Я из компании Luxoft.
Предлагаю ознакомиться с расшифровкой доклада Андрей Сальников из Data Egret "Инструменты создания бэкапов PostgreSQL" . В конце обновленная сводная таблица по инструментам
Данный доклад посвящен доступным инструментам бэкапирования PostgreSQL. Логические backup, бинарные backup, встроенные средства бэкапирования и сторонние инструменты. Нужны ли инкрементальные backup, когда они могут действительно помочь. Посмотрим, когда и какой инструмент уместнее использовать. Как лучше автоматизировать процесс бэкапирования и проверки целостности сделанного бэкапа. Посмотрим вблизи на инструменты, такие как pg_dump, pg_basebackup, barman, wal-e, wal-g, pgbackrest, BART и pg_probackup.
Меня зовут Сальников Андрей, я сотрудник компании Data Egret и этот доклад будет посвящён инструментам создания бэкапов в PostgreSQL.

Сначала о том, кто мы, моя компания. Основная наша деятельность: мы работаем как удалённые администраторы и у нас достаточно большое количество клиентов. Есть огромные базы, есть куча маленьких баз, есть всевозможные смеси, когда одна большая база или кучка маленьких. Также мы оказываем услуги консультирования и аудита – это случай если людям не нужна постоянная поддержка, но нужна какая-то экспертиза.
Так как PostgreSQL является открытым продуктом, то мы, естественно, участвуем во всевозможных конференциях, в плане того, что делимся своим опытом и всячески помогаем продвижению PostgreSQL. Потому что база данных PostgreSQL действительно хорошая. И получается так, что мы видели довольно много профилей нагрузки: DWH нагрузки, и WEB нагрузки, и смеси нагрузок. И базы падали по-разному. Опыта достаточно много.

Это самая интересная часть доклада. Зачем нужны backup-ы? На самом деле они нужны, чтобы мы могли отдыхать спокойно, чтобы могли спать спокойно, чтобы мы могли тусоваться на концертах спокойно. Вот, это основная цель с точки зрения базы зачем нужны backup-ы. Чтобы все было спокойно в нашей жизни. Потому что, если есть backup-ы проверенные, то мы можем всем этим заниматься. А вот что там с базой произойдет это уже дело десятое.

Какой есть ассортимент инструментов для создания бэкапов в мире PostgreSQL? Это встроенный инструмент pg_dump, pg_dumpall или pg_restore для восстановления. Это единственный инструмент, который позволяет делать вам логическое бэкапирование. То есть pg_dump он вам может, как в SQL вывалить, так и в небольшом бинарном формате вывалить данные. И он идет из коробки с PostgreSQL.
Следующий инструмент (pg_basebackup) для создания бэкапов, который тоже идет из коробки и дальше начиная с этого инструмента, и дальше они все будут инструменты для создания бинарных бэкапов базы данных. Pg_basebackup тоже инструмент, идущий из коробки, который позволяет нам наливать реплики для PostgreSQL и снимать бинарную копию базы данных, снимать персистентную базу данных и, если мы хотим еще во времени иметь возможность архивироваться, то мы можем настроить PostgreSQL так, чтобы архивные логи его сваливать на какой-то диск. Это вот базовые инструменты. Они хорошие, они делают, выполняют свой функционал на 5, но они неудобные с точки зрения управления и какой-то массовости. Когда у вас 20 баз данных, это нужно будет вам заниматься шелскриптингом самостоятельно.
Следующие два инструмента специфичные, чисто облачные инструменты – это wal-e и wal-g. Разрабатывают их одни и те же ребята, но разработка wal-e закончилась, и они переключились на wal-g. Эти инструменты ориентированы для в основном для AWS и для хранения в S3. Wal-e еще умеет работать с Google Cloud, с Azure и с дисковой системой, просто вы можете указать какой-то удаленный диск. Wal-g работает только с AWS, только с S3. Ну или любым другим с S3 похожим интерфейсом. Мы их используем, хорошие штуки. Я дальше в деталях буду разбирать каждый инструмент.

И на следующей пачке инструментов, это инструменты, которые опираются на pg_basebackup или используют его напрямую, или каким-то образом реализуют его функционал. Они все написаны разработчиками, которые коммитят в основной PostgreSQL и имеют свой форк коммерческий, который продвигают в своем кругу влияния.
Наиболее популярный инструмент barman, который у нас используется довольно широко в стране. Это по сути дела обертка на Python вокруг pg_basebackup. Еще он может работать по ssh протоколам. Очень интересный и очень многообещающий инструмент pgbackrest. разработчиками занимаются PostgreSQL и активно в него коммитят. Изначально он был написан на Python. Сейчас версия, которая используется — она написана на C для ускорения и возможности параллельного выполнения снятия бэкапов.
Pg_probackup – эта утилита от наших коллег российских в PostgreSQL Professional, которая позволяет делать инкрементальные backup-ы, такие достаточно небольшого размера.
И последняя утилита это backup and recover tool (BART) от компании EnterpriseDB. У нас она не очень популярна. Она в основном для CentOS и Red Hat. Для Ubuntu с ней, по-моему, тяжело. И в связи с малой популярностью BART у нас, ее (BART) почти нет нигде в инсталляциях.

Я бы попытался по этим инструментам разбить на какие-то вещи, которые важны.
Первое нам важно, как мы будем это хранить, на каких дисках и на каких сервисах. И там есть список характеристик, по которым мы пройдемся.
Следующее разделения данных, тут я подразделяю то, что можем ли мы при снятии бэкапа или восстановлении бэкапа, отпилить от целого истанса (сервера) базы данных какой-то кусочек и работать дальше с ним как с целостным, с целостной базой.
Насколько они поддерживают разные версии БД.
Какие режимы работы у них есть в плане параллельности, в плане какой-то автоматизации и тому подобное.
И сервисность это насколько мы можем их выделить в отдельный сервис, который сам будет ходить по базам данных и по какому-то расписанию снимать backup-ы.
Валидирование — хотелось чтобы бэкап еще проверялся в плане того, что мы из него гарантировано потом сможем восстановится и у нас будет нормальная, не поломанная база.
И теперь вот, по этим шести большим пунктам пройдемся более детально. И буду помечать там какой инструмент, что нам даст.

По хранению, в файловой системе хранить они могут все, то есть мы может перемонтировать диск наш к операционке и копировать туда backup-ы. Все инструменты это позволяют делать. Примонтированный сетевой диск — это в принципе тоже самое, потому что это в нашей локальной файловой системе получается.
В AWS (S3) у нас могут работать три инструмента — это wal-g, wal-e, pgbackrest. Потому что среди вот таких утилит: barman и так далее, он единственный, который умеет работать с AWS (S3).
С Azure только wal-e. Google Cloud только wal-e.

- Логическую копию данных нам предоставляет только pg_dump, pg_dumpall. Разница между ними, то что pg_dumpall обрабатывает весь инстанс (сервер) базы данных, в pg_dump вы можете указать конкретную базу данных на инстансе и работать с ней.
- Бинарный копии — все остальные.
- Немаловажный фактор при хранении, это то что, если у нас ограничено каким-то образом по дисковым ресурсам, то частенько возникают ситуации, когда мы разбиваем базу данных по разным табличное пространствам. Это верно и для железных серверов, потому что не хочется мучиться с RAID. Это верно для облаков, потому что потому что там есть определенное ограничение, особенно когда берете тачку с NVME дисками и сколько подключено, столько подключено. У AWS инстансы расширяются, но EBS дисками. И при восстановлении данных, нам будет важно, что мы могли бы перераспределить эти табличные пространства, назначить их по новым путям и на новые диски. И вот это хорошее свойство присутствует у wal-e. В wаl-g пока не умеют с этим работать. Pg_probackup умеют с этим работать. Barman, basebackup, pgbackrest. Эта вещь бывает довольно часто важна, особенно когда да у вас 8-10 ТБ базы данных. У нас среди клиентов production почти все эти базы данных развалены по табличным пространствам.

Теперь о том, какого размера у нас могут быть backup. Это всё пойдёт в контексте бинарных backup. Понятное дело, что бинарные backup — это сколько у нас база весит, столько мы и скопировали. Весит 8 ТБ, мы скопировали 8 ТБ. 1 МБ весит 1 МБ, скопировали. Как экономить место, когда мы хотим длинную цепочку backupов? Для этого придумали некоторые инструменты. То есть, база данных хранит данные в своих файлах. Если у нас есть длиная архивная база данных, то обычно мы меняем там небольшой % этих файлов. И для этого дела придумали дифференциальный backup.
Дифференциальный backup что из себя представляет? Мы смотрим какие файлики изменились и только копируем на хранилище, где хранить backup. А все остальные файлы мы хардлинком просто прилинкуем к этой базе данных. Получается, что мы тем самым экономим место. И при этом можем спокойно удалить старые backupы базы данных, не попортив более свежие.
Эта штука хорошая, но решили пойти дальше и придумали инкрементальные backup. Инкрементальные backupы есть два вида.
Первый это на файловом уровне. От дифференциального backup отличается только тем, что дифференциальный backup ориентируется у вас на полный backup базы данных, и по отношению полному backup копирует diff файлов и копирует. Инкрементальный backup может ориентироваться на дифференциальные backupы, копирует только те изменившиеся файлы, которые изменились по сравнению с дифференциальным backup. Для инкрементального нужна будет вся цепочка бекапов. То есть основной backup -> 1-й инкрементальный backup (он всегда будет дифференциальным) -> дальше все инкрементальные backupы. Дифференциальный backup всегда ориентируется на полный backup базы данных. Инкрементальный может ориентироваться на другие виды backup.
Pg_probackup и BART пошли по пути создания инкрементальных backup по блоку. Потому что мы можем изменить не весь файл, а блок данных. И эти утилиты бегут по wal файлам и выбирают у вас ровно те блоки, которые изменились. В backup копируют именно вот эти блоки. Для того, чтобы восстановиться с таким инкрементальным backup, вам тоже нужна будет полная копия базы данных и плюс ещё нужно сохранить вот эти инкрементальные кусочки, которые набирают из wal. Это накладывает некоторые ограничения утилиты, потому что они должны бегать по wal файлам. У PostgreSQL Professional наложен еще слой на файловую структуру базы данных. Поэтому они довольно быстро эти блоки ищут. Такие инкрементальные backup получаются совсем небольшими. Если у вас меняется небольшой % базы и из-за того, что в wal файл пишется довольно много технической информации, эти утилиты бекапят по десяткам килобайтам данных для 1 wal.

Дальше разделение данных. Тут подразумевается то, что, если нам нужно бекапировать не всё. Или восстанавливать не всё. Это возможно только при логических backup, и это нам позволяет делать только pg_dump. Утилиты довольно широкий функционал предоставляют. Pg_dump может позволить вам сдампить базу данных, структуру, если вам нужна. Можете конкретно одну таблицу сдампить или можете исключить одну таблицу из дампа или список таблиц сдампить, список исключить. Функционал довольно широкий в этом плане. Минус за это то, что при восстановлении с такого дампа, если у вас большая база данных, вам придется потратить достаточно много времени на чтобы восстановиться с него, потому что это всё нужно проигрывать на чистом instance PostgreSQL.
Очень удобны эти утилиты использовать случай, когда мы переоценили свои силы и на создавали кучу мелких баз данных. Мы можем их слить в один instance. Мы можем распилить так, если мы опять теперь оценили наши силы, у нас распухла база данных или меняем архитектуру там с монолита на сервисную и распиливаем данные. Pg_dump в этом случае единственная вещь, которая позволяет это делать безболезненно.
Ещё можно восстановить одну БД и вот тут вот указан pgbackrest. У него есть такая фишка, то что мы можем указать, что нам из бинарного backup нужна только одна база данных. Что он делает? Он восстанавливает база данных по умолчанию из backup, это template и postgres и ту базу данных, которую мы указали. Все остальные базы данных, он файлы обнуляет и делает нулевой длины. То есть у PostgreSQL прозрачная структура хранения баз данных в файлах, там можно на этом уровне, как бы сократить восстанавливаемую базу данных. Допустим нам нужно найти какие срочные данные из бинарника, не хочется 10 ТБ базу поднимать, у нас там две базы, и мы поднимаем одну, которая допустим 5ТБ всего занимает. В данном случае, конечно консистентность нарушается, но для каких-то быстрых решений, когда вам необходимо срочно кровь из носа поднять данные с большой базы данных, которых несколько, то это очень хорошие фичи, которые есть. Но как полноценную backup базы не стоит рассматривать при восстановлении. То есть, это именно для аварийных работ.

Как обстоит работа с множеством версий БД? Тут тоже всё достаточно интересно. Pg_dump очень хорош в плане того, что мы не привязаны к тому, в какую версию БД восстанавливаться. Там есть режим plain text и это просто чистый SQL, который описывает всю структуру базы данных, все данные. Вы можете в принципе оттуда восстановиться куда хотите, в MySQL, в MSSQL, в Oracle с небольшими правками этого дампа. Между мажорными версиями PostgreSQL тоже достаточно легко использовать эти дампы.
Мульти-версионность, что под этим подразумеваю? Это то, что насколько утилита может обрабатывать разные версии баз данных и работать одновременно с PostgreSQL 9.6, 10, 11. Все, кроме встроенных от pg_dump и pg_basebackup, потому что они привязаны к конкретной версии, с которой идут. Остальные ориентируется на эти утилиты. Им можно указывать где находится pg_basebackup, pg_dump разных версий. Они соответственно с версией PostgreSQL выбирают актуальную утилиту для снятия backup.
Для создания реплик, standby серверов подходят все утилиты, кроме pg_dump, потому что это логические backup-ы. Используя любую из этих утилит, вы можете, восстановить серверы и подключить к мастеру для работы, как реплика этого сервера.

Как могут сниматься backup-ы вообще, какие режимы существуют для снятия бэкапов. Можно просто копировать файлы стандартными средствами операционки: по ssh (rsync, scp) протоколу и возможно какие-то другие утилиты, которые есть. Почему такая возможность есть, потому что они позволяют параллелить копирование. Pgbackrest только так работает, barman он может работать так, а может работать по протоколу PostgreSQL.
Протокол PostgreSQL — когда утилита бэкапирования подключается к PostgreSQL и по протоколу репликации тянет все файлы и плюс еще архивные логи, которые возникают в процессе снятия бэкапа. Это умеют все остальные и barman.
Бэкап с реплики умеют в принципе все, это зависит от версии PostgreSQL. С PostgreSQL 10 и 11 мы можем с реплики снимать backup-ы. Но я этого не рекомендую делать, вообще никто из нашей компании не будет это рекомендовать делать. Потому что есть ситуации, когда проморгали по мониторингу, месяц снимали с реплики бэкап, которая отвалилась от мастер-сервера и не актуальна. То есть backup-ы в любом случае всегда нужно снимать с мастер-сервера. Только в таком случае вы будете уверены то, что у вас действительно актуальная бэкап база данных.
Многопоточность бэкапов — это умеют все, потому что все по разным причинам, кто-то через ssh протокол, кто-то реализовал на уровне копирования базы данных. Кроме pg_basebackup и BART, потому что BART операция только на pg_basebackup при снятии бэкапа и он, к сожалению, однопоточный и не будет многопоточный.
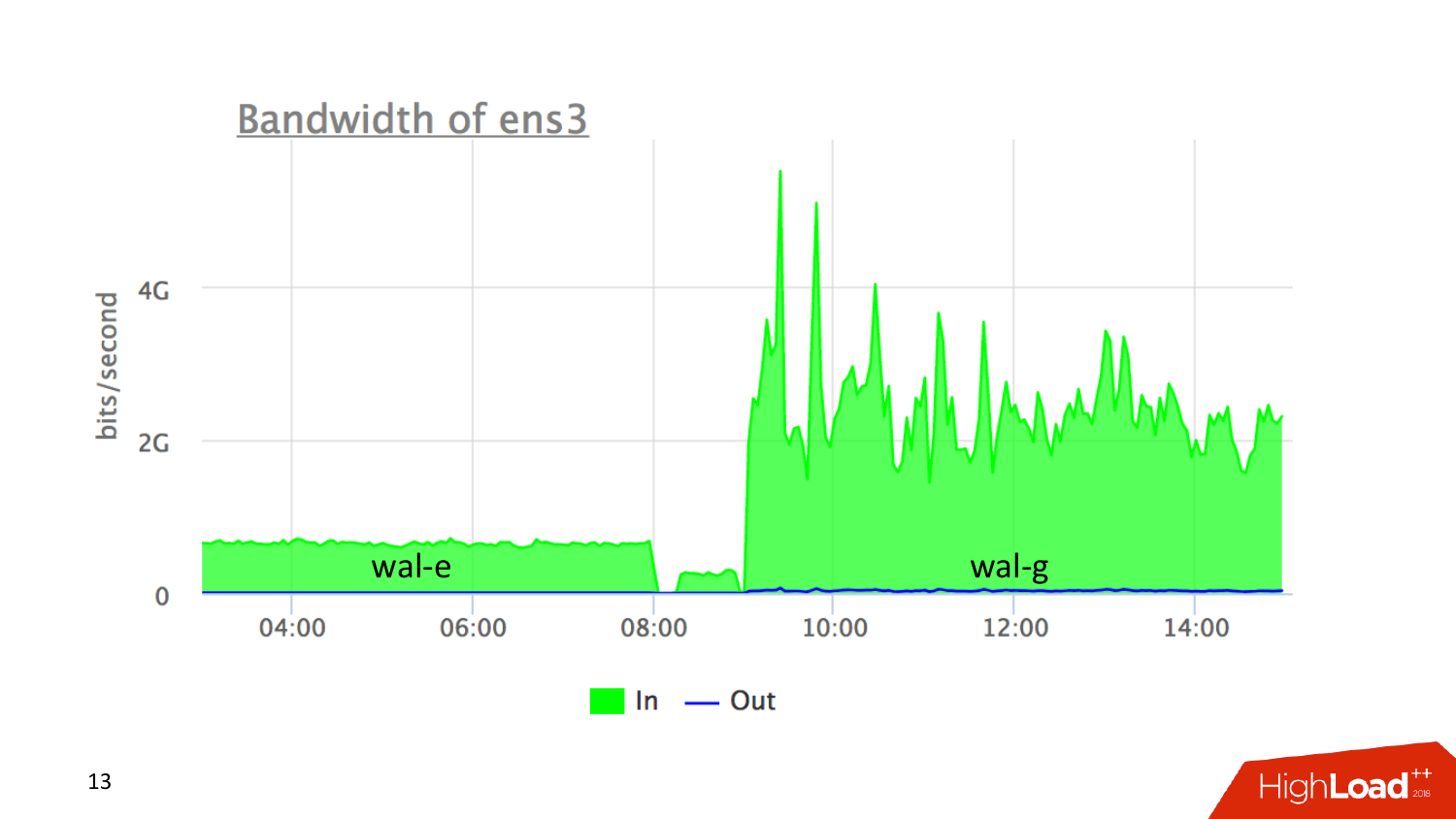
Пример многопоточности. Я восстанавливал 8 ТБ базу данных. Когда будете ориентироваться на выбор системы для снятия бэкапов, то знайте что wal-e написан на Python, wal-g написан на Golang. Мне 8 ТБ базу приходилось восстанавливать. Wal-e уперся в ограничение Python и тянул меня с AWS со скоростью 600 мбит/с. Когда я переключился на wal-g, то у него был ситуация, что он не мог работать с бэкапами wal-e, но мог тянуть wal файлы. Поэтому вот эта вот картина по середиине — это восстановление базы данных. Дальше накатывал wal, которые лежали там в S3 и к определенной точке во времени восстанавливался. Wal-e уперся в ограничение Python и параллелизм в Python она такой условный. A wal-g уперся в интерфейс S3, то есть насколько быстрый S3 каждый момент мог отдавать, настолько быстро он и забирал. В среднем это было 2 гбит/с, что достаточно хорошо. То есть с wal-e час изменений в базу получали за 45 минут накатывания бекапа. С wal-g получилось, что они час изменения базы данных накатывали где-то минут за 5.

Режимы работы, что тут есть у нас интересного в системе бэкапирования.
- Восстановление во времени к определенной точки. Если у нас есть архивные логи, и мы их копируем, мы можем их восстановить. Позволяет это делать система бэкапирования, это как бы стандарт фактор. Главное, чтобы мы хранили wal файлы где-нибудь. Дампы, естественно, это не умеют, потому что они немножечко о другом.
- Регулировка нагрузки на сеть – это довольно важная вещь, потому что как я говорил снимать дамп с мастер-сервера желательно, тогда вы себе гарантируете то, что вы действительно актуальные бэкапы получаете. Ну иногда бывает сервера настолько нагружены, что вклинится туда довольно сложно. У нас некоторые клиенты втыкают отдельный сетевой интерфейс. Иногда там минимальные время нагрузки делается. Еще хорошо, когда мы можем указать нагрузку на сеть при создании бекапа. Это позволяет делать pg_basebackup, barman и BART, wal-e, wal-g.
- Сжатие на лету. Это вопрос к тому сколько мы будем передавать по сети. Если мы сможем сжать файлик до отправки в хранилище, то это хорошо налету. И это умеют почти все, вот. Главное там указать уровень сжатия.

Сервисность, что тут у нас интересного по системам бэкапирования может быть.
- Мощный достаточно CLI — это довольно хорошая штука, потому что он нам позволяет прикрутится с точки зрения мониторинга к бэкапу и посмотреть там, сколько бэкапов у нас есть, к какой точке по времени мы можем восстановиться, можем вообще просто статус посмотреть утилиты. И в принципе все, кроме встроенных они имеют довольно хорошие CLI, полезный и его желательно изучать, когда выбираешь себе систему бэкапирования, чтобы знать какие возможности дает. Некоторые даже для мониторинга специальные команды имеют, чтобы вываливать в удобном читаемом формате данные, а там дальше просто распарсить их.
- Как выделенный сервис на отдельном сервере могут работать barman, pgbackrest и BART, все остальные должны стоять рядом с базой данных. И это плохо, потому что когда мы хотим собирать до 20-30 баз данных, а есть такие люди, у которых там развалено, то куда проще поменять конфик у сервиса на одном сервере, подцепить туда как бы точку базы данных откуда тянуть нам backup-ы и тянуть их и сваливать на один сервер выделенный для этого. Но, к сожалению, это позволяет делать вот немногие.
- Структурированное хранение бэкапов – это вот как раз важная вещь с точки зрения того, что мы могли быстренько посмотреть, за какие числа у нас есть backup-ы, какого они размера, валидные ли эти backup-ы. Есть ли у нас необходимое количество архивных логов для этого дела, для того чтобы восстановиться куда-то по времени дальше. Все утилиты сторонние это умеют это с разной степенью. Минимальный функционал в данном случае все предоставляют.
- Политики хранения – это то насколько долго нам необходимо хранить бэкап и насколько сама утилита бэкапирования может ротировать эти backup-ы, вовремя удалять ненужные, оставлять какие-то на долгое время. Вот все вот эти перечисленные, они имеют политику хранения, которую можно прописать в конфиге. И вы, прописав в конфиге, просто, когда в очередной раз утилитка запускается, она при снятии бэкапа или запихивания wal файла, она просто проверит, если что удалять в политике хранения и удалит. Случай с wal-e, wal-g, там нужно в крон запихать задачу, что мы удаляем backup старее или чем больше чем столько-то бекапов. Мы 7 backup храним у клиентов обычно.

Валидирование у backup. Хотелось бы, чтобы мы были уверены при снятии backup, потому что хороший backup это тот, который потом ещё поднят, поднят сервер и прогнали на нём теми тестами. Практика показывает, что среди наших клиентов никто не делает. Пока они мы не пришли, никто не делал. Потом начинают делать. Потому что на stage накатывают из дампа. Есть некоторые вещи, которые позволяют нам быть достаточно хорошо уверены, что у нас backup валидный. С помощью CLI можем посмотреть, что же там у нас сохранилось и валидный ли эти backup и как это проверяется.
Первое что нам интересно то, что мы действительно скопировали все файлы, которые нужны. Эти системы бэкапирования после того как зальют все файлы, должны показать что backup валидный. Пока бекап заливается, он должен быть в прогрессе. Если отвалились, он должен быть фейл. В принципе, они все так умеют. Хочется ещё больше. Этот механизм checksum в PostgreSQL. Он работает только в том случае, если вы включили у себя checksum в PostgreSQL. Если у вас база данных без checksum, никак не провериться.
Утилиты pgbackrest и pg_probackup в процессе снятия backup вообще ругаются, что у нас нет checksum. Эти утилиты проверяют валидность файлов и блоков файлов по checksum.
Второй пункт, который валидность завершение backup, там в процессе копирования снимается checksum файла, он, когда скопирован checksum проверяется на хранилище. Это вот так мы валидируем.

Полезные ссылки:
- https://www.postgresql.org/docs/10/static/app-pgdump.html
- https://www.postgresql.org/docs/10/static/app-pgbasebackup.html
- https://www.2ndquadrant.com/en/resources/barman/
- https://github.com/wal-e/wal-e
- https://github.com/wal-g/wal-g
- https://pgbackrest.org/
- https://www.enterprisedb.com/products/edb-postgres-platform/edb-backup-and-recovery-tool
- https://postgrespro.ru/products/extensions/pg_probackup
Это ссылочки по всем этим утилитам. Эта тема короткая, но обзора полного не было. Цель доклада было дать представление о том, кто что из них умеет.

Вопрос: Вы сказали, что backup лучше снимать с мастера по причине, что реплика может там отстать, вывалиться из мониторинга, быть не актуальна. И соответственно уже есть даже такие методы, которые позволяют нам ограничить пропускную способность, чтобы не сильно нагружать мастера вовремя backup. А не лучше ли, как альтернативу, рассмотреть всё-таки бэкапирования реплики и одновременно, например, мониторить эту реплику, мониторить лак, отставание не реплики там, что ну как бы убеждаться, что она актуальна. Вот здесь есть какие-то может быть подводные камни?
Ответ: В таких случаях можно с реплики снимать, но в данном это если вы гарантированно уверены, что она не отстаёт и так далее. Большинстве случаев как настраивать бэкопирование. Настроили и забыли. Если что-то пошло не так, например, backup снимется с реплики, если она отвалилась, а качество настраиваемых мониторингов как жизнь показала, что она в большинстве случаев ужасна. И конкретно с базами данных на них довольно частенько плюют, чтобы мониторить в необходимом количестве и реагировать на алерты. Пришёл алерт лаг большой, один раз, второй, пришёл, реплика отвалилась, алерты перестали идти, потому что человек выключил алерты/настроил автоматическое прочтение писем от алертов. Человек забыл, а потом через месяц оказывается реплики отстает, особенно если она не участвует в нагрузке. Если она в нагрузке участвует читающей, да вы это сразу обнаружите. Если не участвуют, то лучше настраивать бекапирование на мастере. Просто не раз сталкивался с такими ситуациями, то что люди просто то как бы забили.
Вопрос: Сравнивали ли вы производительность, скорость, как они системы нагружают? Некоторые могут в несколько потоков забьют сеть.
Ответ: У нас есть только один проект на поддержки. У них на каждом сервере базы данных есть 4 интерфейса. В их случае действительно там забивается интерфейс. Есть один интерфейс для репликации. Есть один интерфейс для снятия backup. Два интерфейса для обслуживания нагрузки от приложений. Во всех остальных случаях, сетевых интерфейсов хватает как правило.
Вопрос: Скажите вашу любимую утилиту или вы выбираете под задачи?
Ответ: Это зависит от задач. Потому что в облаках особо вариантов нет. В амазоне wal-e, wal-g, pgbackrest. А так стандартно borman, pg_dump, в принципе basebackup. Всё зависит от того, что хочет у нас конкретно клиент, что он готов и какое оборудование предоставляет. Соответственно выбираем систему.
Вопрос: Скажите пожалуйста, могут ли возникнуть какие-то сложности при использовании расширения PostgreSQL, добавление типа данных, например, postgis или чего-нибудь такого-либо?
Ответ: Потенциально вряд ли возможно, потому что в случае бинарных backup мы копируем файлы, нам без разницы наполнение этих файлов. Если checksum мы включим, то PostgreSQL сам проверяет checksum, если кривой расширение, но она убьет вам базу и работающую. Это не postgis, а допустим вы сами как-то там с логической репликации неудачно игрались. Pg_dump он вообще шикарен в этом плане, потому что он вываливает, по сути дела, SQL команды. То есть его всегда можно развернуть в SQL команды. Надампил и вырезал ненужные вещи. Он, кстати, используется в этом плане как проверка возможности мажорного апгрейда. Когда мы снимаем dump, на катаем на новую версию базу данных.
Вопрос: Вы сказали, что причина реплики может отставать. Это единственная причина, по которой вы против бекапа с реплики или есть какие-то другие весомые?
Ответ: Это основная самая важная причина. От бекапа и dump нам важно, чтобы всегда были актуальные данные на момент снятие его. Если они не актуальны, ну то есть – это обычно как происходит, вот забили, потом что-то случилось, начали искать, а этого нету и все. Вот эта рекомендация снимать с мастера, это чисто человеческий фактор. Вот, просто она из-за человеческого фактора, потому что люди имеют тенденцию забивать.
Вопрос: Я правильно понимаю, что в инструментах бинарных бэкапов, весь транзакционный мусор, весь bloat в бэкап идет?
Ответ: Да.
Вопрос: Все это многообразие — это хорошо, но в организациях бывает какая-то централизованная система резервного копирования. Например, Symantec, Veritas Backup Exec и другие. Умеют ли они работать с PostgreSQL?
Ответ: Ну, в принципе их можно научить работать, потому что можно просто скопировать файлы. PostgreSQL можно дать команду для бэкапирования, отправить им команду pg_start_backup. В общем, через скрипты. В принципе можно обучить систему.
Вопрос: Не слышно, чтобы какие-то системы Symantec, Veritas Backup Exec и другие пытались начать нативно взаимодействовать.
Ответ: Мы не сталкивались.
Вопрос: Расскажите, пожалуйста, по подробнее как вы валидируете бэкап. это только checksum или есть еще какие-то техники, типа развернуть бекап, какие-то тесты?
Ответ: Нормальная валидация бэкапа — поднять этот бэкап в отдельную базу данных и запустить на нем приложение. Полезная валидация это когда у вас есть stage сервер, где вы проверяете приложение. Вы на этот stage сервер накатывайте новый бэкап. Вот самый адекватный и интересный способ валидации. Можно просто поднять базу на отдельный серверк и прогнать тесты на целостность данных. Но тесты целостность данных, они больше будут завязаны на бизнес-логику, потому что тут их нужно будет самим написать. Вот это самый правильные варианты. Но на это тоже многие забивают.
Вопрос: Если представить ситуацию, что наш бэкап восстанавливается из WAL логов, лежавших на S3. Если мы их будем тащить с помощью wal-e, wal-g или с помощью каких-нибудь awscli к примеру. Что из этого всего будет быстрее?
Ответ (Отвечает Андрей Бородин): Я разработчик wal-g. Поэтому скажу что быстрее wal-g. У меня доклад целый на 40 минут за счёт чего wal-g быстрее. Я не могу ответить одним словом. Можно сказать, мы долго работали. Да честный параллелизм, prefetch, мы закачиваем wal до того, как он тебе понадобился. Поэтому, когда вон там график был — это график, на самом деле упертый в накат wal. Но даже накат wal мы стараемся оптимизировать, подготавливая в page cache страницы базы данных, к тому, что к ним скоро подъедет wal, то есть там это не просто технология, которая заархивировала и поменьше данных унесла в сеть. Там мы наворотили космоса всякого, сложно коротко сказать.
Андрей Бородин: Я хотел про валидацию сказать. Вот мне кажется, что правильный способ провалидировать PostgreSQL — это дамп -> /dev/null, который проверяет, если у тебя включенные контрольные суммы. Он тебе проверит все контрольные суммы и проверит, что ты можешь прочитать все свои данные в базе данных. Но это еще недостаточно для полного smoke теста. Желательно делать amcheck, который проверит инварианты корректности графа индексов. Если эти инварианты выполняются при этом мы знаем, что все контрольные суммы на страницах графа корректны, мы можем говорить о том, что в базе данных логические ошибки отсутствуют.
Вопрос: У меня есть большая база данных 10 ТБ допустим. Я собираюсь делать массированные изменения в базе. Но в любой момент мне захочется вернутся обратно в точку до изменений. Причем сделать это быстро. Просто сделаю в бинарный дамп и wal соответствующие — это потом будет достаточно долго накатываться. Как быстро вернуся к этой точке?
Ответ: Это просто отдельный сервер поднимать для базы данных. Либо делаем реплику и останавливаем репликацию. Высе остальное упрется в копирование файлов. А тут у вас уже готовый инстас базы данных, куда вы просто перекинете нагрузку в случае проблемы.
Вопрос: Если у нас в принципе база сама по себе целостная, то если мы снимаем дамп через pg_dump, то очень небольшая вероятность что он будет битый. Верно?
Ответ: По-хорошему его нужно установить и проверить. Вообще, вероятность небольшая достаточно.
Вопрос: Если дамп битый, то скорее всего проблема в базе, а не в чем-нибудь еще?
Ответ: pg_dump не снимет дамп, если проблема в базе.
Вопрос: У меня просто снимал pg_dump, и он был битый, я не знаю, как это работало, но я не мог его накатить его после этого, он не писал ошибку.
Ответ: Вы могли не накатить его просто по причине того, что у вас не хватало расширения какого-нибудь, криво расширения были поставлены.
Вопрос: База чистая была, без всего вообще.
Ответ: Это надо посмотреть почему у вас так происходило, скорее всего просто сам файлик дамп каким-то образом побился.
Дополнение: Дополнение к предыдущему вопросу. Почему дамп логически может побиться. К вашему вопросу дополнение могу сказать. Бывают такие случаи логический дамп останавливается. Например, у нас было пару случаев, когда был файл битый. Были поврежденные данные. Pg_dump внезапно останавливался, выдавал какую-то ошибку, но exit_code был нормальный. Все вроде нормально, а на самом деле дамп был битый, неполный. И не восстанавливался, и так что следите за этим.
P.S. №1 Сделал обновленную сводную таблицу с инструментами, кроме pg_dump, pg_basebackup.
| barman | wal-e | wal-g | pg_probackup | pgbackrest | BART | |
|---|---|---|---|---|---|---|
| ssh (rsync, scp) | + | + | ||||
| Сохранение на файловой системе | + | + | + | + | + | + |
| S3 | + | + | + | |||
| Azure | + | + | ||||
| Google Cloud | + | + | ||||
| Управление табличным пространством | + | + | + | + | + | |
| Дифференциальные бэкапы | + | + | ||||
| Инкрементальные бэкапы | + | + | ||||
| barman | wal-e | wal-g | pg_probackup | pgbackrest | BART | |
| Инкрементальные по блоку | + | + | ||||
| Инкрементальное восстановление (delta restore) | + | + | ||||
| Восстановить выбранную БД | + | |||||
| Мульти-версионность | + | + | + | + | + | + |
| Многопоточный дамп | + | + | + | + | + | |
| Восстановление на момент времени (Point-in-Time Recovery) | + | + | + | + | + | + |
| Регулировка нагрузки на сеть | + | + | + | |||
| Сжатие на лету | + | + | + | + | + | |
| CLI | + | + | + | + | + | + |
| Выделенный сервер | + | + | + | |||
| barman | wal-e | wal-g | pg_probackup | pgbackrest | BART | |
| Структурированное хранение бэкапов | + | + | + | + | + | + |
| Политики хранения | + | cron | cron | + | + | + |
| CLI для мониторинга | + | + | + | + | + | + |
| Валидность завершения бэкапа | + | + | + | + | + | + |
| Checksum postgresql | + | + |
P.S. №2 Ошибки, исправления по статье, добавления в сводную таблицу можно сделать через Pull request
P.S. №3 Wal-g приветствует волонтеров, которые бы помогли с документацией.
P.S. №4 Для установка wal-g используя rpm вы можете воспользоваться моим репозиторием: Github, Fedora COPR.
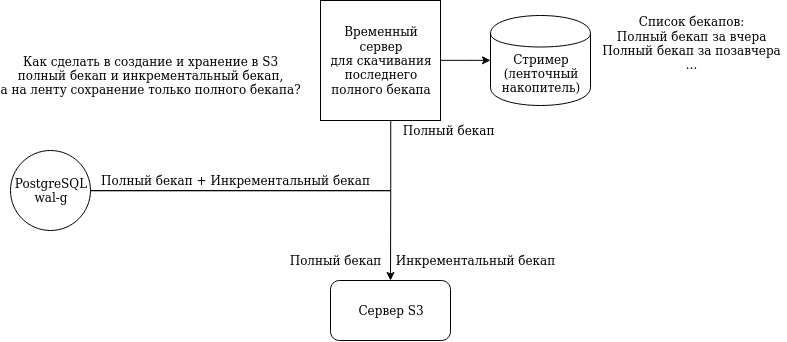
P.S. №5 Как сделать в создание и хранение в S3 полный бекап и инкрементальный бекап, а на ленту сохранение только полного бекапа? Если есть идеи, подскажите в коментариях или в личку.
Опрос: Каким инструментов для бекапов вы пользуетесь?
P.S. №6 Телеграм канал PostgreSQL: https://t.me/pgsql

