В предыдущей статье был описан шеститочечный метод разворачивания этикеток, поиск шести ключевых точек выполнялся при помощи преобразования Хафа. Это давало неплохие результаты для хороших этикеток, но для многих реальных случаев он работал нестабильно, несмотря на попытки его подхачить. В какой-то момент стало очевидно, что на этом зыбком фундаменте хорошую архитектуру не построить, следующая попытка — нейронные сети.
В этой статье я опишу, как мы размечали датасет и подбирали архитектуру, это было весело.

Для нейронных сетей самое главное — это датасет. Конечно, можно было попробовать сгенерировать изображения, но в таких случаях неясно насколько хорошо датасет соответствует реальным примерам, так что датасет должен хотя бы частично состоять из размеченных фотографий.
Итак, до того, как запустить первую архитектуру, нужно разметить данные, а для этого нужна система для разметки данных. На данный момент, есть куча уже готовых инструментов, но они созданы либо для задачи классификации, либо для сегментации. В нашем же случае, нужно указывать шесть точек, при этом нужна разная дополнительная визуализация — значит пишем свою.
Этап первый, «Манул» (каждый из этапов мы называли в честь разных котиков).
Цели:
Требования к системе:
Всякая статистика и разграничение доступов — пока не входит в первоначальный скоуп задач, т.к. тысячу сэмплов собираемся размечать самостоятельно.
В качестве основы для такой системы я взял фреймворк Django — у него есть админка, которая закрывает существенную часть функциональности, и его можно легко расширять под другие нужды.
Создаем модель ImageTask:
Добавляем кастомный темплейт, в нем же ссылки на всякие .js файлы:
Определяем класс ImageTaskAdmin:
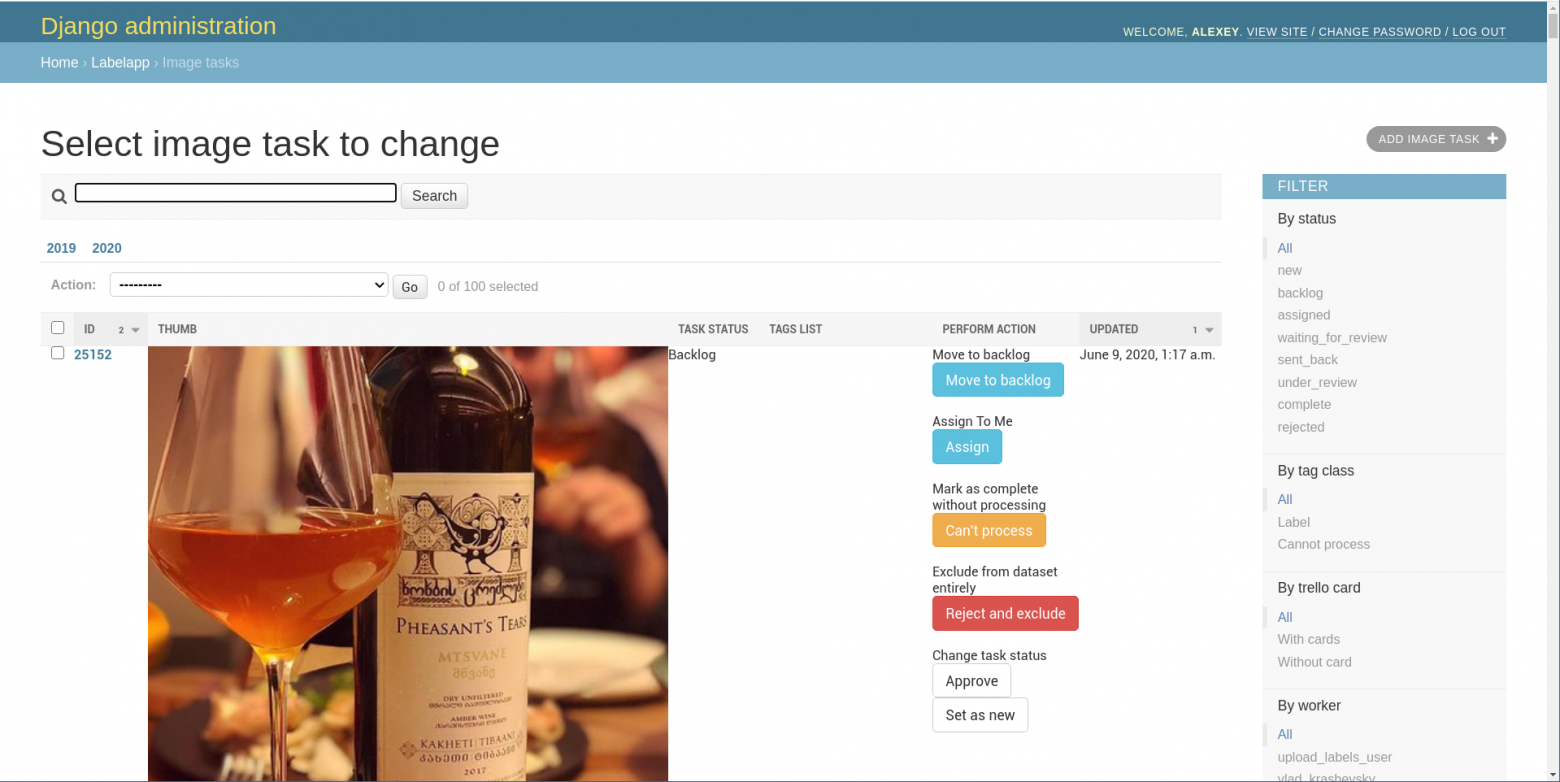
Код немного урезан для наглядности, но суть та же. Открываем в админке Image Tasks, и получаем такой бэклог:
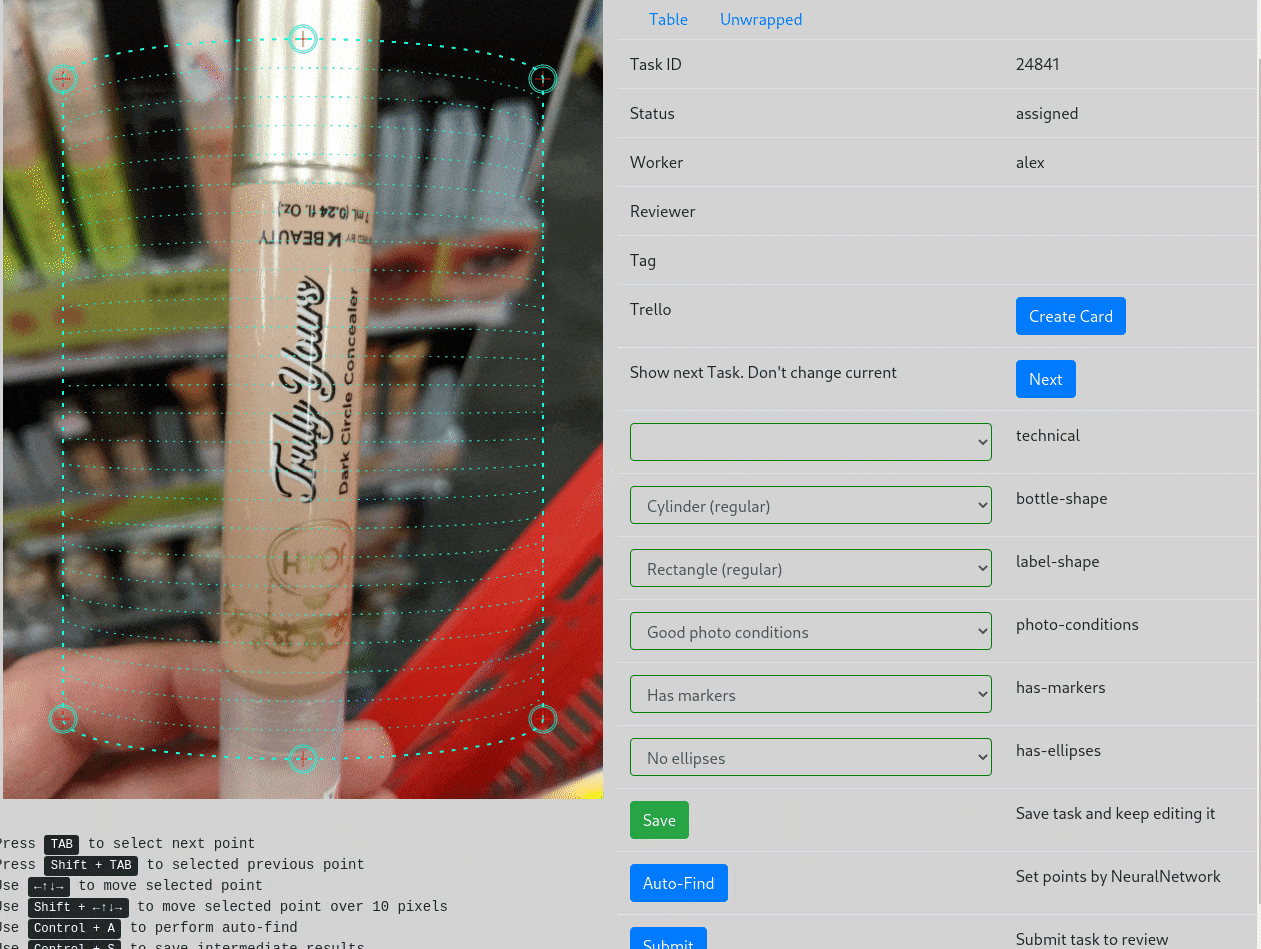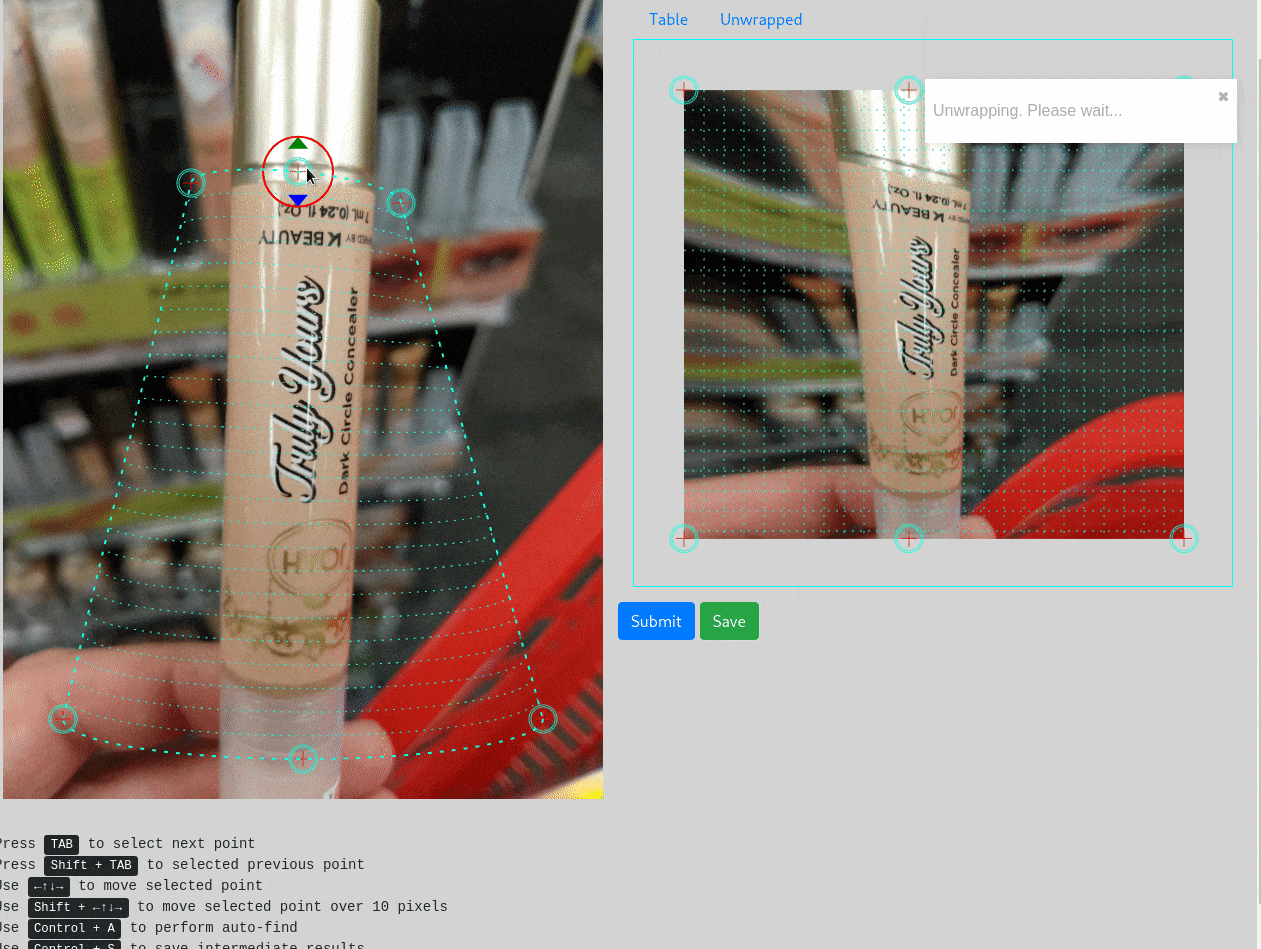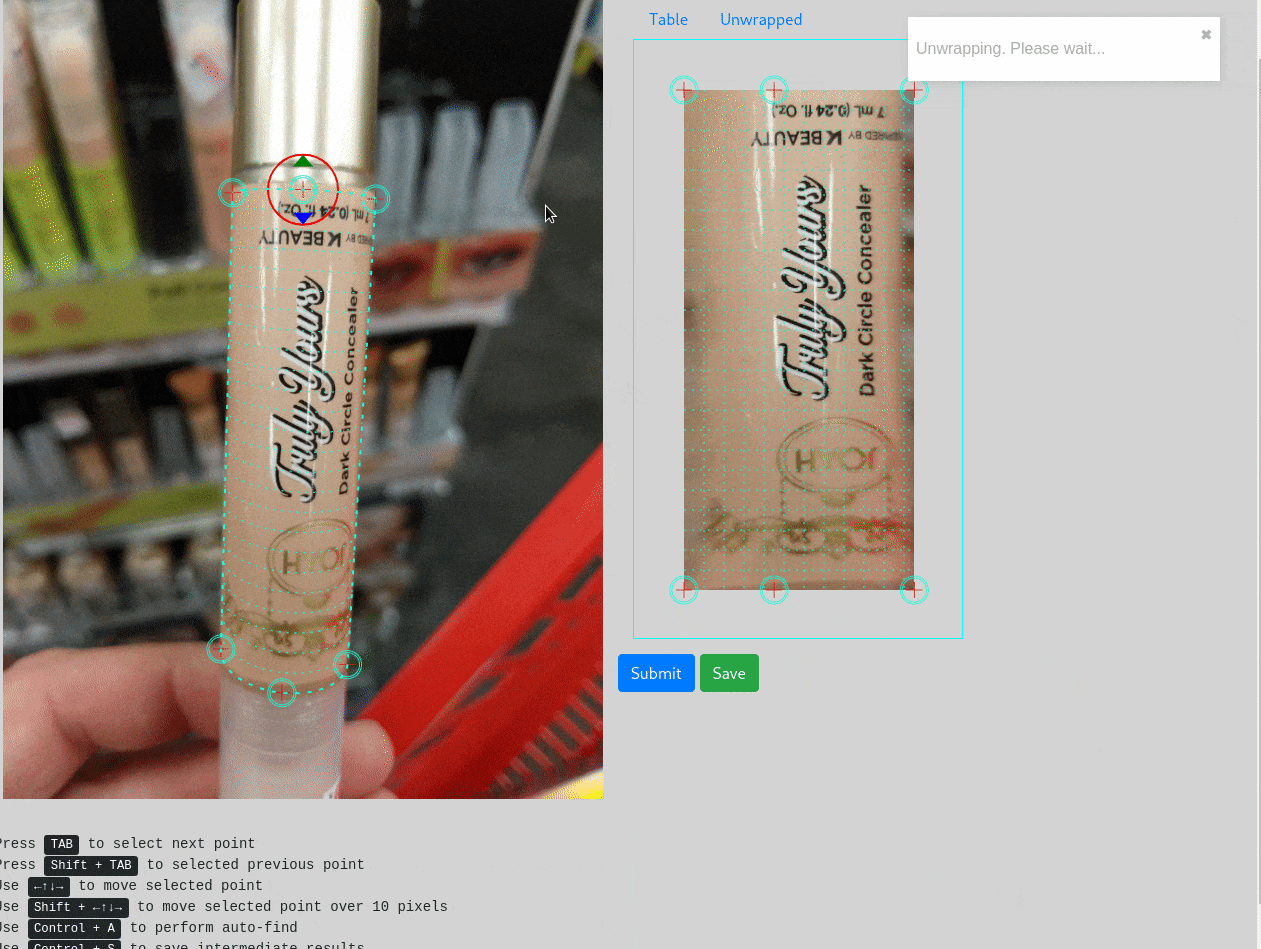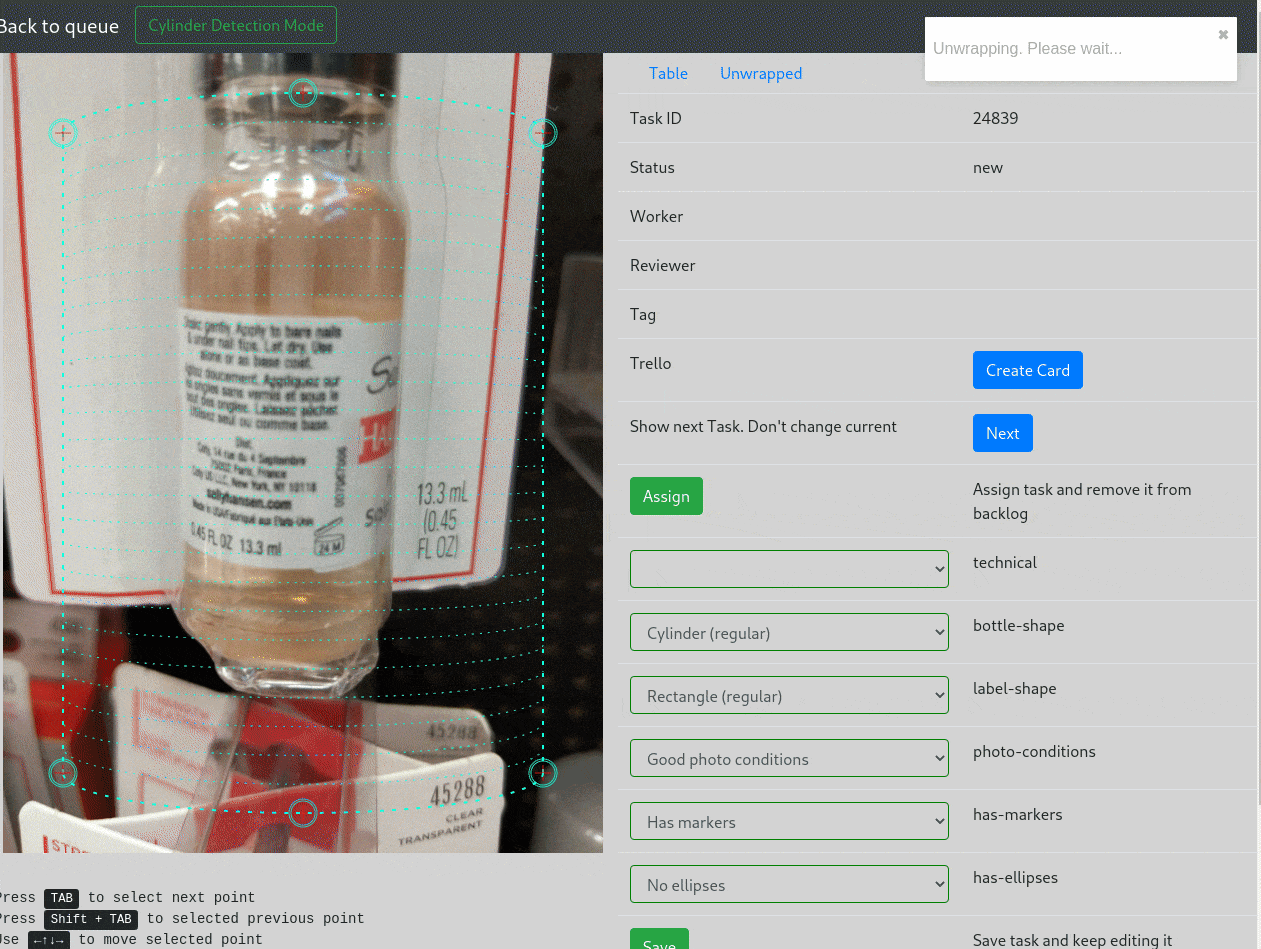
Самое интересное — это, конечно, интерфейс разметки. Последняя версия выглядит так:
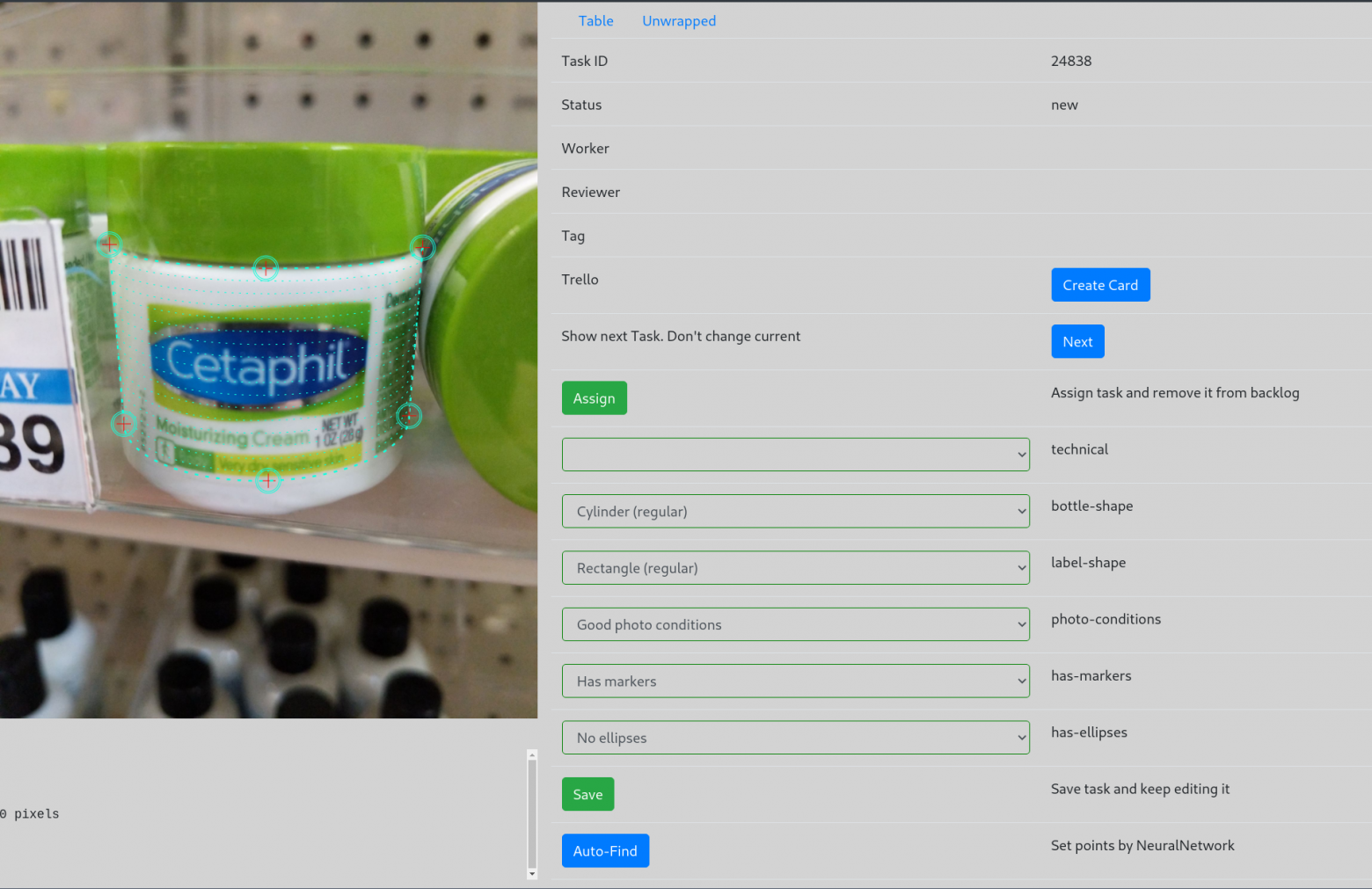
В картинке слева, кружочки можно передвигать мышкой, подстраивая сетку. Первая версия была написана при помощи Canvas + jQuery, и не было всяких тегов и кнопки Auto-Find. Написать такой интерфейс заняло где-то три дня (обожаю Django и примитивный JavaScript), и мы сразу начали размечать датасет.
Размечали самостоятельно, по трудозатратам — где-то около 30-ти человеко-часов, размазанные на пару недель.
В интерфейсе разметки, главный девиз — “действуй быстро, все поправимо”. Процесс должен быть ориентирован на скорость, нельзя добавлять никаких диалоговых окон — любое действие — через один клик. Но при этом нужно, чтобы возможные ошибки (а они неизбежны) можно было легко исправить. Вот один из примеров — загруженные картинки нужно добавлять вручную в бэклог, это делается нажатием кнопки “Move to backlog”. Но если по какой-то причине передумал, то можно вернуть статус “New”:
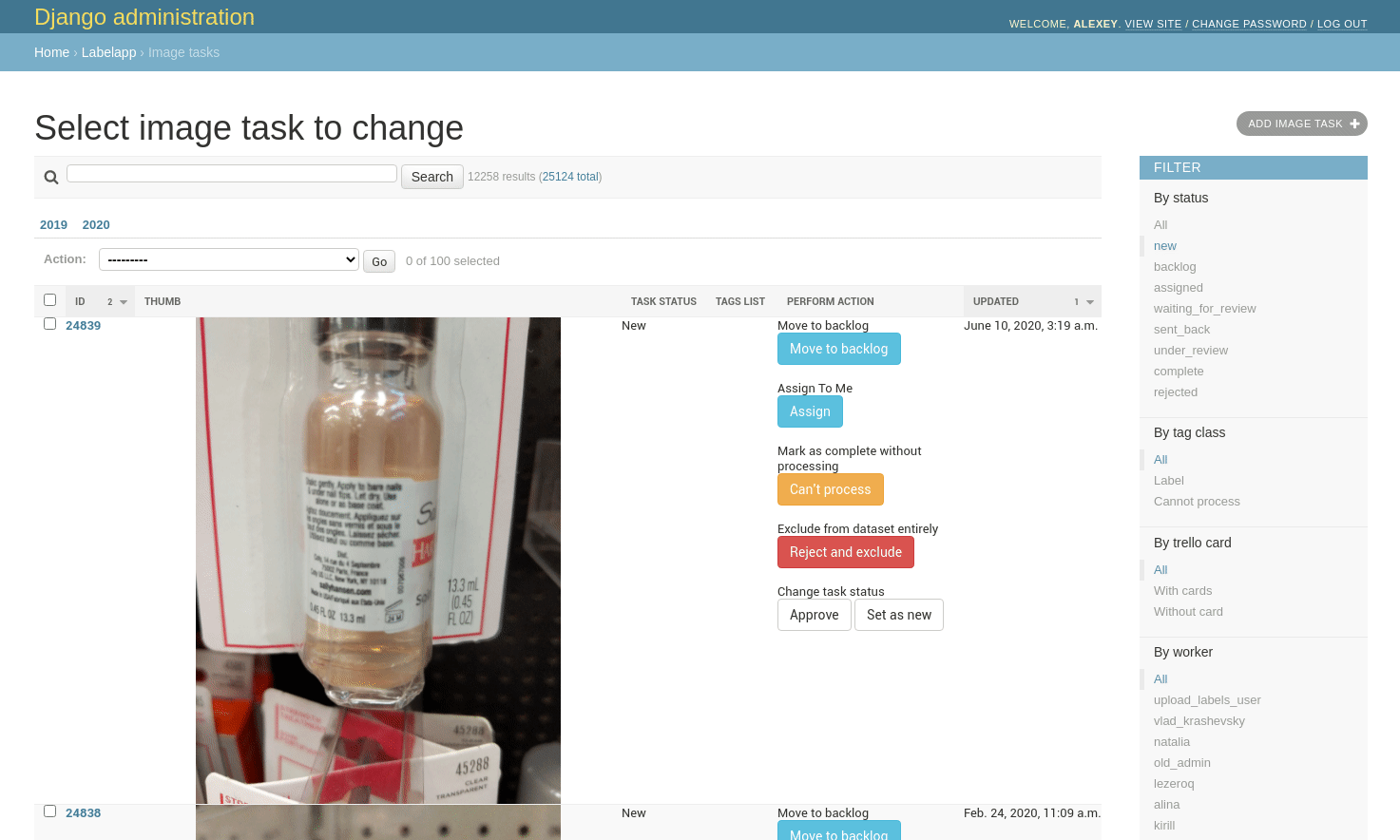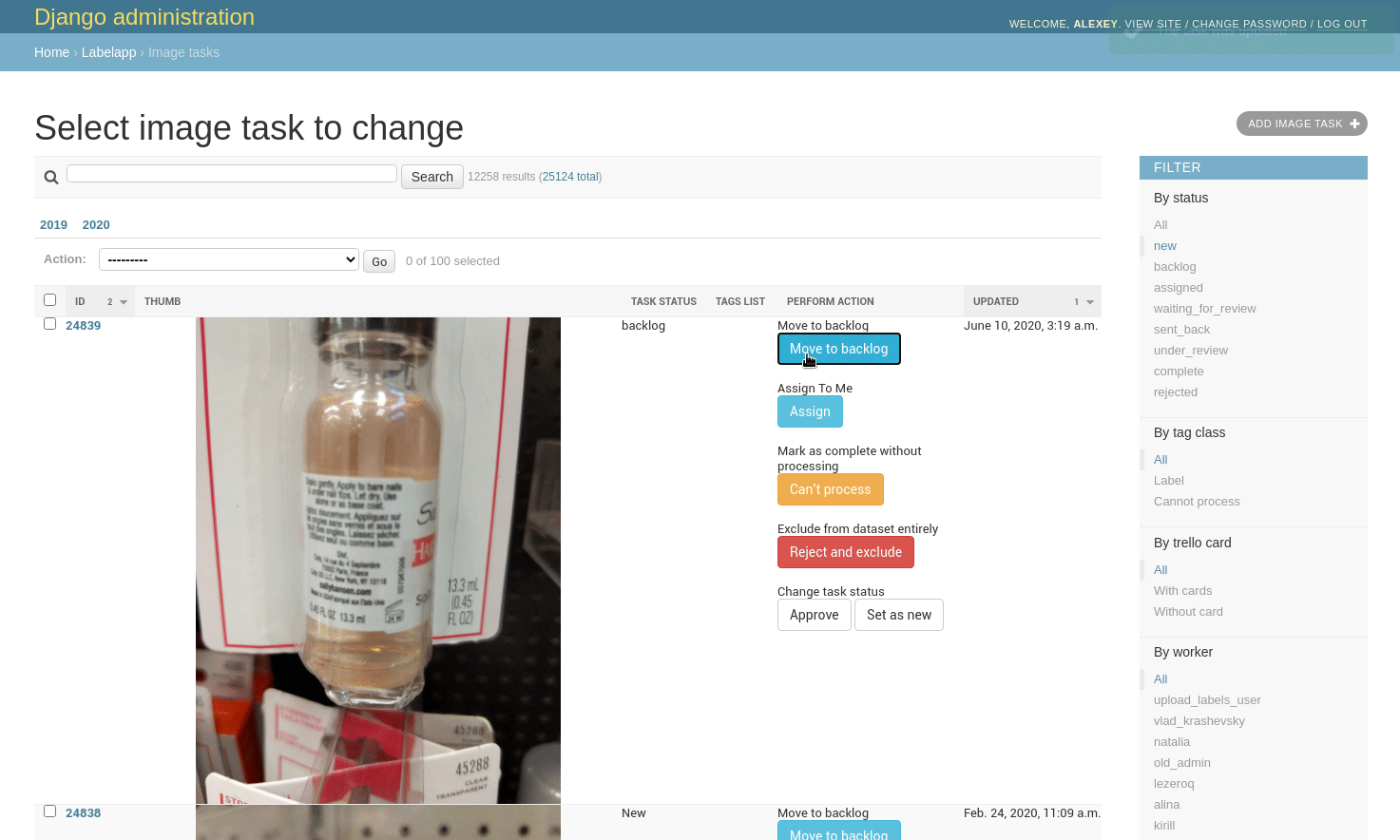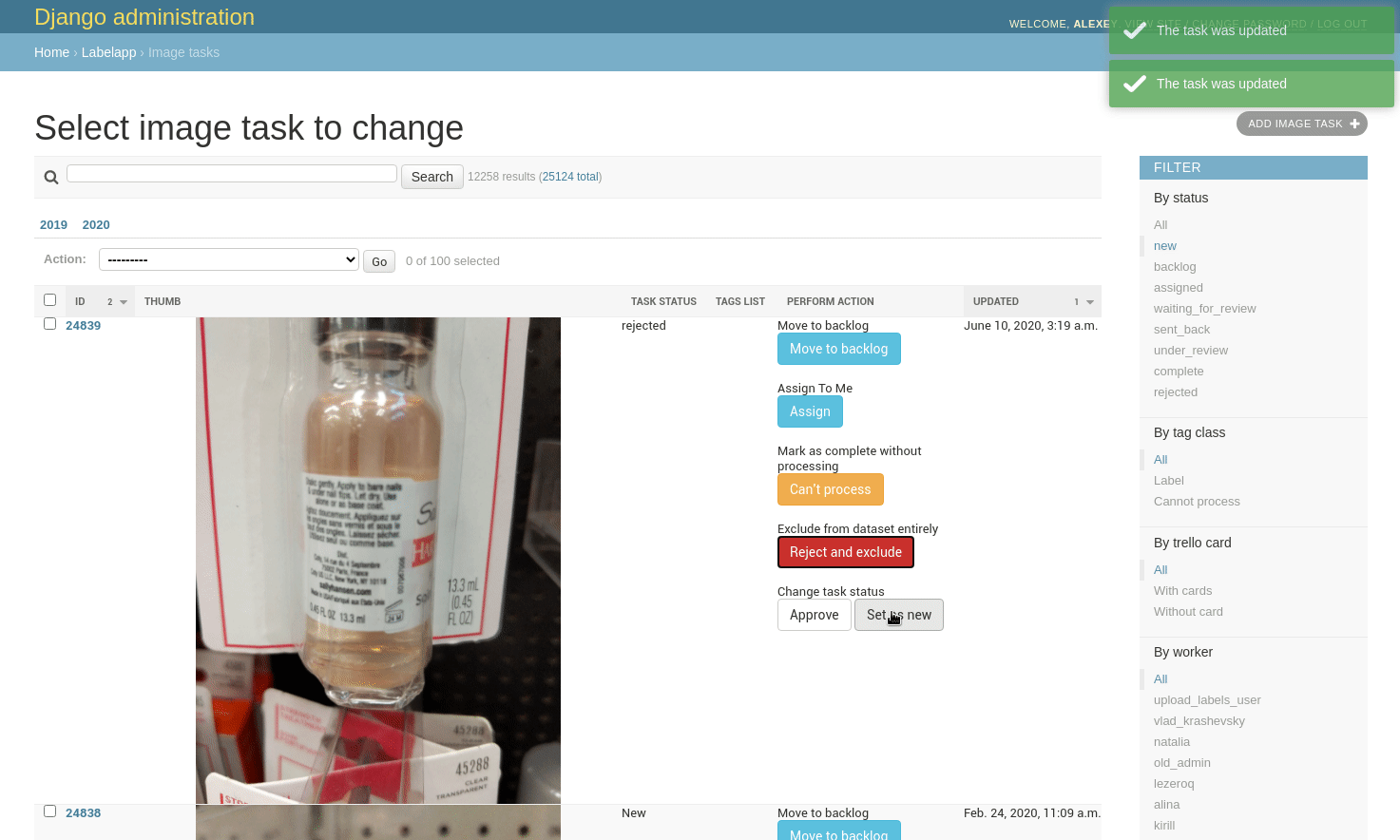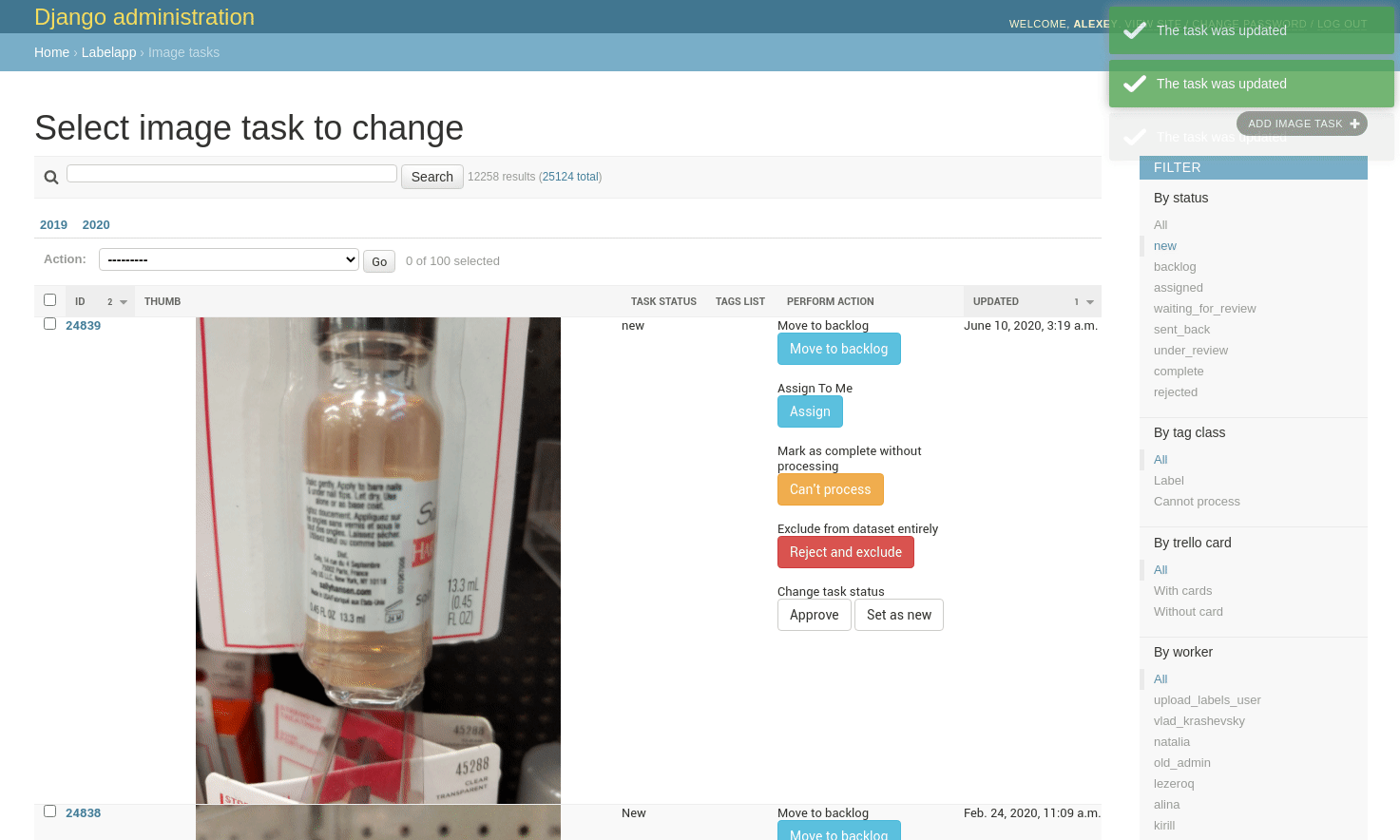
Все это — совсем не rocket science, но именно благодаря таким вещам, работа идет намного эффективнее.
Итак — первый датасет размечен, и теперь самое интересное — нейронка! Unet, тренировка — работает! Проблем хватает, но как proof of the concept — работает на ура. Значит продолжаем размечать.
Следующий этап — «Розовая пантера»:
В это время Кирилл (ответственный за инфраструктуру и все такое), решает внести некоторые изменение в интерфейс. Его лицо, когда видит мой jQuery код:

Так что первым делом переписывает страницу с маркерами на React, и добавляет предпросмотр:
За последующее время, интерфейс претерпел еще и другие изменения — добавили всякие горячие клавиши, теги классификаций, интеграцию с Trello, предварительную разметку этикетки нейронкой, но визуально интерфейс практически не изменился.
Вообще, разметка по факту оказалась довольно нетривиальной вещью — этикеток бывает много разных, и нужно как-то вырабатывать общие правила. Ну, к примеру, какой вариант из двух правильный?

Если размечать наобум, то нейронка будет путаться, и соответственно, будет падать точность.
В какой-то момент, нам пришлось переработать правила разметки, и переразметить датасет (где-то в районе 3к этикеток).
Выше я упоминал интеграцию с Trello — это для того, чтобы можно было на каждую задачу сделать тред с обсуждением, как правильно размечать:
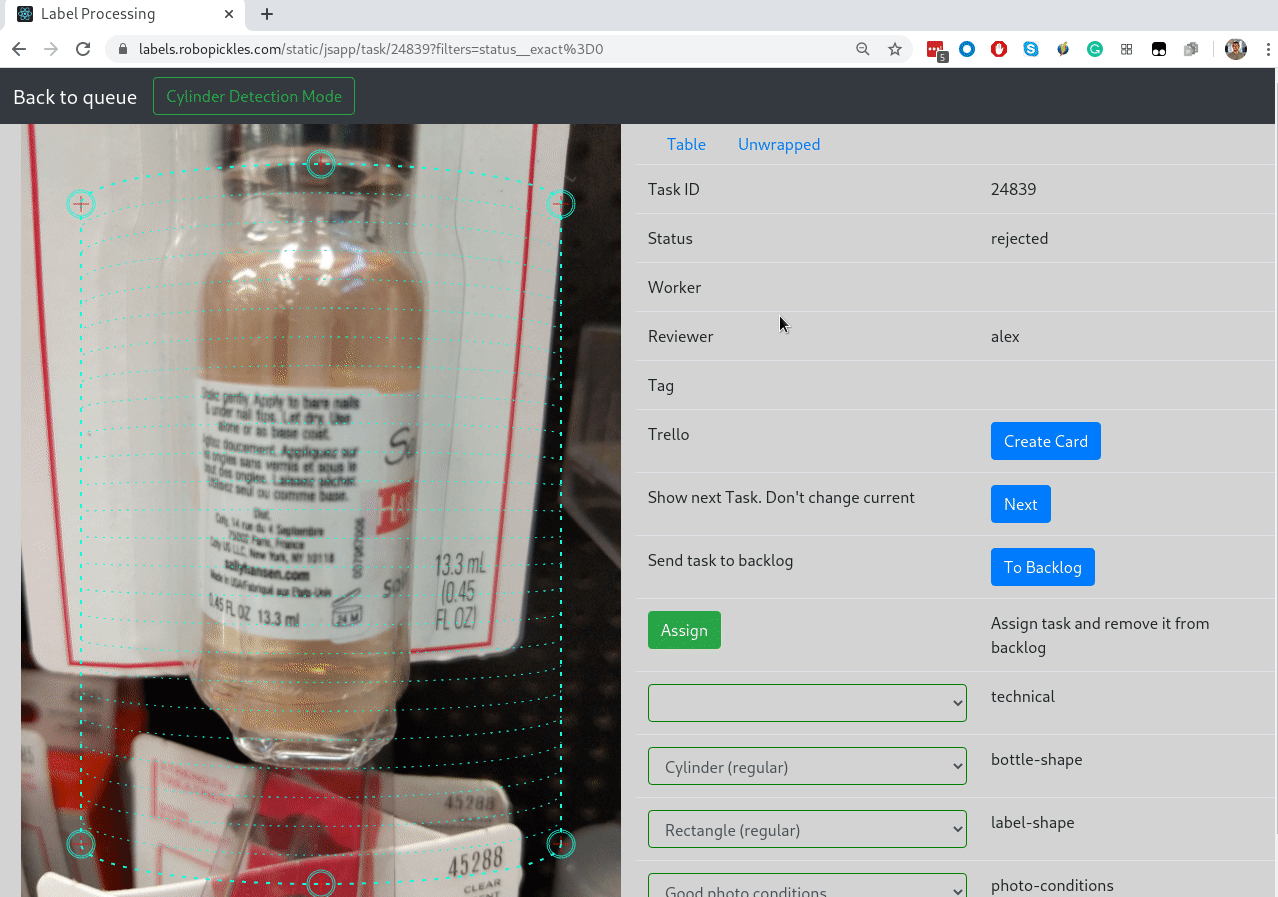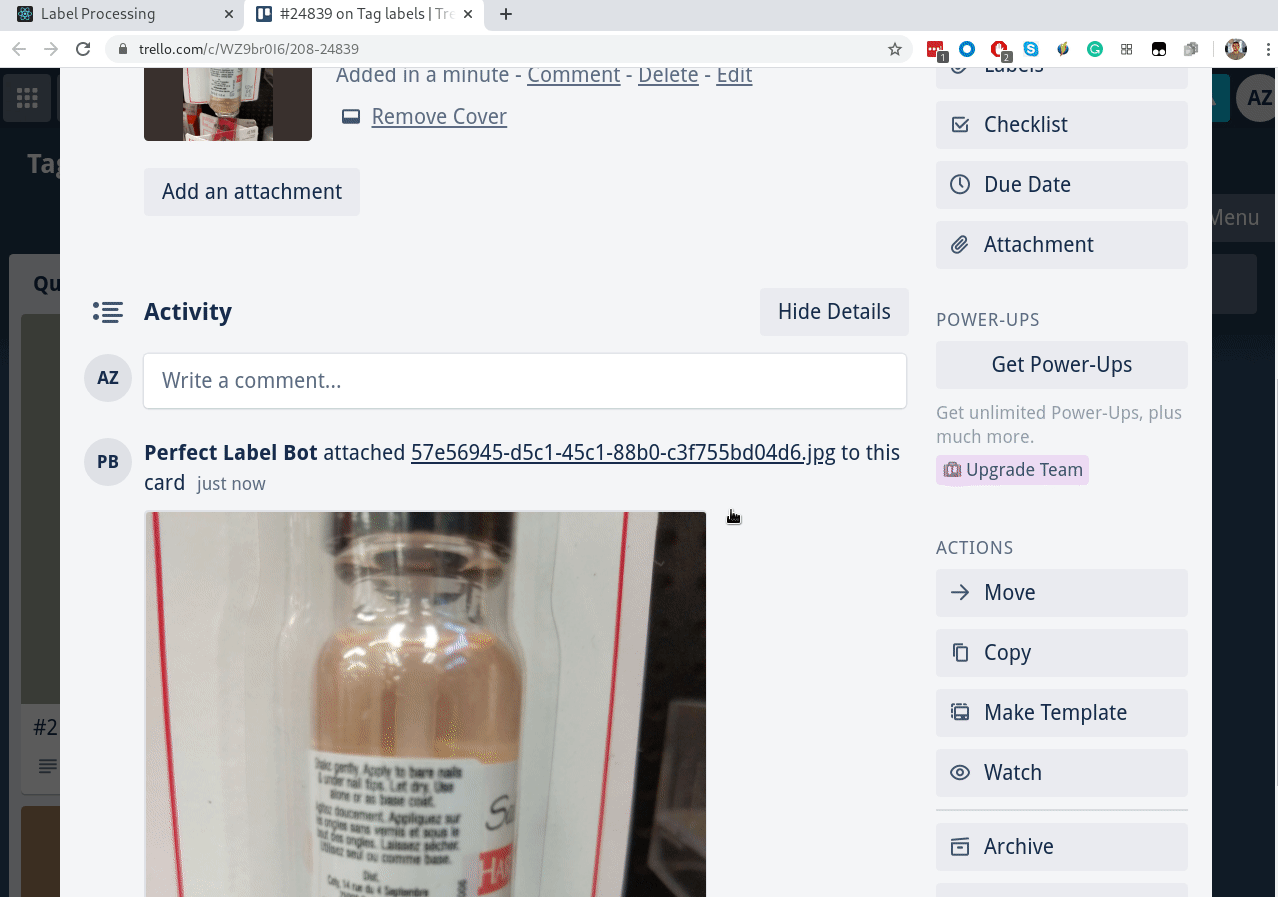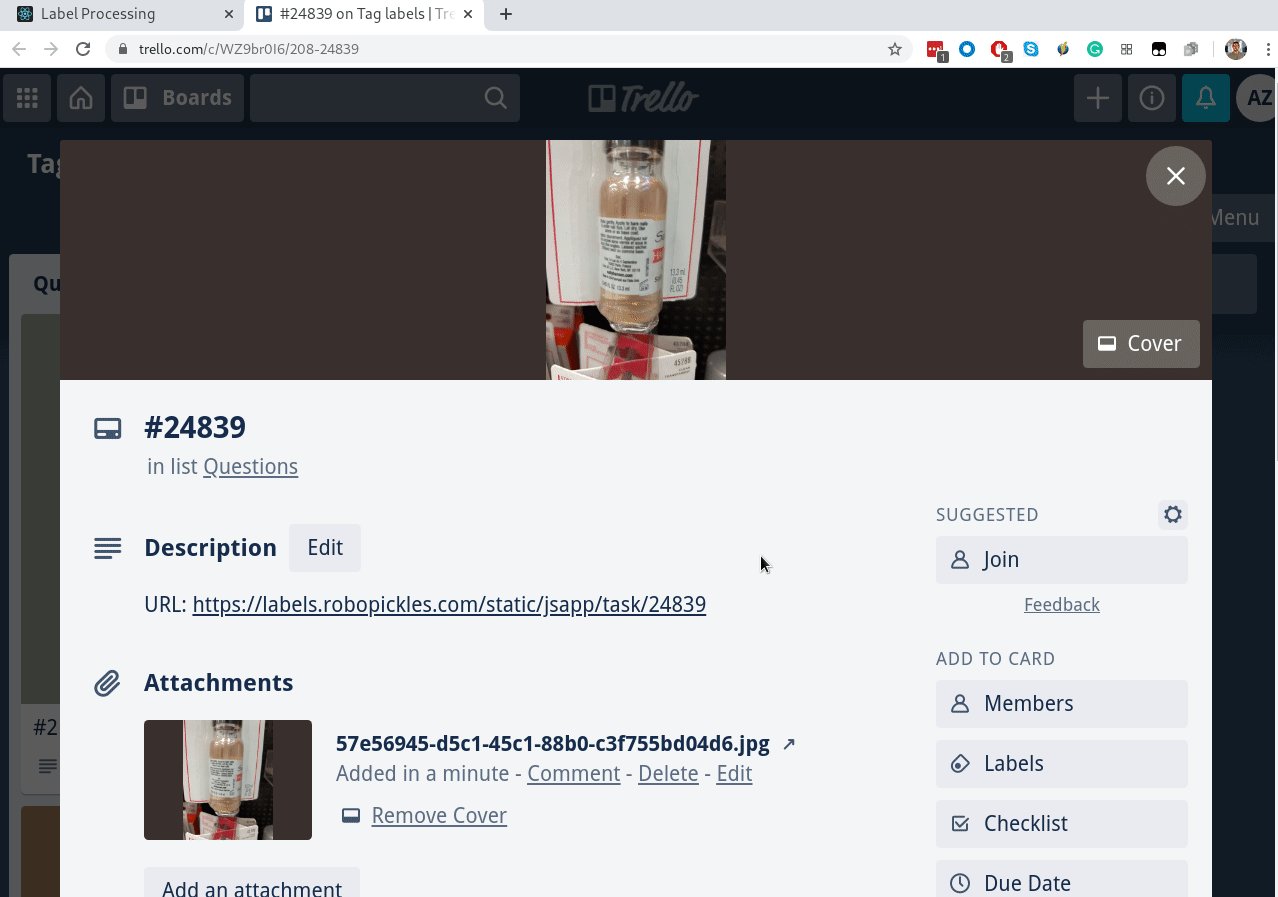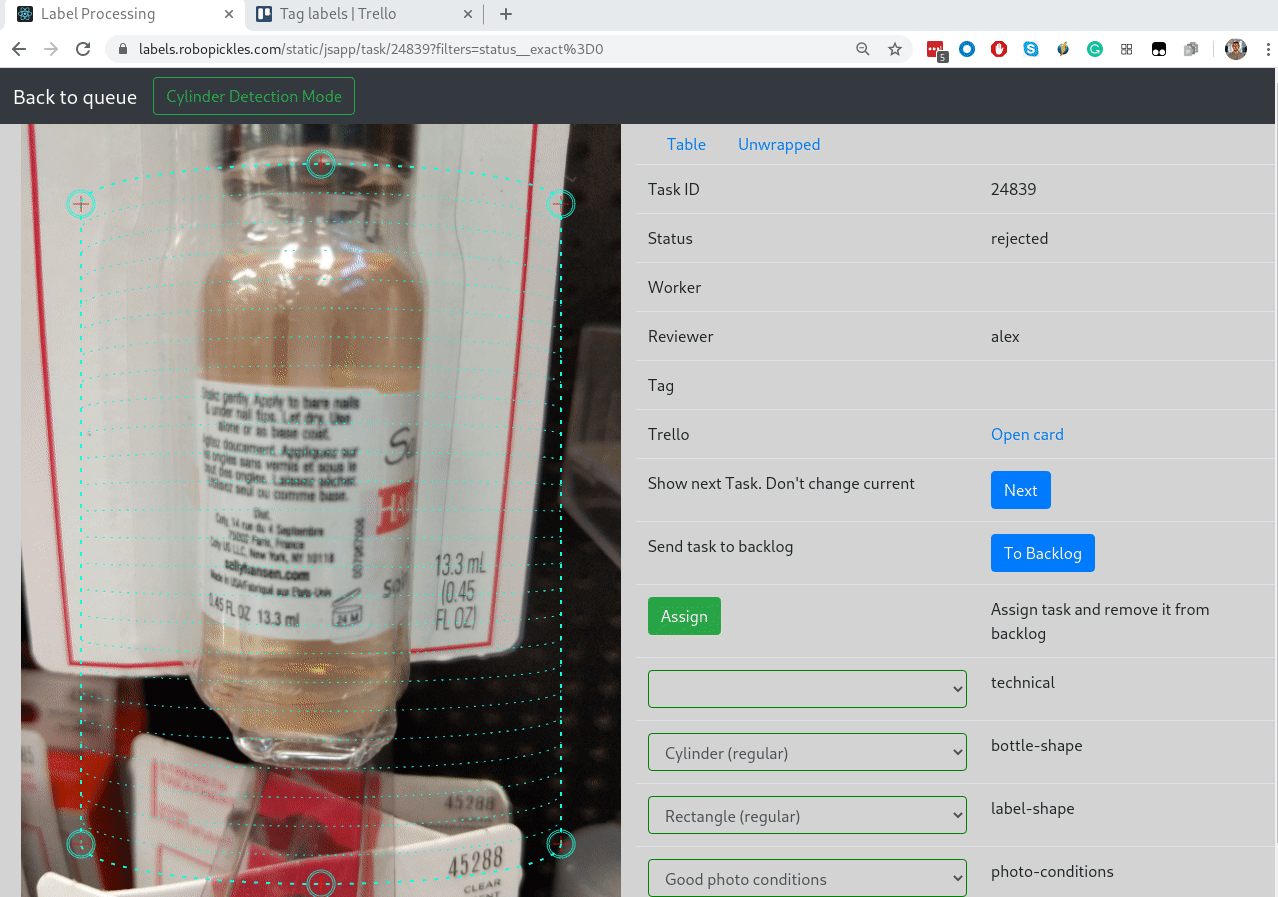
Все вопросы от воркеров попадают в колонку Questions. Ревьювер перетаскивает карточку в колонку Conversations, где идет активное обсуждение. Когда всё понятно, воркер архивирует карточку, но ссылка из интерфейса остается. Удобство такого подхода в том, что интеграция делается за полдня, не нужно писать свой чат, а Trello бесплатный, и у него нескучные обои.
Двухэтапная разметка (сначала воркером, а потом ревьювером) нужна не сколько для того, чтобы не пропустить ошибку, а скорее для того, чтобы лучше параллелить весь процесс. Один-два ревьювера хорошо разбираются в правилах разметки, они могут довольно быстро проревьювить размеченные таски. Воркеры могут не так сильно заморачиваться этими правилами — если что, ревьювер увидит косяк, и скажет как правильно переделать.
Сам состав команды по разметке состоял из волонтеров с некоторым избытком свободного времени, коими были родственники на пенсии. Но нужен, как минимум, один ответственный за контент — главный ревьювер ревьюверов. Ну и мы, разработчики системы, тоже отправлялись, так сказать, на поля. Надо сказать, на сомнительное предложение поработать бесплатно согласилось довольно много знакомых, но вполне закономерно, большинство отвалилось не разметив даже десяти штук.
Еще одна сложность в работе с данными — где брать фотографии. Даже в крупных магазинах не так много разных наименований — обычно в районе 2-3 тысяч, и они пересекаются. Т.е. после Walmart идешь в Target, а там продукты повторяются. Но не особо трудоемкий — за один заход у меня получалось сделать порядка одной тысячи снимков (это где-то за полтора часа работы). Ну и так как я просто заходил в магазин и фотографировал, без всяких там разрешений, то по началу делал это украдкой. Но потом, заметив, что на меня никто из персонала не обращает внимания, то фотографировал в открытую.
В какой-то момент я понял, что разнообразие закончилось (я живу в Нью-Джерси), и если не заказывать датасет где-нибудь в Китае или Индии, то фотографировать больше нечего.
Нетрудно догадаться, что фотографии бутылок на прилавках — это довольно однообразное окружение. Однажды обнаружилось, что нейронная сеть хорошо распознает только на таком фоне, но совершенно теряется, если там что-то другое.
Поэтому, мы пустили в ход еще один подход — онлайн скрапинг, т.е. наполнение датасета картинками из интернета.
Мы скачивали картинки на белом фоне, со всяким текстом, или с неожиданном фоном. Оказалось, что если на фотографии пива есть еще и пивной бокал, наполненный янтарным пенным, то нейронка не может как следует сосредоточиться. Так что пришлось тренировать её выдержку на дополнительной сотне примеров.
Хочу поделится одним лайфхаком для скрапинга, т.к. нужно понимать, что работа с датасетом — это очень скучно. И если вы Гугл и у вас рекапча, то скука распределяется по миллионам невинных людей, но если вы вручную наполняете датасет, то вся скука распределяется только на вас самих. Я к тому, что все этапы должны быть максимально автоматизированы. В случае со скачиванием картинок, мы запустили REST API (Django REST Framework), который принимает ссылку на картинку, скачивает ее, применяет разворачивание, и визуализирует очередь.
На клиентской стороне используется программа copyq hluk.github.io/CopyQ
Она кроссплатформенная, висит себе в трее, и выполняет действие при нажатии на комбинацию клавиш. Конфигурация в моем случае выглядит так:
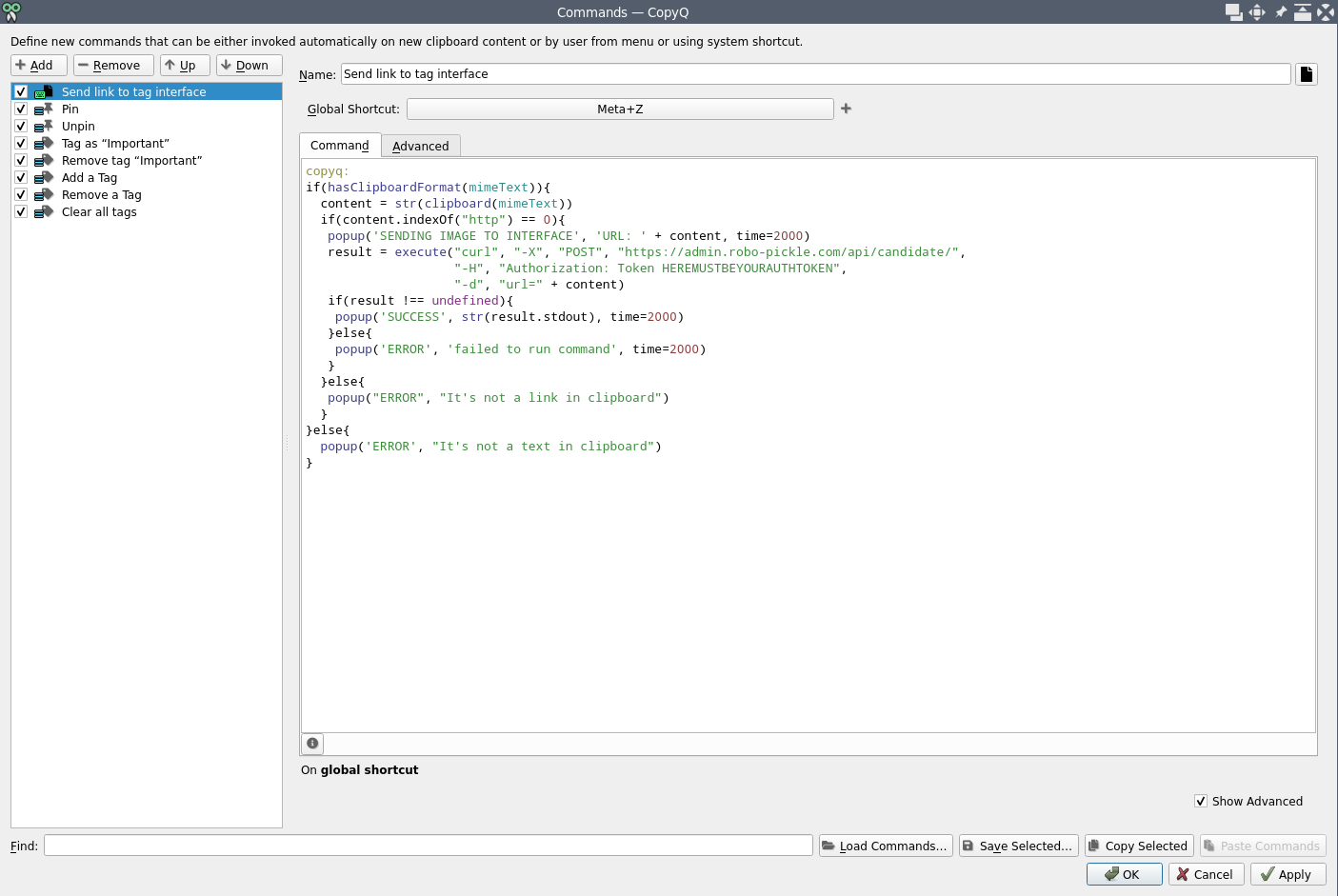
Принцип работы такой — открываешь поисковик, ищешь подходящие картинки, и если таковая найдена, то копируешь ссылку, и нажимаешь горячую клавишу (в моем случае, это Win+Z):

CopyQ отправляет ссылку, пополняя очередь ожидания, а когда в ней набирается, скажем, 100 этикеток, то переключаешься на сайт, и начинаешь добавлять в датасет самые кривые:
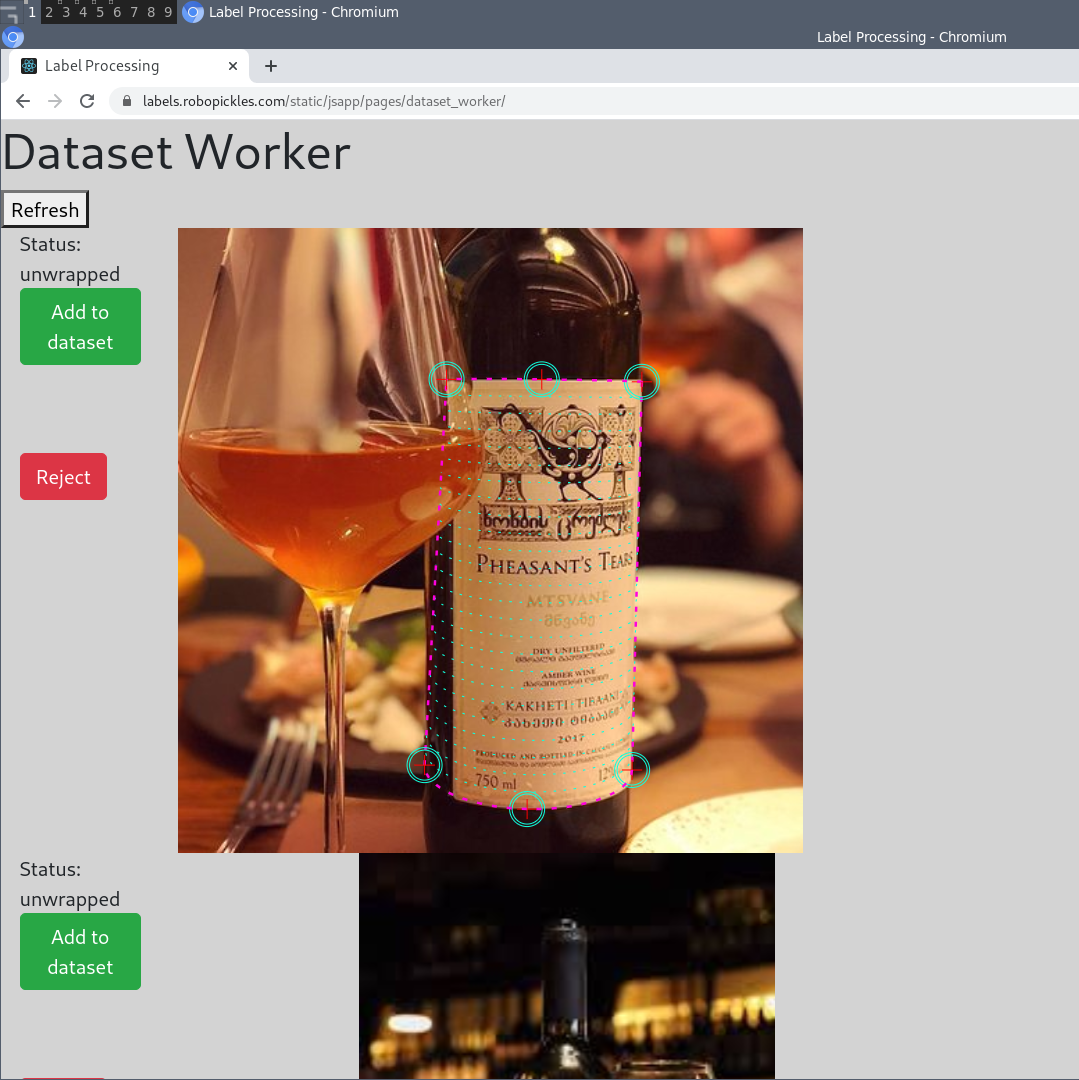
Те, которые уже распознаются хорошо, добавлять в датасет смысла нет, но на примере выше (а это случайный пример из интернета), левая верхняя точка выставлена не по бутылке, а по этикетке. Кликаем на “Add to dataset”, и фотография добавляется в бэклог для обработки.
Таким образом, где-то за три месяца мы разметили датасет из 10 тысяч этикеток. Это выглядит не сильно много, но зато он очень хорошо сбалансирован. На самом деле, большой датасет — это не всегда хорошо, т.к. его намного сложнее балансировать, т.е. набирать примеры в одинаковых пропорциях.
Если этого не сделать, то может так получиться, что нейронке проще проигнорировать примеры, чем генерализировать алгоритм. К примеру, у нас есть 1млн этикеток в датасете, и все они — при хорошей освещенности. Вдруг оказывается, что 15% реальных фотографий делаются при плохой освещенности, и на этих примерах у нейронки срывает крышу. Теперь нам нужно добавить в датасет и такие примеры, но если датасет очень большой, то придется добавлять тысячи фотографий, прежде чем их влияние начнет работать. Это прямо, как бюрократическая система, которая ориентирована на средние показатели, и игнорирует отдельно взятые случаи. По сути, нейронная сеть уходит в состояние локального минимума, барьер которого она не может преодолеть, т.к. оптимизация малочисленных примеров временно ухудшает средний показатель.
Но на 10к примерах нейронной сети проще их запомнить, чем генерализовать алгоритм, поэтому нужна аугментация.
Есть отличные библиотеки — imgaug или albumentation, которыми можно модифицировать картинки разными способами — поворачивать, отражать, добавлять размытие или менять цветовой баланс. Тут главное не переборщить, чтобы изображение оставалось читаемым, к примеру, если применить размытие вместе с изменением яркости, то границы бутылок могут визуально поехать в стороны, не говоря уже о том, что сильные изменения яркости/контраста могут вообще сделать изображение нечитаемым.
Итак, датасет есть. Он сбалансирован и, благодаря аугментациям, достаточно разнообразен, чтобы нейронка не переучивалась. Остается вопрос — какую использовать архитектуру? Нужно ли придумывать свою, или есть универсальные нейронные сети? На самом деле, заранее это неизвестно, но что точно можно сказать — это то, что придется проверить целую кучу разных архитектур, попробовать те, или иные параметры запуска или настройки. Так что любой machine learning проект стоит строить вокруг этой идеи. Если новая архитектура будет подключаться 3 недели, то это плохие новости. В идеале, пайплайн должен быть таким, чтобы закидывая конфигурационный файл, и пару классов-адаптеров для преобразования входных/выходных форматов, подключало новую архитектуру.
Proof of the concept был написан, конечно, без таких требований, но как только он заработал, то следующим шагом было настроить такой пайплайн. Кирилл написал его, взяв за основу Keras, но Сергей, наш заклинатель искусственных интеллектов, поюзав его некоторое время, решил, что торчом жечь удобнее, и запилил свой с блэкджеком и PyTorch.
С миграцией, правда, мы накосячили. У нас была рабочая архитектура, которая сразу заработала на новом коде, когда мы загрузили существующую модель. Но натренировать ее с нуля уже не получалось — что-то было сломано. Проблема была в том, что помимо архитектуры, поменяли параметры аугментации. Вроде бы по чуть-чуть, но много разных изменений, и неясно, что же стало причиной. Пришлось подгонять настройки аугментации один к одному, чтобы понять, что причина не в ней. Так что урок номер один — не выкатывать сразу несколько изменений.
Ошибка номер два — визуализировали аугментацию до предпоследнего шага, а впоследствии оказалось, что проблема была на последнем — данные неправильно нормализировались, и на вход подавалась выжженная картинка. Так что урок второй — если что-то идет не так — лучше сразу визуализировать, и даже если все так — визуализируйте просто на всякий случай.
Все, что натренировали, запустили на выделенном сервере в виде REST API, и сразу начали использовать для предварительной разметки, как указывалось выше.
В DRF есть удобная штука — аутентификация через токен www.django-rest-framework.org/api-guide/authentication/#tokenauthentication. Токен создается для пользователя через админку:
И в дальнейшем, чтобы получить доступ к API, нужно передать токен в заголовке запроса.
Закончу, пожалуй, статью на полуслове, а вскоре ожидайте следующие статьи:
В этой статье я опишу, как мы размечали датасет и подбирали архитектуру, это было весело.
Для нейронных сетей самое главное — это датасет. Конечно, можно было попробовать сгенерировать изображения, но в таких случаях неясно насколько хорошо датасет соответствует реальным примерам, так что датасет должен хотя бы частично состоять из размеченных фотографий.
Итак, до того, как запустить первую архитектуру, нужно разметить данные, а для этого нужна система для разметки данных. На данный момент, есть куча уже готовых инструментов, но они созданы либо для задачи классификации, либо для сегментации. В нашем же случае, нужно указывать шесть точек, при этом нужна разная дополнительная визуализация — значит пишем свою.
Этап первый, «Манул» (каждый из этапов мы называли в честь разных котиков).
Цели:
- Написание на коленке системы для разметки
- Разметка тысячи сэмплов
- Запуск нейронки, чтобы проверить жизнеспособность идеи
Требования к системе:
- Возможность разметки онлайн распределенной командой
- Бэклог задач разметки
- Два этапа — сама обработка и проверка
- Фиксированные ссылки на каждую задачу
- Визуализация
Всякая статистика и разграничение доступов — пока не входит в первоначальный скоуп задач, т.к. тысячу сэмплов собираемся размечать самостоятельно.
В качестве основы для такой системы я взял фреймворк Django — у него есть админка, которая закрывает существенную часть функциональности, и его можно легко расширять под другие нужды.
Создаем модель ImageTask:
Скрытый текст
class ImageTask(models.Model): orig_image = models.OneToOneField( Image, blank=True, null=True, on_delete=models.CASCADE, related_name='+', ) status = models.IntegerField(choices=get_enum_choices(TaskStatus)) type = models.IntegerField( choices=get_enum_choices(TaskType), default=TaskType.detect_marker.value ) worker = models.ForeignKey( User, null=True, blank=True, on_delete=models.SET_NULL, related_name='workers' ) reviewer = models.ForeignKey( User, null=True, blank=True, on_delete=models.SET_NULL, related_name='reviewers' ) data = JSONField(blank=True, default=dict) created = models.DateTimeField(auto_now_add=True) updated = models.DateTimeField(auto_now=True) def clickable_preview(self): url = '' if self.orig_image: url = self.orig_image.full_url task_url = f'/static/jsapp/task/{self.id}' tag = f""" <a href="{task_url}" target="_blank"> <img src="{url}" height="100" width="100" object-fit: "scale-down"> </a> """ return mark_safe(tag)
Добавляем кастомный темплейт, в нем же ссылки на всякие .js файлы:
Скрытый текст
{# templates/admin/labelapp/imagetask/change_list.html #} {% extends "admin/change_list.html" %} {% load bootstrap3 %} {% block extrastyle %} {{ block.super }} <link rel="stylesheet" type="text/css" href="/static/css/imagetask_admin_changel\ ist.css" /> <link rel="stylesheet" type="text/css" href="/static/css/toastr.min.css" /> {% endblock extrastyle %} {% block extrahead %} {{ block.super }} {% bootstrap_css %} <script> var csrftoken = '{{ csrf_token }}'; </script> <script type="text/javascript" src="/static/js/jquery-3.3.1.min.js"></script> <script type="text/javascript" src="/static/js/toastr.min.js"></script> <script type="text/javascript" src="/static/js/const.js"></script> <script type="text/javascript" src="/static/js/imagetask_admin_changelist.js"></\ script> {% endblock extrahead %}
Определяем класс ImageTaskAdmin:
Скрытый текст
@admin.register(ImageTask) class ImageTaskAdmin(admin.ModelAdmin): list_display = ['id', 'thumb', 'task_status', 'tags_list', 'perform_action', "updated"] list_filter = [ "status", TrelloCardFilter, "worker", "reviewer" ] readonly_fields = ['orig_image', 'processed_image'] ordering = ["-updated", '-id'] list_select_related = ['orig_image']
Код немного урезан для наглядности, но суть та же. Открываем в админке Image Tasks, и получаем такой бэклог:
Самое интересное — это, конечно, интерфейс разметки. Последняя версия выглядит так:
В картинке слева, кружочки можно передвигать мышкой, подстраивая сетку. Первая версия была написана при помощи Canvas + jQuery, и не было всяких тегов и кнопки Auto-Find. Написать такой интерфейс заняло где-то три дня (обожаю Django и примитивный JavaScript), и мы сразу начали размечать датасет.
Размечали самостоятельно, по трудозатратам — где-то около 30-ти человеко-часов, размазанные на пару недель.
В интерфейсе разметки, главный девиз — “действуй быстро, все поправимо”. Процесс должен быть ориентирован на скорость, нельзя добавлять никаких диалоговых окон — любое действие — через один клик. Но при этом нужно, чтобы возможные ошибки (а они неизбежны) можно было легко исправить. Вот один из примеров — загруженные картинки нужно добавлять вручную в бэклог, это делается нажатием кнопки “Move to backlog”. Но если по какой-то причине передумал, то можно вернуть статус “New”:
Все это — совсем не rocket science, но именно благодаря таким вещам, работа идет намного эффективнее.
Итак — первый датасет размечен, и теперь самое интересное — нейронка! Unet, тренировка — работает! Проблем хватает, но как proof of the concept — работает на ура. Значит продолжаем размечать.
Следующий этап — «Розовая пантера»:
- Создание рабочего датасета
- Выбор оптимальной архитектуры
- Запуск REST API
- Склеивание этикеток
В это время Кирилл (ответственный за инфраструктуру и все такое), решает внести некоторые изменение в интерфейс. Его лицо, когда видит мой jQuery код:
Так что первым делом переписывает страницу с маркерами на React, и добавляет предпросмотр:
За последующее время, интерфейс претерпел еще и другие изменения — добавили всякие горячие клавиши, теги классификаций, интеграцию с Trello, предварительную разметку этикетки нейронкой, но визуально интерфейс практически не изменился.
Вообще, разметка по факту оказалась довольно нетривиальной вещью — этикеток бывает много разных, и нужно как-то вырабатывать общие правила. Ну, к примеру, какой вариант из двух правильный?
Если размечать наобум, то нейронка будет путаться, и соответственно, будет падать точность.
В какой-то момент, нам пришлось переработать правила разметки, и переразметить датасет (где-то в районе 3к этикеток).
Выше я упоминал интеграцию с Trello — это для того, чтобы можно было на каждую задачу сделать тред с обсуждением, как правильно размечать:
Все вопросы от воркеров попадают в колонку Questions. Ревьювер перетаскивает карточку в колонку Conversations, где идет активное обсуждение. Когда всё понятно, воркер архивирует карточку, но ссылка из интерфейса остается. Удобство такого подхода в том, что интеграция делается за полдня, не нужно писать свой чат, а Trello бесплатный, и у него нескучные обои.
Двухэтапная разметка (сначала воркером, а потом ревьювером) нужна не сколько для того, чтобы не пропустить ошибку, а скорее для того, чтобы лучше параллелить весь процесс. Один-два ревьювера хорошо разбираются в правилах разметки, они могут довольно быстро проревьювить размеченные таски. Воркеры могут не так сильно заморачиваться этими правилами — если что, ревьювер увидит косяк, и скажет как правильно переделать.
Сам состав команды по разметке состоял из волонтеров с некоторым избытком свободного времени, коими были родственники на пенсии. Но нужен, как минимум, один ответственный за контент — главный ревьювер ревьюверов. Ну и мы, разработчики системы, тоже отправлялись, так сказать, на поля. Надо сказать, на сомнительное предложение поработать бесплатно согласилось довольно много знакомых, но вполне закономерно, большинство отвалилось не разметив даже десяти штук.
Еще одна сложность в работе с данными — где брать фотографии. Даже в крупных магазинах не так много разных наименований — обычно в районе 2-3 тысяч, и они пересекаются. Т.е. после Walmart идешь в Target, а там продукты повторяются. Но не особо трудоемкий — за один заход у меня получалось сделать порядка одной тысячи снимков (это где-то за полтора часа работы). Ну и так как я просто заходил в магазин и фотографировал, без всяких там разрешений, то по началу делал это украдкой. Но потом, заметив, что на меня никто из персонала не обращает внимания, то фотографировал в открытую.
В какой-то момент я понял, что разнообразие закончилось (я живу в Нью-Джерси), и если не заказывать датасет где-нибудь в Китае или Индии, то фотографировать больше нечего.
Нетрудно догадаться, что фотографии бутылок на прилавках — это довольно однообразное окружение. Однажды обнаружилось, что нейронная сеть хорошо распознает только на таком фоне, но совершенно теряется, если там что-то другое.
Поэтому, мы пустили в ход еще один подход — онлайн скрапинг, т.е. наполнение датасета картинками из интернета.
Мы скачивали картинки на белом фоне, со всяким текстом, или с неожиданном фоном. Оказалось, что если на фотографии пива есть еще и пивной бокал, наполненный янтарным пенным, то нейронка не может как следует сосредоточиться. Так что пришлось тренировать её выдержку на дополнительной сотне примеров.
Хочу поделится одним лайфхаком для скрапинга, т.к. нужно понимать, что работа с датасетом — это очень скучно. И если вы Гугл и у вас рекапча, то скука распределяется по миллионам невинных людей, но если вы вручную наполняете датасет, то вся скука распределяется только на вас самих. Я к тому, что все этапы должны быть максимально автоматизированы. В случае со скачиванием картинок, мы запустили REST API (Django REST Framework), который принимает ссылку на картинку, скачивает ее, применяет разворачивание, и визуализирует очередь.
На клиентской стороне используется программа copyq hluk.github.io/CopyQ
Она кроссплатформенная, висит себе в трее, и выполняет действие при нажатии на комбинацию клавиш. Конфигурация в моем случае выглядит так:
Принцип работы такой — открываешь поисковик, ищешь подходящие картинки, и если таковая найдена, то копируешь ссылку, и нажимаешь горячую клавишу (в моем случае, это Win+Z):
CopyQ отправляет ссылку, пополняя очередь ожидания, а когда в ней набирается, скажем, 100 этикеток, то переключаешься на сайт, и начинаешь добавлять в датасет самые кривые:
Те, которые уже распознаются хорошо, добавлять в датасет смысла нет, но на примере выше (а это случайный пример из интернета), левая верхняя точка выставлена не по бутылке, а по этикетке. Кликаем на “Add to dataset”, и фотография добавляется в бэклог для обработки.
Таким образом, где-то за три месяца мы разметили датасет из 10 тысяч этикеток. Это выглядит не сильно много, но зато он очень хорошо сбалансирован. На самом деле, большой датасет — это не всегда хорошо, т.к. его намного сложнее балансировать, т.е. набирать примеры в одинаковых пропорциях.
Если этого не сделать, то может так получиться, что нейронке проще проигнорировать примеры, чем генерализировать алгоритм. К примеру, у нас есть 1млн этикеток в датасете, и все они — при хорошей освещенности. Вдруг оказывается, что 15% реальных фотографий делаются при плохой освещенности, и на этих примерах у нейронки срывает крышу. Теперь нам нужно добавить в датасет и такие примеры, но если датасет очень большой, то придется добавлять тысячи фотографий, прежде чем их влияние начнет работать. Это прямо, как бюрократическая система, которая ориентирована на средние показатели, и игнорирует отдельно взятые случаи. По сути, нейронная сеть уходит в состояние локального минимума, барьер которого она не может преодолеть, т.к. оптимизация малочисленных примеров временно ухудшает средний показатель.
Но на 10к примерах нейронной сети проще их запомнить, чем генерализовать алгоритм, поэтому нужна аугментация.
Есть отличные библиотеки — imgaug или albumentation, которыми можно модифицировать картинки разными способами — поворачивать, отражать, добавлять размытие или менять цветовой баланс. Тут главное не переборщить, чтобы изображение оставалось читаемым, к примеру, если применить размытие вместе с изменением яркости, то границы бутылок могут визуально поехать в стороны, не говоря уже о том, что сильные изменения яркости/контраста могут вообще сделать изображение нечитаемым.
Итак, датасет есть. Он сбалансирован и, благодаря аугментациям, достаточно разнообразен, чтобы нейронка не переучивалась. Остается вопрос — какую использовать архитектуру? Нужно ли придумывать свою, или есть универсальные нейронные сети? На самом деле, заранее это неизвестно, но что точно можно сказать — это то, что придется проверить целую кучу разных архитектур, попробовать те, или иные параметры запуска или настройки. Так что любой machine learning проект стоит строить вокруг этой идеи. Если новая архитектура будет подключаться 3 недели, то это плохие новости. В идеале, пайплайн должен быть таким, чтобы закидывая конфигурационный файл, и пару классов-адаптеров для преобразования входных/выходных форматов, подключало новую архитектуру.
Proof of the concept был написан, конечно, без таких требований, но как только он заработал, то следующим шагом было настроить такой пайплайн. Кирилл написал его, взяв за основу Keras, но Сергей, наш заклинатель искусственных интеллектов, поюзав его некоторое время, решил, что торчом жечь удобнее, и запилил свой с блэкджеком и PyTorch.
С миграцией, правда, мы накосячили. У нас была рабочая архитектура, которая сразу заработала на новом коде, когда мы загрузили существующую модель. Но натренировать ее с нуля уже не получалось — что-то было сломано. Проблема была в том, что помимо архитектуры, поменяли параметры аугментации. Вроде бы по чуть-чуть, но много разных изменений, и неясно, что же стало причиной. Пришлось подгонять настройки аугментации один к одному, чтобы понять, что причина не в ней. Так что урок номер один — не выкатывать сразу несколько изменений.
Ошибка номер два — визуализировали аугментацию до предпоследнего шага, а впоследствии оказалось, что проблема была на последнем — данные неправильно нормализировались, и на вход подавалась выжженная картинка. Так что урок второй — если что-то идет не так — лучше сразу визуализировать, и даже если все так — визуализируйте просто на всякий случай.
Все, что натренировали, запустили на выделенном сервере в виде REST API, и сразу начали использовать для предварительной разметки, как указывалось выше.
В DRF есть удобная штука — аутентификация через токен www.django-rest-framework.org/api-guide/authentication/#tokenauthentication. Токен создается для пользователя через админку:
И в дальнейшем, чтобы получить доступ к API, нужно передать токен в заголовке запроса.
Закончу, пожалуй, статью на полуслове, а вскоре ожидайте следующие статьи:
- Склеиваем этикетки в одну длинную, и при чем тут оптический поток
- Регистрируем стартап в штате Делавэр
- Немножко о B2B, и итальянской сиесте

