Продолжаем двигаться к созданию реальных устройств на базе ПЛИС комплекса Redd. Для другого проекта All-Hardware мне нужен простенький логический анализатор, поэтому будем двигаться именно в этом направлении. Повезёт — дойдём и до шинного анализатора USB (но это пока в отдалённой перспективе). Сердцем любого анализатора является ОЗУ и блок, который сначала закачивает в него данные, а затем изымает их. Сегодня мы как раз спроектируем его.
Для этого мы освоим блок DMA. Вообще, DMA — моя любимая тема. Я даже делал большую статью про DMA у некоторых контроллеров ARM. Из той статьи видно, что DMA отнимает такты у шины. В текущей статье мы рассмотрим, как дела обстоят в случае процессорной системы на базе ПЛИС.

Начинаем создавать аппаратную часть. Чтобы понять, насколько блок DMA конфликтует за такты, нам понадобится проводить точные измерения при высокой нагрузке на шине Avalon-MM (Avalon Memory-Mapped). Мы уже выяснили, что мост Altera JTAG-to-Avalon-MM не может дать высокой нагрузки на шину. Поэтому сегодня придётся добавить в систему процессорное ядро, чтобы оно обращалось к шине на высокой скорости. Как это делается, было описано тут. Давайте ради оптимальности отключим процессорному ядру оба кэша, но создадим по одной сильносвязной шине, как мы делали тут.
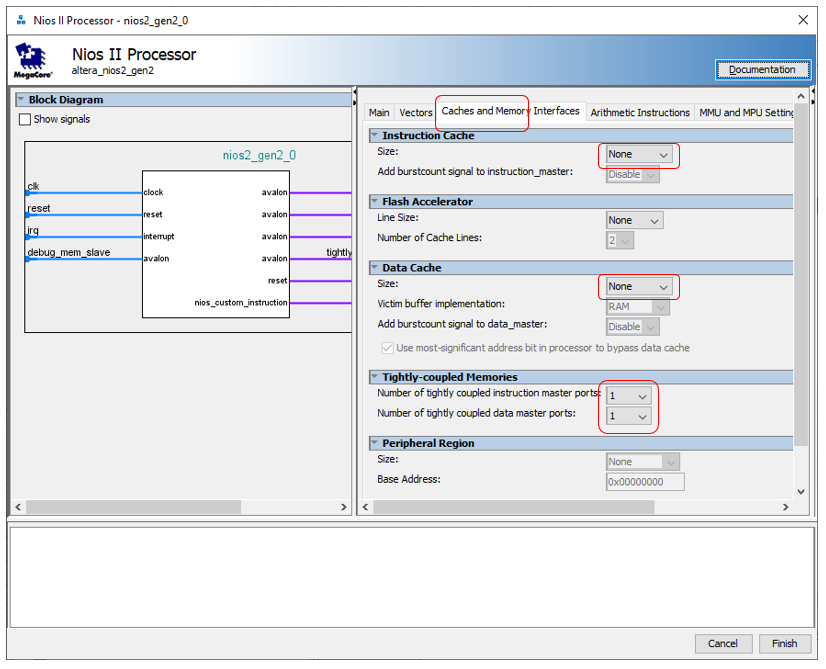
Добавим по 8 килобайт памяти программ и памяти данных. Помним, что память должна быть двухпортовая и иметь адрес в особом диапазоне (чтобы он не спрыгивал – запрём его на замок, причины всего этого мы обсуждали тут).
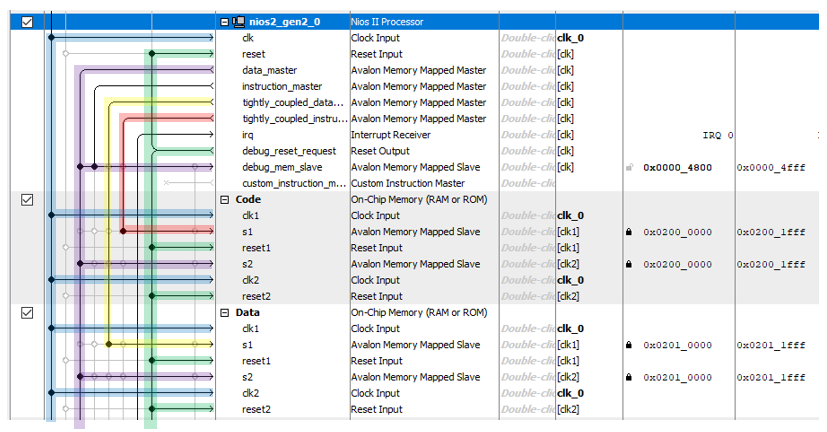
Проект мы уже тысячу раз создавали, так что особо интересного в самом процессе создания ничего нет (если что, все шаги создания описаны тут).
База готова. Теперь нам нужен источник данных, которые мы будем помещать в память. Идеальная вещь – постоянно тикающий таймер. Если во время какого-то такта блок DMA был не в состоянии обрабатывать данные, то мы сразу увидим это по пропущенному значению. Ну, то есть, если в памяти есть значения 1234 и 1236, то значит на такте, когда таймер выдавал 1235, блок DMA не переносил данные. Создаём файл Timer_ST.sv с таким простейшим счётчиком:
Этот счётчик – как пионер: всегда готов (на выходе source_valid всегда единица) и всегда считает (кроме моментов состояния сброса). Почему у модуля именно такие сигналы – мы обсуждали в этой статье.
Теперь создаём свой компонент (как это делается, описано тут). Автоматика ошибочно выбрала нам шину Avalon_MM. Заменяем её на avalon_streaming_source и сопоставляем сигналы, как показано ниже:

Прекрасно. Добавляем наш компонент в систему. Теперь ищем блок DMA… И находим не один, а целых три. Все они описаны в документе Embedded Peripheral IP User Guide от Альтеры (как всегда, я даю названия, но не ссылки, так как ссылки вечно меняются).
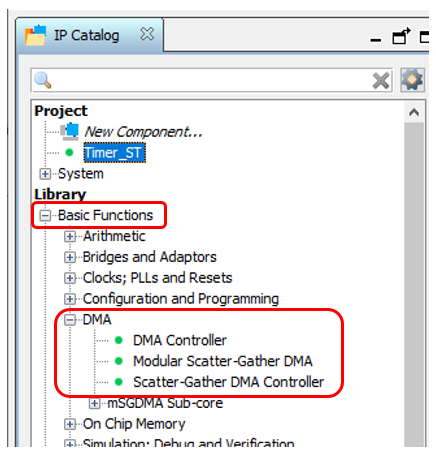
Который из них использовать? Я не могу удержаться от ностальгии. В далёком 2012-м году, делал я систему на базе шины PCIe. Все методички от Альтеры, содержали пример на базе первого из этих блоков. Но он с компонентом PCIe давал скорость не выше 4 мегабайт в секунду. В те времена я плюнул и написал свой блок DMA. Сейчас я его скорость уже не вспомню, но данные от SATA дисков он гонял на пределе возможностей дисков и SSD тех времён. То есть, у меня на этот блок наточен зуб. Но скатываться в сравнение трёх блоков я не стану. Дело в том, что сегодня нам предстоит работать с источником на базе Avalon-ST (Avalon Streaming Interface), а такие источники поддерживает только блок Modular Scatter-Gather DMA. Вот его мы и положим на схему.
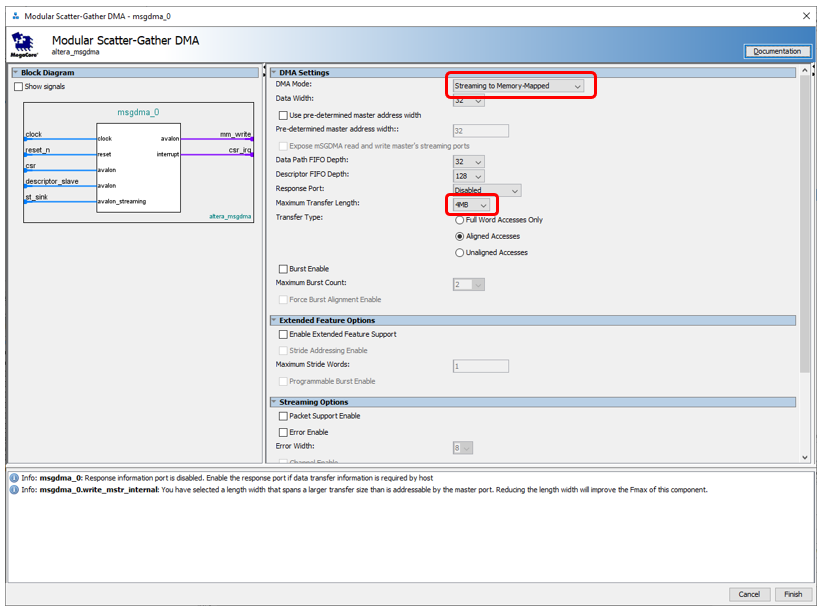
В настройках блока выбираем режим Streaming to Memory Mapped. Плюс – я хочу гонять данные от запуска до заполнения SDRAM, поэтому максимальный блок для передачи данных заменил с 1 килобайта на 4 мегабайта. Меня, правда, предупредили, что в итоге параметр FMax будет не ахти (даже если заменить максимальный блок на 2 килобайта). Но на сегодня FMax приемлемый (104 МГц), а дальше – разберёмся. Остальные параметры я оставил без изменения. Можно ещё поставить режим передачи Full Word Access Only, это повысит FMax до 109 МГц. Но за производительность мы биться будем не сегодня.
Итак. Источник есть, DMA есть. Приёмник… SDRAM? В будущих боевых условиях – да. Но сегодня нам нужна память с заведомо известными характеристиками. К сожалению, у SDRAM требуется периодически посылать команды, занимающие несколько тактов, плюс эта память может быть занята регенерацией. Поэтому вместо неё мы сейчас воспользуемся встроенной памятью ПЛИС. У неё точно всё за один такт работает, без непредсказуемых задержек.
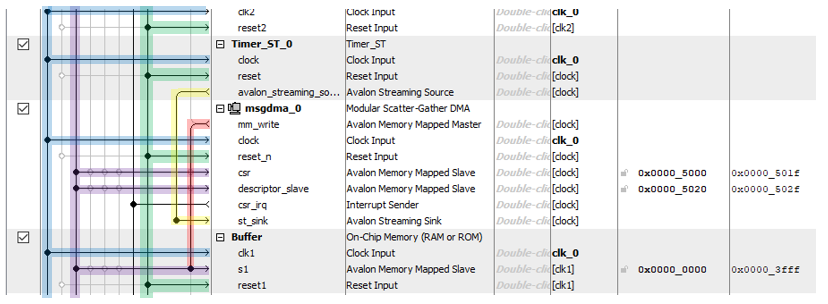
Так как контроллер SDRAM однопортовый, встроенную память тоже можно использовать исключительно в однопортовом режиме. Это важно. Дело в том, что мы хотим писать в память средствами мастера блока DMA, но с другой стороны, мы хотим читать из этой памяти средствами процессорного ядра или блока Altera JTAG-to-Avalon-MM. Рука так и тянется подключить блоки записи и чтения к двум разным портам… А нельзя! Вернее, запрещено условиями задачи. Потому что сегодня-то можно, но завтра мы заменим память на исключительно однопортовую. В общем, у нас получается такой блок из трёх компонентов (таймера, DMA и памяти):
Ну, и чисто для проформы, добавлю в систему JTAG UART и sysid (хотя, второй так и не помог, всё равно потом пришлось колдовать с JTAG-адаптером). Что это, и как их добавление решает мелкие проблемы, мы уже изучали. Подкрашивать шины я не буду, тут с ними всё ясно. Просто покажу, как это всё выглядит в моём проекте:

Всё. Система готова. Назначаем адреса, назначаем вектора процессора, генерим систему (не забываем, что сохранять надо с тем же именем, что и сам проект, тогда она попадёт на верхний уровень иерархии), добавляем её в проект. Делаем ножку reset виртуальной, подключаем clk к ноге pin_25. Собираем проект, заливаем его в аппаратуру… Как там она, бедняжка, в пустом из-за тотальной удалёнки офисе?.. Одиноко и страшно ей там, наверное, одной… Но я отвлёкся.
В BSP Editor привычным движением руки включаю поддержку С++. Скриншот этого дела я так часто вставлял, что перестаю это делать. А вот другой скриншот хоть уже и встречался, но ещё так часто. Так что обсудим его ещё разок. Мы помним, что система пытается положить данные в самый большой кусок памяти. А таковым у нас является Buffer. Поэтому принудительно перекинем всё на Data:

Делаем код, который просто заполняет память содержимым источника (в роли которого выступает счётчик).
Запускаем, ждём сообщения «You can play with memory!», ставим программу на паузу и смотрим память, начиная с адреса 0. Сначала я сильно испугался:
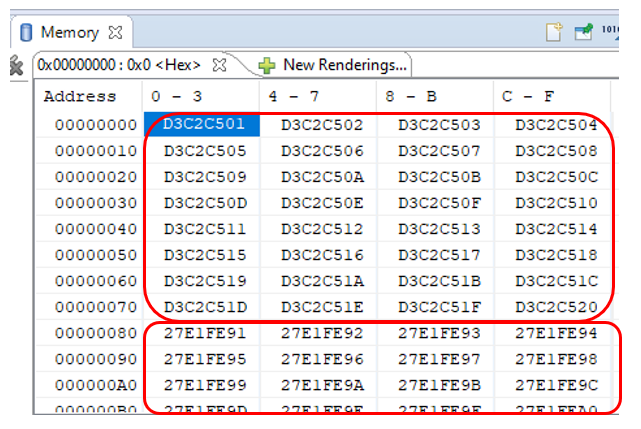
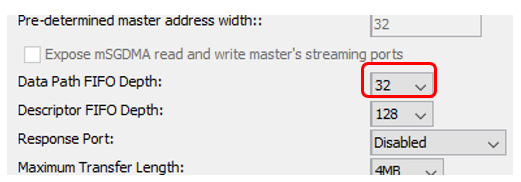
С адреса 0x80 счётчик резко меняет значение. Причём на очень большую величину. Но оказалось, что всё нормально. У нас же счётчик никогда не останавливается и всегда готов, а у DMA имеется собственная очередь упреждающего чтения. Напомню настройки блока DMA:
0x80 байт — это 0x20 тридцатидвухбитных слов. Как раз 32 десятичное. Всё сходится. В условиях отладки это не страшно. В боевых условиях источник будет работать более корректно (у него будет сброшена готовность). Поэтому просто игнорируем этот участок. На остальных участках счётчик считает последовательно. Покажу только фрагмент дампа по ширине. Поверьте на слово, что я осматривал его целиком.

Не доверяя глазам, я написал код, который автоматически проверяет данные:
Он тоже не выявляет никаких проблем.
На самом деле, отсутствие проблем — это не всегда хорошо. В рамках статьи, мне нужно было найти проблемы, а затем показать, как они устраняются. Ведь проблемы очевидны. Не может занятая шина пропускать данные без задержек! Задержки должны быть! Но давайте проверим, почему всё происходит так красиво. В первую очередь, может оказаться, что всё дело в FIFO блока DMA. Уменьшим их размеры до минимума:

Всё продолжает работать! Хорошо. Убедимся, что мы провоцируем число обращений к шине больше, чем размерность FIFO. Добавим счётчик обращений:

По окончании работы он равен 29. Это больше, чем 16. То есть, FIFO должно переполниться. На всякий случай, добавим побольше чтений регистра статуса. Не помогает.
С горя, я отключился от удалённого комплекса Redd, переделал проект под имеющуюся у меня макетную плату, к которой я могу прямо сейчас подключиться осциллографом (в офисе же никого — все на удалёнке, до осциллографа не дотянуться). Добавил в таймер два порта:
И назначил их:
В итоге, модуль стал выглядеть так:
Дома у меня макетка с кристаллом поменьше, так что аппетиты памяти пришлось уменьшать. И выяснилось, что моя примитивная программа не влезет в секцию, размером 4 килобайта. Так что тема, поднятая в прошлой статье — ох, как актуальна. Памяти в системе — в обрез!
При запуске программы получаем всплеск ready то ли на 16, то ли на 17 тактов. Это заполняется FIFO блока DMA. Тот самый эффект, который меня в начале напугал. Именно эти данные сформируют то самое ложное заполнение буфера.

Далее — имеем красивую картинку на 40960 наносекунд, то есть, 2048 тактов (с домашним кристаллом, буфер пришлось уменьшить до 8 килобайт, то есть, 2048 тридцатидвухбитных слов). Вот её начало:
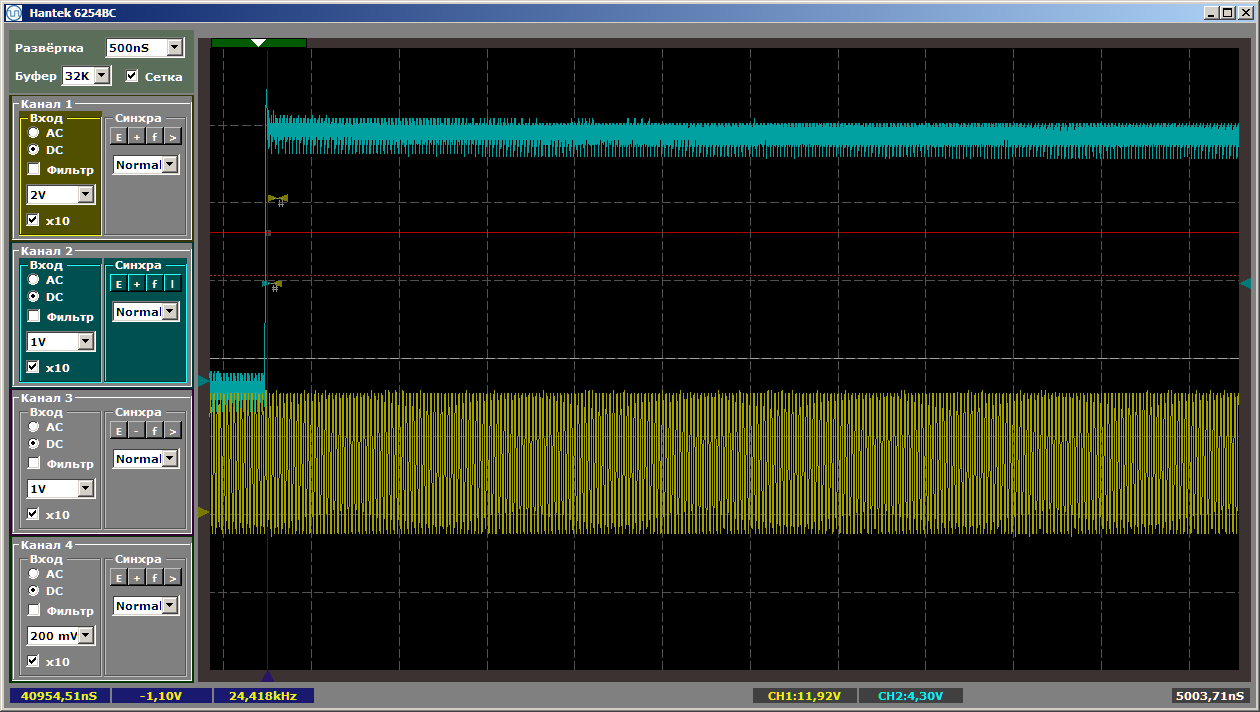
Вот конец:

Ну, и на всём протяжении — ни одного провала. Нет, было ясно, что так будет, но была некоторая надежда…
Может, надо в шину попробовать писать, а не только читать из неё? Я добавил в систему блок GPIO:

Добавил запись в него при ожидании готовности:

Вот нет проблем и всё тут! Кто же виноват?
Кто же виноват? С горя я начал изучать все меню инструмента Platform Designer и, кажется, нашёл разгадку. Как обычно выглядит шина? Набор проводов, к которым подключены клиенты. Так? Вроде, да. Мы же видим это из рисунков в редакторе. Как раз, вторая цель у статьи была показать, как можно разбить шину на два независимых сегмента, каждый из которых работает, не мешая другому.
Но давайте посмотрим на сообщения, которые выдаются при генерации системы. Выделю ключевые слова подсветкой:
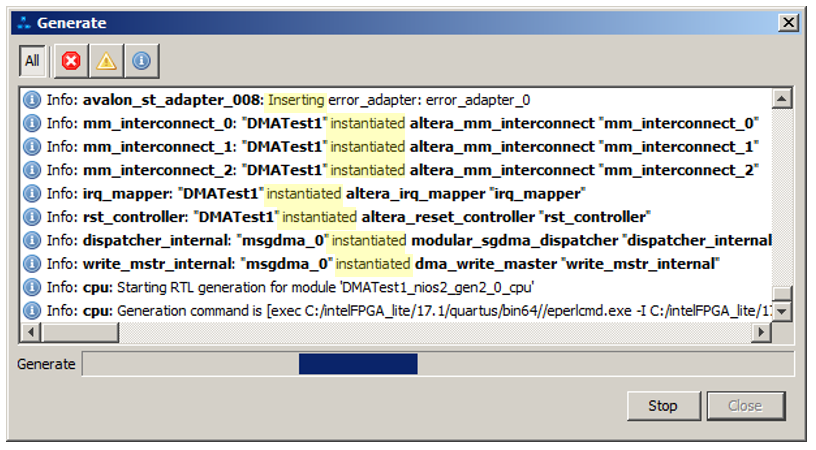
И там много подобных сообщений: то добавлено, это добавлено. Оказывается, после редактирования ручками в систему добавляется много дополнительных вещей. Как бы поглядеть на схему, в которой это уже всё имеется? Я ещё в этом плаваю, но наиболее вероятный ответ в рамках статьи мы можем получить, выбрав вот этот пункт меню:
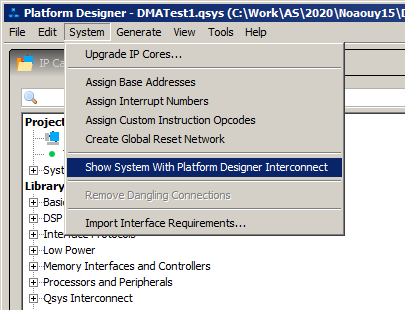
Открывшийся рисунок уже сам по себе впечатляет, но я не буду его приводить. А сразу выберу вот эту вкладку:
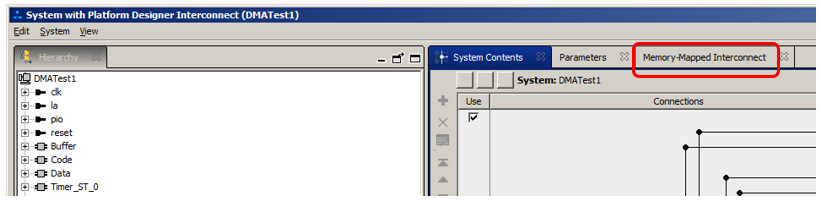
И там мы видим следующее:

Покажу покрупнее самое важное:

Шины не объединены! Они разбиты на сегменты! Обосновать не могу (возможно, меня поправят специалисты в комментариях), но похоже, что система вставила коммутаторы за нас! Именно эти коммутаторы создают изолированные сегменты шины, и основная система может работать в параллель с блоком DMA, который в это время бесконфликтно может обращаться к памяти!
Получив все эти знания, мы делаем вывод, что спровоцировать проблемы мы вполне можем. Это нужно для того, чтобы убедиться, что тестовая система их может создать, а значит, среда разработки действительно самостоятельно разруливает их. Будем обращаться не к абстрактным устройствам на шине, а к той же самой памяти Buffer, чтобы блок cmd_mux_005 распределял-таки шину между процессорным ядром и блоком DMA. Переписываем многострадальную функцию ожидания так:

И наконец-то на осциллограмме появились провалы!

Функция проверки памяти также нашла массу пропусков:
Да и на глаз мы прекрасно видим, что данные сдвинуты от строки к строке:

А вот пример конкретного сбойного места (отсутствует значение 6CCE488F):
Теперь мы видим, что эксперимент был сделан верно, просто среда разработки провела оптимизацию за нас. Это тот случай, когда фразу «Больно умные все стали» я произношу не с издёвкой, а с благодарностью. Спасибо разработчикам Квартуса за это дело!
Мы научились вставлять в систему блок DMA для перекачки потоковых данных в память. Также мы убедились, что процессу закачки не будет мешать работа прочих устройств на шине. Среда разработки автоматически создаст изолированный сегмент, который будет работать в параллель с другими участками шины. Само собой, если кто-то обратится к этому же сегменту, коллизии и временные затраты на их разрешение неизбежны, но программист вполне может предусмотреть такие вещи.
В следующей статье мы заменим ОЗУ на контроллер SDRAM, а таймер — на реальную «голову» и сделаем первый логический анализатор. Будет ли он работать —пока не знаю. Надеюсь, проблемы не появятся.
Для этого мы освоим блок DMA. Вообще, DMA — моя любимая тема. Я даже делал большую статью про DMA у некоторых контроллеров ARM. Из той статьи видно, что DMA отнимает такты у шины. В текущей статье мы рассмотрим, как дела обстоят в случае процессорной системы на базе ПЛИС.
Предыдущие статьи цикла
- Разработка простейшей «прошивки» для ПЛИС, установленной в Redd, и отладка на примере теста памяти.
- Разработка простейшей «прошивки» для ПЛИС, установленной в Redd. Часть 2. Программный код.
- Разработка собственного ядра для встраивания в процессорную систему на базе ПЛИС.
- Разработка программ для центрального процессора Redd на примере доступа к ПЛИС.
- Первые опыты использования потокового протокола на примере связи ЦП и процессора в ПЛИС комплекса Redd.
- Веселая Квартусель, или как процессор докатился до такой жизни.
- Методы оптимизации кода для Redd. Часть 1: влияние кэша.
- Методы оптимизации кода для Redd. Часть 2: некэшируемая память и параллельная работа шин.
- Экстенсивная оптимизация кода: замена генератора тактовой частоты для повышения быстродействия системы.
- Доступ к шинам комплекса Redd, реализованным на контроллерах FTDI
- Работа с нестандартными шинами комплекса Redd
- Практика в работе с нестандартными шинами комплекса Redd
- Проброс USB-портов из Windows 10 для удалённой работы
- Использование процессорной системы Nios II без процессорного ядра Nios II
Создание аппаратной части
Начинаем создавать аппаратную часть. Чтобы понять, насколько блок DMA конфликтует за такты, нам понадобится проводить точные измерения при высокой нагрузке на шине Avalon-MM (Avalon Memory-Mapped). Мы уже выяснили, что мост Altera JTAG-to-Avalon-MM не может дать высокой нагрузки на шину. Поэтому сегодня придётся добавить в систему процессорное ядро, чтобы оно обращалось к шине на высокой скорости. Как это делается, было описано тут. Давайте ради оптимальности отключим процессорному ядру оба кэша, но создадим по одной сильносвязной шине, как мы делали тут.
Добавим по 8 килобайт памяти программ и памяти данных. Помним, что память должна быть двухпортовая и иметь адрес в особом диапазоне (чтобы он не спрыгивал – запрём его на замок, причины всего этого мы обсуждали тут).
Проект мы уже тысячу раз создавали, так что особо интересного в самом процессе создания ничего нет (если что, все шаги создания описаны тут).
База готова. Теперь нам нужен источник данных, которые мы будем помещать в память. Идеальная вещь – постоянно тикающий таймер. Если во время какого-то такта блок DMA был не в состоянии обрабатывать данные, то мы сразу увидим это по пропущенному значению. Ну, то есть, если в памяти есть значения 1234 и 1236, то значит на такте, когда таймер выдавал 1235, блок DMA не переносил данные. Создаём файл Timer_ST.sv с таким простейшим счётчиком:
module Timer_ST ( input clk, input reset, input logic source_ready, output logic source_valid, output logic[31:0] source_data ); logic [31:0] counter; always @ (posedge clk, posedge reset) if (reset == 1) begin counter <= 0; end else begin counter <= counter + 1; end assign source_valid = 1; assign source_data [31:24] = counter [7:0]; assign source_data [23:16] = counter [15:8]; assign source_data [15:8] = counter [23:16]; assign source_data [7:0] = counter [31:24]; endmodule
Этот счётчик – как пионер: всегда готов (на выходе source_valid всегда единица) и всегда считает (кроме моментов состояния сброса). Почему у модуля именно такие сигналы – мы обсуждали в этой статье.
Теперь создаём свой компонент (как это делается, описано тут). Автоматика ошибочно выбрала нам шину Avalon_MM. Заменяем её на avalon_streaming_source и сопоставляем сигналы, как показано ниже:
Прекрасно. Добавляем наш компонент в систему. Теперь ищем блок DMA… И находим не один, а целых три. Все они описаны в документе Embedded Peripheral IP User Guide от Альтеры (как всегда, я даю названия, но не ссылки, так как ссылки вечно меняются).
Который из них использовать? Я не могу удержаться от ностальгии. В далёком 2012-м году, делал я систему на базе шины PCIe. Все методички от Альтеры, содержали пример на базе первого из этих блоков. Но он с компонентом PCIe давал скорость не выше 4 мегабайт в секунду. В те времена я плюнул и написал свой блок DMA. Сейчас я его скорость уже не вспомню, но данные от SATA дисков он гонял на пределе возможностей дисков и SSD тех времён. То есть, у меня на этот блок наточен зуб. Но скатываться в сравнение трёх блоков я не стану. Дело в том, что сегодня нам предстоит работать с источником на базе Avalon-ST (Avalon Streaming Interface), а такие источники поддерживает только блок Modular Scatter-Gather DMA. Вот его мы и положим на схему.
В настройках блока выбираем режим Streaming to Memory Mapped. Плюс – я хочу гонять данные от запуска до заполнения SDRAM, поэтому максимальный блок для передачи данных заменил с 1 килобайта на 4 мегабайта. Меня, правда, предупредили, что в итоге параметр FMax будет не ахти (даже если заменить максимальный блок на 2 килобайта). Но на сегодня FMax приемлемый (104 МГц), а дальше – разберёмся. Остальные параметры я оставил без изменения. Можно ещё поставить режим передачи Full Word Access Only, это повысит FMax до 109 МГц. Но за производительность мы биться будем не сегодня.
Итак. Источник есть, DMA есть. Приёмник… SDRAM? В будущих боевых условиях – да. Но сегодня нам нужна память с заведомо известными характеристиками. К сожалению, у SDRAM требуется периодически посылать команды, занимающие несколько тактов, плюс эта память может быть занята регенерацией. Поэтому вместо неё мы сейчас воспользуемся встроенной памятью ПЛИС. У неё точно всё за один такт работает, без непредсказуемых задержек.
Так как контроллер SDRAM однопортовый, встроенную память тоже можно использовать исключительно в однопортовом режиме. Это важно. Дело в том, что мы хотим писать в память средствами мастера блока DMA, но с другой стороны, мы хотим читать из этой памяти средствами процессорного ядра или блока Altera JTAG-to-Avalon-MM. Рука так и тянется подключить блоки записи и чтения к двум разным портам… А нельзя! Вернее, запрещено условиями задачи. Потому что сегодня-то можно, но завтра мы заменим память на исключительно однопортовую. В общем, у нас получается такой блок из трёх компонентов (таймера, DMA и памяти):
Ну, и чисто для проформы, добавлю в систему JTAG UART и sysid (хотя, второй так и не помог, всё равно потом пришлось колдовать с JTAG-адаптером). Что это, и как их добавление решает мелкие проблемы, мы уже изучали. Подкрашивать шины я не буду, тут с ними всё ясно. Просто покажу, как это всё выглядит в моём проекте:
Всё. Система готова. Назначаем адреса, назначаем вектора процессора, генерим систему (не забываем, что сохранять надо с тем же именем, что и сам проект, тогда она попадёт на верхний уровень иерархии), добавляем её в проект. Делаем ножку reset виртуальной, подключаем clk к ноге pin_25. Собираем проект, заливаем его в аппаратуру… Как там она, бедняжка, в пустом из-за тотальной удалёнки офисе?.. Одиноко и страшно ей там, наверное, одной… Но я отвлёкся.
Создание программной части
Подготовка
В BSP Editor привычным движением руки включаю поддержку С++. Скриншот этого дела я так часто вставлял, что перестаю это делать. А вот другой скриншот хоть уже и встречался, но ещё так часто. Так что обсудим его ещё разок. Мы помним, что система пытается положить данные в самый большой кусок памяти. А таковым у нас является Buffer. Поэтому принудительно перекинем всё на Data:
Эксперимент с программой
Делаем код, который просто заполняет память содержимым источника (в роли которого выступает счётчик).
Посмотреть код
#include "sys/alt_stdio.h" #include <altera_msgdma.h> #include <altera_msgdma_descriptor_regs.h> #include <system.h> #include <string.h> int main() { alt_putstr("Hello from Nios II!\n"); memset (BUFFER_BASE,0,BUFFER_SIZE_VALUE); // Остановили процесс, чтобы всё понастраивать IOWR_ALTERA_MSGDMA_CSR_CONTROL(MSGDMA_0_CSR_BASE, ALTERA_MSGDMA_CSR_STOP_DESCRIPTORS_MASK); // На самом деле, тут должно быть ожидание фактической остановки, // но в рамках теста, оно не нужно. Точно остановимся. // Добавляем дескриптор в FIFO IOWR_ALTERA_MSGDMA_DESCRIPTOR_READ_ADDRESS(MSGDMA_0_DESCRIPTOR_SLAVE_BASE, (alt_u32)0); IOWR_ALTERA_MSGDMA_DESCRIPTOR_WRITE_ADDRESS(MSGDMA_0_DESCRIPTOR_SLAVE_BASE, (alt_u32)BUFFER_BASE); IOWR_ALTERA_MSGDMA_DESCRIPTOR_LENGTH(MSGDMA_0_DESCRIPTOR_SLAVE_BASE, BUFFER_SIZE_VALUE); IOWR_ALTERA_MSGDMA_DESCRIPTOR_CONTROL_STANDARD(MSGDMA_0_DESCRIPTOR_SLAVE_BASE, ALTERA_MSGDMA_DESCRIPTOR_CONTROL_GO_MASK); // Запустили процесс, не забыв отключить прерывания IOWR_ALTERA_MSGDMA_CSR_CONTROL(MSGDMA_0_CSR_BASE, ALTERA_MSGDMA_CSR_STOP_ON_ERROR_MASK & (~ALTERA_MSGDMA_CSR_STOP_DESCRIPTORS_MASK) &(~ALTERA_MSGDMA_CSR_GLOBAL_INTERRUPT_MASK)) ; // Ждём конца передачи static const alt_u32 errMask = ALTERA_MSGDMA_CSR_STOPPED_ON_ERROR_MASK | ALTERA_MSGDMA_CSR_STOPPED_ON_EARLY_TERMINATION_MASK | ALTERA_MSGDMA_CSR_STOP_STATE_MASK | ALTERA_MSGDMA_CSR_RESET_STATE_MASK; volatile alt_u32 status; do { status = IORD_ALTERA_MSGDMA_CSR_STATUS(MSGDMA_0_CSR_BASE); } while (!(status & errMask) &&(status & ALTERA_MSGDMA_CSR_BUSY_MASK)); alt_putstr("You can play with memory!\n"); /* Event loop never exits. */ while (1); return 0; }
Запускаем, ждём сообщения «You can play with memory!», ставим программу на паузу и смотрим память, начиная с адреса 0. Сначала я сильно испугался:
С адреса 0x80 счётчик резко меняет значение. Причём на очень большую величину. Но оказалось, что всё нормально. У нас же счётчик никогда не останавливается и всегда готов, а у DMA имеется собственная очередь упреждающего чтения. Напомню настройки блока DMA:
0x80 байт — это 0x20 тридцатидвухбитных слов. Как раз 32 десятичное. Всё сходится. В условиях отладки это не страшно. В боевых условиях источник будет работать более корректно (у него будет сброшена готовность). Поэтому просто игнорируем этот участок. На остальных участках счётчик считает последовательно. Покажу только фрагмент дампа по ширине. Поверьте на слово, что я осматривал его целиком.
Не доверяя глазам, я написал код, который автоматически проверяет данные:
volatile alt_u32* pData = (alt_u32*)BUFFER_BASE; volatile alt_u32 cur = pData[0x10]; int nLine = 0; for (volatile int i=0x11;i<BUFFER_SIZE_VALUE/4;i++) { if (pData[i]!=cur+1) { alt_printf("Problem at 0x%x\n",i*4); if (nLine++ > 10) { break; } } cur = pData[i]; }
Он тоже не выявляет никаких проблем.
Попытка найти хоть какие-то проблемы
На самом деле, отсутствие проблем — это не всегда хорошо. В рамках статьи, мне нужно было найти проблемы, а затем показать, как они устраняются. Ведь проблемы очевидны. Не может занятая шина пропускать данные без задержек! Задержки должны быть! Но давайте проверим, почему всё происходит так красиво. В первую очередь, может оказаться, что всё дело в FIFO блока DMA. Уменьшим их размеры до минимума:
Всё продолжает работать! Хорошо. Убедимся, что мы провоцируем число обращений к шине больше, чем размерность FIFO. Добавим счётчик обращений:
То же самое текстом:
volatile alt_u32 status; volatile int n = 0; do { status = IORD_ALTERA_MSGDMA_CSR_STATUS(MSGDMA_0_CSR_BASE); n += 1; } while (!(status & errMask) &&(status & ALTERA_MSGDMA_CSR_BUSY_MASK));
По окончании работы он равен 29. Это больше, чем 16. То есть, FIFO должно переполниться. На всякий случай, добавим побольше чтений регистра статуса. Не помогает.
С горя, я отключился от удалённого комплекса Redd, переделал проект под имеющуюся у меня макетную плату, к которой я могу прямо сейчас подключиться осциллографом (в офисе же никого — все на удалёнке, до осциллографа не дотянуться). Добавил в таймер два порта:
output clk_copy, output ready_copy
И назначил их:
assign clk_copy = clk; assign ready_copy = source_ready;
В итоге, модуль стал выглядеть так:
module Timer_ST ( input clk, input reset, input logic source_ready, output logic source_valid, output logic[31:0] source_data, output clk_copy, output ready_copy ); logic [31:0] counter; always @ (posedge clk, posedge reset) if (reset == 1) begin counter <= 0; end else begin counter <= counter + 1; end assign source_valid = 1; assign source_data [31:24] = counter [7:0]; assign source_data [23:16] = counter [15:8]; assign source_data [15:8] = counter [23:16]; assign source_data [7:0] = counter [31:24]; assign clk_copy = clk; assign ready_copy = source_ready; endmodule
Дома у меня макетка с кристаллом поменьше, так что аппетиты памяти пришлось уменьшать. И выяснилось, что моя примитивная программа не влезет в секцию, размером 4 килобайта. Так что тема, поднятая в прошлой статье — ох, как актуальна. Памяти в системе — в обрез!
При запуске программы получаем всплеск ready то ли на 16, то ли на 17 тактов. Это заполняется FIFO блока DMA. Тот самый эффект, который меня в начале напугал. Именно эти данные сформируют то самое ложное заполнение буфера.
Далее — имеем красивую картинку на 40960 наносекунд, то есть, 2048 тактов (с домашним кристаллом, буфер пришлось уменьшить до 8 килобайт, то есть, 2048 тридцатидвухбитных слов). Вот её начало:
Вот конец:
Ну, и на всём протяжении — ни одного провала. Нет, было ясно, что так будет, но была некоторая надежда…
Может, надо в шину попробовать писать, а не только читать из неё? Я добавил в систему блок GPIO:
Добавил запись в него при ожидании готовности:
То же самое текстом
volatile alt_u32 status; volatile int n = 0; do { status = IORD_ALTERA_MSGDMA_CSR_STATUS(MSGDMA_0_CSR_BASE); IOWR_ALTERA_AVALON_PIO_DATA (PIO_0_BASE,0x01); IOWR_ALTERA_AVALON_PIO_DATA (PIO_0_BASE,0x00); n += 1; } while (!(status & errMask) &&(status & ALTERA_MSGDMA_CSR_BUSY_MASK));
Вот нет проблем и всё тут! Кто же виноват?
Чудес не бывает, но бывают неисследованные вещи
Кто же виноват? С горя я начал изучать все меню инструмента Platform Designer и, кажется, нашёл разгадку. Как обычно выглядит шина? Набор проводов, к которым подключены клиенты. Так? Вроде, да. Мы же видим это из рисунков в редакторе. Как раз, вторая цель у статьи была показать, как можно разбить шину на два независимых сегмента, каждый из которых работает, не мешая другому.
Но давайте посмотрим на сообщения, которые выдаются при генерации системы. Выделю ключевые слова подсветкой:
И там много подобных сообщений: то добавлено, это добавлено. Оказывается, после редактирования ручками в систему добавляется много дополнительных вещей. Как бы поглядеть на схему, в которой это уже всё имеется? Я ещё в этом плаваю, но наиболее вероятный ответ в рамках статьи мы можем получить, выбрав вот этот пункт меню:
Открывшийся рисунок уже сам по себе впечатляет, но я не буду его приводить. А сразу выберу вот эту вкладку:
И там мы видим следующее:
Покажу покрупнее самое важное:
Шины не объединены! Они разбиты на сегменты! Обосновать не могу (возможно, меня поправят специалисты в комментариях), но похоже, что система вставила коммутаторы за нас! Именно эти коммутаторы создают изолированные сегменты шины, и основная система может работать в параллель с блоком DMA, который в это время бесконфликтно может обращаться к памяти!
Провоцируем реальные проблемы
Получив все эти знания, мы делаем вывод, что спровоцировать проблемы мы вполне можем. Это нужно для того, чтобы убедиться, что тестовая система их может создать, а значит, среда разработки действительно самостоятельно разруливает их. Будем обращаться не к абстрактным устройствам на шине, а к той же самой памяти Buffer, чтобы блок cmd_mux_005 распределял-таки шину между процессорным ядром и блоком DMA. Переписываем многострадальную функцию ожидания так:
То же самое текстом
volatile alt_u32 status; volatile int n = 0; volatile alt_u32* pBuf = (alt_u32*)BUFFER_BASE; volatile alt_u32 sum = 0; do { status = IORD_ALTERA_MSGDMA_CSR_STATUS(MSGDMA_0_CSR_BASE); sum += pBuf[n]; n += 1; } while (!(status & errMask) &&(status & ALTERA_MSGDMA_CSR_BUSY_MASK));
И наконец-то на осциллограмме появились провалы!
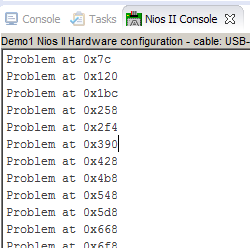
Функция проверки памяти также нашла массу пропусков:
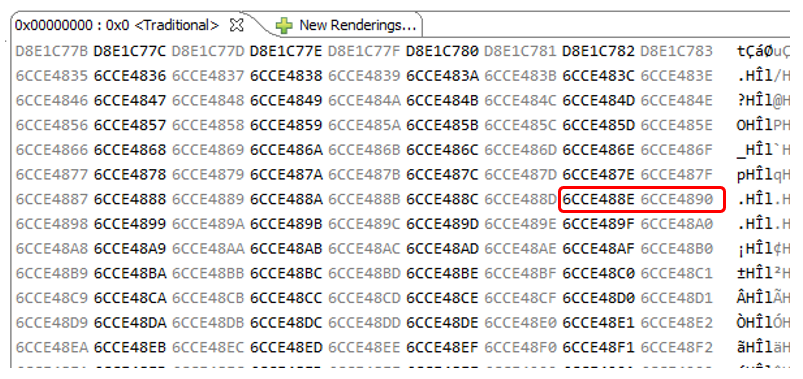
Да и на глаз мы прекрасно видим, что данные сдвинуты от строки к строке:
А вот пример конкретного сбойного места (отсутствует значение 6CCE488F):
Теперь мы видим, что эксперимент был сделан верно, просто среда разработки провела оптимизацию за нас. Это тот случай, когда фразу «Больно умные все стали» я произношу не с издёвкой, а с благодарностью. Спасибо разработчикам Квартуса за это дело!
Заключение
Мы научились вставлять в систему блок DMA для перекачки потоковых данных в память. Также мы убедились, что процессу закачки не будет мешать работа прочих устройств на шине. Среда разработки автоматически создаст изолированный сегмент, который будет работать в параллель с другими участками шины. Само собой, если кто-то обратится к этому же сегменту, коллизии и временные затраты на их разрешение неизбежны, но программист вполне может предусмотреть такие вещи.
В следующей статье мы заменим ОЗУ на контроллер SDRAM, а таймер — на реальную «голову» и сделаем первый логический анализатор. Будет ли он работать —пока не знаю. Надеюсь, проблемы не появятся.

