
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
я склоняюсь к тому чтобы
Предлагаете изменить стандарт или просто не учить людей стандарту, что бы они на сложных вещах ошибались? Если стандарту всё же учить, диаграммы Венна не подходят.
Как диаграммы Венна покажут пересечение ключей при расчёте накопительного итога?
Что касается накопительный итог — не совсем понимаю что имеется в виду. Если можно поясните пожалуйста на примере?
FROM A JOIN B ON B.date <= A.dateпочему бы не сделать семантическое разделение
Вы не предлагаете его нарушить, вы видимо предлагаете его поменять.
Про накопительный итог вам ниже рассказали. Каким образом диаграммы Венна покажут пересечение ключей при расчёте накопительного итога?
можно задавать условия соединения двух таблиц в WHERE а условия фильтрации в JOIN
Нельзя. LEFT JOIN не взаимозаменяем с WHERE, если есть null.
Вроде же sql — structured query language, язык структурированных запросов.
Мне кажется, что zetroot имел в виду, что аббревиатура SQL расшифровывается как Structured Query Language, а не как Simple Query Language. Что есть абсолютная правда, см. например https://en.wikipedia.org/wiki/SQL
Визуализацию нужно повернуть на 45 градусов, и поменять в ней таблицы местами.
Вроде бы получилась простая визуализация. Хотя в ней есть ограничения: здесь показан случай, когда в ON записано равенство, а не что-то хитрое (любое булево выражение).
Отличие "любого булева выражения" от равенства — лишь в том, что "любые булевы выражения" чаще дают дублирующиеся строки. Но поскольку вы специально подобрали совпадающие идентификаторы — никакого отличия в визуализации не будет.
Кстати, а как же FULL OUTER JOIN? Ну так, чисто для полноты картины.
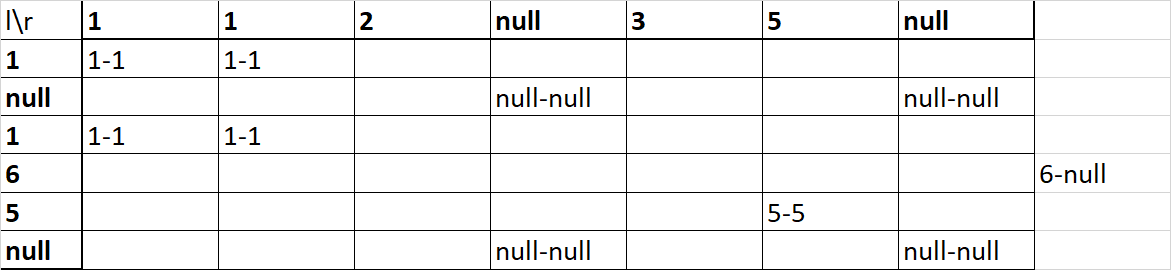
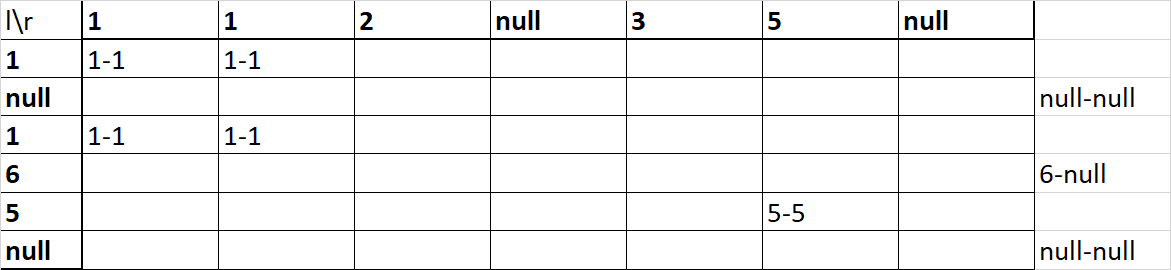
CREATE TABLE t1 (id int, v varchar(1));
CREATE TABLE t2 (id int, v varchar(1));
INSERT INTO t1
values
(1, 'a'),
(null, 'b'),
(1, 'c'),
(6, 'd'),
(5, 'e'),
(null, 'f');
INSERT INTO t2
VALUES
(1, 'a'),
(1, 'b'),
(2, 'c'),
(null, 'd'),
(3, 'e'),
(5, 'f'),
(null, 'g');
SELECT t1.id, t2.id
FROM t1
LEFT JOIN t2
ON t1.id = t2.id;
SELECT t1.v, t2.v
FROM t1
LEFT JOIN t2
ON t1.id = t2.id;







join — это скорее декартово произведение, чем пересечение.
SELECT t1.id, t2.id
FROM t1
INNER JOIN t2
ON t1.id = t2.id
SELECT t1.id, t2.id
FROM t1, t2
WHERE t1.id = t2.idSELECT t1.id, t2.id
FROM t1
CROSS JOIN t2
WHERE t1.id = t2.idТак и хочеться набросить что web девелоперы не могут в алгебру, но собственно вот из учебных материалов:
http://www.mstu.edu.ru/study/materials/zelenkov/ch_4_4.html
СОЕДИНЕНИЕ
Данная операция имеет сходство с ДЕКАРТОВЫМ ПРОИЗВЕДЕНИЕМ. Однако, здесь добавлено условие, согласно которому вместо полного произведения всех строк в результирующее отношение включаются только строки, удовлетворяющие опредленному соотношению между атрибутами соединения (А1,A2) соответствующих отношений.
И да, что у вас там в постгре лежит и почему вы джойните диапазоны ipшников - это конечно отдельный вопрос
Я конечно извиняюсь, но такое ощущение что обе статьи написаны в зануда мод вкл
Но для многих видно наболевшая тема




Понимание джойнов сломано. Продолжение. Попытка альтернативной визуализации