Техника кеширования позволяет создавать более масштабируемые приложения, запоминания результаты некоторых запросов в быстрое in-memory хранилище. Однако, некорректно реализованное кеширование может сильно ухудшить впечатление пользователя о вашем приложении. Эта статья содержит некоторые базовые понятия о кешировании, различные правила и табу, которые я извлек из нескольких прошлых своих проектов.
Не используйте кеширование.
Ваш проект работает быстро и не имеет никаких проблем с производительностью?
Забудьте о кешировании. Серьезно :)
Оно сильно усложнит операции чтения из базы без каких-либо бенефитов.
Правда, Мохамед Саид в начале этой статьи делает некоторые вычисления и доказывает, что в некоторых случаях оптимизация приложения на миллисекунды способна сэкономить кучу денег на вашем AWS счету. Так что, если прогнозируемая экономия на вашем проекте больше, чем 1.86 долларов, возможно, реализация кеширования — неплохая идея.
Как это работает?
Когда приложения хочет получить некоторые данные из базы, например сущность Post по его id, оно формирует уникальный ключ кеширования для этого случая ('post_' . $id вполне подходяще) и пытается найти значение по этому ключу в быстром key-value хранилище(memcache, redis, или другое). Если значение там — то приложение использует его. Если нет, забирает его из базы данных и сохраняет в кеш по этому ключу для будущих использований.
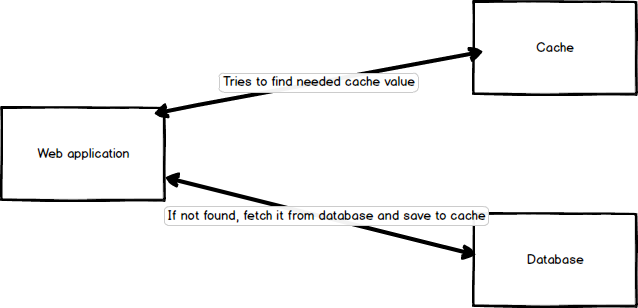
Сохранять это значение в кеше навсегда не самая лучшая идея, поскольку эту сущность Post могут обновить, но приложение всегда будет получать старое, закешированное, значение.
Поэтому функции кеширования обычно спрашивают какое время это значение хранить.
После истечения этого времени memcache или redis "забудут" про него и приложение возьмет свежее значение из базы.
Пример:
public function getPost($id): Post { $key = 'post_' . $id; $post = \Cache::get($key); if($post === null) { $post = Post::findOrFail($id); \Cache::put($key, $post, 900); } return $post; }
Здесь я кладу сущность Post в кеш на 15 минут (начиная с версии 5.8 laravel использует секунды в этом параметре, раньше там были минуты). Фасад Cache также имеет удобный метод remember для этого случая. Этот код делает ровно тоже самое, что и предыдущий:
public function getPost($id): Post { return \Cache::remember('post_' . $id, 900, function() use ($id) { return Post::findOrFail($id); }); }
В документации Laravel есть глава Cache, которая обьясняет как установить необходимые драйверы для вашего приложения и главный функционал.
Данные в кеше
Все стандартные драйверы Laravel хранят данные как строки. Когда мы просим сохранить в кеше экземпляр модели Eloquent, оно использует функцию serialize, чтобы получить строку из обьекта. Функция unserialize восстанавливает состояние обьекта когда мы получаем его из кеша.
Почти любые данные могут быть закешированы. Числа, строки, массивы, обьекты (если они умеют корректно сериализоваться, смотрите описания функций по ссылкам ранее).
Сущности Eloquent и коллекции легко могут быть закешированы и являются самыми популярными значениями в кеше приложений Laravel. Однако, использование других типов тоже практикуется довольно широко. Метод Cache::increment популярен для реализации различных счетчиков. Также, атомарные локи весьма полезны когда разработчики сражаются с race conditions.
Что кешировать?
Первые кандидаты на кеширование — это запросы, которые выполняются очень часто, но их план выполнения не самый простой. Лучший пример — top-5 статей на главной странице, или последние новости. Кеширование таких значений способно сильно улучшить производительность главной страницы.
Обычно, выборка сущностей по id, используя Model::find($id) работает очень быстро, но если эта таблица сильно загружена многочисленными запросами update, insert и delete, уменьшение количества select запросов даст хорошую передышку базе данных. Сущности с отношениями hasMany, которые будут загружаться каждый раз, тоже хорошие кандидаты на кеширование. Когда я работал на проекте с 10+ миллионов посетителей в день мы кешировали почти любой select запрос.
Инвалидация кеша
Протухание ключа через заданное время помогает обновить данные в кеше, но это происходит не сразу. Пользователь может поменять данные, но некоторое время он будет продолжать видеть старую версию их в приложении. Обычный диалог на одном из моих прошлых проектов:
Пользователь: Я обновил публикацию, но продолжаю видеть старую версию! Разработчик: Пожалуйста, подождите 15 минут(или полчаса, или час)...
Это поведение весьма неудобно для пользователей и очевидное решение удалять из кеша старые данные, когда мы их обновили быстро приходит в голову. Этот процесс называется инвалидацией. Для простых ключей типа "post_%id%", инвалидация не очень сложная.
События Eloquent могут помочь, или если ваше приложение генерит специальные события, такие как PostPublished или UserBanned это может быть еще проще. Пример с событиями Eloquent. Сначала надо создать классы событий. Для удобства я буду использовать абстрактный класс для них:
abstract class PostEvent { /** @var Post */ private $post; public function __construct(Post $post) { $this->post = $post; } public function getPost(): Post { return $this->post; } } final class PostSaved extends PostEvent{} final class PostDeleted extends PostEvent{}
Разумеется, по PSR-4, каждый класс должен лежать в своем файле. Настраиваем Post Eloquent класс (используя документацию):
class Post extends Model { protected $dispatchesEvents = [ 'saved' => PostSaved::class, 'deleted' => PostDeleted::class, ]; }
Создаем слушатель этих событий:
class EventServiceProvider extends ServiceProvider { protected $listen = [ PostSaved::class => [ ClearPostCache::class, ], PostDeleted::class => [ ClearPostCache::class, ], ]; } class ClearPostCache { public function handle(PostEvent $event) { \Cache::forget('post_' . $event->getPost()->id); } }
Этот код будет удалять закешированные значения после каждого обновления или удаления сущностей Post. Инвалидация списков сущностей, таких как top-5 статей или последних новостей, будет чуток посложнее. Я видел три стратегии:
Стратегия "Не инвалидируем"
Просто не трогать эти значения. Обычно, это не приносит никаких проблем. Ничего страшного в том, что новая новость появится в списке последних чуть позже (конечно, если это не большой новостной портал). Но некоторым проектам действительно важно иметь свежие данные в этих списках.
Стратегия "Найти и обезвредить"
Можно при каждом обновлении публикации, пытаться найти её в закешированных списках, и если она там есть, удалить это закешированное значение.
public function getTopPosts() { return \Cache::remember('top_posts', 900, function() { return Post::/*формируем запрос получения top-5*/()->get(); }); } class CheckAndClearTopPostsCache { public function handle(PostEvent $event) { $updatedPost = $event->getPost(); $posts = \Cache::get('top_posts', []); foreach($posts as $post) { if($updatedPost->id == $post->id) { \Cache::forget('top_posts'); return; } } } }
Выглядит уродливо, зато работает.
Стратегия "хранить id"
Если порядок элементов в списке неважен, то в кеше можно хранить только id записей. После получения id, можно сформировать список ключей вида 'post_'.$id и получить все значения используя метод Cache::many, который достает много значений из кеша за один запрос (это еще называется multi get).
Инвалидация кеша не зря названа одной из двух трудностей в програмировании и весьма трудно в некоторых случаях.
Кеширование отношений
Кеширование сущностей с отношениями требует повышенного внимания.
$post = Post::findOrFail($id); foreach($post->comments...)
Этот код выполняет два SELECT запроса. Получение сущности по id и комментариев по post_id. Реализуем кеширование:
public function getPost($id): Post { return \Cache::remember('post_' . $id, 900, function() use ($id) { return Post::findOrFail($id); }); } $post = getPost($id); foreach($post->comments...)
Первый запрос был закеширован, а второй — нет. Когда драйвер кеша записывает Post в кеш, comments еще не загружены. Если мы хотим кешировать и их тоже, то мы должны загрузить их вручную:
public function getPost($id): Post { return \Cache::remember('post_' . $id, 900, function() use ($id) { $post = Post::findOrFail($id); $post->load('comments'); return $post; }); }
Теперь кешируются оба запроса, но мы должны инвалидировать значения 'post_'.$id каждый раз когда добавляется комментарий. Это не очень эффективно, поэтому лучше хранить кеш комментариев отдельно:
public function getPostComments(Post $post) { return \Cache::remember('post_comments_' . $post->id, 900, function() use ($post) { return $post->comments; }); } $post = getPost($id); $comments = getPostComments($post); foreach($comments...)
Иногда сущность и отношение сильно связаны друг с другом и всегда используются вместе (заказ с деталями, публикация с переводом на нужный язык). В этом случае хранить их в одном кеше вполне нормально.
Single source of truth для ключей кеширования
Если на проекте реализована инвалидация, ключи кеширования генерируются как минимум в двух местах: для вызова Cache::get / Cache::remember и для вызова Cache::forget. Я уже встречался с ситуациями, когда этот ключ был изменен в одном месте, но не в другом и инвалидация ломалась. Обычный совет для таких случаев — константы, но ключи кеширования формируются динамически, поэтому я использую специальные классы, генерирующие ключи:
final class CacheKeys { public static function postById($postId): string { return 'post_' . $postId; } public static function postComments($postId): string { return 'post_comments' . $postId; } } \Cache::remember(CacheKeys::postById($id), 900, function() use ($id) { $post = Post::findOrFail($id); }); // .... \Cache::forget(CacheKeys::postById($id));
Время жизни ключей также можно вынести в константы, ради лучшей читаемости. Эти 900 или 15*60 увеличивают когнитивную нагрузку при чтении кода.
Не используйте кеш в операциях записи
При реализации операций записи, таких как изменение заголовка или текста публикации, велик соблазн использовать метод getPost, написанный ранее:
$post = getPost($id); $post->title = $newTitle; $post->save();
Пожалуйста, не делайте так. Значение в кеше может быть устаревшим, даже если инвалидация сделана корректно. Небольшой race condition и публикация потеряет изменения, сделанные другим пользователем. Оптимистические блокировки помогут хотя бы не потерять изменения, но количество ошибочных запросов может сильно возрасти.
Лучшее решение — использовать абсолютно разную логику выборки сущностей для операций чтения и записи (привет, CQRS). В операциях записи всегда нужно выбирать свежее значение из базы данных. И не забывать о блокировках (оптимистичных или пессимистичных) для важных данных.
Я думаю, это достаточно для вводной статьи. Кеширование весьма сложная и пространная тема, с ловушками для разработчиков, но прирост производительности иногда перевешивает все трудности.

