В "Черном Зеркале" была серия (S2E1), в которой создавали роботов, похожих на умерших людей, используя для обучения историю переписок в социальных сетях. Я хочу рассказать, как я попробовал сделать что-то подобное и что из этого получилось. Теории не будет, только практика.

Идея была простая — взять историю своих чатов из Telegram и на их основе обучить seq2seq сеть, способную по началу диалога предсказывать его завершение. Такая сеть может работать в трех режимах:
- Предсказывать завершение фразы пользователя с учетом истории разговора
- Работать в режиме чат-бота
- Синтезировать логи разговоров целиком
Вот что получилось у меня
Бот предлагает завершение фразы
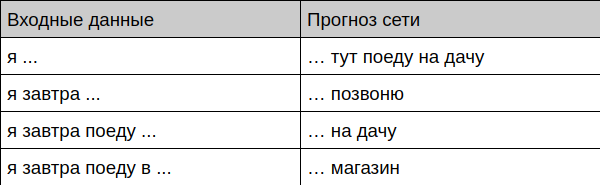
Бот предлагает завершение диалога

Бот общается с живым человеком
User: привет Bot: привет User: как ты? Bot: собираюсь User: баг пофиксил? Bot: нет User: почему? Bot: да не получается User: ты сегодня когда дома будешь? Bot: не знаю пока User: ты занят? Bot: в магазин еду
Дальше я расскажу, как подготовить данные и обучить такого бота самому.
Как обучить самому
Подготовка данных
Прежде всего нужно где-то добыть очень много чатов. Я взял всю свою переписку в Telegram, благо клиент для десктопа позволяет выгрзуить полный архив в формате JSON. Дальше я выбросил все сообщения, которые содержат цитаты, ссылки, и файлы, а оставшиеся тексты перевел в lower case и выбросил оттуда все редкие символы, оставив только простой набор из букв, цифр и знаков препинания — так сети проще обучиться.
Потом я привел чаты к такому виду:
=== > привет < и тебе привет > пока < до встречи! === > как дела? < хорошо
Здесь сообщения, которые начинаются с символа ">" это вопрос мне, символ "<" соответственно помечает мой ответ, а строка "===" служит для разделения диалогов между собой. То, что один диалог закончился, а другой начался, я определял по времени (если между сообщеними прошло больше 15 минут, значит считаем, что это новый разговор. Скрипт для конвертации истории можно посмотреть на github.
Так как я давно и активно пользуюсь телеграмом, то и сообщений в итоге набралось немало — в итоговом файле получилось 443 тысячи строк.
Выбор модели
Я обещал, что теории сегодня не будет, поэтому постораюсь объяснить максимально коротко и на пальцах.
Я выбрал классическую модель seq2seq на основе GRU. Такая модель на вход получает текст побуквенно и на выход также выдает по одной букве. Процесс обучения строится на том, что мы учим сеть предсказывать последнюю букву текста, например на вход мы подаем "приве" и ждем, что на выходе будет выдано "ривет".
Для генерации же длинных текстов используется простой трюк — результат предыдущего предсказания отправляется обратно в сеть и так до тех пор, пока не будет сгененирован текст необходимой длины.
Модули GRU очень-очень упрощенно можно представлять себе как "хитрый персептрон с памятью и вниманием", подробнее про них можно почитать, например, здесь.
За основу модели был выбран известный пример задачи генерации текстов Шекспира.
Обучение
Все, кто хоть раз сталкивался с нейросетями, наверное знает, что учить их на CPU очень скучно. К счастью на помощь приходит google с их сервисом Colab — в нем можно бесплатно запускать свой код в jupyter notebook с использованием CPU, GPU и даже TPU. В моем случае обучение на видеокарте укладывается в 30 минут, хотя вменяемые результаты доступны уже через 10. Главное, это не забыть переключить тип железа (в меню Runtime -> Change runtime type).
Тестирование
После обучения можно переходить к проверке модели — я написал несколько примеров, которые позволяют обращаться к модели в разных режимах — от генерации текста, до живого чата. Все они есть на github.
В методе генерации текста есть параметр temperature — чем он выше, тем более разнообразный текст (и бессмысленный) будет выдавать бот. Этот параметр есть смысл настраивать руками под конкретную задачу.
Дальнейшее использование
Для чего может быть использована такая сеть? Самое очевидное, это для разработки бота (или умной клавиатуры), который сможет предлагать пользователю готовые ответы ещё до того, как он их напишет. Подобная функция давно существует в Gmail и большинстве клавиатур, но там не учитывается контекст беседы и манера конкретного пользователя вести переписку. Скажем, клавиатура G-Keyboard стабильно предлагает мне совершенно бессмысленные варианты, например "я еду с… уважением" в том месте, где хотелось бы получить вариант "я еду с дачи", который я однозначно употреблял много раз.
Есть ли будущее у чат бота? В чистом виде точно нет, в нем слишком много персональных данных, никто не знает, в какой момент он выдаст собеседнику номер вашей кредитки, который вы однажды кидали другу. Тем более такой бот совершенно не тюнингуется, очень сложно заставить его выполнять какие-то конкретные задачи или правильно отвечать на определенный вопрос. Скорее такой чат-бот мог бы работать совместно с другими типами ботов, обеспечивая бОльшую связаность диалогов "ни о чем" — с этим он хорошо справляется. (И тем не менее внешний эксперт в лице жены сказал, что манера общения у бота на меня весьма похожа. А ещё темы его волнуют явно те же самые — в текстах постоянно всплывает баги, фиксы, коммиты и другие радости и грусти разработчика).
Что ещё советую попробовать, если эта тема вам интересна?
- Transfer learning (обучить на большом корпусе чужих диалогов, а потом доучить на своих)
- Поменять модель — увеличить, изменить тип (например, на LSTM).
- Попробовать работу с TPU. В чистом виде эта модель работать не будет, но адаптировать её можно. Теоретическое ускорение обучения должно быть десятикратным.
- Портировать на мобильную платформу, например с помощью Tensorflow mobile.
P.S. Ссылка на github

