Привет, Хабр! Представляю вашему вниманию перевод статьи "Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)" автора Jay Alammar.
Sequence-to-sequence модели (seq2seq) – это модели глубокого обучения, достигшие больших успехов в таких задачах, как машинный перевод, суммаризация текста, аннотация изображений и др. Так, например, в конце 2016 года подобная модель была встроена в Google Translate. Основы же seq2seq моделей были заложены еще в 2014 году с выходом двух статей — Sutskever et al., 2014, Cho et al., 2014.
Чтобы в достаточной мере понять и затем использовать эти модели, необходимо сначала прояснить некоторые понятия. Предложенные в данной статье визуализации будут хорошим дополнением к статьям, упомянутым выше.
Sequence-to-sequence модель – это модель, принимающая на вход последовательность элементов (слов, букв, признаков изображения и т.д.) и возвращающая другую последовательность элементов. Обученная модель работает следующим образом:
В нейронном машинном переводе, последовательность элементов – это набор слов, обрабатываемых поочередно. Выводом также является набор слов:
Заглянем под капот
Под капотом у модели находятся энкодер и декодер.
Энкодер обрабатывает каждый элемент входной последовательности, переводит полученную информацию в вектор, называемый контекстом (context). После обработки всей входной последовательности энкодер пересылает контекст декодеру, который затем начинает генерировать выходную последовательность элемент за элементом.
То же самое происходит и в случае машинного перевода.
Применительно к машинному переводу контекст представляет собой вектор (массив чисел), а энкодер и декодер, в свою очередь, чаще всего являются рекуррентными нейронными сетями (см. введение в RNN — A friendly introduction to Recurrent Neural Networks).

Контекст – это вектор чисел с плавающей точкой. Далее в статье векторы будут визуализированы в цвете таким образом, что более светлый цвет соответствует ячейкам с большими значениями.
При обучении модели можно задать размер контекстного вектора – число скрытых нейронов (hidden units) в энкодере RNN. Данные визуализации показывают 4-мерный вектор, но в реальных приложениях контекстый вектор будет иметь размерность порядка 256, 512 или 1024.
По умолчанию в каждый временной отрезок RNN принимает на вход два элемента: непосредственно входной элемент (в случае энкодера, одно слово из исходного предложения) и скрытое состояние (hidden state). Слово, однако, должно быть представлено вектором. Для преобразования слова в вектор прибегают к ряду алгоритмов, называемых «эмбеддинги слов» (word embeddings). Эмбеддинги отображают слова в векторные пространства, содержащие смысловую и семантическую информацию о них (например, «король» – «мужчина» + «женщина» = «королева»).

Прежде чем обрабатывать слова, необходимо преобразовать их в векторы. Эта трансформация осуществляется с помощью алгоритма эмбеддингов слов. Можно использовать как предобученные эмбеддинги, так и обучить эмбеддинги на своем наборе данных. 200-300 — типичная размерность вектора эмбеддинга; в данной статье для простоты используется размерность 4.
Теперь, когда мы познакомились с нашими основными векторами/тензорами, давайте вспомним механизм работы RNN и создадим визуализации для его описания:
На следующем шаге RNN берет второй входной вектор и скрытое состояние #1 для формирования выхода на данном временном отрезке. Далее в статье подобная анимация используется для описания векторов внутри модели нейронного машинного перевода.
В следующей визуализации каждый кадр описывает обработку входов энкодером и генерацию выходов декодером за один временной отрезок. Так как и энкодер, и декодер представляют собой RNN, в каждый временной отрезок нейронная сеть занята обработкой и обновлением своих скрытых состояний на основе текущего и всех предыдущих входов. При этом последнее из скрытых состояний энкодера и является тем самым контекстом, который передается в декодер.
Декодер также содержит скрытые состояния, которые он передает из одного временного отрезка в другой. (Этого нет в визуализации, изображающей лишь основные части модели.)
Обратимся теперь к другому виду визуализации sequence-to-sequence моделей. Эта анимация поможет понять статическую графику, которая описывает эти модели – т.н. развернутое (unrolled) представление, где вместо того, чтобы показывать один декодер, мы показываем его копию для каждого временного отрезка. Так мы можем посмотреть на входные и выходные элементы на каждом временном отрезке.
Обратите внимание!
Контекстный вектор является бутылочным горлышком для такого типа моделей, благодаря чему, им сложно иметь дело с длинными предложениями. Решение было предложено в статьях Bahdanau et al., 2014 и Luong et al., 2015, где была представлена техника, получившая название «механизм внимания» (attention). Данный механизм значительно улучшает качество систем машинного перевода, позволяя моделям концентрироваться на релевантных частях входных последовательностей.
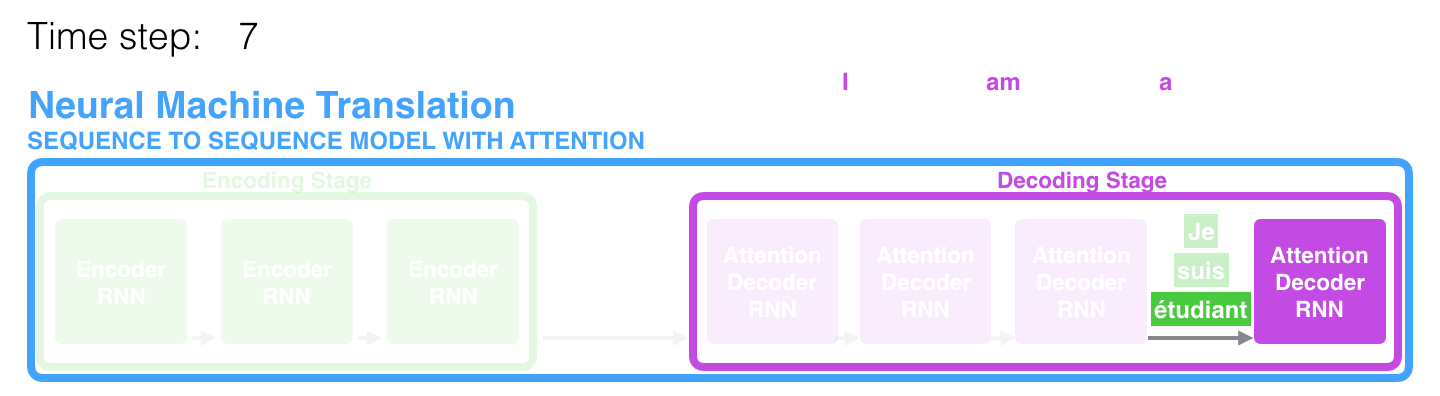
На 7-ом временном отрезке механизм внимания позволяет декодеру сфокусироваться на слове «étudiant» («student» по-французски), прежде чем сгенерировать перевод на английский. Эта способность усиливать сигнал от релевантной части входной последовательности позволяет моделям, основанным на механизме внимания, получать лучший результат по сравнению с остальными моделями.
При рассмотрении модели с механизмом внимания на высоком уровне абстракции можно выделить два основных отличия от классической sequence-to-sequence модели.
Во-первых, энкодер передает значительно больше данных декодеру: вместо передачи лишь последнего скрытого состояния после этапа кодирования, энкодер отправляет ему все свои скрытые состояния:
Во-вторых, декодер проходит через дополнительный этап, прежде чем сгенерировать выход. Для того, чтобы сфокусироваться на тех частях входной последовательности, которые релевантны для соответствующего временного отрезка, декодер делает следующее:
- Смотрит на набор скрытых состояний, полученных от энкодера – каждое из скрытых состояний соотносится наилучшим образом с одним из слов в входной последовательности;
- Назначает каждому скрытому состоянию некую оценку (опустим пока, как происходит процедура оценивания);
- Умножает каждое скрытое состояние на преобразованную softmax функцией оценку, выделяя, таким образом, скрытые состояния с большой оценкой и отводя на второй план скрытые состояния с маленькой.
Это «упражнение с оценками» производится в декодере на каждом временном отрезке.
Итак, подытоживая все вышеописанное, рассмотрим процесс работы модели с механизмом внимания:
- В декодере RNN получает эмбеддинг <END> токена и первоначальное скрытое состояние.
- RNN обрабатывает входной элемент, генерирует выход и новый вектор скрытого состояния (h4). Выход отбрасывается.
- Механизм внимания использует скрытые состояния энкодера и вектор h4 для вычисления контекстного вектора (C4) на данном временном отрезке.
- Вектора h4 и C4 конкатенируются в один вектор.
- Этот вектор пропускается через нейронную сеть прямого распространения (feedforward neural network, FFN), обучаемую совместно с моделью.
- Вывод FFN сети указывает на выходное слово на данном временном отрезке.
- Алгоритм повторяется для следующего временного отрезка.
Другой способ посмотреть на то, на какой части исходного предложения фокусируется модель на каждом этапе работы декодера:
Обратите внимание, что модель не просто бездумно связывает первое слово на входе с первым словом на выходе. Она на самом деле поняла в процессе обучения, как сопоставлять слова в этой рассматриваемой языковой паре (в нашем случае — французский и английский). Пример того, насколько точно этот механизм может работать, можно посмотреть в статьях о механизме внимания, указанных выше.

Если вы чувствуете, что готовы научиться применять эту модель, обратитесь к руководству Neural Machine Translation (seq2seq) на TensorFlow.
Авторы
- Автор оригинала — Jay Alammar
- Перевод — Смирнова Екатерина
- Редактирование и вёрстка — Шкарин Сергей

