберта Мартина.
Модули верхних уровней не должны зависеть от модулей нижних уровней. Оба типа модулей должны зависеть от абстракций.
Абстракции не должны зависеть от деталей. Детали должны зависеть от абстракций.
Под уровнями тут подразумевается традиционный способ проектирования, когда программа делится на «слои» и каждый «слой» спрячет от тех кто выше что-то своё. Слой доступа к базе данных, слой, прячущий от разработчиков разницу между различными платформами и т. д. Хотя даже если у вас на картинках и диаграммах нет слоёной пирамиды, то принцип инверсии зависимости предполагает дробление системы на части, которые зависят только от абстракций. Это позволяет нам разбивать программы на части, которые могут использоваться отдельно. Например, для проверки юнит-тестами.
Для полноты картины приведу ещё два примера из своей практики. Сначала высокоуровневый, а потом низкоуровневый.
Жила-была система, которая управляла массовыми рассылками. Была у неё серверная часть (Назовём её MegaSender), которая заведовала рассылками в промышленных масштабах по просьбам различных клиентов. Некоторые просьбы передавались из десктопного приложения, некоторые из плагинов к браузеру, было и SOAP API.
И среди различных клиентских приложений было веб-приложение. Его назовём SenderAccess. И оно писалось так, будто MegaSender и SenderAccess будут вместе навеки. SenderAccess лазил напрямую в БД MegaSender, хоть и имел свою, использовал код MegaSender, был сплётен за годы разработки с MegaSender плотнее, чем маркетинг Apple и буква i.
И вот однажды появился легковесный аналог MegaSender. Назовём его LightSender. И мне поручили сделать так, чтобы SenderAccess работал c LightSender. Абсолютно все понимали, сколько боли и страданий эта задача будет стоить, но её надо было сделать. И я сделал это именно с помощью инверсии зависимостей, потому что иначе было никак.
Целую неделю я перекапывал код SenderAccess, документируя все места, где он соприкасается с MegaSender тем или иным образом. Потом я провёл три месяца, выстраивая стену из абстракций между SenderAccess и MegaSender. В один прекрасный момент все зависимости от MegaSender оказались «за забором». Был код, который ничего не знал о MegaSender, был код, который с ним работал, а между ними были только абстрактные интерфейсы. Дальнейшее было делом техники. Оставалось только добавить конкретные реализации, работающие с LightSender и настроить выбор конкретных реализаций в зависимости от того, с кем мы работаем, с LightSender, или с MegaSender.
А ведь если бы тот, кто писал SenderAccess до меня проложил бы некоторые архитектурные границы, адаптация SenderAccess под LightSender прошла бы без боли и страданий. И заняла бы на порядок меньше времени.
Второй низкоуровневый пример возвращает нас к видеоигре из прошлого раздела, где был интерфейс IActor и интерфейсы ICollidable, IUpdatable, IDisplayble. Так вот, интерфейс IActor появился не сразу. Сначала был базовый класс Actor от которого наследовались Player, Enemy, Door, Wall и прочие. И так получилось, что они конструировались из чертежей.
Чертёж представлял из себя наследник класса Blueprint. А в чертеже содержалась вся информация для создания действующего лица. Какой спрайт, как быстро двигается, чем стреляет, куда стреляет, как выглядит, et cetera. И, очевидно, у босса, и у двери чертежи были разные.
Для связи между действующим лицом и чертежом, по которому его собирают, я использовал такую фичу языка C#, как дженерики. Если вы пользовались этим языком больше одной недели, вы наверняка видели что-то вроде List<String>. Это означало, что есть обобщённый тип List<T> и его конкретизация List<String>. Вот и у меня базовый класс Actor принял форму Actor<TBlueprint>.
Грабли полетели навстречу носу, когда стало ясно, что мне нужно как-то хранить и обрабатывать всех действующих лиц вместе. А Actor<EnemyBlueprint> и Actor<DoorBlueprint> считаются абсолютно разными и несовместимыми типами, хоть ты убейся. Например, в одну коллекцию их не положить.
Вот тут-то инверсия зависимости меня и выручила. Чертёж используется только при создании действующего лица и не используется при использовании этого действующего лица, например, камерой. Или классом, проверяющим столкновения. А значит, эту деталь можно спрятать за абстракцией. Я включил те методы, которые нужны взаимодействующим с действующими лицами в интерфейс IActor, и никто, кроме ActorsFactory больше не знал о чертежах.
У меня была ещё одна причина взять именно этот пример из прошлого раздела. Я хотел подвести вас к одной мысли: инверсия зависимости и принцип разделения интерфейса при правильном сочетании убийственно эффективны.
Использование за пределами ООП
Если с другими принципами было трудно придумать где они используются, то тут трудно придумать, где инверсия зависимости не используется. Если на уровне отдельных классов без инверсии ещё можно как-то выжить, то дальше без прослойки из абстракций в нужных местах жизнь становится невыносимой. Теперь конкретный (почти) пример:
Возьмём сетевой протокол. Любой. Вообще любой. TCP/HTTP/SMPP/SOAP, нужное подчеркните. В чём их основная прелесть? В том, что TCP/HTTP/SMPP/SOAP-сервер и TCP/HTTP/SMPP/SOAP-клиент могут договориться между собой, чтобы они из себя не представляли. Их общение зависит от выбранного протокола, но не от каких-то деталей друг друга. Как бы построили взаимодействие по сети без них? Задумайтесь об этом. Возможно, картинка этой альтернативной вселенной заменит вам просмотр «Сербского фильма» или «Дома 1000 кровавых трупов».
Главное в разработке ПО
К этому моменту у читателя может возникнуть вопрос. Обязательно всё это использовать? Прям вот всё до последней строчки должно быть по фэн-шую и по SOLID'у? Ответ на этот вопрос раскрывается через дао разработчика ПО, которое сформировалось у меня в голове к этому моменту. Хотя нельзя исключать и того, что я его где-то увидел, и забыл источник.
Если что-то облегчает твою жизнь в долгосрочной перспективе, используй это.
Если что-то усложняет твою жизнь в долгосрочной перспективе, НЕ используй это.
Я не просто так сделал упор на долгосрочную перспективу. Например, в краткосрочной перспективе нет вообще никакого смысла заморачиваться с юнит-тестами, инверсией зависимости, архитектурными границами и прочими вещами. На начальном этапе они отнимут достаточно времени. Но потом обязательно выплывет какой-нибудь момент, и вам придётся добавлять абстракции и мастерить архитектурные границы, но уже поверх существующего кода, который должен остаться рабочим после ваших манипуляций, даже если вы не добавляли туда юнит-тесты. Короче говоря, вещи описанные в этой статье минимизируют геморрой в обмен на потраченное время.
Но иногда они могут усложнять вашу жизнь в долгосрочной перспективе. Дам напоследок пару аббревиатур-мантр для того, чтобы вы вовремя умерили пыл:
KISS — Пиши просто. Сложные программы усложняют вашу жизнь. Очень сильно её усложняют. Никто не скажет вам спасибо за семь уровней наследования, или маленькую структурку из двух крепко связанных между собой строк, доступ к которой обёрнут тремя слоями абстракции. Используйте вышенаписанное, чтобы ваши программы были простыми, а не сложными.
Так, например, у меня один класс Actor реализует три интерфейса одновременно. Но я специально оставил один класс, потому что делить его на три — усложнять себе жизнь, ведь их как-то надо потом объединять в одно целое и таскать вместе. Достаточно от остальных спрятать тот факт, что это один класс за тремя интерфейсами.
YAGNI — Тебе это не понадобится. Кто-то начитавшись про разумное, доброе, вечное начинает писать код «на вырост», в надежде, что он когда-нибудь понадобится и эти семь уровней наследования действительно принесут нам пользу. К сожалению, с предсказанием будущего у разработчиков всё не очень. А код «на вырост» надо как-то сопровождать и тестить. А не факт, что когда он понадобится, его не придётся обрабатывать напильником. И не факт, что обработка займёт меньше времени, чем написание с нуля.
Допустим, вы прочитали внимательно раздел про OC/P и решили сделать свой модуль расширяемым. И добавили туда 50 точек расширения. Лишь для того, чтобы обнаружить, что из них используется только три-четыре. А ради этих 50 точек вам пришлось навернуть на ваш модуль несколько слоёв абстракции, и теперь в них чёрт ногу сломит. Вместе с теми несчастными, которые пользуются тремя-четырьмя нужными.
Как же найти минимально необходимую сложность? Увы, ничего толкового в голову, кроме «с опытом придёт», не приходит. Просто держите «дао разработчика» в голове и пробуйте прикинуть, что и почему может поменяться в вашей программе.
Возвращаясь к вопросу о том, стоит ли использовать SOLID и всё остальное. Да, чёрт возьми.
Чё почитать
К счастью, эта статья не превратилась в книгу. Потому что если тратить время на книгу, то пусть это будет книга кого-нибудь, у кого опыта больше, чем у меня. Дам маленький список того, что меня вдохновляло.
- «Code Complete» Макконелла. Классика, где подробно освещается «святая троица» без привязки к какому-либо языку.
- «Clean Code» Роберта Мартина. Можно полирнуть сверху «Clean Architecture».
- «Agile Principles, Patterns and Practices in C#» того же Роберта Мартина. Впервые о SOLID я узнал именно оттуда. К сожалению, не language-agnostic.
P.S.
Возможно, у вас появилось неприятное такое ощущение. Вам кажется, что в этой невероятно раздутой статье описываются вещи, которые и так должен знать каждый профессионал. Так вот: вам не кажется! Просто в мире, где существуют четырёхнедельные курсы разработчиков ПО, статей с language-agnostic знаниями должно быть больше.
Кстати, о language-agnostic. Я специально придумал NEPL, чтобы подчеркнуть одну простую вещь: принципы, здесь изложенные, не зависят от языка, на котором вы программируете. Хоть и использования того, что я расписал, в разных языках может отличаться.
По законам жанра, тут должны быть апдейты из комментариев. Но я не уверен, что у меня хватил сил на своевременную обработку того, что на меня высыпется тут. Поэтому на всякий случай дисклеймер:
Я не гуру разработки ПО, я просто пытаюсь приумножить разумное, доброе, вечное. И уверен, в комментарии придут люди с опытом большим, чем у меня на порядок. А даже если нет, коллективный разум в любой случае побьёт мои старания. Так что могу сказать только одно: дальше начинается самый смак, добро пожаловать в комментарии.

