
Вы можете использовать это руководство для различных целей:
- Чтобы понять, что такое Spring Framework
- Как работают ее основные фичи: такие как внедрение зависимостей или Web MVC
- Это также исчерпывающий FAQ (Перечень часто задаваемых вопросов)
Примечание: Статья ~ 9000 слов, вероятно, не стоит читать ее на мобильном устройстве. Добавьте ее в закладки и вернитесь позже. И даже на компьютере ешь читай этого слона по одному кусочку за раз :-)
Содержание
- Введение
- Основы внедрения зависимостей
- Контейнер Spring IOC / Dependency Injection
- Spring AOP (Аспектно-ориентированное программирование) и прокси
- Управление ресурсами Spring
- Spring Web MVC
- Дополнительные модули Spring Framework
- Spring Framework: часто задаваемые вопросы
- Заключение
Примечание переводчика:
Текст статьи весьма большой и в переводе могут остаться неточности несмотря на многократную вычитку текста. Буду благодарен всем за конструктивные замечания.
Введение
Сложность экосистемы Spring
Многие компании используют Spring, однако когда вы захотите узнать об этом фреймворке и перейдете на сайт spring.io, то увидите, что вселенная Spring на самом деле состоит из 21 различных активных проектов. Ой!
Кроме того, если вы начали программировать с помощью Spring в последние пару лет, очень велика вероятность того, что вы перешли непосредственно к Spring Boot или Spring Data.
Однако это руководство касается только одного, самого важного из этих проектов: Spring Framework. Почему?
Потому что важно понимать, что Spring Framework является основой для всех других проектов. Spring Boot, Spring Data, Spring Batch — все это построено поверх Spring.
Это имеет два последствия:
- Без надлежащего знания Spring Framework вы рано или поздно потеряетесь. Вы не будете в полной мере понимать, например. Spring Boot, несмотря на то, что, как вы думаете знание ядра Spring Framework неважно.
- Потраченные ~ 15 минут на чтение этого руководства, которое охватывает самые важные 80% Spring Framework, многократно окупятся в вашей профессиональной карьере.
Что такое Spring Framework?
Краткий ответ:
По сути Spring Framework представляет собой просто контейнер внедрения зависимостей, с несколькими удобными слоями (например: доступ к базе данных, прокси, аспектно-ориентированное программирование, RPC, веб-инфраструктура MVC). Это все позволяет вам быстрее и удобнее создавать Java-приложения.
Только это не очень помогает, не так ли?
К счастью, есть и длинный ответ:
Остальная часть этого руководства.
Основы внедрения зависимостей
Если вы уже знаете, что такое внедрение зависимостей, не стесняйтесь переходить прямо к следующему разделу Контейнер Spring IOC / Dependency Injection. В противном случае читайте дальше.
Что такое зависимость?
Представьте, что вы пишете Java класс, который позволяет вам получить доступ к таблице пользователей в вашей базе данных. Вы бы назвали эти классы DAO (объект доступа к данным) или репозитории. Итак, вы собираетесь написать класс UserDAO.
public class UserDao { public User findById(Integer id) { // execute a sql query to find the user } }
Ваш класс UserDAO имеет только один метод, который позволяет вам находить пользователей в вашей таблице базы данных по их идентификаторам.
Чтобы выполнить соответствующий SQL запрос, вашему классу UserDAO требуется соединение с базой данных. А в мире Java вы, обычно, получаете соединение с базой данных из другого класса, называемого DataSource. Итак, ваш код теперь будет выглядеть примерно так:
import javax.sql.DataSource; public class UserDao { public User findById(Integer id) throws SQLException { try (Connection connection = dataSource.getConnection()) { // (1) PreparedStatement selectStatement = connection.prepareStatement("select * from users where id = ?"); // use the connection etc. } } }
- Вопрос в том, откуда ваш UserDao получает свою информацию об источнике данных? Очевидно, что DAO зависит от действительного источника данных для запуска этих SQL-запросов.
Внедрение зависимостей с помощью new()
Наивным решением было бы просто создать новый источник данных с помощью конструктора, каждый раз, когда он вам нужен. Итак, для подключения к базе данных MySQL ваш UserDAO может выглядеть так:
import com.mysql.cj.jdbc.MysqlDataSource; public class UserDao { public User findById(Integer id) { MysqlDataSource dataSource = new MysqlDataSource(); // (1) dataSource.setURL("jdbc:mysql://localhost:3306/myDatabase"); dataSource.setUser("root"); dataSource.setPassword("s3cr3t"); try (Connection connection = dataSource.getConnection()) { // (2) PreparedStatement selectStatement = connection.prepareStatement("select * from users where id = ?"); // execute the statement..convert the raw jdbc resultset to a user return user; } } }
- Мы хотим подключиться к базе данных MySQL, для чего мы используем MysqlDataSource и задали непосредственно в коде url/username/password для облегчения чтения кода.
- Мы используем наш недавно созданный источник данных для запроса.
Это работает, но давайте посмотрим, что произойдет, когда мы расширим наш класс UserDao другим методом, findByFirstName.
К сожалению, этому методу также нужен источник данных для работы. Мы можем добавить этот новый метод к нашему UserDAO и применить некоторые рефакторинги, введя метод newDataSource.
import com.mysql.cj.jdbc.MysqlDataSource; public class UserDao { public User findById(Integer id) { try (Connection connection = newDataSource().getConnection()) { // (1) PreparedStatement selectStatement = connection.prepareStatement("select * from users where id = ?"); // TODO execute the select , handle exceptions, return the user } } public User findByFirstName(String firstName) { try (Connection connection = newDataSource().getConnection()) { // (2) PreparedStatement selectStatement = connection.prepareStatement("select * from users where first_name = ?"); // TODO execute the select , handle exceptions, return the user } } public DataSource newDataSource() { MysqlDataSource dataSource = new MysqlDataSource(); // (3) dataSource.setUser("root"); dataSource.setPassword("s3cr3t"); dataSource.setURL("jdbc:mysql://localhost:3306/myDatabase"); return dataSource; } }
- findById был переписан для использования нового метода newDataSource().
- findByFirstName был добавлен и также использует новый метод newDataSource().
- Это наш недавно извлеченный метод, способный создавать новые источники данных.
Этот подход работает, но имеет два недостатка:
Что произойдет, если мы хотим создать новый класс ProductDAO, который также выполняет операторы SQL? Ваш ProductDAO также будет иметь зависимость DataSource, которая теперь доступна только в вашем классе UserDAO. Затем у вас будет другой подобный метод или извлечен вспомогательный класс, содержащий ваш DataSource.
Мы создаем совершенно новый источник данных для каждого запроса SQL. Учтите, что DataSource открывает реальное сокет-соединение от вашей Java-программы к вашей базе данных. Это занимает время и довольно дорого. Было бы намного лучше, если бы мы открыли только один источник данных и использовали его повторно, вместо того, чтобы открывать и закрывать их тонны. Одним из способов сделать это может быть сохранение источника данных в закрытом поле в нашем UserDao, чтобы его можно было повторно использовать между методами, но это не помогает при дублировании между несколькими DAO.
Зависимости в глобальном классе приложения
Чтобы решить эти проблемы, вы можете подумать о написании глобального класса Application, который выглядит примерно так:
import com.mysql.cj.jdbc.MysqlDataSource; public enum Application { INSTANCE; private DataSource dataSource; public DataSource dataSource() { if (dataSource == null) { MysqlDataSource dataSource = new MysqlDataSource(); dataSource.setUser("root"); dataSource.setPassword("s3cr3t"); dataSource.setURL("jdbc:mysql://localhost:3306/myDatabase"); this.dataSource = dataSource; } return dataSource; } }
Ваш класс UserDAO теперь может выглядеть так:
import com.yourpackage.Application; public class UserDao { public User findById(Integer id) { try (Connection connection = Application.INSTANCE.dataSource().getConnection()) { // (1) PreparedStatement selectStatement = connection.prepareStatement("select * from users where id = ?"); // TODO execute the select etc. } } public User findByFirstName(String firstName) { try (Connection connection = Application.INSTANCE.dataSource().getConnection()) { // (2) PreparedStatement selectStatement = connection.prepareStatement("select * from users where first_name = ?"); // TODO execute the select etc. } } }
Это улучшение по двум направлениям:
- Вашему UserDAO больше не нужно создавать свою собственную зависимость DataSource, вместо этого он может попросить класс Application предоставить ему полнофункциональную. То же самое для всех других ваших DAO.
- Ваш класс приложения является одноэлементным (это означает, что будет создан только один INSTANCE), и этот одноэлементный компонент приложения содержит ссылку на одноэлементный объект DataSource.
Однако у этого решения есть еще несколько недостатков:
- UserDAO активно должен знать, где получить свои зависимости, он должен вызвать класс приложения → Application.INSTANCE.dataSource().
- Если ваша программа становится больше, и вы получаете все больше и больше зависимостей, у вас будет один монстр класс Application.java, который обрабатывает все ваши зависимости. В этот момент вы захотите разделить вещи на несколько классов / фабрик и т.д.
Инверсия управления (IoC, Inversion of Control)
Давайте сделаем еще один шаг вперед.
Было бы неплохо, если бы вам в классе UserDAO вообще не приходилось беспокоиться о поиске зависимостей? Вместо того, чтобы активно вызывать Application.INSTANCE.dataSource(), ваш UserDAO мог бы (как-то) кричать, что он ему нужен, но больше не контролирует, когда / как / откуда он его получает?
Это то, что называется инверсией управления (Inversion of Control).
Давайте посмотрим, как может выглядеть наш класс UserDAO, с новым конструктором.
import javax.sql.DataSource; public class UserDao { private DataSource dataSource; private UserDao(DataSource dataSource) { // (1) this.dataSource = dataSource; } public User findById(Integer id) { try (Connection connection = dataSource.getConnection()) { // (2) PreparedStatement selectStatement = connection.prepareStatement("select * from users where id = ?"); // TODO execute the select etc. } } public User findByFirstName(String firstName) { try (Connection connection = dataSource.getConnection()) { // (2) PreparedStatement selectStatement = connection.prepareStatement("select * from users where first_name = ?"); // TODO execute the select etc. } } }
- Всякий раз, когда вызывающий создает новый UserDao через свой конструктор, вызывающий также должен передать действительный источник данных.
- Методы findByX будут просто использовать этот источник данных.
С точки зрения UserDao это выглядит намного лучше. Он больше не знает ни о классе приложения, ни о том, как создавать сами источники данных. Он только объявляет миру, что «если вы хотите создать (то есть использовать) меня, вам нужно дать мне источник данных».
Но представьте, что вы хотите запустить свое приложение. Если раньше вы могли вызывать «new UserService()», то теперь вам нужно обязательно вызвать новый UserDao(dataSource).
public class MyApplication { public static void main(String[] args) { UserDao userDao = new UserDao(Application.INSTANCE.dataSource()); User user1 = userDao.findById(1); User user2 = userDao.findById(2); // etc ... } }
Контейнеры для внедрения зависимостей
Следовательно, проблема в том, что вы, как программист, все еще создаете UserDAO с помощью их конструктора и, таким образом, устанавливаете зависимость DataSource вручную.
Разве не было бы хорошо, если бы кто-то знал, что ваш UserDAO имеет зависимость от конструктора DataSource, и знал, как ее создать? А затем волшебным образом сконструирует для вас оба объекта: работающий DataSource и работающий UserDao?
Этот кто-то является контейнером внедрения зависимостей и является именно тем, что представляет собой среда Spring.
Контейнер Spring IOC / Dependency Injection
Как уже упоминалось в самом начале, Spring Framework по своей сути является контейнером внедрения зависимостей, который управляет написанными вами классами и их зависимостями для вас (см. Предыдущий раздел). Давайте выясним, как это происходит.
Что такое ApplicationContext? Для чего тебе это?
Тот, кто контролирует все ваши классы и может управлять ими соответствующим образом (читай: создайте их с необходимыми зависимостями), называется ApplicationContext во вселенной Spring.
Чего мы хотим добиться, так это следующего кода (я описал UserDao и DataSource в предыдущем разделе, перейдите по ссылке, если вы пришли сюда и пропустили его):
import org.springframework.context.ApplicationContext; import org.springframework.context.annotation.AnnotationConfigApplicationContext; import javax.sql.DataSource; public class MyApplication { public static void main(String[] args) { ApplicationContext ctx = new AnnotationConfigApplicationContext(someConfigClass); // (1) UserDao userDao = ctx.getBean(UserDao.class); // (2) User user1 = userDao.findById(1); User user2 = userDao.findById(2); DataSource dataSource = ctx.getBean(DataSource.class); // (3) // etc ... } }
- Здесь мы создаем наш Spring ApplicationContext. Мы подробно расскажем о том, как это работает, в следующих параграфах.
- ApplicationContext может дать нам полностью сконфигурированный UserDao, то есть один с его набором зависимостей DataSource.
- ApplicationContext может также предоставить нам источник данных напрямую, который является тем же источником данных, который он устанавливает внутри UserDao.
Это довольно круто, не правда ли? Вам, как вызывающей стороне, больше не нужно беспокоиться о создании классов, вы можете просто попросить ApplicationContext предоставить вам рабочие классы!
Но как это работает?
Что такое ApplicationContextConfiguration? Как построить ApplicationContexts из конфигураций.
В приведенном выше коде мы помещаем переменную с именем someConfigClass в конструктор AnnotationConfigApplicationContext. Вот быстрое напоминание:
import org.springframework.context.annotation.AnnotationConfigApplicationContext; public class MyApplication { public static void main(String[] args) { ApplicationContext ctx = new AnnotationConfigApplicationContext(someConfigClass); // (1) // ... } }
То, что вы действительно хотите передать в конструктор ApplicationContext, это ссылка на класс конфигурации, который должен выглядеть следующим образом:
import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class MyApplicationContextConfiguration { // (1) @Bean public DataSource dataSource() { // (2) MysqlDataSource dataSource = new MysqlDataSource(); dataSource.setUser("root"); dataSource.setPassword("s3cr3t"); dataSource.setURL("jdbc:mysql://localhost:3306/myDatabase"); return dataSource; } @Bean public UserDao userDao() { // (3) return new UserDao(dataSource()); } }
- У вас есть выделенный класс конфигурации ApplicationContext, помеченный аннотацией
@Configuration, который немного похож на класс Application.java из раздела Зависимости в глобальном классе приложения. - У вас есть метод, который возвращает DataSource и аннотируется
@Beanдля Spring. - У вас есть другой метод, который возвращает UserDao и создает указанный UserDao, вызывая метод bean-компонента dataSource.
Этого класса конфигурации уже достаточно для запуска самого первого приложения Spring.
import org.springframework.context.ApplicationContext; import org.springframework.context.annotation.AnnotationConfigApplicationContext; public class MyApplication { public static void main(String[] args) { ApplicationContext ctx = new AnnotationConfigApplicationContext(MyApplicationContextConfiguration.class); UserDao userDao = ctx.getBean(UserDao.class); // User user1 = userDao.findById(1); // User user2 = userDao.findById(1); DataSource dataSource = ctx.getBean(DataSource.class); } }
Теперь давайте выясним, что именно Spring и AnnotationConfigApplicationContext делают с тем классом конфигурации, который вы написали.
Почему мы создали AnnotationConfigApplicationContext? Существуют ли другие классы ApplicationContext?
Существует много способов создания Spring ApplicationContext, например, с помощью файлов XML, аннотированных классов конфигурации Java или даже программно. Для внешнего мира это представлено через единый интерфейс ApplicationContext.
Посмотрите на класс MyApplicationContextConfiguration сверху. Это класс Java, который содержит аннотации Spring. Вот почему вам необходимо создать аннотацию AnnotationConfigApplicationContext.
Если вместо этого вы хотите создать свой ApplicationContext из файлов XML, вы должны создать ClassPathXmlApplicationContext.
Есть и много других, но в современном приложении Spring вы обычно начинаете с контекста приложения, основанного на аннотациях.
Что делает аннотация @Bean? Что такое Spring Bean?
Вам придется думать о методах внутри вашего класса конфигурации ApplicationContext как о фабричных методах. На данный момент есть один метод, который знает, как создавать экземпляры UserDao, и один метод, который создает экземпляры DataSource.
Эти экземпляры, которые создаются этими фабричными методами, называются bean-компонентами. Spring контейнер создал их и они находятся под его управлением.
Но это приводит к вопросу: сколько экземпляров определенного компонента должно быть создано Spring?
Что такое Spring bean scope?
Сколько экземпляров наших DAO следует создать в Spring? Чтобы ответить на этот вопрос, вам нужно узнать о bean scope (область применения бина).
- Должен ли Spring создать singleton: все ваши DAO используют один и тот же источник данных?
- Должен ли Spring создать prototype: все ваши DAO получают свой собственный источник данных?
- Или ваши компоненты должны иметь еще более сложные области действия, например: новый источник данных для HttpRequest? Или за HttpSession? Или за WebSocket?
Вы можете прочитать полный список доступных областей применения бинов здесь, но пока достаточно знать, что вы можете повлиять на область действия с помощью еще одной аннотации.
import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Scope; import org.springframework.context.annotation.Configuration; @Configuration public class MyApplicationContextConfiguration { @Bean @Scope("singleton") // @Scope("prototype") etc. public DataSource dataSource() { MysqlDataSource dataSource = new MysqlDataSource(); dataSource.setUser("root"); dataSource.setPassword("s3cr3t"); dataSource.setURL("jdbc:mysql://localhost:3306/myDatabase"); return dataSource; } }
Аннотация области (scope annotation) определяет, сколько экземпляров создаст Spring. И, как упоминалось выше, это довольно просто:
- Scope("singleton") → Ваш бин будет синглтоном, т.е. будет только один экземпляр.
- Scope("prototype") → Каждый раз, когда кому-то нужна ссылка на ваш компонент, Spring создает новый. (Здесь есть несколько предостережений, например, внедрения прототипов в синглтоны).
- Scope("session") → Для каждого сеанса HTTP пользователя будет создан один компонент.
- и т.п.
Суть: большинство приложений Spring почти полностью состоят из одноэлементных bean-компонентов, в которые время от времени добавляются другие области действия bean-компонента (прототип, запрос, сессия, websocket и т.д.).
Теперь, когда вы знаете о ApplicationContexts, Beans & Scopes, давайте еще раз рассмотрим зависимости или то, как наш UserDAO может получить DataSource.
Что такое Spring Java Config?
До сих пор вы явно настраивали свои bean-компоненты в конфигурации ApplicationContext с помощью аннотированных @Bean методов Java.
Это то, что вы бы назвали Spring Java Config, в отличие от указания всего в XML, который исторически был подходом для Spring. Просто краткий обзор того, как это выглядит:
import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class MyApplicationContextConfiguration { @Bean public DataSource dataSource() { MysqlDataSource dataSource = new MysqlDataSource(); dataSource.setUser("root"); dataSource.setPassword("s3cr3t"); dataSource.setURL("jdbc:mysql://localhost:3306/myDatabase"); return dataSource; } @Bean public UserDao userDao() { // (1) return new UserDao(dataSource()); } }
- Один вопрос: почему вы должны явно вызывать новый UserDao() с ручным вызовом dataSource()? Разве Spring не может понять все это сам?
Вот где появляется другая аннотация @ComponentScan.
Что делает @ComponentScan?
Первое изменение, которое вам нужно применить к своей конфигурации контекста, — это добавить к ней дополнительную аннотацию @ComponentScan.
import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.ComponentScan; import org.springframework.context.annotation.Configuration; @Configuration @ComponentScan // (1) public class MyApplicationContextConfiguration { @Bean public DataSource dataSource() { MysqlDataSource dataSource = new MysqlDataSource(); dataSource.setUser("root"); dataSource.setPassword("s3cr3t"); dataSource.setURL("jdbc:mysql://localhost:3306/myDatabase"); return dataSource; } // (2) // no more UserDao @Bean method! }
- Мы добавили аннотацию
@ComponentScan. - Обратите внимание, что определение UserDAO теперь отсутствует в конфигурации контекста!
То, что делает эта аннотация @ComponentScan, это сказать Spring: Посмотрите на все классы Java в том же пакете, что и конфигурация контекста, если они выглядят как Spring Bean!
Это означает, что, если ваш MyApplicationContextConfiguration находится в пакете com.marcobehler, Spring будет сканировать каждый пакет, включая подпакеты, который начинается с com.marcobehler для поиска потенциальных компонентов Spring.
Как Spring узнает, является ли что-то бином Spring? Легко: Ваши классы должны быть помечены аннотацией маркера, называемой @Component.
Что делают аннотации @Component и @Autowired?
Давайте добавим аннотацию @Component к вашему UserDAO.
import javax.sql.DataSource; import org.springframework.stereotype.Component; @Component public class UserDao { private DataSource dataSource; private UserDao(DataSource dataSource) { // (1) this.dataSource = dataSource; } }
- Это говорит Spring, аналогично тому методу
@Bean, который вы написали ранее: эй, если вы обнаружите, что меня аннотируют с помощью@Componentчерез ваш@ComponentScan, тогда я хочу быть бином Spring, управляемым вами, контейнером внедрения зависимостей!
(Когда вы посмотрите на исходный код аннотаций, таких как @Controller, @Service или @Repository, позже, вы обнаружите, что все они состоят из нескольких дополнительных аннотаций, всегда включая @Component!).
Отсутствует только один маленький кусочек информации. Как Spring узнает, что он должен взять DataSource, который вы указали как метод @Bean, а затем создать новые UserDAO с этим конкретным DataSource?
Легко, с другой аннотацией: @Autowired. Следовательно, ваш окончательный код будет выглядеть следующим образом.
import javax.sql.DataSource; import org.springframework.stereotype.Component; import org.springframework.beans.factory.annotation.Autowired; @Component public class UserDao { private DataSource dataSource; private UserDao(@Autowired DataSource dataSource) { this.dataSource = dataSource; } }
Теперь Spring имеет всю информацию, необходимую для создания bean-компонентов UserDAO:
- UserDAO аннотируется
@Component→ Spring создаст его - UserDAO имеет аргумент конструктора
@Autowired→ Spring автоматически внедрит источник данных, настроенный с помощью вашего метода@Bean - Если в ваших конфигурациях Spring не было настроено ни одного источника данных, вы получите исключение NoSuchBeanDefinition во время выполнения.
Внедрение зависимости через конструктор и Autowired
Я лгал вам чуть-чуть в предыдущем разделе. В более ранних версиях Spring (до 4.2) вам нужно было указывать @Autowired, чтобы внедрение зависимости работало.
В более новых версиях Spring действительно достаточно умен, чтобы внедрять эти зависимости без явной аннотации @Autowired в конструкторе. Так что это также будет работать.
@Component public class UserDao { private DataSource dataSource; private UserDao(DataSource dataSource) { this.dataSource = dataSource; } }
Почему я упомянул @Autowired тогда? Поскольку это не повредит, то есть делает вещи более явными и потому что вы можете использовать @Autowired во многих других местах, кроме конструкторов.
Давайте рассмотрим различные способы внедрения зависимостей — внедрение конструкторов — всего лишь один из них.
Что такое Field Injection? Что такое Setter Injection?
Проще говоря, Spring не должен использовать конструктор для внедрения зависимостей.
Он также может напрямую внедрять поля.
import javax.sql.DataSource; import org.springframework.stereotype.Component; import org.springframework.beans.factory.annotation.Autowired; @Component public class UserDao { @Autowired private DataSource dataSource; }
Кроме того, Spring также может внедрять сеттеры.
import javax.sql.DataSource; import org.springframework.stereotype.Component; import org.springframework.beans.factory.annotation.Autowired; @Component public class UserDao { private DataSource dataSource; @Autowired public void setDataSource(DataSource dataSource) { this.dataSource = dataSource; } }
Эти два стиля внедрения (поля, сеттеры) имеют тот же результат, что и внедрение конструктора: вы получите работающий Spring Bean. На самом деле есть еще один метод, называемый внедрением метода, который мы не будем здесь описывать.
Но очевидно, что они отличаются друг от друга, что означает, что было очень много споров о том, какой стиль внедрения является лучшим и какой вы должны использовать в своем проекте.
Внедрение зависимости через конструктор или через поле
Было много споров в сети что лучше внедрение зависимости через конструктор или через поле и множеством громких голосов, утверждавших, что внедрение с помощью метода установки (setter) вредна.
Чтобы не добавлять шума к этим аргументам сформулируем суть этой статьи:
- В последние годы я работал с обоими стилями, внедрением зависимости через конструктор и через поле в различных проектах. Основываясь исключительно на личном опыте, у меня в действительности нет предпочтения одного стиля над другим.
- Важна согласованность: не стоит использовать в 80% ваших бинов внедрение зависимости через конструктор, в 10% — инъекцию поля и для оставшихся 10% — внедрение метода.
- Подход Spring из официальной документации кажется разумным: используйте внедрением зависимости через конструктор для обязательных зависимостей и внедрение с помощью метода установки / через поле для необязательных зависимостей. Еще раз предупреждаю: будьте действительно последовательны с этим.
Резюме о контейнере Spring IoC
К настоящему моменту вы должны знать почти все, что вам нужно знать о контейнере зависимостей Spring.
Конечно, это еще не все, но если вы хорошо разбираетесь в ApplicationContexts, Beans, зависимостях и различных методах внедрения зависимостей, то вы уже на правильном пути.
Давайте посмотрим, что еще может предложить Spring, кроме инъекций чистой зависимости.
Spring AOP (Аспектно-ориентированное программирование) и прокси
Внедрение зависимостей поможет вести вас к более структурированным программам, но внедрение зависимости здесь и там не совсем то, в чем заключается суть экосистемы Spring. Давайте еще раз посмотрим на простую ApplicationContextConfiguration:
import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class MyApplicationContextConfiguration { @Bean public UserService userService() { // (1) return new UserService(); } }
- Предположим, что UserService — это класс, который позволяет вам находить пользователей из таблицы базы данных или сохранять пользователей в этой таблице базы данных.
Вот где проявляется функция скрытая особенность Spring:
В этом контексте Spring читает конфигурацию, содержащую метод @Bean, который вы написали, и поэтому Spring знает, как создавать и внедрять компоненты UserService.
Однако Spring может обманывать и создавать что-то еще, кроме вашего класса UserService. Как? Почему?
Spring может создавать прокси
Потому что под капотом любой метод Spring @Bean может вернуть вам то, что (в вашем случае) выглядит и ощущается как UserService, но на самом деле это не так.
Он может вернуть вам прокси.
Прокси-сервер в какой-то момент делегирует службу UserService, которую вы написали, но сначала он выполнит свою собственную функциональность.
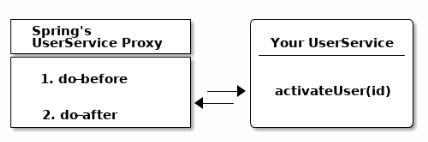
В частности, Spring по умолчанию создаст динамические прокси-серверы Cglib, которым не нужен интерфейс для работы прокси-серверов (например, внутренний механизм прокси-сервера JDK): вместо этого Cglib может прокси-классы посредством их подклассов на лету. (Если вы не уверены относительно отдельных шаблонов прокси, прочитайте больше о прокси в Википедии.)
Почему Spring желает создавать прокси?
Потому что это позволяет Spring дать вашим компонентам дополнительные функции без изменения кода. В сущности, это то, что является аспектно-ориентированным (или: AOP) программированием.
Давайте рассмотрим самый популярный пример AOP — аннотацию Spring @Transactional.
Spring аннотация @Transactional
Ваша реализация UserService выше может выглядеть примерно так:
import org.springframework.stereotype.Component; import org.springframework.transaction.annotation.Transactional; @Component public class UserService { @Transactional // (2) public User activateUser(Integer id) { // (1) // execute some sql // send an event // send an email } }
- Мы написали метод activateUser, который при вызове должен выполнить некоторый SQL-запрос, чтобы обновить состояние пользователя в базе данных, возможно, отправить сообщение электронной почты или событие обмена сообщениями.
@Transactionalдля этого метода сигнализирует Spring, что для работы этого метода необходимо открытое соединение с базой данных / транзакция и что указанная транзакция также должна быть зафиксирована в конце. И Spring должна сделать это.
Проблема: хотя Spring может создать ваш компонент UserService через конфигурацию applicationContext, он не может переписать ваш UserService. Он не может просто вставить туда код, который открывает соединение с базой данных и фиксирует транзакцию с базой данных.
Но что она может сделать, так это создать прокси вокруг вашего UserService, который будет транзакционным. Таким образом, только прокси-сервер должен знать, как открывать и закрывать соединение с базой данных, а затем может просто делегировать его вашему UserService.
Давайте еще раз посмотрим на эту безопасную ContextConfiguration.
@Configuration @EnableTransactionManagement // (1) public class MyApplicationContextConfiguration { @Bean public UserService userService() { // (2) return new UserService(); } }
- Мы добавили аннотацию, сигнализирующую Spring: да, нам нужна поддержка
@Transactional, которая автоматически включает прокси Cglib под капотом. - С указанным выше набором аннотаций Spring не просто создает и возвращает ваш UserService здесь. Он создает Cglib-прокси вашего компонента, который выглядит, пахнет и делегирует ваш UserService, но фактически оборачивает ваш UserService и предоставляет свои функции управления транзакциями.
Поначалу это может показаться немного не интуитивным, но большинство разработчиков Spring очень скоро сталкиваются с прокси в сеансах отладки. Из-за прокси трассировки стека Spring могут быть довольно длинными и незнакомыми: когда вы входите в метод, вы можете очень хорошо сначала войти в прокси — что отпугивает людей. Это, однако, совершенно нормальное и ожидаемое поведение.
Нужно ли Spring использовать прокси Cglib?
Прокси являются выбором по умолчанию при программировании AOP с помощью Spring. Однако вы не ограничены использованием прокси, вы также можете пройти полный маршрут AspectJ, который при желании изменяет ваш фактический байт-код. Однако покрытие AspectJ выходит за рамки данного руководства.
Также смотрите раздел: В чем разница между Spring AOP и AspectJ?
Резюме о поддержке Spring AOP
Конечно, о аспектно-ориентированном программировании можно сказать гораздо больше, но это руководство дает представление о том, как работают наиболее популярные сценарии использования Spring AOP, такие как @Transactional или Spring Security, @Secured. Вы можете даже написать свои собственные аннотации AOP, если хотите.
В качестве утешения для неожиданного конца, если вы хотите получить больше информации о том, как подробно работает управление @Transactional в Spring, посмотрите мое руководство по @Transactional.
Управление ресурсами Spring
Мы уже давно говорим о внедрении зависимостей и прокси. Давайте теперь посмотрим на то, что я бы назвал важными утилитами удобства в среде Spring. Одной из таких утилит является поддержка ресурсов Spring.
Подумайте, как бы вы попытались получить доступ к файлу в Java через HTTP или FTP. Вы можете использовать класс URL в Java и написать некоторый код.
Точно так же, как бы вы читали в файлах из пути к классам вашего приложения? Или из контекста сервлета, это означает из корневого каталога веб-приложений (по общему признанию, это становится все реже и реже в современном приложении packaged.jar).
Опять же, вам нужно написать довольно много стандартного кода, чтобы он работал, и, к сожалению, код будет отличаться для каждого варианта использования (URL-адреса, пути к классам, контексты сервлетов).
Но есть решение: абстракция ресурсов Spring. Это легко объяснить в коде.
import org.springframework.core.io.Resource; public class MyApplication { public static void main(String[] args) { ApplicationContext ctx = new AnnotationConfigApplicationContext(someConfigClass); // (1) Resource aClasspathTemplate = ctx.getResource("classpath:somePackage/application.properties"); // (2) Resource aFileTemplate = ctx.getResource("file:///someDirectory/application.properties"); // (3) Resource anHttpTemplate = ctx.getResource("https://marcobehler.com/application.properties"); // (4) Resource depends = ctx.getResource("myhost.com/resource/path/myTemplate.txt"); // (5) Resource s3Resources = ctx.getResource("s3://myBucket/myFile.txt"); // (6) } }
- Как всегда, вам нужен ApplicationContext для начала.
- Когда вы вызываете getResource() для applicationContext со строкой, которая начинается с classpath:, Spring будет искать ресурс в вашем application classpath.
- Когда вы вызываете getResource() со строкой, начинающейся с file:, Spring будет искать файл на вашем жестком диске.
- Когда вы вызываете getResource() со строкой, которая начинается с https: (или http), Spring будет искать файл в Интернете.
- Если вы не укажете префикс, это зависит от того, какой тип контекста приложения вы настроили. Подробнее об этом здесь.
- Это не работает из коробки со Spring Framework, но с дополнительными библиотеками, такими как Spring Cloud, вы даже можете напрямую обращаться к путям s3://.
Короче говоря, Spring дает вам возможность доступа к ресурсам с помощью приятного небольшого синтаксиса. Интерфейс ресурса имеет несколько интересных методов:
public interface Resource extends InputStreamSource { boolean exists(); String getFilename(); File getFile() throws IOException; InputStream getInputStream() throws IOException; // ... other methods commented out }
Как видите, он позволяет вам выполнять самые распространенные операции с ресурсом:
- Это существует?
- Какое имя файла?
- Получить ссылку на фактический объект File.
- Получить прямую ссылку на необработанные данные (InputStream).
Это позволяет вам делать все, что вы хотите с ресурсом, независимо от того, живете ли вы в Интернете, на вашем пути к классам или на жестком диске.
Абстракция ресурсов выглядит как такая крошечная функция, но она действительно сияет в сочетании со следующей удобной функцией, предлагаемой Spring: Properties.
Что такое Spring Environment?
Большая часть любого приложения — это чтение свойств (properties), таких как имя пользователя и пароли базы данных, конфигурация почтового сервера, детализированная конфигурация оплаты и т.д.
В простейшем виде эти свойства находятся в файлах .properties, и их может быть много:
- Некоторые из них на вашем classpath, так что у вас есть доступ к некоторым паролям, связанным с разработкой.
- Другие в файловой системе или на сетевом диске, поэтому рабочий сервер может иметь свои собственные, защищенные свойства.
- Некоторые могут даже прийти в форме переменных среды операционной системы.
Spring пытается упростить вам регистрацию и автоматический поиск свойств во всех этих различных источниках с помощью абстракции environment.
import org.springframework.core.env.Environment; public class MyApplication { public static void main(String[] args) { ApplicationContext ctx = new AnnotationConfigApplicationContext(someConfigClass); Environment env = ctx.getEnvironment(); // (1) String databaseUrl = env.getProperty("database.url"); // (2) boolean containsPassword = env.containsProperty("database.password"); // etc } }
- Через applicationContext вы всегда можете получить доступ к текущей среды (environment) выполняемого Spring приложения.
- Среда (environment), с другой стороны, позволяет вам, помимо прочего, получать доступ к свойствам.
Что такое environment?
Что такое Spring @PropertySources?
В двух словах, среда состоит из одного или многих источников свойств выполняемого Spring приложения. Например:
- /mydir/application.properties
- classpath:/application-default.properties
(Примечание. Среда также состоит из профилей, то есть профилей «dev» или «production», но мы не будем вдаваться в подробности о профилях в этом пересмотре этого руководства).
По умолчанию среда веб-приложения Spring MVC состоит из параметра ServletConfig/Context, источников системных свойств JNDI и JVM. Они также являются иерархическими, это означает, что они имеют порядок важности и перекрывают друг друга.
Тем не менее, довольно легко определить новые @PropertySources самостоятельно:
import org.springframework.context.annotation.PropertySources; import org.springframework.context.annotation.PropertySource; @Configuration @PropertySources( {@PropertySource("classpath:/com/${my.placeholder:default/path}/app.properties"), @PropertySource("file://myFolder/app-production.properties")}) public class MyApplicationContextConfiguration { // your beans }
Теперь стало намного понятнее, почему мы говорили об управлении ресурсами Spring раньше. Потому что обе функции идут рука об руку.
Аннотация @PropertySource работает с любым допустимым классом конфигурации Spring и позволяет вам определять новые дополнительные источники с помощью абстракции ресурсов Spring: помните, что все дело в префиксах: http://, file://, classpath: и т.д.,
Определение свойств через @PropertySources — это хорошо, но разве нет лучшего способа, чем пройти через среду, чтобы получить к ним доступ? Да, есть.
Spring аннотация @Value и внедрение значений свойств
Вы можете внедрять значения свойств в ваши bean-компоненты, так же, как вы бы добавили зависимость с аннотацией @Autowired. Но для свойств вам нужно использовать аннотацию @Value.
import org.springframework.stereotype.Component; import org.springframework.beans.factory.annotation.Value; @Component public class PaymentService { @Value("${paypal.password}") // (1) private String paypalPassword; public PaymentService(@Value("${paypal.url}") String paypalUrl) { // (2) this.paypalUrl = paypalUrl; } }
- Аннотация
@Valueработает непосредственно с полями ... - Или по аргументам конструктора.
Там действительно не так много всего. Всякий раз, когда вы используете аннотацию @Value, Spring будет проходить через вашу (иерархическую) среду и искать соответствующее свойство — или выдавать сообщение об ошибке, если такого свойства не существует.
Spring Web MVC
Spring Web MVC, также известный как Spring MVC, является веб-средой Spring. Это позволяет создавать все, что связано с сетью, от небольших веб-сайтов до сложных веб-сервисов. Он также поддерживает фреймворки, такие как Spring Boot.
Что такое MVC?
Если вы совершенно не знакомы с MVC, вы можете прочитать страницу Model-View-Controller в Википедии, прежде чем продолжить чтение.
В контексте рендеринга HTML-страниц, скажем, страницы учетной записи пользователя, вот как выглядит MVC в Spring:
- Ваша Model (модель) содержит данные, которые вы хотите отобразить на веб-странице. Однако данные полностью независимы от вашего HTML, это простые объекты Java (например, объекты пользователя), из которых состоит ваше приложение.
- Ваше View (представление) будет HTML-шаблоном, который является каркасом для вашей HTML-страницы, написанной с определенной библиотекой шаблонов. Эти библиотеки позволяют включать заполнители в ваши шаблоны, которые позволяют получить доступ к данным модели, например, имени пользователя.
- Controller (Контроллер) будет аннотированным методом
@Controller, который отвечает на HTTP-запрос /account и знает, как преобразовать HTTP-запрос в объекты Java, а также ваши объекты Java в ответ HTML.
Итак, вашей конечной целью является написание контроллеров с помощью Spring, которые сопоставляются с конкретными HTTP-запросами, такими как (/account), и предоставляют пользователю соответствующую HTML-страницу, которая визуализируется путем объединения представления и данных, необходимых для этой страницы.
Та же логика верна для написания веб-сервисов JSON или XML.
Прежде чем мы рассмотрим реализацию класса типа контроллер, давайте сделаем шаг назад и посмотрим, как мы реализовали бы веб-страницу в низко-низко-низкоуровневом Java: с помощью старого доброго API сервлета Java (на котором основывается Spring MVC). ).
HttpServlet памятка
На данный момент игнорируем MVC: чтобы написать что-нибудь, связанное с HTTP с Java, вы бы использовали сервлеты или, в частности, HttpServlets (примечание для придир: да, есть и другие способы, спасибо за замечание). Сервлеты могут обрабатывать HTTP-запросы, а также возвращать браузеру или клиенту соответствующий HTTP-ответ.
После написания вашего сервлета вы должны зарегистрировать его в контейнере сервлетов, таком как Tomcat или Jetty. Регистрация сервлета всегда включает путь, чтобы указать, за какие URL в вашем веб-приложении отвечает ваш сервлет. Давайте предположим путь "/*", поэтому каждый входящий HTTP-запрос к вашему приложению обрабатывается одним сервлетом.
Вот как может выглядеть этот сервлет:
import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; public class MyServlet extends HttpServlet { // (1) @Override protected void doGet(HttpServletRequest request, HttpServletResponse response) { // (2) if (request.getRequestURI().startsWith("/account")) { String userId = request.getParameter("userId"); // return <html> or {json} or <xml> for an account get request } else if (request.getRequestURI().startsWith("/status")) { // return <html> or {json} or <xml> for a health status get request } // etc } @Override protected void doPost(HttpServletRequest request, HttpServletResponse response) { // (3) // return <html> or {json} or <xml> for a post request, like a form submission } }
- Ваш сервлет должен расширить Java HttpServlet.
- Вы можете переопределить метод doGet(), чтобы обрабатывать запросы Http GET. С отображением сервлета "/" это означает для всех запросов GET. Таким образом, запрос «/status», «/info», «/account» в конечном итоге будет выполнен в одном и том же методе doGet.
- Вы можете переопределить метод doPost() для обработки запросов POST Http. С отображением сервлета "/" это означает для всех запросов POST. Таким образом, отправка форм в «/register», «/submit-form», «/password-recovery» в конечном итоге будет осуществляться одним и тем же методом doPost().
Обрабатывать каждый запрос к вашему приложению всего двумя способами — это немного громоздко, и для того, чтобы получить правильный MVC, требуется довольно много работы.
Кроме того, вашему MyServlet (контроллеру) необходимо выполнить довольно много ручного HTTP-специфического подключения, проверки URI запроса, просмотра строк, преобразования requestParameters и ответов и так далее.
Было бы намного приятнее, если бы вам не пришлось заботиться обо всем этом слесарном деле и позволить Spring сделать это за вас. Вот тут и приходит DispatcherServlet.
Что делает DispatcherServlet?
Uber-контроллер в среде Spring MVC Spring представляет собой сервлет, который называется DispatcherServlet.
Он называется DispatcherServlet, потому что он может буквально обрабатывать любой входящий HTTP-запрос, анализировать его содержимое и пересылать данные в виде симпатичных маленьких объектов Java в класс Controller.
Он также достаточно умен, чтобы брать выходные данные с этих контроллеров и конвертировать их в HTML / JSON / XML, в зависимости от того, что подходит. Весь процесс выглядит следующим образом (с пренебрежением большим количеством промежуточных классов, потому что DispatcherServlet не выполняет всю работу сам).

Это именно то, что вы хотите.
- Spring заботится обо всей HTTP механике.
- Вы пишете свои контроллеры.
- А также представления (шаблоны) и модели (ваши Java объекты).
Давайте посмотрим на эти классы типа Controller более подробно.
Как писать классы типа Controller
Наконец, мы можем написать наш Controller класс, который обрабатывает запросы /account.
Страница /account будет HTML-страницей с несколькими динамическими переменными, такими как имя пользователя, адрес, информация о подписке и т.д.
import org.springframework.stereotype.Controller; import org.springframework.ui.Model; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.PathVariable; /** * A class that responds to /account requests. * Think of Netflix's account page, where you want to see your username/password/subscription info */ @Controller // (1) public class AccountController { @GetMapping("/account/{userId}") public String account(@PathVariable Integer userId) { // (2) // TODO retrieve name, address, subscription information return "templates/account"; // (3) } }
В этих двух строчках происходит МНОГО, давайте посмотрим, что именно.
У вас есть класс AccountController, который аннотируется @Controller. Он сообщает Spring: этот класс хочет реагировать на HTTP-запросы и ответы, чтобы DispatcherServlet знал об этом.
У вас есть простой Java-метод, называемый account(). Что еще интереснее, метод аннотируется @GetMapping. Это сообщает DispatcherServlet, что все запросы, похожие на /account/{userId}, должны обрабатываться именно этим методом контроллера. Более того, dispatcherServlet возьмет {userId}, преобразует его в целое число и использует его в качестве параметра метода!
Наш метод Java возвращает строку с именем account. На самом деле это не просто строка, а ссылка на представление (HTML-шаблон). Давайте посмотрим на эти шаблоны на секунду.
Как генерировать HTML представление (view) с помощью Spring Web MVC
Spring MVC по умолчанию предполагает, что вы хотите визуализировать некоторый HTML. И, конечно же, вы не хотите сами отображать HTML-строки с помощью конкатенации строк, скорее вы захотите использовать шаблонную среду, такую как Velocity или Freemarker. Spring интегрируется со всеми этими технологиями.
Итак, вы могли бы иметь следующее представление (шаблон):
classpath:/templates/account.vm
<html> <body> Hello $user.name, this is your account! <!-- list subscriptions etc --> </body> </html>
Это очень простая HTML-страница, содержащая одну переменную, $user.name. Как эта переменная попадает в шаблон? Пока что этого не было в нашем контроллере аккаунта. Давайте вставим это.
import org.springframework.stereotype.Controller; import org.springframework.ui.Model; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.PathVariable; @Controller public class AccountController { @GetMapping("/account/{userId}") public String account(Model model, @PathVariable Integer userId) { // (1) // TODO validate user id model.addAttribute("user", userDao.findById(userId)); // (2) return "templates/account"; // (3) } }
- Spring может автоматически ввести параметр "Model" в методы вашего контроллера. Как упоминалось ранее, модель содержит любые данные, которые вы хотели бы представить в своем представлении, т.е. ваш шаблон.
- Модель Spring ведет себя почти как map (отображение), вы просто добавляете в нее все свои данные и затем можете ссылаться на ключи отображения из вашего шаблона.
- Опять же, это ссылка на ваш view, шаблон аккаунта, который мы написали выше.
Вот и все, разработка Spring MVC полностью завершена!
Как генерировать JSON / XML (представления) с помощью Spring Web MVC
С веб-сервисами вы не генерируете HTML, а генерируете XML или JSON. Это довольно просто, с Spring MVC также.
Конечно, вам нужна соответствующая библиотека, такая как Jackson, добавленная в ваш проект, но тогда вы можете просто аннотировать свой Controller дополнительной аннотацией, чтобы сигнализировать Spring: пожалуйста, преобразуйте мои объекты Java напрямую в XML / JSON, вместо того, чтобы я давал вам ссылка на вид.
import org.springframework.stereotype.Controller; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.ResponseBody; @Controller public class HealthController { @GetMapping("/health") @ResponseBody // (1) public HealthStatus health() { return new HealthStatus(); // (2) } }
- На этот раз вы добавляете дополнительную аннотацию
@ResponseBodyв метод контроллера, который сообщает Spring, что вы хотите записать свой Java-объект HealthStatus непосредственно в HttpResponse (например, в виде XML или JSON). - Вы просто возвращаете простой Java-объект внутри вашего метода, а не строковую ссылку на ваше представление.
Но как Spring узнает, должен ли он возвращать XML, JSON или что-то еще?
Как работает согласование контента (content negotiation) Spring MVC
Существует множество способов, с помощью которых вы, как клиент, можете указать Spring MVC, какой формат ответа вы хотите при выполнении запроса к приложению Spring MVC.
- Указав заголовок Accept, такой как «Accept: application/json» или «Accept: application/xml». Это работает "из коробки", но требует определенных библиотек в вашем пути к классам для поддержки сортировки XML или JSON.
- Добавив расширение URL к вашему пути запроса, например /health.json или /health.xml. Это требует настройки на стороне Spring MVC для работы.
- Добавив параметр запроса в путь запроса, например /health?Format = json. Это требует настройки на стороне Spring MVC для работы.
Затем Spring знает: вы аннотировали этот метод с помощью @ResponseBody, и клиент хочет «JSON». У меня есть библиотека на пути к классам, как Джексон, которая может визуализировать JSON? Если да, хорошо, давайте преобразуем HealthStatus в JSON. В противном случае выведите исключение.
Если вы хотите узнать больше о согласовании контента, ознакомьтесь с официальной документацией.
Какой тип ввода HTTP-запроса понимает Spring?
Spring MVC понимает в основном все, что предлагает HTTP — с помощью сторонних библиотек.
Это означает, что вы можете выбросить в него тела запросов JSON, XML или HTTP (Multipart) Fileupload, и Spring удобно преобразует этот ввод в объекты Java.
Какие HTTP-ответы может написать Spring MVC?
Spring MVC может записывать все что угодно в HttpServletResponse — с помощью сторонних библиотек.
Будь то HTML, JSON, XML или даже тела ответов WebSocket. Более того, он берет ваши объекты Java и генерирует эти тела ответов для вас.
А как насчет других концепций Spring MVC?
Официальная документация Spring MVC буквально содержит сотни страниц, описывающих, как работает веб-фреймворк.
Поэтому, если вы хотите узнать больше о RequestParams, Моделях, Представлениях, ViewHandlers, RootContexts, Фильтрах, Кэшировании и Безопасности, я приглашаю вас проверить это. Это просто не входит в рамки данного руководства, чтобы охватить все.
Однако в разделе часто задаваемых вопросов данного руководства есть ответы на несколько дополнительных вопросов.
Дополнительно: Кратко о Spring Boot
Хотя это руководство не касается Spring Boot, давайте немного отвлечемся, посмотрев на источник аннотации @RestController, с которой вы, возможно, уже сталкивались в своем проекте Spring Boot.
Вы могли бы подумать, что она присуща Spring Boot (как я ошибочно делал слишком долго), но, как правильно заметил Мацей Волковяк, это часть простого старого Spring MVC. Вот его источник:
// some other annotations left out @Controller @ResponseBody public @interface RestController { }
Это верно, Spring MVC @RestController — это не что иное, как Spring MVC @Controller в сочетании с аннотацией Spring MVC @ResponseBody — хотя вы можете подумать, что это что-то связанное со Spring Boot.
Резюме: Spring MVC
Spring MVC — это старый добрый фреймворк MVC, который позволяет довольно легко писать HTML / JSON / XML веб-сайты или веб-сервисы. Он прекрасно интегрируется с контейнером внедрения зависимостей Spring, включая все его вспомогательные утилиты.
Вкратце: он позволяет вам сосредоточиться на написании Java-классов, вместо того, чтобы иметь дело с сланцевым кодом сервлета, то есть работать с Http-запросами и ответами, и дает вам хорошее разделение проблем между вашей моделью и представлениями.
Дополнительные модули Spring Framework
Мы рассмотрели контейнер IoC Spring, Spring Web MVC и несколько других небольших модулей Spring. Но есть еще много. Что они делают?
О чем дополнительные модули Spring Framework?
Spring Framework состоит из еще большего количества удобных утилит, чем вы видели до сих пор. Давайте назовем их модулями и не путайте эти модули с 20 другими проектами Spring на spring.io. Наоборот, все они являются частью рамочного проекта Spring.
Итак, о каком удобстве идет речь?
Вы должны понимать, что в основном все, что Spring предлагает в этих модулях, также доступно на чистой Java. Предлагается либо JDK, либо сторонней библиотекой. Spring Framework всегда опирается на эти существующие функции.
Вот пример: отправка вложений электронной почты с помощью Java API Почты, безусловно, выполнима, но немного неудобна в использовании. Смотрите здесь примера кода.
Spring предоставляет приятную маленькую API-оболочку поверх Java Mail API, с тем дополнительным преимуществом, что все, что он предлагает, прекрасно вписывается в контейнер внедрения зависимостей Spring.
import org.springframework.core.io.FileSystemResource; import org.springframework.mail.javamail.JavaMailSender; import org.springframework.mail.javamail.MimeMessageHelper; public class SpringMailSender { @Autowired private JavaMailSender mailSender; // (1) public void sendInvoice(User user, File pdf) throws Exception { MimeMessage mimeMessage = mailSender.createMimeMessage(); MimeMessageHelper helper = new MimeMessageHelper(mimeMessage, true); // (2) helper.setTo("john@rambo.com"); helper.setText("Check out your new invoice!"); FileSystemResource file = new FileSystemResource(pdf); helper.addAttachment("invoice.pdf", file); mailSender.send(mimeMessage); } }
- Все, что связано с настройкой почтового сервера (URL, имя пользователя, пароль), абстрагируется от класса MailSender, специфичного для Spring, который вы можете внедрить в любой компонент, который хочет отправлять электронную почту.
- Spring предлагает конструкторы удобства, такие как MimeMessageHelper, для создания составных электронных писем, скажем, из файлов, как можно быстрее.
Итак, подытоживая, цель Spring Framework состоит в том, чтобы «упростить» доступную функциональность Java, подготовить ее к внедрению зависимостей и, следовательно, упростить использование API в контексте Spring.
Есть ли список всех дополнительных модулей Spring Framework?
Я хотел бы дать вам краткий обзор наиболее распространенных утилит, функций и модулей, с которыми вы можете столкнуться в проекте Spring. Однако обратите внимание, что подробное описание всех этих инструментов невозможно в рамках данного руководства. Вместо этого взгляните на официальную документацию для получения полного списка.
- Spring’s Data Access: не путать с библиотеками Spring Data (JPA / JDBC). Это основа для поддержки Springs
@Transactional, а также чистой интеграции JDBC и ORM (например, Hibernate). - Spring Integration модули: упрощает отправку электронных писем, интеграцию с JMS или AMQP, планирование задач и т. Д.
- Spring Expression Language (SpEL): Даже если это не совсем правильно, думайте о нем как о DSL или Regex для создания / конфигурации / внедрения Spring Bean. Это будет описано более подробно в следующих версиях этого руководства.
- Реактивные модули Spring. Позволяет писать реактивные веб-приложения.
- Фреймворк тестирования Spring. Позволяет (интегрировать) тестировать контексты Spring и, следовательно, приложения Spring, включая вспомогательные утилиты для тестирования служб REST.
Spring Framework: FAQ
Какую версию Spring я должен использовать?
Выбор версии Spring относительно прост:
- Если вы создаете новые проекты Spring Boot, используемая вами версия Spring уже предопределена. Например, если вы используете Spring Boot 2.2.x, вы будете использовать Spring 5.2.x (хотя теоретически вы можете переопределить это).
- Если вы используете обычный Spring в новом проекте, вы можете выбрать любую версию, какую захотите. Текущая последняя версия Spring 5.2.3.RELEASE, и вы всегда можете найти анонсы новых версий в блоге Spring.
- Если вы используете Spring в унаследованном проекте, вы всегда можете подумать о переходе на более новую версию Spring, если это имеет смысл с точки зрения бизнеса (или если вы хотите следовать EOL анонсу) — версии Spring имеют высокую степень совместимости (см. следующий параграф).
В реальности вы можете найти проекты на Spring версии 4.x-5.x, используемые компаниями, хотя имеются и редкие, унаследованные проекты на Spring 3.x (первоначальный выпуск: 2009).
Как часто выпускаются новые версии Spring? Как долго они поддерживаются?
Вот хороший маленький график, показывающий историю версий Spring:

Вы можете видеть, что первоначальная версия Spring была ~ 17 лет назад, а основные версии платформы выпускались каждые 3-4 года. Это не учитывает филиалы обслуживания, как бы то ни было.
- Например, Spring 4.3 был выпущен в июне 2016 года и будет поддерживаться до конца 2020 года.
- Даже поддержка Spring 5.0 и 5.1 будет прекращена в конце 2020 года, в пользу Spring 5.2, которая была выпущена в сентябре 2019 года.
Примечание. Текущий EOL() (больше никаких обновлений и поддержки) для всех версий Spring, кроме 5.2, в настоящее время настроен на 31 декабря 2020 года.
Какие библиотеки вам нужны, чтобы начать работу с Spring?
На самом деле существует только одна зависимость, которая вам нужна, когда вы хотите настроить проект Spring. Это называется spring-context. Это абсолютный минимум, чтобы заставить работать инъекционный контейнер Spring.
Если вы работаете над проектом Maven или Gradle, вы можете просто добавить к нему следующую зависимость (см. также вопрос выше: Какую версию Spring мне следует использовать?) — вместо загрузки указанного файла .jar и добавления его в ваш проект вручную.
<!-- Maven --> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-context</artifactId> <version>5.2.3.RELEASE</version> </dependency>
// Gradle compile group: 'org.springframework', name: 'spring-context', version: '5.2.3.RELEASE'
Для дополнительных функций Spring (таких как поддержка Spring JDBC или JMS) вам потребуются другие дополнительные библиотеки.
Вы можете найти список всех доступных модулей в официальной документации Spring, хотя с точки зрения зависимостей Maven artifactIds действительно следуют за именем модуля. Вот пример:
<!-- Maven --> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-webmvc</artifactId> <version>5.2.3.RELEASE</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-jdbc</artifactId> <version>5.2.3.RELEASE</version> </dependency>
Чем отличаются версии Spring?
Подобно JVM, версии Spring безумно обратно совместимы, что означает, что вы можете (по существу) по-прежнему запускать файлы Spring 1.0 xml с последней версией Spring 5.0 (хотя я, по общему признанию, еще не пробовал это). Кроме того, обновление с, скажем, 3 до 5 также возможно с небольшими усилиями (см. Это руководство по миграции).
Таким образом, в целом, новые версии Spring основаны на более старых версиях Spring и имеют минимальные критические изменения (по сравнению, скажем, с Python 2 против 3). Итак, все основные концепции, которые вы изучили для Spring версии 3 или 4, остаются верными для Spring версии 5.
Вы можете получить отличный обзор того, что изменилось за последние 7 лет в отдельных версиях Spring, здесь:
Чтобы дать вам резюме:
Ядро (внедрение зависимостей, управление транзакциями и т.д.) Всегда остается неизменным или расширяется. Однако Spring идет в ногу со временем и предлагает поддержку для новых версий языка Java, улучшений инфраструктуры тестирования, веб-сокетов, реактивного программирования и т.д.
Что сейчас происходит в 20 других проектах Spring.io? Как насчет изменения реального байт-кода?
В рамках данного руководства я не могу вдаваться в подробности всех различных проектов, но давайте рассмотрим те, с которыми вы, скорее всего, столкнетесь.
- Spring Boot: Пожалуй, самый популярный проект Spring. В Spring Boot принят "компетентный" подход к Spring Framework. Посмотрите ниже вопрос про разницу между Spring и Spring Boot чтобы выяснить, что на самом деле означает эта довольно бессмысленная фраза.
- Spring Batch: библиотека, которая помогает вам писать старые добрые пакетные задания.
- Spring Cloud: набор библиотек, которые помогают вашему проекту Spring легче интегрироваться с «облаком» (например, AWS) или писать микросервисы.
- Spring Security: библиотека, которая помогает вам защитить, например, ваше веб-приложение с OAuth2 или Basic Auth.
- и многое другое ...
Вывод: все эти библиотеки расширяют Spring Framework и основываются на его основных принципах внедрения зависимостей.
В чем разница между Spring и Spring Boot?
Если вы прочитали это руководство, вы должны понимать, что Spring Boot построен поверх Spring. Несмотря на то, что скоро появится подробное руководство по Spring Boot, вот пример того, что означают «самоуверенные значения по умолчанию» в Spring Boot.
Spring предлагает вам возможность читать .properties файлы из разных мест, например с помощью аннотаций @PropertySource. Он также предлагает вам возможность писать контроллеры JSON REST с помощью своей инфраструктуры Web MVC.
Проблема в том, что вы должны сами написать и настроить все эти отдельные части. Spring Boot, с другой стороны, берет эти отдельные части и связывает их вместе. Пример:
- Всегда и автоматически ищите файлы application.properties в разных местах и читайте их.
- Всегда загружайте встроенный Tomcat, чтобы вы могли сразу увидеть результаты работы ваших Rest контроллеров.
- Автоматически настраивайте все для отправки / получения JSON, не беспокоясь о конкретных зависимостях Maven / Gradle.
Все это запускается основным методом в классе Java, который снабжен аннотацией @SpringBootApplication. Более того, Spring Boot предлагает плагины Maven / Gradle, которые позволяют вам упаковать ваше приложение в файл .jar, который вы можете запустить следующим образом:
java -jar mySpringBootApp.jar
Итак, Spring Boot — это все, что нужно для того, чтобы собрать существующие части Spring Framework, предварительно сконфигурировать и упаковать их с минимальными затратами на разработку.
В чем разница между Spring AOP и AspectJ?
Как упомянуто выше в разделе Нужно ли Spring использовать прокси Cglib?" в Spring по умолчанию используется AOP на основе прокси. Он оборачивает ваши компоненты в прокси для достижения таких вещей, как управление транзакциями. Это имеет несколько ограничений и предостережений, но является довольно простым и понятным способом реализации наиболее распространенных проблем AOP, с которыми сталкиваются разработчики Spring.
AspectJ, с другой стороны, позволяет вам изменять фактический байт-код путем ткачества времени загрузки или ткачества времени компиляции. Это дает вам гораздо больше возможностей в обмен на гораздо большую сложность.
Однако вы можете настроить Spring на использование AOP AspectJ вместо AOP по умолчанию на основе прокси.
Вот пара ссылок, если вы хотите получить больше информации по этой теме:
В чем разница между Spring и Spring Batch?
Spring Batch — это фреймворк, упрощающий написание пакетных заданий, т.е. «Читать эти 95 CSV-файлов каждую ночь в 3 часа ночи и вызывать внешнюю службу проверки для каждой записи».
Опять же, он построен на основе Spring Framework, но во многом является собственным проектом.
Тем не менее, обратите внимание, что по сути невозможно создать надежное пакетное задание без хорошего понимания общего управления транзакциями в Spring Framework и его отношения к Spring Batch.
В чем разница между Spring и Spring Web MVC?
Если вы прочитали это руководство, вы должны понимать, что Spring Web MVC является частью среды Spring.
На очень высоком уровне это позволяет вам превратить ваше Spring-приложение в веб-приложение с помощью DispatcherServlet, который маршрутизирует классы @Controller.
Это могут быть RestControllers (где вы отправляете XML или JSON клиенту) или старые добрые HTML-контроллеры, где вы генерируете HTML с такими фреймворками, как Thymeleaf, Velocity или Freemarker.
В чем разница между Spring и Struts?
Вопрос должен быть: чем отличается Spring Web MVC от Struts?
Краткий исторический ответ таков: Spring Web MVC начинал как конкурент Struts, который, как утверждается, был плохо спроектирован разработчиками Spring (см. Википедию).
Современный ответ заключается в том, что, хотя Struts 2, безусловно, все еще используется в странном устаревшем проекте, Spring Web MVC является основой для всего, что связано с сетью во вселенной Spring. От Spring Webflow до RestControllers Spring Boot.
Что лучше? Spring XML или аннотации или Java конфигурация?
Spring начинался только с конфигурации XML. Затем медленно, все больше и больше появлялись аннотации / возможности Java конфигурации.
Сегодня вы заметитите, что конфигурация XML в основном используется в более старых, унаследованных проектах, а в новых проектах используется конфигурации на основе Java или аннотаций.
Обратите внимание на две вещи:
- По сути, ничто не мешает объединить XML / Аннотации / Java Config в одном проекте, но это обычно приводит к путанице.
- Вы должны стремиться к однородности в своей конфигурации Spring, то есть не генерировать случайным образом некоторые конфигурации с XML, некоторые с конфигурацией Java, а некоторые с компонентным сканированием.
Что лучше? Внедрение зависимостей на основе конструктора или поля?
Как уже упоминалось в разделе о внедрении зависимостей, этот вопрос вызывает много разных мнений. Самое главное, что ваш выбор должен быть одинаковым для всего вашего проекта: не используйте внедрение на основе конструктора для 83% ваших бинов и внедрение на основе поля для остальных 17%.
Разумным подходом будет использование рекомендованного способа в документации Spring: использование внедрения конструктора для обязательных зависимостей, установка / установка поля для необязательных зависимостей, а затем проверка этих дополнительных зависимостей по всему классу на ноль.
Самое главное, имейте в виду: общий успех вашего программного проекта не будет зависеть от выбора вашего любимого метода внедрения зависимостей.
Есть ли альтернативы контейнеру внедрения зависимостей в Spring?
Да, две популярные в экосистеме Java:
- Google Guice
- Google Dagger, ранее Square
Обратите внимание, что Dagger предлагает только внедрение зависимостей, без дополнительных удобных функций. Guice предлагает внедрение зависимостей и другие функции, такие как управление транзакциями (с помощью Guice Persist).
Заключение
Если вы читали это далеко, то теперь у вас должно быть достаточно глубокое понимание того, что такое Spring Framework.
Вы узнаете, как это связано с другими библиотеками экосистемы Spring (такими как Spring Boot или Spring Data) в последующих руководствах, но сейчас я хочу, чтобы вы помнили эту метафору при попытке ответить на вопрос «Что такое Spring Фреймворк?»
Представьте, что вы хотите отремонтировать дом (~ = создать программный проект).
Spring Framework — это ваш DIY-магазин (~ = контейнер для инъекций зависимости), который предлагает множество различных инструментов, от горелок Бунзена (~ = ресурсы / свойства) до кувалд (~ = Web MVC) для вашего обновления. Эти инструменты просто помогут вам быстрее и удобнее отремонтировать ваш дом (создать приложение на Java).
(примечание: не спрашивайте меня, как я придумал эти сравнения;))
Вот и все на сегодня. Если у вас есть какие-либо вопросы или предложения, напишите мне по адресу marco@marcobehler.com или оставьте комментарий ниже. Для практических занятий ознакомьтесь с учебным курсом Spring Framework.
Спасибо за прочтение. Auf Wiedersehen.
Благодарности
Большое спасибо:
- Patricio Moschcovich, за то, что он проделал потрясающую работу, вычитав эту статью и указав на кучу небольших ошибок.
- Maciej Walkowiak за то, что указал, что
@RestControllerвсегда был частью Spring MVC, а не Spring Boot.
(Благодарности автора оригинальной статьи — прим. перев.)

