Привет, Хабр! В этой статье я хочу рассмотреть такую библиотеку для Java, как ClusterJ, которая позволяет очень просто работать с движком MySQL NDBCLUSTER из Java кода, которая представляет собой высокоуровневое API, схожее по концепции с JPA и Hibernate.
В рамках статьи создадим простое приложение на SpringBoot, а также сделаем стартер с ClusterJ на борту для удобного использования в приложениях с использованием автоконфигурации. Напишем простые тесты с использованием JUnit5 и TestContainers, которые покажут базовое использование API.
Также расскажу о нескольких недостатках, с которыми пришлось столкнутся в процессе работе с ней.
Кому интересно, добро пожаловать под кат.
Введение
На работе активно используется MySQL NDB Cluster и в одном из проектов в угоду скорости встала задача вместо привычного JDBC воспользоваться библиотекой ClusterJ, которая по своему API очень напоминает JPA, и по сути, представляет собой обертку над библиотекой libndbclient.so, которую использует через JNI.
Для тех кто не в курсе, MySQL NDB Cluster это версия MySQL с высокой доступностью и резервированием, адаптированная для среды распределенных вычислений, в которой используется механизм храненияNDB(NDBCLUSTER) для работы в кластере. Не хочу подробно здесь останавливаться на этом, подробнее можно почитать тут и тут
Для работы из Java кода с данной базой существует два способа:
- Стандартный, через
JDBCиSQLзапросы - Через
ClusterJ, для высокопроизводительного доступа к данным в базе данныхMySQL Cluster.
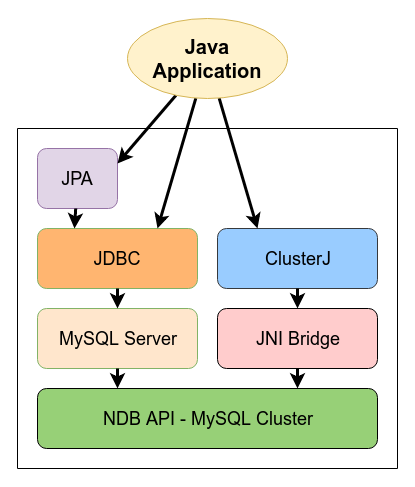
ClusterJ построен вокруг 4 ключевых концепций:
SessionFactory— аналог connection pool'а, используется для получения сессии. Для каждого экземпляра кластера должен быть свой SessionFactory.Session— представляет собой непосредственно соединение с кластеромMySQL.Domain Object— аннотированный интерфейс, представляющий собой отображение таблицы наJavaкод, подобноJPA.Transaction— представляет собой атомарную единицу работы. В любой момент времени, в одной сессии выполняется одна транзакция. Любая операция (получение, вставка, обновление, удаление) выполняется в новой транзакции.
Ограничения ClusterJ:
- Отсутствие JOIN'ов
- Нет возможности создать таблицу и индексы. Для этого нужно использовать
JDBC. - Нет отложенной загрузки (
Lazy). Вся запись загружается за один раз. - В доменных объектах нет возможно определить взаимосвязи между таблицами. Подобие
OneToMany,ManyToOne,ManyToManyполностью отсутствует.
Практика. Talk is cheap. Show me the code.
Что ж, хватит теории, перейдем к практике.
Первая проблема, с которой предстоит столкнутся, это отсутствие ClusterJ в центральном репозитории Maven. Установим библиотеку ручками в локальный репозиторий. Понятно, что по хорошему она должна ложится в Nexus или какой-нибудь Artifactory, но для нашего примера это излишне.
Итак, идем сюда и выбираем свою операционную систему. Если вы на Linux подобной ОС, качаем пакет под названием mysql-cluster-community-java и ставим данный rpm/deb пакет. Если у вас Windows, качаем полный архив mysql-cluster-gp.
Так или иначе у нас будет jar файл вида: clusterj-{version}.jar. Ставим его через maven:
mvn install:install-file -DgroupId=com.mysql.ndb -DartifactId=clusterj -Dversion={version} -Dpackaging=jar -Dfile=clusterj-{version}.jar -DgeneratePom=true
Также нам нужна библиотека libndbclient, которая представляет собой набор C++ функций для работы с NDB API, которые ClusterJ вызывает через JNI. Для Windows данная библиотека (.dll) находится в архиве mysql-cluster-gp, для Linux нужно скачать пакет ndbclient_{version}.
Далее создаем проект. Мы будем использовать SpringBoot, JUnit5+ TestContainers для тестов.

Проект состоит из двух модулей:
clusterj-spring-boot-starter— стартер, который содержит непосредственноClusterJ, а также атоконфигурацию. Благодаря данному стартеру, мы можем в нашемappliation.ymlфайле описать подключение кMySQL NDBв таком виде:
clusterj: connectString: localhost:1186 dataBaseName: NDB_DB
После чего SpringBoot создаст для нас необходимую фабрику SessionFactory для подключения.
clusterj-app— непосредственно само приложение, которое будет использовать наш стартер. Остановимся на нем подробнее.
Для начала работы нам необходимо создать доменную модель, подобно JPA. Только в данном случае нам необходимо сделать это в виде интерфейса, реализацию которого в рантайме нам сделает clusterj:
import com.mysql.clusterj.annotation.Column; import com.mysql.clusterj.annotation.PersistenceCapable; import com.mysql.clusterj.annotation.PrimaryKey; @PersistenceCapable(table = "user") public interface User { @PrimaryKey int getId(); void setId(int id); @Column(name = "firstName") String getFirstName(); void setFirstName(String firstName); @Column(name = "lastName") String getLastName(); void setLastName(String lastName); }
Здесь сразу есть проблема. В аннотации PersistenceCapable есть возможность задать название схемы или базы данных, в которой лежит таблица, однако это не работает. Совсем. В ClusterJ это не реализовано. Поэтому, все таблицы, с которыми идет работа через ClusterJ должны быть в одной схеме, из-за чего получается свалка таблиц, которые по логике должны находится в разных схемах.
Попробуем теперь воспользоваться данным интерфейсом. Для этого напишем простой тест.
Чтобы не заморачиваться с установкой MySQL Cluster, воспользуемся замечательной библиотекой для интеграционного тестирования TestContainers и Docker. Так как мы используем JUnit5 напишем простой Extension:
import com.github.dockerjava.api.model.Network; import lombok.extern.slf4j.Slf4j; import org.junit.jupiter.api.extension.Extension; import org.testcontainers.containers.BindMode; import org.testcontainers.containers.GenericContainer; import org.testcontainers.containers.wait.strategy.Wait; import org.testcontainers.shaded.com.google.common.collect.ImmutableMap; import java.time.Duration; import java.util.stream.Stream; @Slf4j class MySQLClusterTcExtension implements Extension { private static final String MYSQL_USER = "sys"; private static final String MYSQL_PASSWORD = "qwerty"; private static final String CLUSTERJ_DATABASE = "NDB_DB"; private static Network.Ipam getIpam() { Network.Ipam ipam = new Network.Ipam(); ipam.withDriver("default"); Network.Ipam.Config config = new Network.Ipam.Config(); config.withSubnet("192.168.0.0/16"); ipam.withConfig(config); return ipam; } private static org.testcontainers.containers.Network network = org.testcontainers.containers.Network.builder() .createNetworkCmdModifier(createNetworkCmd -> createNetworkCmd.withIpam(getIpam())) .build(); private static GenericContainer ndbMgmd = new GenericContainer<>("mysql/mysql-cluster") .withNetwork(network) .withClasspathResourceMapping("mysql-cluster.cnf", "/etc/mysql-cluster.cnf", BindMode.READ_ONLY) .withClasspathResourceMapping("my.cnf", "/etc/my.cnf", BindMode.READ_ONLY) .withCreateContainerCmdModifier(createContainerCmd -> createContainerCmd.withIpv4Address("192.168.0.2")) .withCommand("ndb_mgmd") .withExposedPorts(1186) .waitingFor(Wait.forListeningPort().withStartupTimeout(Duration.ofSeconds(150))); private static GenericContainer ndbd1 = new GenericContainer<>("mysql/mysql-cluster") .withNetwork(network) .withClasspathResourceMapping("mysql-cluster.cnf", "/etc/mysql-cluster.cnf", BindMode.READ_ONLY) .withClasspathResourceMapping("my.cnf", "/etc/my.cnf", BindMode.READ_ONLY) .withCreateContainerCmdModifier(createContainerCmd -> createContainerCmd.withIpv4Address("192.168.0.3")) .withCommand("ndbd"); private static GenericContainer ndbMysqld = new GenericContainer<>("mysql/mysql-cluster") .withNetwork(network) .withCommand("mysqld") .withCreateContainerCmdModifier(createContainerCmd -> createContainerCmd.withIpv4Address("192.168.0.10")) .withClasspathResourceMapping("mysql-cluster.cnf", "/etc/mysql-cluster.cnf", BindMode.READ_ONLY) .withClasspathResourceMapping("my.cnf", "/etc/my.cnf", BindMode.READ_ONLY) .waitingFor(Wait.forListeningPort()) .withEnv(ImmutableMap.of("MYSQL_DATABASE", CLUSTERJ_DATABASE, "MYSQL_USER", MYSQL_USER, "MYSQL_PASSWORD", MYSQL_PASSWORD)) .withExposedPorts(3306) .waitingFor(Wait.forListeningPort()); static { log.info("Start MySQL Cluster testcontainers extension...\n"); Stream.of(ndbMgmd, ndbd1, ndbMysqld).forEach(GenericContainer::start); String ndbUrl = ndbMgmd.getContainerIpAddress() + ":" + ndbMgmd.getMappedPort(1186); String mysqlUrl = ndbMysqld.getContainerIpAddress() + ":" + ndbMysqld.getMappedPort(3306); String mysqlConnectionString = "jdbc:mysql://" + mysqlUrl + "/" + CLUSTERJ_DATABASE + "?useUnicode=true" + "&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false"; System.setProperty("clusterj.connectString", ndbUrl); System.setProperty("clusterj.dataBaseName", CLUSTERJ_DATABASE); System.setProperty("spring.datasource.username", MYSQL_USER); System.setProperty("spring.datasource.password", MYSQL_PASSWORD); System.setProperty("spring.datasource.url", mysqlConnectionString); } }
В данном Extension'е мы поднимаем управляющую ноду кластера, одну дата ноду и MySQL ноду. После чего выставляем соответствующие настройки подключения для использования SpringBoot'ом, как раз те, что мы описывали в автоконфигурации стартера:
System.setProperty("clusterj.connectString", ndbUrl); System.setProperty("clusterj.dataBaseName", CLUSTERJ_DATABASE); System.setProperty("spring.datasource.username", MYSQL_USER); System.setProperty("spring.datasource.password", MYSQL_PASSWORD); System.setProperty("spring.datasource.url", mysqlConnectionString);
Далее напишем аннотацию, которая позволит нам декларативно поднимать контейнеры в тестах. Здесь все очень просто, используем наш Extension:
@Retention(RetentionPolicy.RUNTIME) @Target(ElementType.TYPE) @ExtendWith(MySQLClusterTcExtension.class) public @interface EnableMySQLClusterContainer { }
Наконец, напишем тест:
@Test void shouldGetUserViaClusterJ() { User newUser = session.newInstance(User.class); newUser.setId(1); newUser.setFirstName("John"); newUser.setLastName("Jonson"); session.persist(newUser); User userFromDb = session.find(User.class, 1); assertAll( () -> assertEquals(userFromDb.getId(), 1), () -> assertEquals(userFromDb.getFirstName(), "John"), () -> assertEquals(userFromDb.getLastName(), "Jonson")); }
В данном тесте показано, как мы можем достать запись по первичному ключу. Данный запрос эквивалентен SQL запросу:
SELECT * FROM user WHERE id = 1;
Сделаем еще один тест, с более сложной логикой:
@Test void queryBuilderTest() { QueryBuilder builder = session.getQueryBuilder(); QueryDomainType<User> userQueryDomainType = builder.createQueryDefinition(User.class); // parameter PredicateOperand propertyIdParam = userQueryDomainType.param("lastName"); // property PredicateOperand propertyEntityId = userQueryDomainType.get("lastName"); userQueryDomainType.where(propertyEntityId.equal(propertyIdParam)); Query<User> query = session.createQuery(userQueryDomainType); query.setParameter("lastName", "Jonson"); List<User> foundEntities = query.getResultList(); Optional<User> firstUser = foundEntities.stream().filter(u -> u.getId() == 1).findFirst(); Optional<User> secondUser = foundEntities.stream().filter(u -> u.getId() == 2).findFirst(); assertAll( () -> assertEquals(foundEntities.size(), 2), () -> assertTrue(firstUser.isPresent()), () -> assertTrue(secondUser.isPresent()), () -> assertThat(firstUser.get(), allOf( hasProperty("firstName", equalTo("John")), hasProperty("lastName", equalTo("Jonson")) ) ), () -> assertThat(secondUser.get(), allOf( hasProperty("firstName", equalTo("Alex")), hasProperty("lastName", equalTo("Jonson")) ) ) ); }
Для построения сложных запросов с условиями in, where, equal, like используется QueryBuilder. В данном тесте, мы вытаскиваем всех пользователей, у которых фамилия = Jonson. Данный запрос эквивалентен следующему SQL:
SELECT * FROM user WHERE lastName = 'Jonson';
Здесь тоже столкнулся с проблемой. Невозможно составить запрос вида:
SELECT * FROM user WHERE (lastName = 'Jonson' and firstName = 'John') or id = 2;
Данная возможность на данный момент не реализована. Можно посмотреть тест: andOrNotImplemented.
@SpringBootTest @ExtendWith(SpringExtension.class) @EnableAutoConfiguration @EnableMySQLClusterContainer class NdbClusterJTest { @Autowired private JdbcTemplate jdbcTemplate; @Autowired private SessionFactory sessionFactory; private Session session; @BeforeEach void setUp() { jdbcTemplate.execute("CREATE TABLE IF NOT EXISTS `user` (id INT NOT NULL PRIMARY KEY," + " firstName VARCHAR(64) DEFAULT NULL," + " lastName VARCHAR(64) DEFAULT NULL) ENGINE=NDBCLUSTER;"); session = sessionFactory.getSession(); } @Test void shouldGetUserViaClusterJ() { User newUser = session.newInstance(User.class); newUser.setId(1); newUser.setFirstName("John"); newUser.setLastName("Jonson"); session.persist(newUser); User userFromDb = session.find(User.class, 1); assertAll( () -> assertEquals(userFromDb.getId(), 1), () -> assertEquals(userFromDb.getFirstName(), "John"), () -> assertEquals(userFromDb.getLastName(), "Jonson")); } @Test void queryBuilderTest() { User newUser1 = session.newInstance(User.class); newUser1.setId(1); newUser1.setFirstName("John"); newUser1.setLastName("Jonson"); User newUser2 = session.newInstance(User.class); newUser2.setId(2); newUser2.setFirstName("Alex"); newUser2.setLastName("Jonson"); session.persist(newUser1); session.persist(newUser2); QueryBuilder builder = session.getQueryBuilder(); QueryDomainType<User> userQueryDomainType = builder.createQueryDefinition(User.class); // parameter PredicateOperand propertyIdParam = userQueryDomainType.param("lastName"); // property PredicateOperand propertyEntityId = userQueryDomainType.get("lastName"); userQueryDomainType.where(propertyEntityId.equal(propertyIdParam)); Query<User> query = session.createQuery(userQueryDomainType); query.setParameter("lastName", "Jonson"); List<User> foundEntities = query.getResultList(); Optional<User> firstUser = foundEntities.stream().filter(u -> u.getId() == 1).findFirst(); Optional<User> secondUser = foundEntities.stream().filter(u -> u.getId() == 2).findFirst(); assertAll( () -> assertEquals(foundEntities.size(), 2), () -> assertTrue(firstUser.isPresent()), () -> assertTrue(secondUser.isPresent()), () -> assertThat(firstUser.get(), allOf( hasProperty("firstName", equalTo("John")), hasProperty("lastName", equalTo("Jonson")) ) ), () -> assertThat(secondUser.get(), allOf( hasProperty("firstName", equalTo("Alex")), hasProperty("lastName", equalTo("Jonson")) ) ) ); } @Test void andOrNotImplemented() { QueryBuilder builder = session.getQueryBuilder(); QueryDomainType<User> userQueryDomainType = builder.createQueryDefinition(User.class); // parameter PredicateOperand firstNameParam = userQueryDomainType.param("firstName"); // property PredicateOperand firstName = userQueryDomainType.get("firstName"); // parameter PredicateOperand lastNameParam = userQueryDomainType.param("lastName"); // property PredicateOperand lastName = userQueryDomainType.get("lastName"); // parameter PredicateOperand idParam = userQueryDomainType.param("id"); // property PredicateOperand id = userQueryDomainType.get("id"); Executable executable = () -> userQueryDomainType.where(firstNameParam.equal(firstName) .and(lastNameParam.equal(lastName)) .or(idParam.equal(id))); UnsupportedOperationException exception = assertThrows(UnsupportedOperationException.class, executable); assertEquals("Not implemented.", exception.getMessage()); } @AfterEach void tearDown() { session.deletePersistentAll(User.class); session.close(); } }
Благодаря нашей аннотации @EnableMySQLClusterContainer, мы скрыли детали подготовки окружения для тестов. Также благодаря нашему стартеру, мы можем просто заинжектить в наш тест SessionFactory, и использовать ее для наших нужд, не заботясь о том, что ее нужно создавать вручную.
Все это концентрирует нас на написании бизнес логики тестов, а не обслуживающей инфраструктуры.
Также хочу обратить внимание на то, что запускать приложение, в котором используется ClusterJ нужно с параметром:
-Djava.library.path=/usr/lib/x86_64-linux-gnu/
который показывает путь до libndbclient.so. Без него ничего не заработает.
Заключение
Как по мне, ClusterJ хорошая вещь в тех системах, которые критичны к скорости доступа к данным, но мелкие недоработки и ограничения портят общее впечатление. Если у вас есть возможность выбирать и вам не принципиальна скорость доступа, полагаю, лучше использовать JDBC.
В статье не рассмотрена работа с транзакциями и блокировками, и так получилось довольно много.
На этом все, Happy Coding!
Полезные ссылки:
Весь код с проектом лежит тут
Страница загрузок
Информация о ClusterJ
Работа с Java и NDB Cluster
Книга Pro MySQL NDB Cluster
Подробнее про MySQL NDB Cluster тут и тут
Еще больше примеров тестов в самом репозитории MySQL

