╔═══╗╔═══╗╔═══╗╔═══╗╔╗─╔╗────╔═══╗╔══╗╔═══╗ ║╔══╝║╔═╗║║╔══╝║╔══╝║╚═╝║────║╔═╗║╚╗╔╝║╔══╝ ║║╔═╗║╚═╝║║╚══╗║╚══╗║╔╗─║────║╚═╝║─║║─║║╔═╗ ║║╚╗║║╔╗╔╝║╔══╝║╔══╝║║╚╗║────║╔══╝─║║─║║╚╗║ ║╚═╝║║║║║─║╚══╗║╚══╗║║─║║────║║───╔╝╚╗║╚═╝║ ╚═══╝╚╝╚╝─╚═══╝╚═══╝╚╝─╚╝────╚╝───╚══╝╚═══╝ 5HHHG HH HHHHHHH 9HHHA HHHHHHHH5 HHHHHHHHHHHHHHHHHH 9HHHHH5 5HHHHHHHHHHHHHHHHHHHHHHHHHHH HHHHHHHHHHHHHHHHHHHHHHHHHHHH ;HHHHHHHHHHHHHHHHHHHHHHHHHHA H2 HHHHHHHHHHHHHHHHHHHHHH HHHHHHHHHHHHHHHHHHHHHHH9 HHHHHHHHHHHHHHHHHHHHHHH AHHHHHHHHHHHHHHHHHHHHHH HHHHHHHHHHHHHHHHHHHHH9 iHS HHHHHHHHHHHHHHHHHHHHHHhh HHHHHHHHHHHHHHHHHH AA HHHHHHHHHHHHHH3 &H Hi HS Hr & H& H& Hi
Вступление
Хочу рассказать вам о разработке своей небольшой библиотеки на php. Какие же задачи она решает? Зачем я ее решил написать и почему она могла бы вам пригодиться? Что ж попытаюсь ответить на эти вопросы.
GreenPig (далее GP) – это н��большой помощник для работы с базой данных, который может дополнить функциональность любого, используемого вами php фреймворка.
Как и любой инструмент GP заточен под решение определенных задач. Он будет вам полезен, если вы предпочитаете писать запросы к БД на чистом sql и не используете Active record и прочие подобные технологии. К примеру, у нас на работе БД Oracle и зачастую запросы занимают несколько экранов с десятками джойнов, еще используются plsql функции, union all и т.д. и т.п., поэтому ничего другого, как писать запросы на чистом sql, не остается.
Но при таком подходе встает вопрос: как генерировать where часть sql запроса при поиске пользователями информации? GP нацелен, в первую очередь, на удобное составление средствами php where запроса любой сложности.
Но что же сподвигло меня к написанию этой библиотеки (кроме, конечно, получения интересного опыта)? Это три вещи:
Во-первых, это необходимость получения не стандартного плоского ответа из БД, а вложенного, древовидного массива.
[ [0] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 1 ['name'] => 'вес (кг)' ['value'] => 790 ], [1] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 2 ['name'] => 'количество месяцев в эксплуатации' ['value'] => 24 ], [2] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 3 ['name'] => 'лошадиные силы' ['value'] => 75 ], [3] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 10 ['name'] => 'диагональ экрана' ['value'] => 5 ], [4] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 8 ['name'] => 'вес (кг)' ['value'] => 0.12 ], [5] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 9 ['name'] => 'количество месяцев в эксплуатации' ['value'] => 1 ], [6] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 10 ['name'] => 'диагональ экрана' ['value'] => 5 ], [7] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 8 ['name'] => 'вес (кг)' ['value'] => 0.12 ], [8] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 9 ['name'] => 'количество месяцев в эксплуатации' ['value'] => 1 ], [9] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 10 ['name'] => 'диагональ экрана' ['value'] => 5 ], [10] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 8 ['name'] => 'вес (кг)' ['value'] => 0.12 ], [11] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 9 ['name'] => 'количество месяцев в эксплуатации' ['value'] => 1 ], [12] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 1 ['name'] => 'вес (кг)' ['value'] => 790 ], [13] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 2 ['name'] => 'количество месяцев в эксплуатации' ['value'] => 24 ], [14] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 3 ['name'] => 'лошадиные силы' ['value'] => 75 ], [15] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 1 ['name'] => 'вес (кг)' ['value'] => 790 ], [16] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 2 ['name'] => 'количество месяцев в эксплуатации' ['value'] => 24 ], [17] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 3 ['name'] => 'лошадиные силы' ['value'] => 75 ] ]
Чтобы получить древовидный массив, нам необходимо либо самим п��иводить результат в нужный вид, либо делать N запросов к БД для каждого товара. А если нам нужна пагинация, да еще и с сортировкой? GP способен решить эти проблемы. Вот пример выборки с GP:
[ [1] => [ ['prod_type'] => 'car' ['properties'] => [ [1] => [ ['name'] => 'вес (кг)' ['value'] => 790 ] [2] => [ ['name'] => 'количество месяцев в эксплуатации' ['value'] => 24 ] [3] => [ ['name'] => 'лошадиные силы' ['value'] => 75 ] ] ] [4] => [ ['prod_type'] => 'phone' ['properties'] => [ [10] => [ ['name'] => 'диагональ экрана' ['value'] => 5 ] [8] => [ ['name'] => 'вес (кг)' ['value'] => 0.12 ] [9] => [ ['name'] => 'количество месяцев в эксплуатации' ['value'] => 1 ] ] ] ]
И конечно при этом удобная пагинация и сортировка: ->pagination(1, 10)->sort('id').
Вторая причина не такая частая, но тем не менее она встречается (а в моем случае это самая главная причина). Если в БД хранятся некие сущности, и свойства этих сущностей динамические и задаются пользователями, то, когда вам понадобится поискать сущности по их свойствам, вам придется добавлять (join’ить) одну и ту же таблицу со значениями свойств (столько же раз, сколько используется свойств при поиске). Так вот GP поможет вам и подключить все таблицы и сгенерировать where запрос практически одной функцией. Ближе к концу статьи разберу этот случай подробно.
Ну и наконец, все это должно работать как для БД Oracle, так и для mySql. Также есть еще ряд возможностей, описанных в документации.
Вполне возможно, что я изобрел очередной велосипед, но я добросовестно искал и не нашел подходящее для меня решение. Если вы знаете библиотеку, которая решает эти задачи – напишите пожалуйста в комментариях.
Перед тем как непосредственно перейти к рассмотрению самой библиотеки и к примерам, скажу, что здесь будет только самая суть, без детальных объяснений. Если вам станет интересно как именно работает GP, можете посмотреть документацию, в ней я постарался подробно все изложить.
Подключение библиотеки
Библиотеку можно установить через composer: composer require falbin/green-pig-dao
Затем необходимо написать фабрику, через которую будете пользоваться данной библиотекой.
Класс Where
С помощью данного класса можно составить where часть sql запроса любой сложности.
Атомарная часть запроса
Рассмотрим наименьшую, атомарную часть запроса. Она описывается массивом: [колонка, знакСравнения, значение]
Пример: [‘name’, ‘like’, ‘%Вас%’]
- Первый элемент массива — это просто строка, вставляющаяся в sql запрос без изменений, а, следовательно, в ней можно писать sql функции. Пример:
['LOWER(name)', 'like', '%вас%'] - Второй элемент - это тоже строка, вставляющаяся в sql без изменений между двумя операндами. Может принимать следующие значения: =, >, <, >=, <=, <>, like, not like, between, not between, in, not in.
- Третий элемент массива может быть как числового, так и строкового типа. Where класс автоматически подставит в sql запрос вместо значения сгенерированный псевдоним.
- Элемент массива с ключом sql. Бывает нужно, чтобы значение вставлялось в sql код без изменений. Например, для применения функций. Этого можно добиться, указав в качестве ключа ‘sql’ (для 3го элемента). Пример:
[‘LOWER(name)’, ‘like’, ‘sql’ => "LOWER('$name')"] - Элемент массива с ключом bind — это массив для хранения биндов. Приведённый выше пример — неправильный с точки зрения безопасности. Нельзя вставлять переменные в sql – черевато инъекциями. Поэтому, в данном случае, нужно будет самому указывать псевдонимы, например так:
['LOWER(name)', 'like', 'sql' => "LOWER(:name)", 'bind'=> ['name' => $name] ] - Оператор in можно записать так:
['curse', 'not in', [1, 3, 5]]. Класс Where преобразует такую запись в следующий sql код:curse not in (:al_where_jCgWfr95kh, :al_where_mCqefr95kh, :al_where_jCfgfr9Gkh) - Оператор between можно записать так:
['curse', ' between', 1, 5]. Класс Where преобразует такую запись в следующий sql код:curse between :al_where_Pi4CRr4xNn and :al_where_WiPPS4NKiG
Но будьте внимательны, если третий и четвертый элемент массива это строки, то применяется особая логика. В данном случае считается, что идет выборка из диапазона дат и, следовательно, применяется sql функция приведения строки к дате. Функция преобразования к дате (у mySql и Oracle они разные) и ее параметры берутся из массива настроек (подробнее в документации). Массив['build_date', 'between', '01.01.2016', '01.01.2019']будет преобразован в sql:build_date between TO_DATE(:al_where_fkD7nZg5lU, 'dd.mm.yyyy hh24:mi::ss') and TO_DATE(:al_where_LdyVRznPF8, 'dd.mm.yyyy hh24:mi::ss')
Сложные запросы
Создадим экземпляр класса через фабрику: $wh = GP::where();
Чтобы указать логическую связь между «атомарными частями» запроса, необходимо использовать функции linkAnd() или linkOr(). Пример:
// sql: (old > 18 and old < 50) $wh->linkAnd([ ['old', '<', 18], ['old', '>', 50] ]); // sql: (old < 18 or old > 50) $wh->linkOr([ ['old', '<', 18], ['old', '>', 50] ]);
При использовании функций linkAnd/linkOr все данные сохраняются внутри экземпляра класса Where – $wh. Так же все «атомарные части», указанные в функции, берутся в скобки.
Sql любой сложности можно описать тремя функциями: linkAnd(), linkOr(), getRaw(). Рассмотрим на примере:
// sql: curse = 1 and (old < 18 or old > 50) $wh->linkAnd([ ['curse', '=', 1], $wh->linkOr([ ['old', '<', 18], ['old', '>', 50] ])->getRaw() ]);
В классе Where есть приватная переменная, в которой хранится сырое выражение. Методы linkAnd() и linkOr() перезаписывают эту переменную, поэтому при составлении логического выражения методы вкладываются друг в друга и переменная с сырым выражением содержит данные полученные из последнего выполненного метода.
Класс JOIN
Join - это класс, который генерирует join фрагмент sql кода. Создадим экземпляр класса через фабрику: $jn = GP::leftJoin('coursework', 'student_id', 's.id'), где:
- coursework – таблица, которую будем join’ить.
- student_id – столбец с внешним ключом из таблицы coursework.
- s.id – столбец таблицы с которой join’им, должен записываться вместе с псевдонимом таблицы (в данном случае псевдоним таблицы – s).
Сгенерированный sql: left JOIN coursework coursework_joM9YuTTfW ON coursework_joM9YuTTfW.student_id = s.id
При создании экземпляра класса мы уже описали условие соединения таблиц, но бывает необходимо уточнить и расширить условие. Функции linkAnd/linkOr помогут это сделать: $jn->linkAnd(['semester_number', '>', 2])
Сгенерированный sql: inner JOIN coursework coursework_Nd1n5T7c0r ON coursework_Nd1n5T7c0r.student_id = s.id and (semester_number > :al_where_M1kEcHzZyy)
Если есть несколько присоединяемых таблиц, их можно объединить в классе: CollectionJoin.
Класс Query
Это основной класс, для работы с БД, через него происходит выборка, запись, обновление и удаление данных. Также можно проводить определенную обработку данных, полученных из БД.
Рассмотрим типичный пример.
Создадим экземпляр клас��а через фабрику: $qr = GP::query();
Теперь зададим sql шаблон, подставляем в sql шаблон необходимые для данного сценария значения и скажем, что хотим получить одну запись, а конкретно данные из колонки average_mark.
$rez = $qr->sql("select /*select*/ from student s inner join mark m on s.id = m.student_id inner join lesson l on l.id = m.lesson_id /*where*/ /*group*/") ->sqlPart('/*select*/', 's.name, avg(m.mark) average_mark', []) ->whereAnd('/*where*/', ['s.id', '=', 1]) ->sqlPart('/*group*/', 'group by s.name', []) ->one('average_mark');
Результат: 3,16666666666666666666666666666666666667
Выборка из БД с вложенными параметрами
Больше всего мне не хватало возможности получить выборку из базы данных в древовидном виде, с вложенными свойствами. Поэтому в библиотеки GP реализована такая возможность, причем глубина вложенности не ограничена.
Проще всего рассмотреть принцип работы на основе примера. Для рассмотрения возьмём такую схему базы данных:
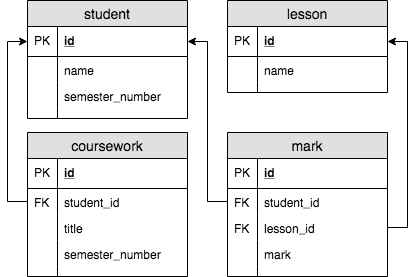
Cодержимое таблиц:
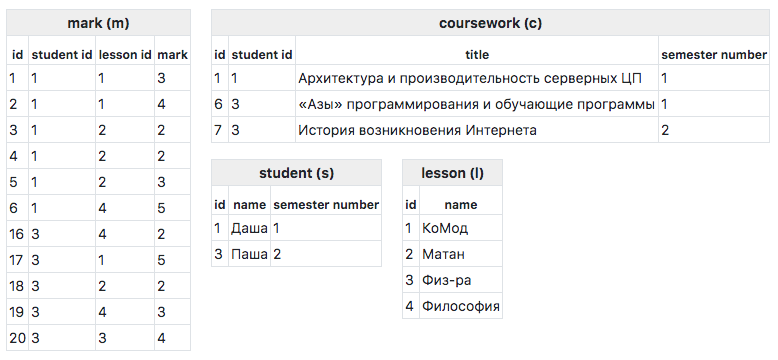
Зачастую при запросе к БД хочется получить не плоский ответ, а древовидный. К примеру, выполнив такой запрос:
SELECT s.id, s.name, c.id title_id, c.title FROM student s INNER JOIN coursework c ON c. student_id = s.id WHERE s.id = 3
Получим плоский результат:
[ 0 => [ 'id' => 3, 'name' => 'Паша', 'title_id' => 6, 'title' => '«Азы» программирования и обучающие программы', ], 1=> [ 'id' => 3, 'name' => 'Паша', 'title_id' => 7, 'title' => 'История возникновения Интернет' ] ]
С помощью GP можно получить такой результат:
[ 3 => [ 'name' => 'Паша', 'courseworks' => [ 6 => ['title' => '«Азы» программирования и обучающие программы'], 7 => ['title' => 'История возникновения Интернет'] ] ] ]
Чтобы добиться такого результата, необходимо в функцию all (функция возвращает все строки запроса) передать массив с опциями:
all([ 'id'=> 'pk', 'name' => 'name', 'courseworks' => [ 'title_id' => 'pk', 'title' => 'title' ] ])
Массив $option в функциях aggregator($option, $rawData) и all($options) строится по следующим правилам:
- Ключи массива – названия колонок. Элементы массива – новые названия для колонок, можно вписа��ь старое название.
- Существует одно зарезервированное слово для значений массива –
pk. Оно говорит, что данные будут сгруппированы по этой колонке (ключ массива — это название колонки). - На каждом уровне должен быть только один
pk. - В агрегированном (результирующем) массиве в качестве ключей будут использоваться значения из колонки, объявленной
pk. - Если необходимо часть колонок поместить на уровень ниже, то в качестве ключа массива используется новое, выдуманное название, а в качестве значения будет массив, строящийся по правилам описанным выше.
Рассмотрим более сложный пример. Допустим нам надо получить всех студентов с названием их курсовых и со всеми оценками по всем предметам. Мы бы хотели получить это не в плоском виде, а в древовидном, без дублей. Ниже приведен нужный запрос к БД и результат.
SELECT s.id student_id, s.name student_name, s.semester_number, c.id coursework_id, c.semester_number coursework_semester, c.title coursework_title, l.id lesson_id, l.name lesson, m.id mark_id, m.mark FROM student s LEFT JOIN coursework c ON c.student_id = s.id LEFT JOIN mark m ON m.student_id = s.id LEFT JOIN lesson l ON l.id = m.lesson_id ORDER BY s.id, c.id, l.id, m.id
Результат нас не устраивает:

Чтобы добиться поставленной задачи, нужно написать следующий массив $option:
$option = [ 'student_id' => 'pk', 'student_name' => 'name', 'courseworks' => [ 'coursework_semester' => 'pk', 'coursework_title' => 'title' ], 'lessons' => [ 'lesson_id' => 'pk', 'lesson' => 'lesson', 'marks' => [ 'mark_id' => 'pk', 'mark' => 'mark' ] ] ];
Запрос к БД:
// Создаем экземпляры классов Query с помощью фабрики. Подробнее в документации в разделе УСТАНОВКА // (здесь случай компонента для yii2) $qr = Yii::$app->gp->query( "SELECT s.id student_id, s.name student_name, s.semester_number, c.id coursework_id, c.semester_number coursework_semester, c.title coursework_title, l.id lesson_id, l.name lesson, m.id mark_id, m.mark FROM student s LEFT JOIN coursework c ON c.student_id = s.id LEFT JOIN mark m ON m.student_id = s.id LEFT JOIN lesson l ON l.id = m.lesson_id ORDER BY s.id, c.id, l.id, m.id"); // результаты варианта 1, варианта 2 и варианта 3 одинаковые // вариант 1 $result = $qr->all($option); // вариант 2 $result = $qr->aggregator($option, $qr->all()); // вариант 3 $qr->all(); $result = $qr->aggregator($option, $qr->rawData());
Функция aggregator может обработать любой массив со структурой схожей с результатом запроса к БД, по правилам описанным в $option.
Переменная $result содержит следующие данные:
[ 1 => [ 'name' => 'Даша', 'courseworks' => [ 1 => ['title' => 'Архитектура и производительность серверных ЦП'], ], 'lessons' => [ 1 => [ 'lesson' => 'КоМод', 'marks' => [ 1 => ['mark' => 3], 2 => ['mark' => 4] ] ], 2 => [ 'lesson' => 'Матан', 'marks' => [ 3 => ['mark' => 2], 4 => ['mark' => 2], 5 => ['mark' => 3] ] ], 4 => [ 'lesson' => 'Философия', 'marks' => [ 6 => ['mark' => 5] ] ] ] ], 3 => [ 'name' => 'Паша', 'courseworks' => [ 1 => ['title' => '«Азы» программирования и обучающие программы'], 2 => ['title' => 'История возникновения Интернета'] ], 'lessons' => [ 1 => [ 'lesson' => 'КоМод', 'marks' => [ 17 => ['mark' => 5] ] ], 2 => [ 'lesson' => 'Матан', 'marks' => [ 18 => ['mark' => 2] ] ], 3 => [ 'lesson' => 'Физ-ра', 'marks' => [ 20 => ['mark' => 4] ] ], 4 => [ 'lesson' => 'Философия', 'marks' => [ 16 => ['mark' => 2], 19 => ['mark' => 3] ] ], ] ] ]
К слову, при пагинации с агрегированным запросом считаются только верхние, самые основные данные. В приведенном выше примере для пагинации будет только 2 строчки.
Многократное объединение с самим собой во имя поиска
Как я уже писал ранее, основная задача моей библиотеки – это упростить генерацию where части для select запросов. Так в каком случае нам может понадобиться многократно join’нить одну и ту же таблицу для where запроса? Один из вариантов, это когда у нас есть некий товар, свойства которого заранее неизвестны и они будут добавляться пользователями, а нам необходимо дать возможность поискать товары по этим динамическим свойствам. Проще всего объяснить на упрощенном примере.
Допустим у нас есть интернет магазин, продающий компьютерные комплектующие, причем у нас нет строгого ассортимента и мы периодически будем закупать то одни комплектующие, то другие. Но мы бы хотели описать все наши товары единой сущностью и осуществлять поиск по всем товарам. Итак, какие же сущности можно выделить с точки зрения бизнес логики:
- Товар. Самая главная сущность, вокруг которой все строится.
- Тип товара. Это можно представить как корневое свойство для всех других свойств товара. К примеру, в нашем маленьком магазине это пока только: ОЗУ, SSD и HDD.
- Свойства товара. В нашей реализации к любому типу товара можно применить любое свойство, выбор остается на совести менеджера. В нашем магазине менеджеры внесли только 3 свойства: объем памяти, форм-фактор и DDR.
- Значение товара. То значение, которое будет вбивать покупатель при поиске.
Вся описанная выше бизнес-логика подробно отражена на картинке снизу.

Например, у нас есть товар: оперативная память DDR 3 на 16 Гб. На схеме это можно отобразить так:

Структура и данные БД наглядно видны на следующем рисунке:

Как мы видим из схемы все значения всех свойств хранятся в одной таблице val (к слову, в нашем упрощенном варианте все значения у свойств числовые). Поэтому, если мы захотим поискать одновременно по нескольким свойствам со связкой AND, то получим пустую выборку.
Вот к примеру, покупатель ищет товары подходящие под такой запрос: объем памяти должен быть больше 10 Гб и форм фактор должен быть 2.5 дюйма. Если написать sql так, как показано ниже, то получим пустую выборку:
select * from product p inner join val v on v.product_id = p.id where (v.property_id = 1 and v.value > 10) AND (v.property_id = 3 and v.value = 2.5)
Так как значения всех свойств хранятся в одной таблице, то для поиска по нескольким свойствам необх��димо join’ить таблицу val для каждого свойства, по которому будет поиск. Но тут есть нюанс, join соединяет таблицы «по горизонтали» (к слову union all соединяет «по вертикали»), ниже приведен пример:

Такой результат нас не устраивает, мы бы хотели увидеть все значения в одном столбце. Для этого необходимо join’нить таблицу val на 1 раз больше, чем свойств по которым осуществляется поиск.

Мы уже близки к автоматической генерации sql запроса. Давайте рассмотрим функцию
whereWithJoin ($aliasJoin, $options, $aliasWhere, $where), которая выполнит всю работу:
- $aliasJoin - псевдоним в базовом шаблоне вместо которого подставится sql часть с join’ами.
- $options - массив с описаниями правил генерации join части.
- $aliasWhere - псевдоним в базовом шаблоне вместо которого подставится where sql часть.
- $where - экземпляр класса Where.
Давайте рассмотрим на примере: whereWithJoin('/*join*/', $options, '/*where*/', $wh).
Сначала создадим переменную $options: $options = ['v' => ['val', 'product_id', 'p.id']];
v – псевдоним таблицы. Если данный псевдоним встретится в $wh, то будет подключена join’ом новая таблица val (где product_id - это внешний ключ таблицы val, а p.id - это первичный ключ для таблицы с псевдонимом p), для нее сгенерирован новый псевдоним и этот псевдоним заменит v в where.
$wh – экземпляр класса Where. Формируем все тот же запрос: объем памяти должен быть больше 10 Гб и форм фактор должен быть 2.5 дюйма.
$wh->linkAnd([ $wh->linkAnd([ ['v.property_id', '=', 1], ['v.value', '>', 10] ])->getRaw(), // оборачиваем в скобку $wh->linkAnd([ ['v.property_id', '=', 3], ['v.value', '=', 2.5] ])->getRaw(),// оборачиваем в скобку ]);
При создании where запроса, необходимо оборачивать в скобки часть с id свойством и его значением, это говорит функции whereWithJoin(), что в этой части псевдоним таблицы будет одинаковый.
$qr->sql("select p.id, t.name type_name, pr.id prop_id, pr.name prop_name, v.id val_id, v.value from product p inner join type t on t.id = p.type_id inner join val v on v.product_id = p.id inner join properties pr on pr.id = v.property_id /*join*/ /*where*/") ->whereWithJoin('/*join*/', $options, '/*where*/', $wh) // Получаем выборку со вложенными значениями. ->all([ 'id' => 'pk', 'type_name' => 'type', 'properties' => [ 'prop_id' => 'pk', 'prop_name' => 'name', 'values' => [ 'val_id' => 'pk', 'value' => 'val' ] ] ]);
Просматриваем сгенерированный sql, бинды и время выполнения запроса: $qr->debugInfo():
[ [ 'type' => 'info', 'sql' => 'select p.id, t.name type_name, pr.id prop_id, pr.name prop_name, v.id val_id, v.value from product p inner join type t on t.id = p.type_id inner join val v on v.product_id = p.id inner join properties pr on pr.id = v.property_id inner JOIN val val_mIQWpnHhdQ ON val_mIQWpnHhdQ.product_id = p.id inner JOIN val val_J0uveMpwEM ON val_J0uveMpwEM.product_id = p.id WHERE ( val_mIQWpnHhdQ.property_id = :al_where_leV5QlmOZN and val_mIQWpnHhdQ.value > :al_where_ycleYAswIw ) and ( val_J0uveMpwEM.property_id = :al_where_dinxDraTOE and val_J0uveMpwEM.value = :al_where_wZJhUqs74i )', 'binds' => [ 'al_where_leV5QlmOZN' => 1, 'al_where_ycleYAswIw' => 10, 'al_where_dinxDraTOE' => 3, 'al_where_wZJhUqs74i' => 2.5 ], 'timeQuery' => 0.0384588241577 ] ]
Выводим исходную выборку из БД $qr->rawData():
[ [ 'id' => 3, 'type_name' => 'SSD', 'prop_id' => 1, 'prop_name' => 'Объем памяти', 'val_id' => 5, 'value' => 512 ], [ 'id' => 3, 'type_name' => 'SSD', 'prop_id' => 3, 'prop_name' => 'Форм-фактор', 'val_id' => 6, 'value' => 2.5 ], [ 'id' => 4, 'type_name' => 'SSD', 'prop_id' => 1, 'prop_name' => 'Объем памяти', 'val_id' => 7, 'value' => 256 ], [ 'id' => 4, 'type_name' => 'SSD', 'prop_id' => 3, 'prop_name' => 'Форм-фактор', 'val_id' => 8, 'value' => 2.5 ], [ 'id' => 6, 'type_name' => 'HDD', 'prop_id' => 1, 'prop_name' => 'Объем памяти', 'val_id' => 11, 'value' => 1024 ], [ 'id' => 6, 'type_name' => 'HDD', 'prop_id' => 3, 'prop_name' => 'Форм-фактор', 'val_id' => 12, 'value' => 2.5 ] ]
Выводим выборку из БД в древовидном виде $qr->aggregateData():
[ 3 => [ 'type' => 'SSD', 'properties' => [ 1 => [ 'name' => 'Объем памяти', 'values' => [ 5 => ['val' => 512] ] ], 3 => [ 'name' => 'Форм-фактор', 'values' => [ 6 => ['val' => 2.5] ] ] ] ], 4 => [ 'type' => 'SSD', 'properties' => [ 1 => [ 'name' => 'Объем памяти', 'values' => [ 7 => ['val' => 256] ] ], 3 => [ 'name' => 'Форм-фактор', 'values' => [ 8 => ['val' => 2.5] ] ] ] ], 6 => [ 'type' => 'HDD', 'properties' => [ 1 => [ 'name' => 'Объем памяти', 'values' => [ 11 => ['val' => 1024] ] ], 3 => [ 'name' => 'Форм-фактор', 'values' => [ 12 => ['val' => 2.5] ] ] ] ] ]
Подводя итог данного раздела статьи, постараюсь формализовать задачу, которую решает функция whereWithJoin(), абстрагируясь от конкретного примера.
Функция whereWithJoin() подойдёт, если необходимо написать запрос, где в рамках одной таблицы n колонок идентифицируют сущность объекта, а в m колонках записывается значение объекта. Причем n и m могут принимать значения от 1 и больше и в качестве значений могут быть id записей из других таблиц. И нам необходимо поискать объекты по нескольким сущностям, причем логическая связка между сущностями AND.
Более подробно с библиотекой можно ознакомиться прочитав документацию и просмотрев код на GitHub.

