Привет, Хабр! Представляю вашему вниманию перевод статьи "Machine Learning for Anyone Who Took Math in Eighth Grade" автора Kyle Gallatin.

Я обычно замечаю, что искусственный интеллект объясняется одним из двух способов: через все более сенсационную призму различных медиа, или через плотную научную литературу, пронизанную излишним языком и специфическими для области терминами.
Между этими крайностями существует менее публикуемая область, где, я думаю, литература должна немного активизироваться. Новости о «прорывах», по типу этого глупого робота София, поднимают хайп вокруг искусственного интеллекта и может показаться, что это чем-то похоже на человеческое сознание, в то время как в действительности София не умнее, чем SmarterChild у AOL Instant Messenger.
Научная литература может быть еще хуже, заставляя даже самого искушенного исследователя закрывать глаза после нескольких абзацев бессмысленного псевдоинтеллектуального мусора. Чтобы правильно оценить AI, люди должны в целом понимать, что это такое на самом деле. И все, что нужно, чтобы понять основы искусственного интеллекта, это немного математики средней школы.
Я могу быть склонен к излишнему упрощению — и я попрошу всех моих коллег по математике, наукам о данных и инженерному делу потерпеть мое объяснение — иногда это то, что нужно вычурной науке.
Основы искусственного интеллекта и машинного обучения
Типичный, классический искусственный интеллект — это все, что имитирует человеческий интеллект. Это может быть что угодно — от ботов для видеоигр до сложных платформ, таких как Deepmind Alphago.

Игнорируйте «Глубокое обучение» — в этом контексте, это то же самое что машинное. Изображение: Geospatial World
Машинное обучение — это подмножество искусственного интеллекта. Это позволяет машинам «учиться» на реальных данных вместо того, чтобы действовать по набору предопределенных правил.
Но что означает «учиться»? Это может быть не так футуристично, как кажется.
Мое любимое объяснение: машинное обучение — это просто  на крэке. Если вы смотрели что-то вроде Black Mirror, довольно легко начать представлять современный искусственный интеллект как сознательное существо — то, что думает, чувствует и принимает сложные решения. Это еще более распространено в СМИ, где AI последовательно олицетворяется, а затем сравнивается со Skynet из Терминатора, или фильмом Матрица.
на крэке. Если вы смотрели что-то вроде Black Mirror, довольно легко начать представлять современный искусственный интеллект как сознательное существо — то, что думает, чувствует и принимает сложные решения. Это еще более распространено в СМИ, где AI последовательно олицетворяется, а затем сравнивается со Skynet из Терминатора, или фильмом Матрица.
На самом деле это совсем не так. В своём нынешнем состоянии искусственный интеллект — это просто математика. Иногда это сложная математика, а иногда она требует глубоких знаний в области компьютерных наук, статистики и других. Но в конце концов современный AI в своей основе — это просто математическая функция.
Не беспокойтесь, если вы не дружите с математическими функциями, потому что не помните или не используете их. Чтобы уловить суть, нам нужно запомнить всего несколько простых вещей: есть вход ( ) и есть выход (
) и есть выход ( ), и функция — это то, что происходит между входом и выходом — связь между ними.
), и функция — это то, что происходит между входом и выходом — связь между ними.
Мы можем заставить компьютер взглянуть на входящие (
Примером супер-упрощенного искусственного интеллекта может быть функция, выраженная как . Мы уже знаем и (из таблицы ниже); нам просто нужно найти  и
и  , чтобы понять, какова связь между и .
, чтобы понять, какова связь между и .
| (вход) |
(выход) |
|---|---|
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
| 4 | 5 |
Таблица: Kyle Gallatin
Для этого шаблона, чтобы получить из , нам нужно умножить на 1() и добавить 1(). Так выйдет функция  .
.
Отлично! Мы определили, что  и
и  . Мы просто взяли некоторые данные (из таблицы выше) и создали функцию, которая их описала. По сути это и есть машинное обучение. Теперь, используя полученную функцию, мы можем сделать предположение, чему будет равен для других данных на входе .
. Мы просто взяли некоторые данные (из таблицы выше) и создали функцию, которая их описала. По сути это и есть машинное обучение. Теперь, используя полученную функцию, мы можем сделать предположение, чему будет равен для других данных на входе .
Интересная часть это то, как вы учите машину находить, какая функция лучше всего описывает данные, но когда вы с этим закончите, то, что у вас получится — это, как правило, некоторая форма . Как только мы получим эту функцию, мы также можем построить ее на графике:

Скриншот из видео Tecmath
Для более подробного объяснения функций у Math Is Fun есть интуитивно понятный и простой сайт (даже если название является для вас потенциальным красным флажком, и сайт выглядит так, как будто их веб-дизайнер сбежал когда-то в начале 2000-х).
Люди не сумеют подсчитать, машины сумеют
Очевидно, — это очень простой пример. Единственная причина, по которой существует машинное обучение, заключается в том, что люди не могут смотреть на миллионы входящих и выходящих точек данных и придумывать сложную функцию для описания результатов. Вместо этого мы можем обучить компьютер делать это за нас.
В любом случае, должно быть достаточно данных, чтобы найти правильную функцию. Если у нас есть только по одной точке данных для и , ни мы, ни машина не могли бы предсказать только одну точную функцию. В исходном примере, где  и
и  , функция может быть
, функция может быть  ,
,  ,
, ![$y = ([x + 1] \cdot 5 - 9)^5 + 1$](https://habrastorage.org/getpro/habr/formulas/017/64c/07f/01764c07f5a876b3483a8dd7051a4b48.svg) или многими другими. Если у нас недостаточно данных, функция, которую найдет машина, может привести к большому количеству ошибок, когда мы попытаемся использовать её для большего количества данных.
или многими другими. Если у нас недостаточно данных, функция, которую найдет машина, может привести к большому количеству ошибок, когда мы попытаемся использовать её для большего количества данных.
Кроме того, реальные данные не всегда так совершенны. В приведенном ниже примере машина определила несколько функций, которые соответствуют большей части данных, но линия не проходит через каждую точку. В отличие от прошлого примера с таблицей из математического класса, данные, собранные из реального мира, более непредсказуемы и никогда не могут быть описаны полностью.
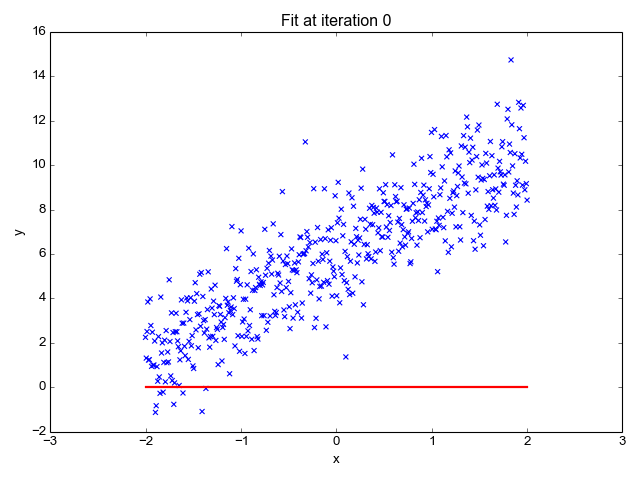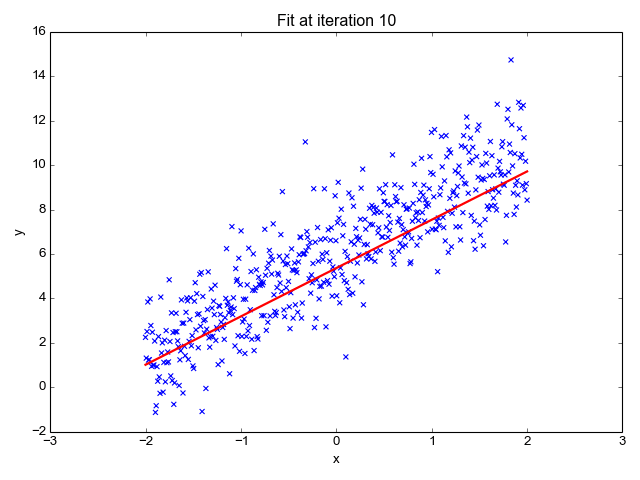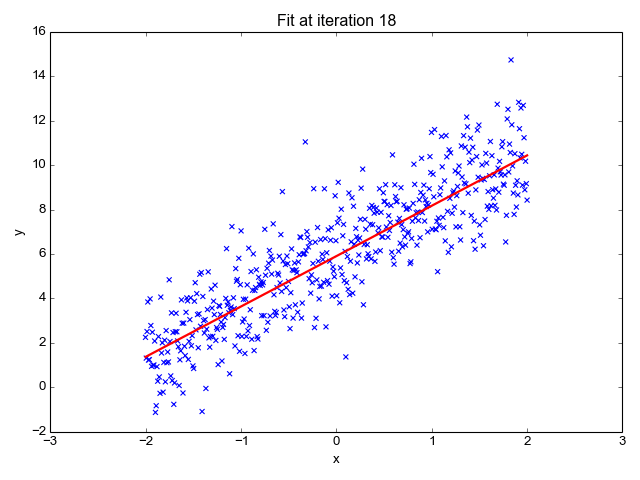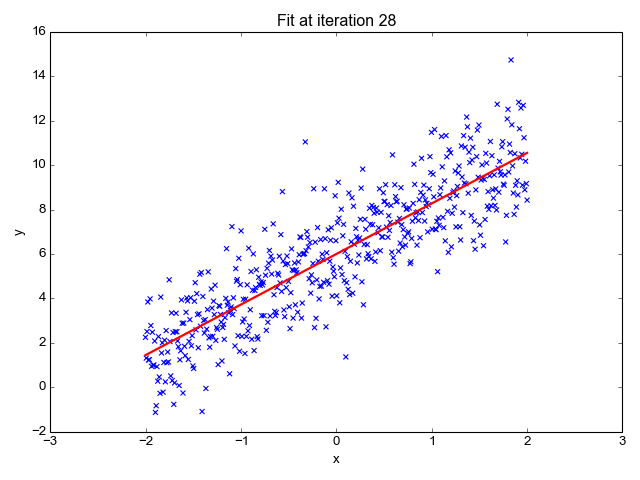
Этот базовый пример показывает, как машина учится, чтобы лучше всего описывать представленные данные. Изображение: Towards Data Science
Наконец, последнее, что люди не могут сделать, это посмотреть на кучу переменных. Это просто с помощью и , но что если входящих переменных больше? Что если на влияет  ,
,  ,…
,…  . Очень быстро функции могут становиться все более сложными (для людей).
. Очень быстро функции могут становиться все более сложными (для людей).
Машинное обучение и искусственный интеллект в реальном мире
Давайте посмотрим на реальный пример. Я работаю в области фармацевтики, поэтому предположим, что у нас есть набор данных связанных с раком, который имеет две входящие переменные, отвечающие размеру опухоли — радиус и периметр, и выход, с двумя возможными значениями: является ли опухоль доброкачественной или метастатической (потенциально опасной для жизни). Это может показаться сложным, но нам всего-то нужно применить знакомую концепцию :
- является диагнозом, и может быть 0 (доброкачественный) или 1 (метастатический).
 — радиус.
— радиус. — периметр.
— периметр.- У каждого есть свой неизвестный ; давайте назовем их
 и
и  .
. - — неизвестная постоянная.
Как теперь выглядит наше линейное уравнение? Не сильно отличается от примера выше:

Как я объяснил выше, мы выходим из области человеческих возможностей. Таким образом, вместо того, чтобы смотреть на данные и пытаться выяснить, на что мы должны умножить наши переменные, используем машины. Они сделают это за нас, и мы получим точную оценку диагноза. И это и есть машинное обучение!
Конечно, даже самые подробные, многофакторные данные не идеальны, поэтому и наша модель машинного обучения тоже такой не будет. Но нам и не нужно, чтобы они были правильны в 100% случаев. Мы просто нуждаемся в них, чтобы придумать наилучшую возможную функцию, которая подходит для большинства случаев.
Эта часть только царапает поверхность невероятной математики и компьютерной науки, которая входит в машинное обучение. Но даже на сложных уровнях концепция та же. Неважно, насколько впечатляющим или странным может показаться машинное обучение и искусственный интеллект, все это происходит от функций, которыми машина научилась лучше всего описывать данные.

