
Что делать, когда мастер сервер PostgreSQL погибает под нагрузкой?
Довольно часто встречается ситуация, когда база данных не тянет существующую нагрузку и вертикальное масштабирование железа не помогает. Менять PostgreSQL на другую базу данных или переделывать архитектуру приложения и отказываться от СУБД?
Давайте я представлюсь.

Я администратор баз данных. Я работаю с Postgres. Работаю в компании Data Egret. Мы удаленные DBA для многих других компаний. И также занимаемся консалтингом по Postgres. И мы встречаем кучу типовых проблем, которые от компании к компании, от разработчика к разработчику повторяются и имеют одни и те же корни.
Т. к. Postgres – это open source решение, то хороший тон, это делиться своими знаниями с людьми и помогать им лучше его использовать, т. е. более эффективно. Поэтому мы довольно частенько выступаем на конференциях и делимся своими знаниями и опытом.

Первая часть доклада – это картинки-страшилки из мониторинга о том, как у нас нагрузка выглядит. Ваня до этого рассказал очень много про то, как конфигурировать, что надо использовать, что не надо использовать. А как это все дело выглядит в картинках сейчас мы с вами посмотрим.
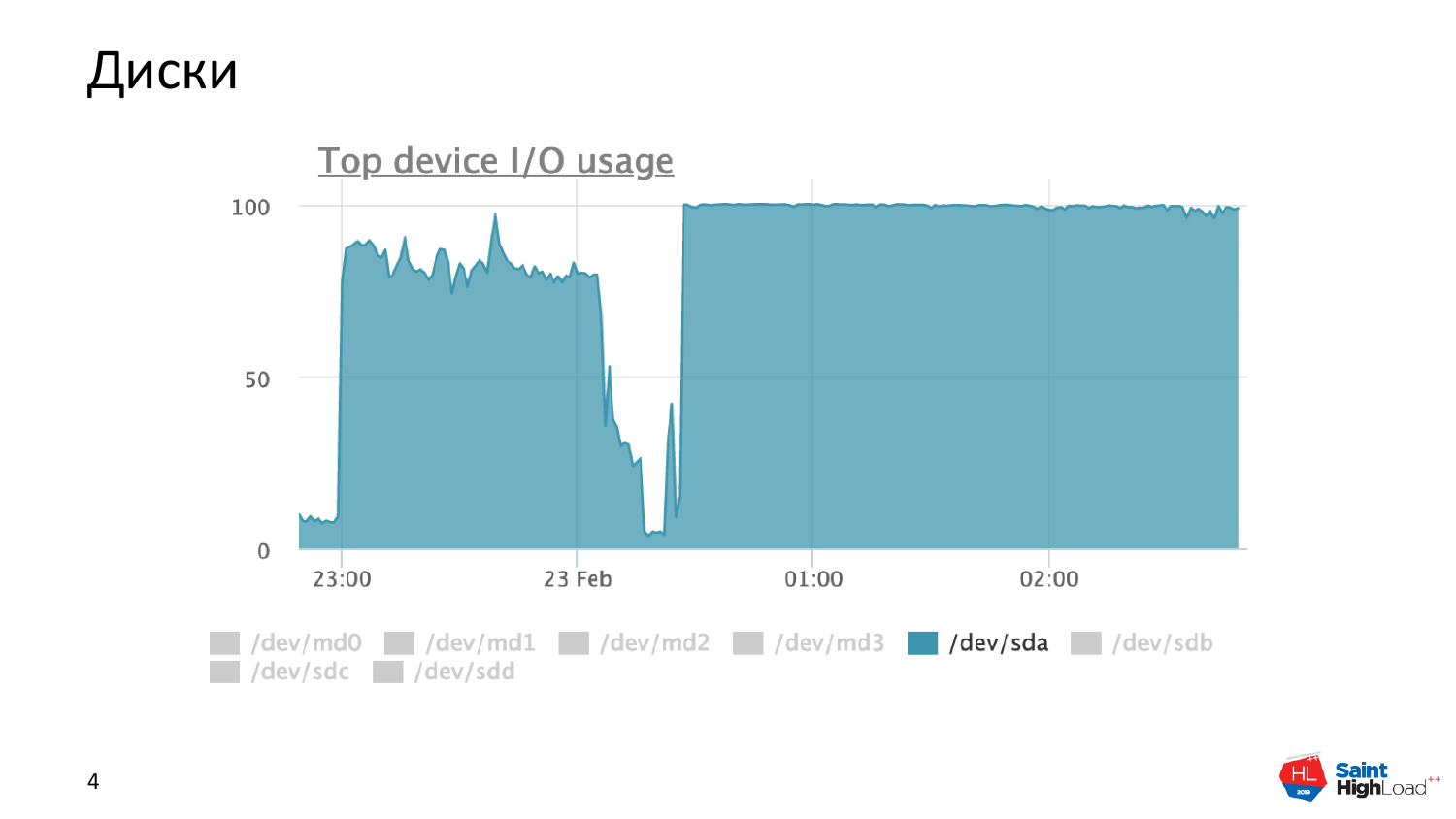
Типичная вещь – это диски в полку. Это может быть у вас как один запрос, так и куча запросов. Это снято с продуктовой базы данных. Это реально работающая база с дисками в полку.
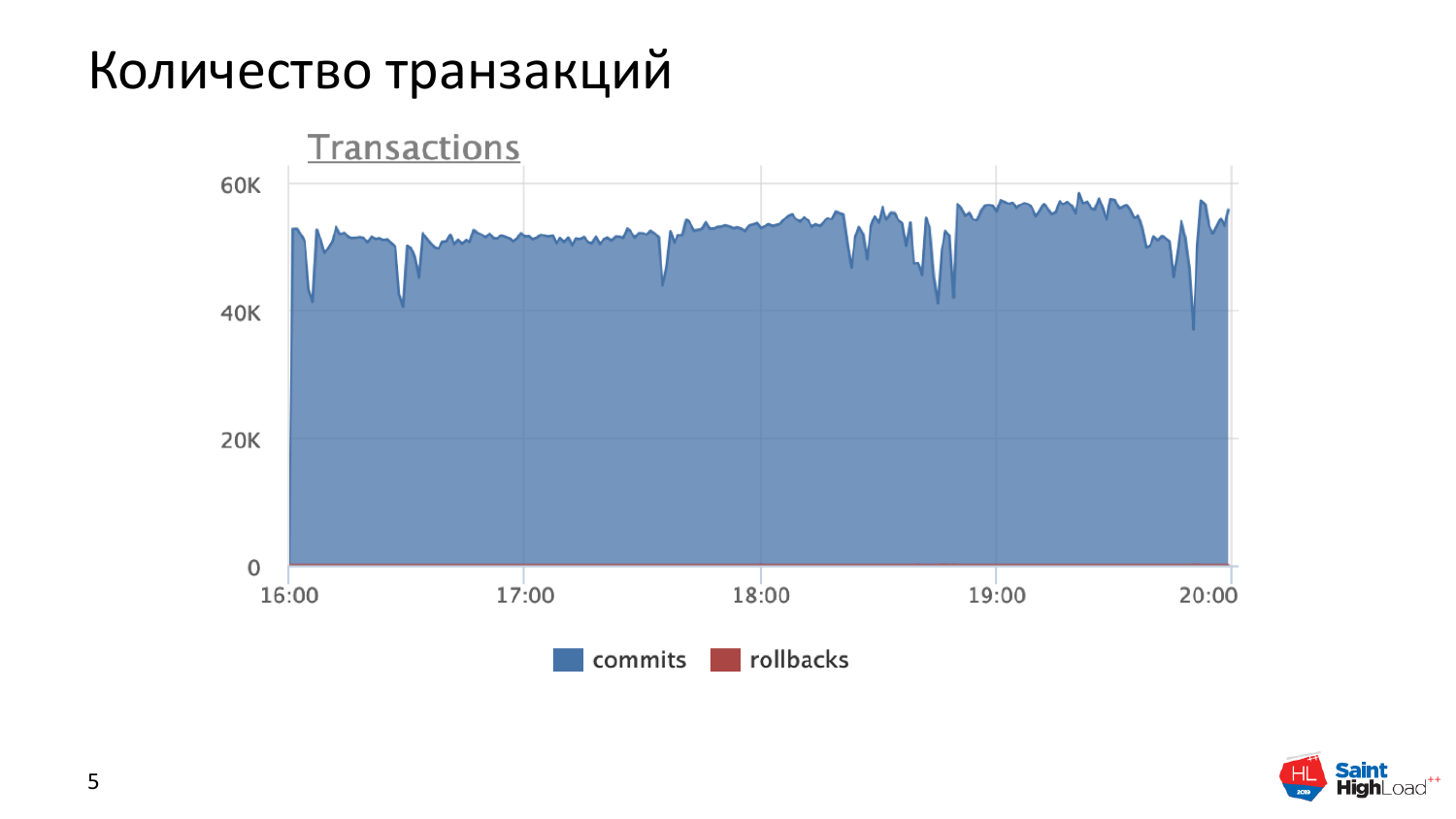
Другая вещь, как у нас проявляется нагрузка, это количество транзакций. На самом деле 50 000 транзакций с одного мастер-сервера – это много для Postgres. Нормальные числа – это 20 000-30 000. Но это тоже продуктовая работающая база и чувствующая себя хорошо. Но если вы видите, что у вас очень много транзакций, значит, что-то вы не так делаете и об этом мы дальше более подробно поговорим.
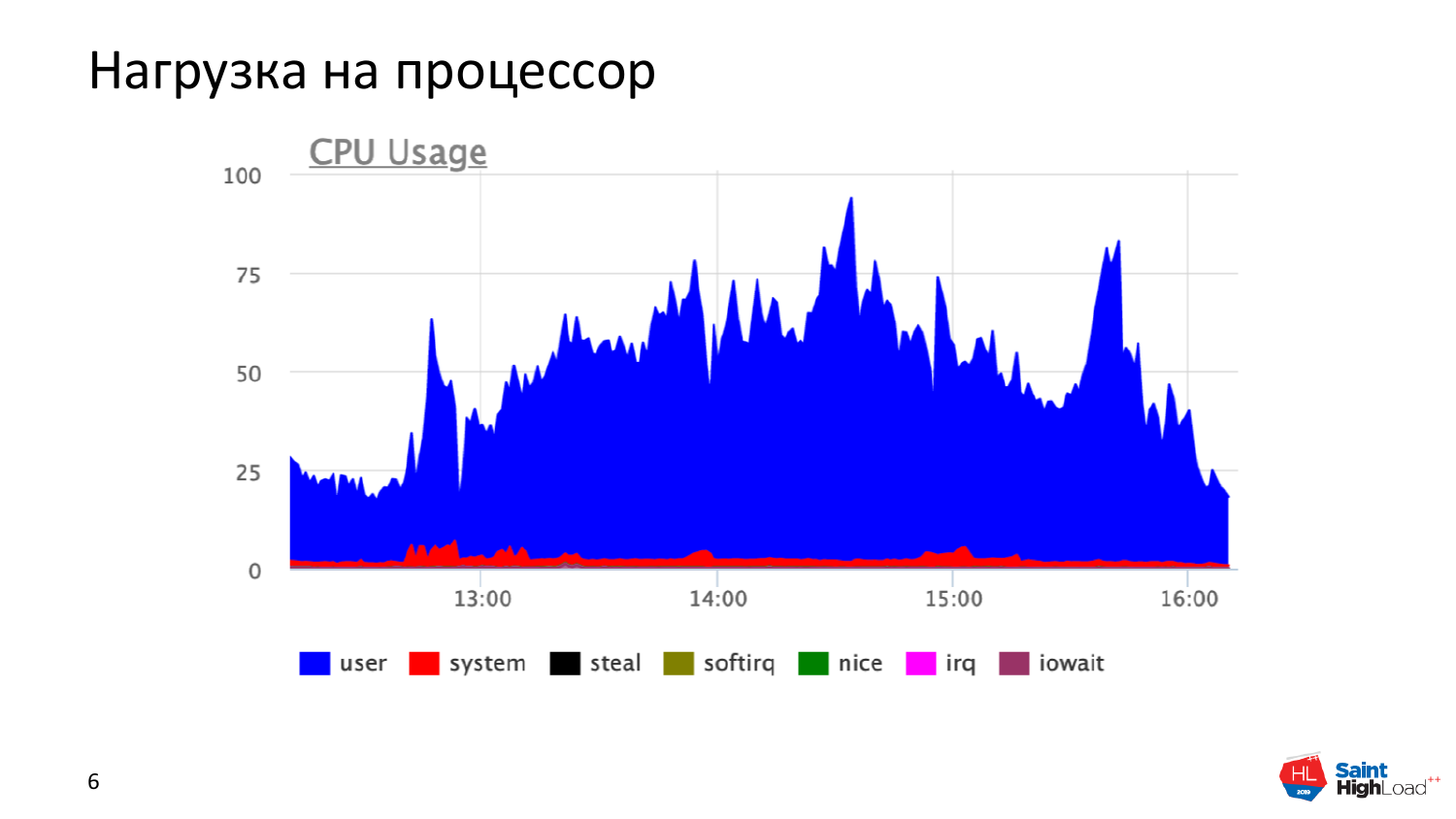
Естественно, CPU. На наших базах я не нашел, когда где в полку, но когда показания CPU высокие, то это значит, что у нас достаточно большая нагрузка на базу данных.
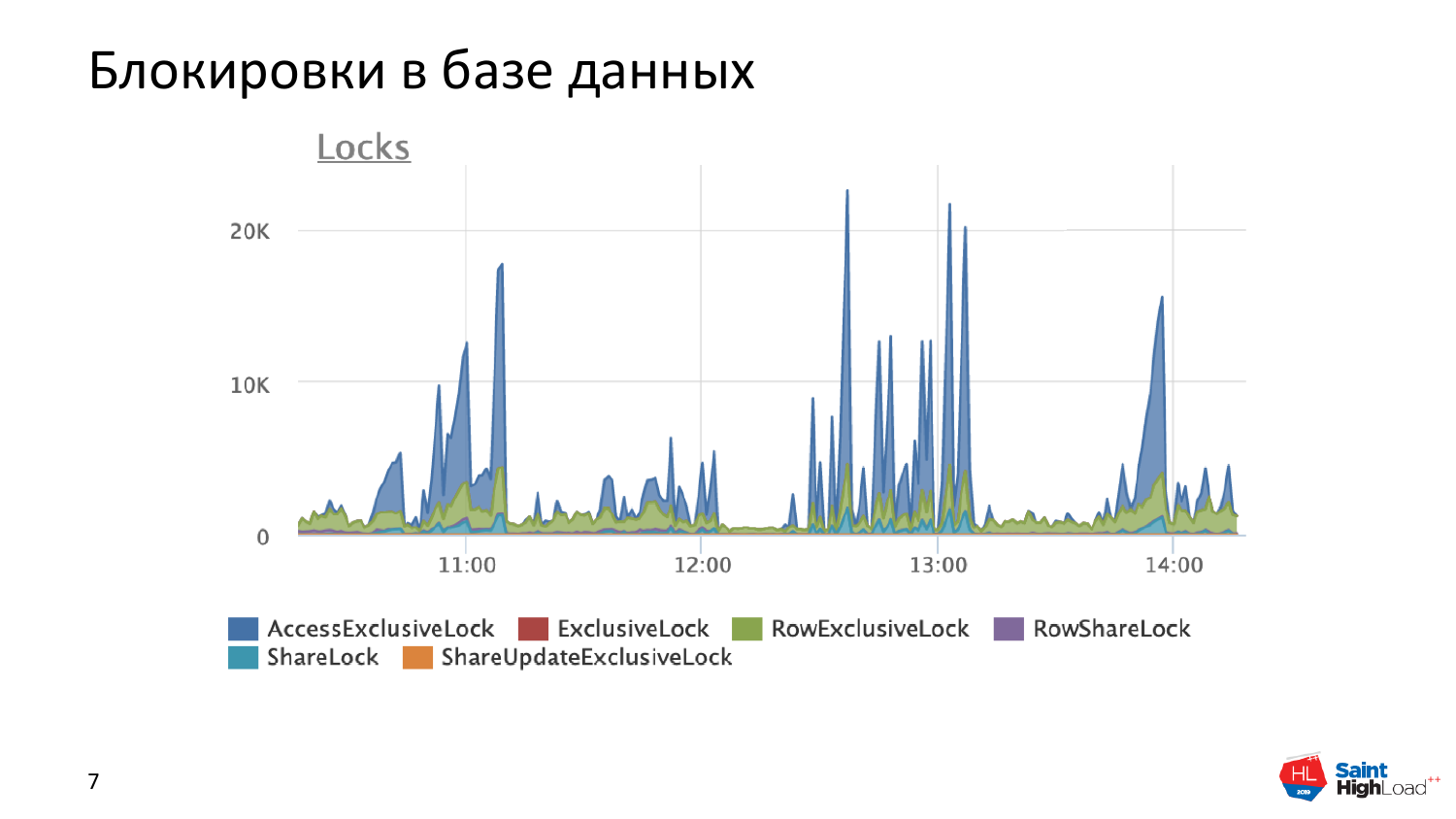
На этой картинке я чуть подробней остановлюсь. Вот это совсем нездоровая картинка, когда у нас 20 000 эксклюзивных блокировок в секунду. Это синие пики.
И я не хотел об этом рассказывать, но в контексте предыдущего рассказа расскажу. Это эксклюзивные блокировки, которые возникают при создании временных таблиц.
Меня позвали разобраться с одной проблемой. И проблема была в том, что новый бэкенд Postgres, когда сессию поднимали, не стартовал. Он стартовал, пытался инициализировать свои внутренние переменные, форкнуть себе каталог системный, форкнуть себе другие вещи, такие, как описание таблиц и т. д. И не мог это сделать, он зависал на этом процессе. Причем зависал он по причине того, что он не мог вклиниться в очередь, чтобы встать очередь ожидания блокировок. Т. е. он даже в очередь очереди не мог вклиниться.

А реальная картинка по блокировкам в базе данных на этот момент была вот такого вида, т. е. это 40 000 блокировок, висящих в базе данных.
И суть в том, что для базы данных эксклюзивная блокировка на временную таблицу вроде бы нестрашная вещь, потому что этой временной таблицей мы пользуемся в конкретной транзакции. И как оказалось, что у нас возникает проблема с тем, что мы просто не можем попасть в очередь на получение блокировки из-за того, что там большие таблицы этих блокировок и просто пробиться сквозь них не можем. И это тоже причина больших нагрузок, которые мы сами себе создали. Это еще камешек в сторону временных таблиц в Postgres.
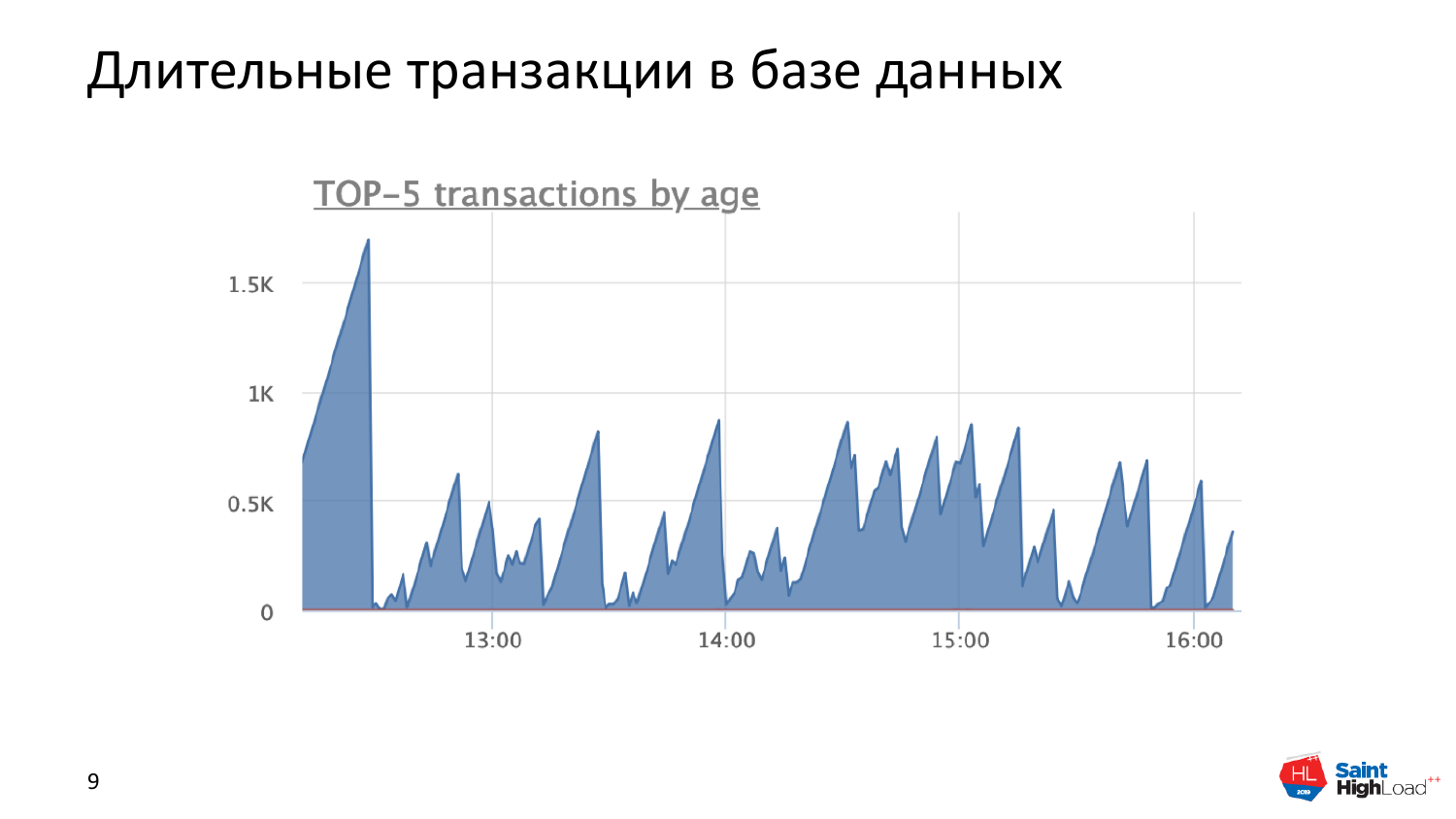
И самая важная проблема – это длительные транзакции, которые очень долгие. На этом графике вы можете увидеть то, что транзакции у нас длительностью по 10-20 минут.

И реально запросы, которые в это время выполняются, укладываются в миллисекунды. И это говорит о том, что у нас что-то нездоровое с базой данных происходит.
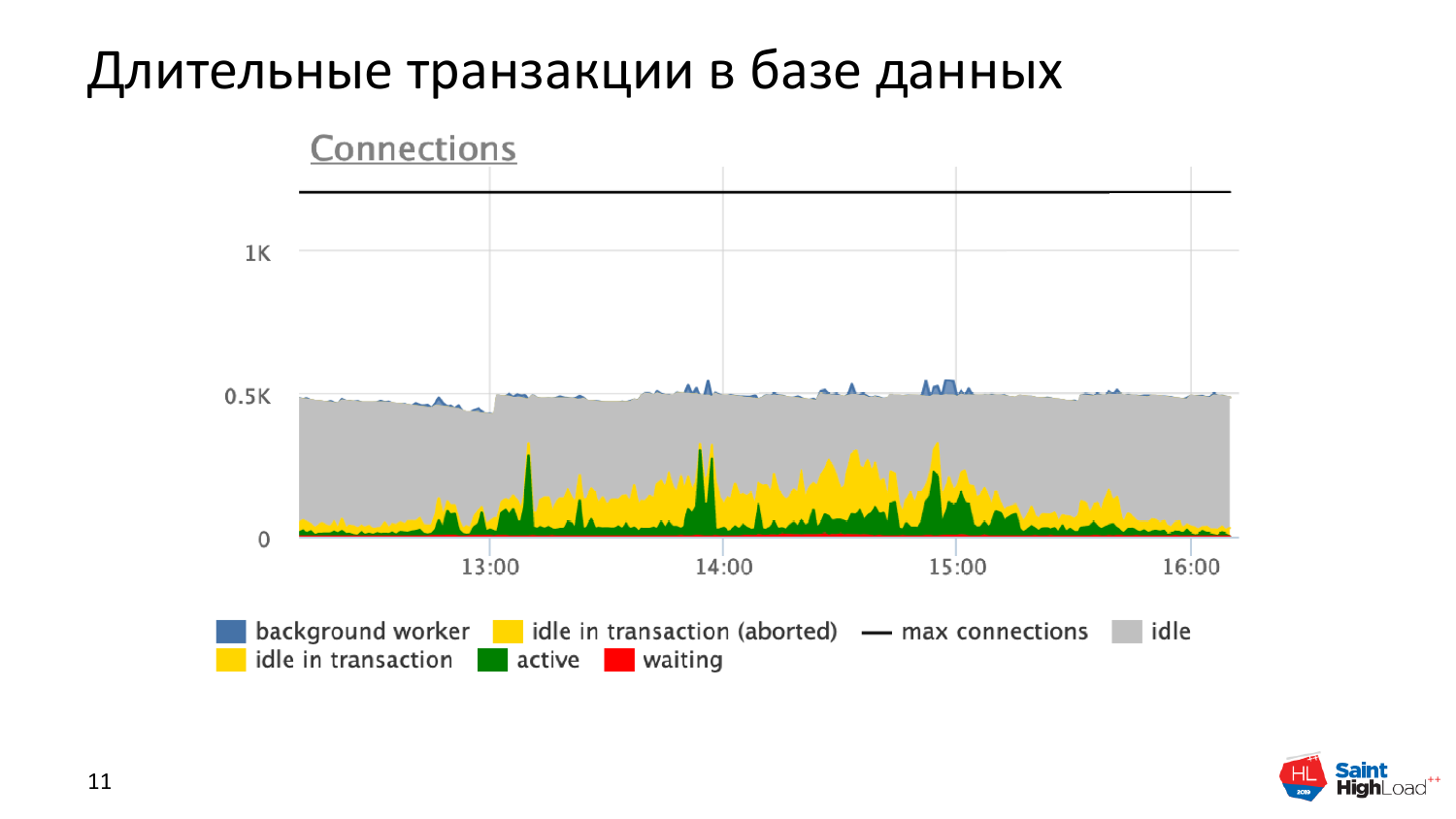
И если вы мониторите состояние своих транзакций, то вот эти нездоровые вещи – это как раз желтенькие части соединения, которые называются idle in transaction.
Idle in transaction – это мы стартанули транзакцию, забили себе transaction id и перестали работать с базой данных. Тем самым мы заставили страдать внутренние механизмы базы данных: делаем плохо и себе, и базе данных. И приложение потом тормозит. И это самая главная вещь, с которой надо разбираться.
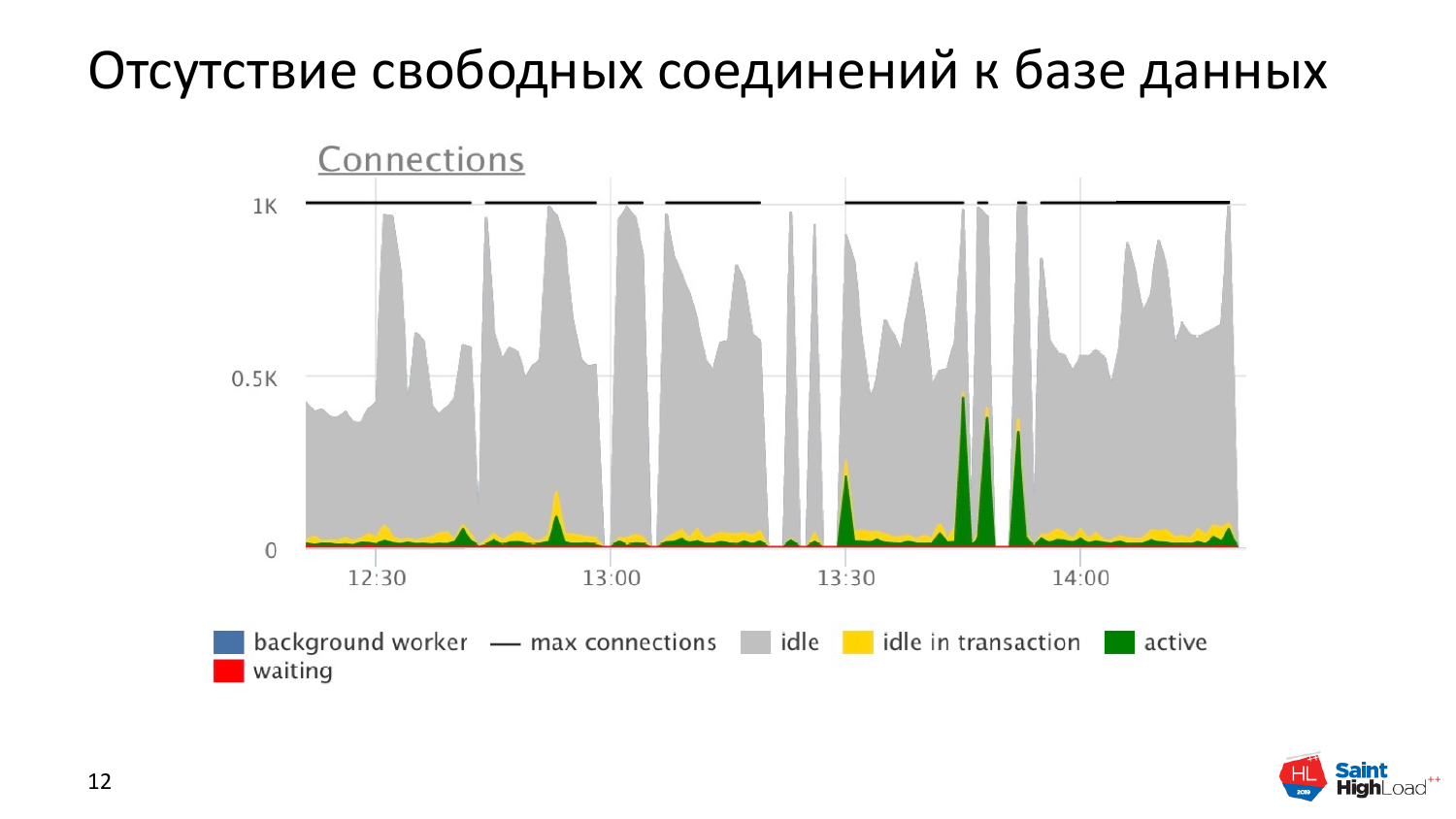
И последняя страшилка, которая тоже говорит о высокой нагрузке, которая не является по факту высокой нагрузкой, когда мы съедаем все свободные соединения.
Случается это оттого, что мы неправильно используем pool connections. Это могут быть pool connections, которые встроены в ваши языки программирования: в Hibernate свои поднимают, в Python свои есть. И если переборщим с этим, то будем держать кучу бесполезных соединений в базе данных, которые не работают. А реально работающих там единицы.
И как бы мы не увеличивали количество соединений, мы все равно будем страдать оттого, что в базе данных нет соединений. Даже если мы будем использовать PgBouncer или Odyssey, который сейчас набирает популярность благодаря Яндексу, то при неправильном использовании можем столкнуться с такой ситуацией.

Картинки-страшилки закончились. И теперь перейду к практической части полезных советов.
Доклад о том, как мы можем шардироваться с помощью реплик. Но когда мы придем к этому моменту, перед этим нам необходимо проделать некоторые вещи, которые вам помогут снизить нагрузку до момента шардирования. И, скорее всего, каждый из вас найдет что-нибудь для себя, что ему необходимо сделать.

У меня буквально несколько слайдов, я быстренько по ним пробегусь и расскажу. 100 % вы найдете свои случаи.
50 % времени пишем в базу ненужную информацию. И это я еще по-доброму написал, потому что, скорее всего, это 80 % или 90 % времени. Почему такие вещи возникают? Когда у нас стартует проект, мы не знаем, какие данные нам нужны, какие не нужны и пытаемся сохранить все. Если у нас проект живет, развивается, то в какой-то момент нам нужно принять волевое решение и не писать весь тот хлам, который мы писали до этого, а писать действительно нужные вещи. Это нам снизит существенно нагрузку по записи в базу данных. Если вы хотите хранить все обо всем, то эти вещи называются логи. Пишите логи, складывайте в пакеты и сваливайте в медленные дисковые хранилища. Когда захочет аналитик что-то там посчитать, для этого есть специальные решения. RDBMS база данных не для этого. RDBMS базы данных ��олжны обслуживать более-менее онлайн-нагрузку, а не такие тяжелые аналитические вещи, если, конечно, это у вас не специально аналитическая база данных. В контексте этой конференции в основном проекты – это какие-то сервисы, которые обслуживают людей и это должна быть онлайн-нагрузка, поэтому дальше я буду говорить именно в этом контексте.
Из этого следует, что мы 50 % читаем ненужные вещи. Даже если мы возьмем паспортные данные, то реально чтобы человека авторизовать, нам нужны его логин и пароль. Но, как правило, разработка идет тем путем, что читают целиком строку, а там у нас могут быть паспортные данные, еще что-то. И это выливается в то, что мы по сети передаем не 10 байт, как нужно было, а 10 килобайт. Тем самым больше читаем с диска, больше передаем по сети, больше нагружаем процессор. И это я тоже еще по-доброму написал, потому что на самом деле нужно еще написать, что 50 % времени удаляем ненужную информацию.
Справочники – это такая вещь, которая меняется редко. И хороший тон при работе с действительно нагруженной базой данных, не ломиться каждый раз в этот справочник, особенно, когда у вас 10 строчек в нем, а один раз при старте вашего бэкенда прочитать его и хранить закэшированно. Обновления по ним приходят редко. Например, раз в неделю, раз в месяц, раз в полгода. Можно себе придумать любую нотификацию, например, через механизм очередей, когда пришло обновление справочника, и просто перечитать его в кэше. Это вам сэкономит очень много ресурсов на чтении на мелких транзакциях, которые все равно жрут процессорные ресурсы и сетевые ресурсы, соответственно. Понятное дело, что справочник будет лежать в памяти, но если вы его закэшируете по поближе к конечному потребителю, то только выиграете от этого, избавив себя от лишних хождений в базу данных.
Разделение информации, которую мы записываем. Этот вопрос касается поиска и нужных, ненужных данных тоже.
- Хороший тон, если у вас есть поля, по которым вы часто ищите в базе данных. Это может быть ID, если вы по ID обращаетесь. Если ищете человека, то фамилия, имя. Хранить это лучше в нативных для Postgres и простых типах, потому что под эти типы написано уйма индексов. Есть уйма методик, как искать. И вы будете более быстро и более точно искать. Если все это вы запихаете в один JSON, то вы будете тратить ресурсы сервера на то, чтобы прочитать JSON, распаковать JSON. Распарсить JSON – это недешево, поэтому для быстрого, часто используемого поиска поля рекомендую хранить в нативных типах для Postgres.
- Т. к. JSON очень многие любят и базы обслуживают фронтенд-отображение визуальной информации, поэтому то, что выводится на экран лучше хранить в компактном небольшом JSON. У нас может быть куча еще дополнительной информации, которая не касается того, что мы должны отображать пользователю. Это могут быть какие-то примечания, что-то отдельное, т. е. то, что мы не читаем много раз. Это нам позволит снизить сетевую и ресурсную нагрузку, потому что мы не будем брать ненужные нам данные из базы данных, а ровно только то, что нужно. Это простое правило, но к нему обычно приходят через боль, через проблемы, когда что-то где-то сложилось или сеть забилась. Наращивают железо, хотя решения довольно простые. У меня есть практический пример, когда разработчики спилили себе запрос один. И у них трафик в половину упал. Они просто убрали ненужную информацию из запроса. И эта вещь будет полезной вам.

Эти все подсказки крутятся около одного момента. Этим можно описать все одной фразой – адекватность запросов в базу, т. е. насколько мы с ней адекватно работаем, с точки зрения того, что нам нужно и что мы оттуда получаем. К сожалению, практические жизненные примеры показывают, что гоняется куча ненужной информации туда-сюда абсолютно бесполезным образом. И любимые ORM, автогенераторы запросов любят генерировать запросы больших размеров. Например, 1 мегабайт, 200 мегабайт. На нашей практике были и гигабайтного размера запросы. И когда в базу данных приходит запрос размером, допустим, в 20 мегабайт, то базе данных банально нужно время, чтобы его прочитать, разобрать, разложить по полочкам и построить какой-то план выполнения. Т. е. они еще не начали выполняться у вас, а уже сожрали большое количество времени и погрели воздух процессором, поэтому такие запросы лучше всего, конечно, контролировать. Контролировать это можно с помощью логов Postgres, потому что они туда, скорее всего, попадут, если вы настроили логирование долгих запросов.
Другая распространенная вещь, если вы у себя видите DISTINCT и n*JOIN. И если вы видите, что вы этот DISTINCT можете смело заменить на GROUP BY и у вас не изменится ничего, это означает, что у вас что-то неправильно в логике запросов. Например, неправильно сделали условия по JOIN, потому что всегда можно написать JOIN таким образом, что вы отберете уникальные поля. Эти вещи тоже надо контролировать в своих запросах. И, по сути дела, это облегчит вам выполнение, когда вы исключите операции поиска уникальных записей, если они у вас предварительно гарантированно уникальные. Довольно распространенная ситуация, когда в JOIN две таблички. Джонят такими условиями, что получают кучу дубликатов. Чуть-чуть меняют условия, а потом делают DISTINCT, чтобы уникальные строчки получить. Меняешь чуть-чуть условия, сразу получаешь уникальные строчки и у тебя запрос раз в 10 быстрее работает. А быстро работающие запросы – это быстро полученный ответ к бэкендам и быстро обработанные данные, и снижение общей нагрузки, ничего не тормозит.
Следующие вещи – это чрезмерное злоупотребление COUNT, MAX, MIN, SUM и всеми агрегатными функциями, потому что эти вещи из раздела аналитики. Этим пользуются бухгалтеры, когда считают зарплату. Они это делают один раз в месяц или один раз в неделю, два раза в неделю, но не каждые 5 секунд. Если у вас каждые 5 секунд активность в вашей базе данных пестрит такими запросами, значит, что-то у вас не так с логикой работы базы данных и вам нужно посмотреть на свои запросы и подумать – правильно ли вы обращаетесь к ней, можно ли как-то переписать. И, скорее всего, вы сможете найти более простое и элегантное решение для базы данных, для прочитывания запросов.
Следующая подсказка, которая облегчает жизнь. Часто используют WHERE id IN и при этом SELECT возвращает несколько тысяч записей. Это тяжеловесная операция. Логичнее будет заменить это на EXISTS (SELECT…). И это вам срежет тоже потребление ресурсов сервера и ускорит запрос. Если SELECT возвращает две-три строчки, то хорошо. Если тысячами, то лучше переписывать в подзапросе.
Очень часто LEFT JOIN можно заменить на такую же конструкцию, как EXISTS (SELECT…) из таблички, которая у вас по LEFT JOIN. Когда это можно заменить? Когда из таблички LEFT JOIN вы не берете никакие строчки, вам просто нужно проверить наличие записи. И тогда это проще сделать через EXISTS. Т. е. если вы ничего не читаете из таблицы, выбираете LEFT JOIN, пишите EXISTS, это будет быстрее, читабельней и понятней.
Разные задачи — разные пользователи
Еще одна очень важная вещь. Это уже в сторону администрирования, т. е. тем, как управлять ресурсами, потому что у нас есть какая-то онлайн-нагрузка, по которой мы должны отвечать быстро, и есть какие-то фоновые задачи, например, балансы посчитать, отчет собрать, еще что-то, которые выполняются достаточно долго и более трудоемко по ресурсам. И такие задачи лучше разделять. В любой у нас проект тыкнешь, в который приходят ребята вначале, у них один пользователь. И, ура, если это не Postgres. Ура, если они создали другого пользователя. А еще дважды ура, если он не superuser. Поэтому под разные задачи, под разные куски кода лучше создавать отдельных пользователей. Самый простой пример, я привел. Это онлайн-нагрузка, когда мы должны отвечать быстро на короткие запросы и какая-нибудь тяжелая аналитика. Лучше это развести по двум разным пользователям. И тогда средствами операционной системы мы можем прижать по ресурсам пользователя просто процессы в операционке, запущенные от пользователя. Тут он называется cron. Можно его report назвать или как угодно. Это нам позволит делать и то и другое, и при этом онлайн-нагрузка не будет страдать, и худо-бедно мы посчитаем отчет, который, как правило, не нужен прямо здесь и сейчас, т. е. всегда дается какое-то время, позволяющее нам посчитать отчет.

Большая проблема, если мы хотим иметь очереди в Postgres. Т. е. если у нас есть очереди снаружи, лучше использовать специализированные решения. Их полно. Это RabbitMQ, ZeroMQ, Kafka. Они все хорошо работают, если вы умеете их варить, лучше их использовать. Все опытные DBA имеют за собой грех, что они писали свою очередь. Я тоже писал свою очередь. Но есть решение, которое было написано давно. Работает оно хорошо и у него один только недостаток. Это плохая документация. Но если разобраться с тем, какой функционал он предоставляет, то там он на все случаи жизни подходит.
- PgQ на данный момент – это единственное решение для реорганизации очереди внутри базы данных, которое работает хорошо и не прогибает базу данных по ресурсам, и не пакостит. Потому что люди, когда его писали, прошлись уже по всем граблям. PgQ из недр Скайпа, когда еще Скайп не microsoft’овским был.
Поговорим про нехватку соединений в базе данных. Картинки-страшилки вы видели.
- Там нагрузки, было два-три соединения, а все остальное idle-сессиями было забито. И я часто встречаю, когда накручивают много соединений. На самом деле Postgres не очень любит большое количество соединений. 100-200-300 – это нормальное количество сессий, которые он может поддерживать. 1 000 – это уже извращение, поэтому посмотрите на настройки своих pools в языках программирования. Срежьте idle-сессии, насколько это возможно. И старайтесь не злоупотреблять ими, потому что вы можете лишить себя соединений и база при этом будет простаивать, а у вас не будет работать приложение.
- И самый лучший вариант – это использование PgBouncer в transaction режиме. Это самое хорошее решение. У него есть ограничение. Он не дает вам prepared statements использовать. Нужно следить не просочились ли set-устанавливающие переменные сессии через PgBouncer. А в остальном там только плюсы, потому что он поднимает сразу нужное количество соединений и сам балансирует нагрузку, с точки зрения того, что выстраивает в очередь запросы. И если вы уперлись одним пользователем в пуле соединений, ничего страшного, у вас страдает только этот пользователь, другие части приложения, работающие с этой базой данных, не страдают. Штука важная и нужная. Надеюсь, что Яндекс свой Odyssey допилит у PgBouncer будет конкурент.
Большие размеры таблиц. Чем это плохо? Плохо это тем, что технические процессы, которые работают над таблицами типа wraparound vacuum, просто vacuum, они могут затянуться надолго и работать часами.
- Поэтому большие таблицы не очень хороши. И чтобы как-то облегчить нам жизнь при работе с большими таблицами, есть такая хорошая штука как частичный индекс, который вам поможет. Приведем пример с транзакциями. У вас валятся какие-то финансовые транзакции. И них есть состояния: обработанное, ожидает обработки. Понятное дело, что обработанных состояний у вас будет 99 % в таблице. И ожидающие обработки или отлупленые транзакции у вас будут составлять 1 %. Поэтому вы можете составить индекс и написать, что в этот индекс заиндексируйте только те строки, которые в транзакции не являются обработанными. У вас будет маленький индекс и будут быстрые запросы. Это очень хорошо, потому что читать многогигабайтный индекс – это тяжело.
- И партиционирование (секционирование). Я люблю слово «партиционирование», но это не русское слово. По-русски будет – секционирование. Эта вещь помогает структурировать и развалить большую таблицу на маленькие кусочки. Как правильно это делать, Иван про это рассказал. Это важная и полезная вещь.

И после того, как вы это все проделали, вам 100 % полегчает. И вы забудете о том, что вам необходимо было шардировать нагрузку. И вы поживете какое-то время. Нагрузку у вас от роста проекта, естественно, вырастет. И тогда вы уже задумаетесь о распределение нагрузки с помощью репликации.
- Из моего выступления вы поняли, что, если вы много пишите, значит, это данные не для базы данных, а для логов, которые нужно хранить где-нибудь в Data Lake, Big Data. Т. е. это куча данных, которые никогда не используются, но копятся. Нам нужны данные, с которыми мы действительно должны работать. И это нужно понимать при работе с базой данных, т. е. надо стремиться к этому.
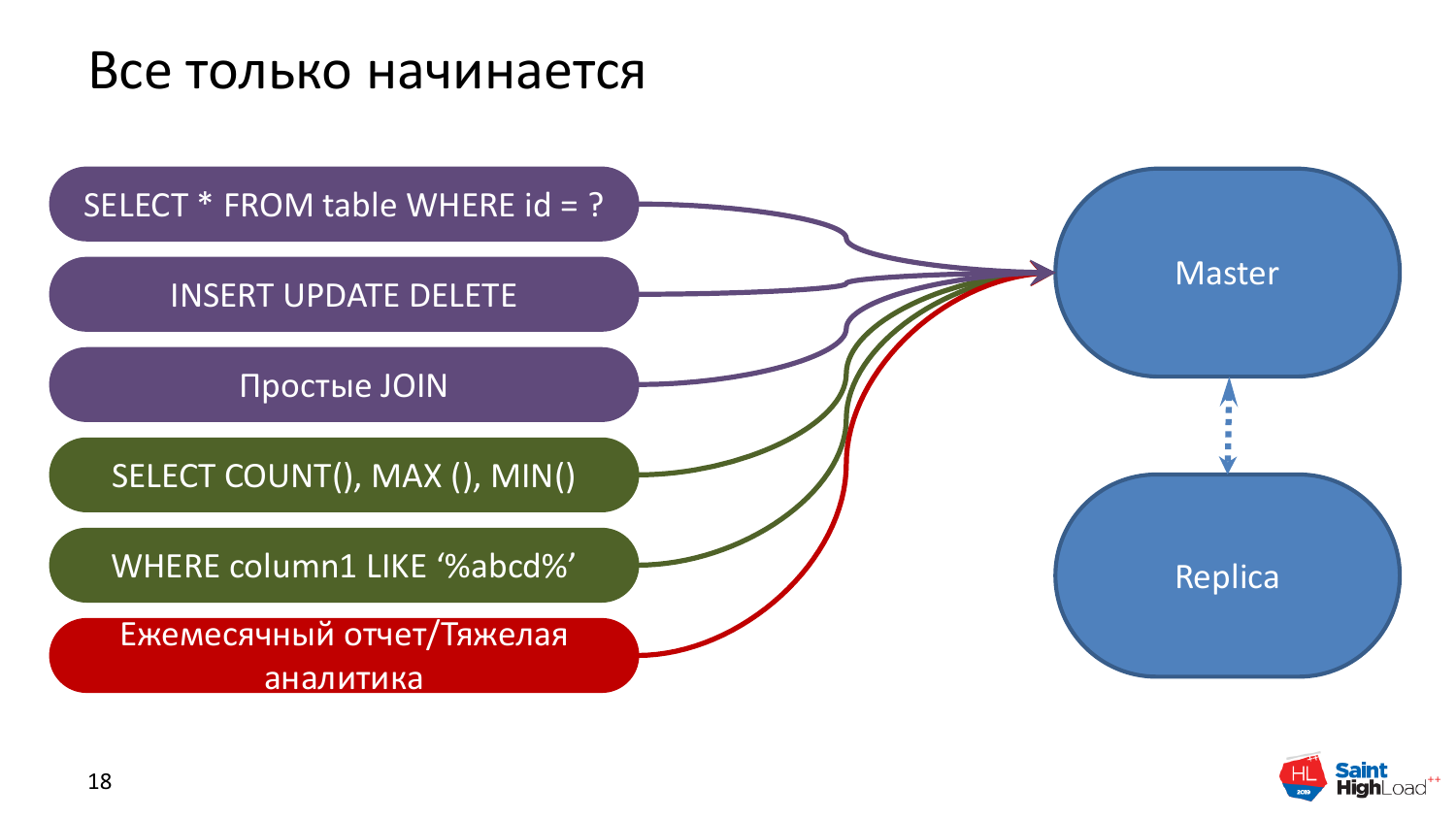
Какие основные паттерны распределения нагрузки с помощью реплик? Это будет только читающая нагрузка, потому что это единственно нормально работающий из коробки вариант без всяких дополнений.
Обычно, когда у нас проект начинается, у нас есть мастер базы данных, в котором творится весь тот беспредел, с которым мы уже разобрались. И есть какой-то набор запросов, которые у нас обеспечивают web-нагрузку. Они обычно идут по ключу, чтобы быстро прочитать, т. е. это какие-то строчки конкретно по ID, какие-то новые вставки и небольшие JOIN. Это все обычная онлайн-нагрузка.
Есть более тяжелая нагрузка, которую можно назвать отчетной или в которой есть сложный поиск. Она требует больше ресурсов, больше дополнительных индексов и больше время на выполнение.
И есть очень тяжелая нагрузка. Например, расчет зарплаты. Эту нагрузку выполняют крайне редко. Она занимает много ресурсов и это очень мучительный, тяжелый процесс. И хорошо, если у нас есть реплика. Если мы продвинутые ребята, то мы озаботились о Fault Tolerance, т. е. не доверяем одному серверу, имеем второй железный. И если случится авария, мы на него переключимся.
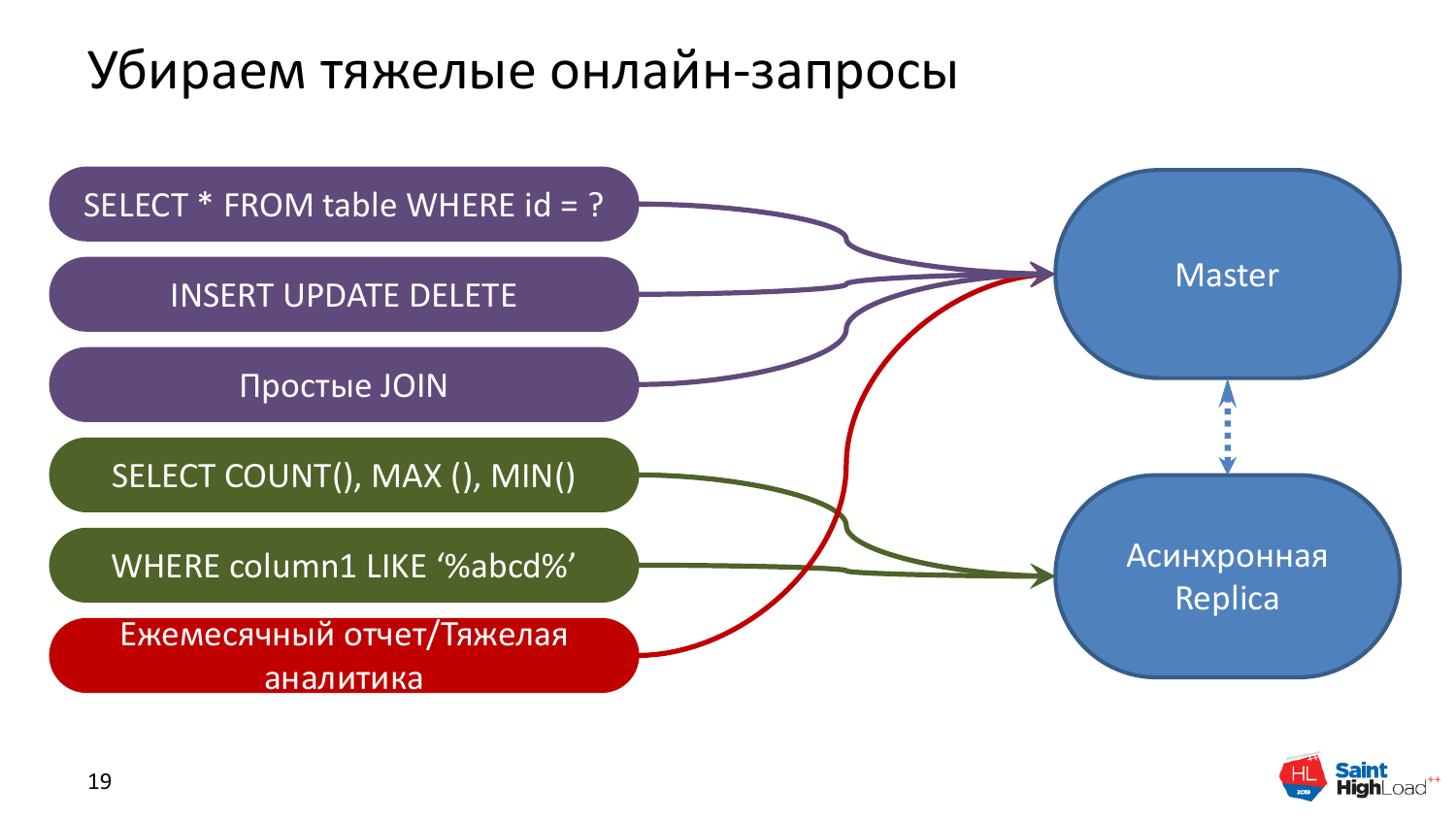
Это исходное состояние. Что мы с ним можем сделать? Понятно, что запросы, которые COUNT, MAX, MIN, т. е. те, которые выполняются долго, они вам не нужны прямо сейчас. И если запрос запустился, условно говоря, минуту назад, то вы получаете устаревшие данные ровно на минуту. Соответственно, эти запросы можно убрать на реплику.
Почему не любят реплики? Потому что у нее есть какое-то отставание по сравнению с мастером. Это касается наиболее используемого типа реплик, т. е. асинхронных реплик. Все тяжелые и длительные запросы мы можем с чистым сердцем и совестью убрать на реплику, потому что ничего для нас не изменится.
Единственное, нам нужно будет подкрутить один параметр – max_streaming_delay, позволяющий не отстреливать эти длинные запросы. Грубо говоря, он выставляется из расчета – берем длительность самого долгого запроса, увеличиваем в два раза задержку репликации. И у нас не будет проблем, мы будем гарантированно вычитывать данные с асинхронных реплик.
И нам уже сразу полегчает, потому что, во-первых, два сервера, наполнение кэша разное, т. е. для быстрых запросов, к примеру, у нас могут быть нужны одни индексы, для медленных другие. И на двух серверах они в памяти кэшируются. Разные данные закэшированы, и мы живем хорошо. Быстрые данные у нас актуальные приходят, а долгие приходят чуть позже. Красота.
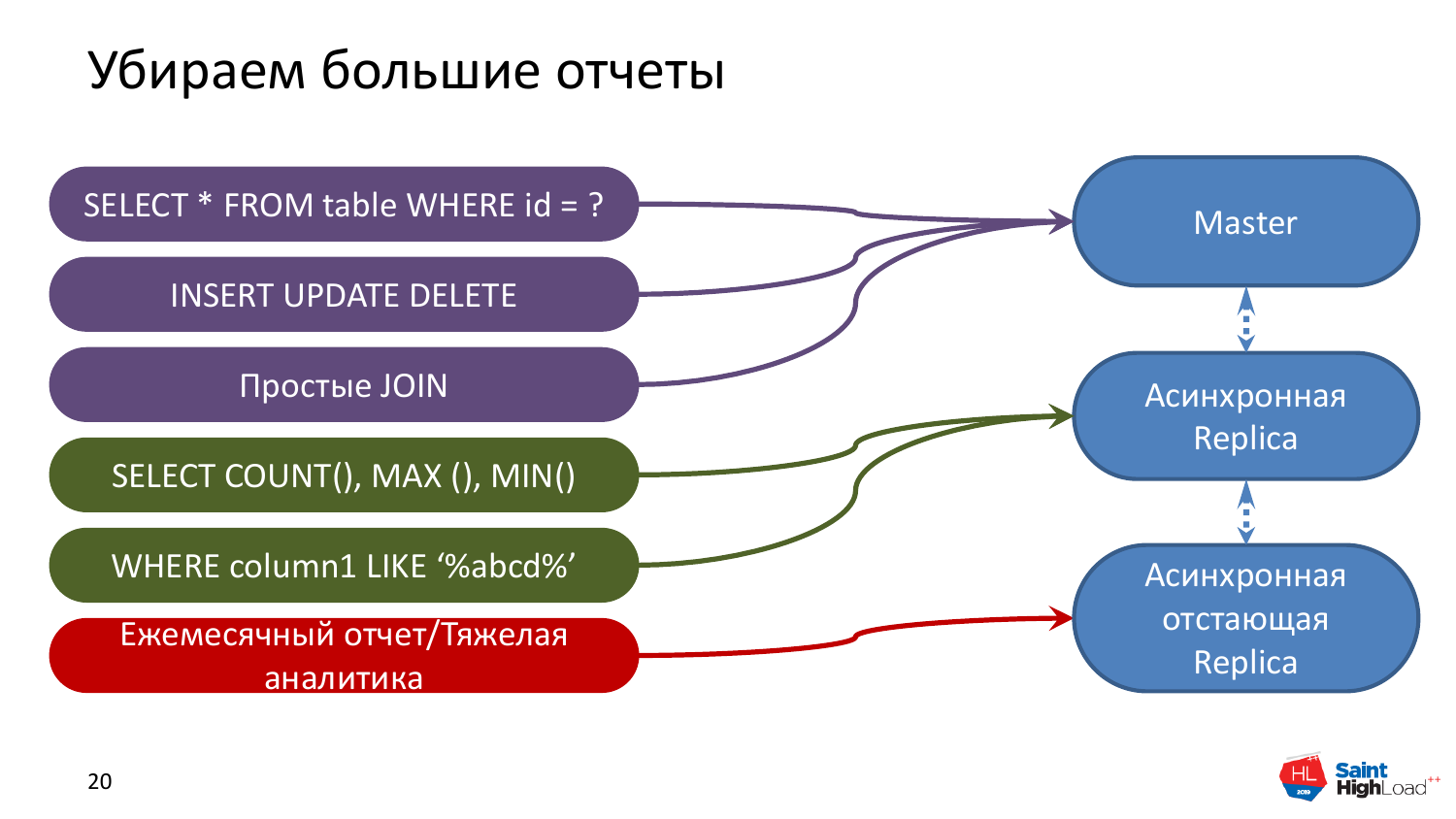
Что можно сделать следующим шагом? Следующим шагом мы можем сделать еще более долго отстающую реплику. Допустим, приходят аналитики и говорят, что им нужно что-то сделать с тяжелыми отчетами. Понятное дело, что на мастере нам такая нагрузка будет мешать. Для этого мы можем или увести на асинхронную реплику этот отчет или создать специальную реплику для отчетов, в которой будет max_streaming_delay. И можно даже сутки поставить, это нестрашно. Отчет, который выполняется несколько часов, никогда не будет актуальным и по свежим данным. Поэтому такая вещь тоже легко переносится.
И получается, что на данной картинке у нас вот эти две реплики обеспечивают более-менее онлайн-нагрузку, а эта для отчетов. И все хорошо, никто не страдает. И мы по ресурсам еще отмасштабировались, и это хорошо для нас.

Что можно сделать еще? Вот эти шаги обычно проходят наши клиенты, это жизненные примеры, как это все происходит. Следующим шагом, когда мы действительно упремся в быструю онлайн-нагрузку, это добавить реплику, которая будет синхронной или асинхронной с небольшим latency. Небольшое latency в данном случае – это 10-20 миллисекунд. Такие значения достижимы.
Мы помним, что все тяжелое с сервера мы убрали на другие реплики и можем довольно быструю реплику построить. Единственное, там есть требование к сети. Нужно, чтобы сеть была бодрой и веселой.
И всю читающую нагрузку мы можем распределять между несколькими репликами. Но этот случай совсем крайний, когда вы действительно уперлись. Если идти по шагам слайдов, как я шел с самого начала, то вы, скорее всего, до этого этапа в большинстве случаев не доберетесь.
Почему написано «(А)Синхронная реплика»? У синхронной реплики есть небольшой нюанс. Синхронная реплика заставляет страдать вакуум в основном на мастере. И это нам выливается в bloat таблиц и индексов. И это выливается в итоге в ухудшение производительности базы данных. Поэтому лучше все-таки асинхронные использовать реплики. Но если совсем-совсем надо, то можно и синхронные, но их нужно включать с гарантированно хорошей сетью.

Какие параметры нам действительно в практике полезные, которые работают и не сильно ущемляют внутренние системные ресурсы Postgres?
Max_standby_streaming_delay – это самый универсальный параметр. Тут можно для себя понять, что запрос, который работает секунду, он у вас никогда неактуален. И вы всегда можете отложить репликацию на секунду. И получите ровно те же самые данные, ничто для вас не изменится. Если у вас часовой запрос, т. е. вы его час назад стартанули, то в него данные, напихавшиеся в базу за час, не попадут. И вы можете спокойно реплику заставить отставать на час. А если на час, то и на два можете заставить отставать. Нет тут никакой проблемы. Просто с этой мыслью надо сжиться и понять, что это работает и это нормально. И это первый параметр, который вам надо крутить.
Hot_standby_feedback – это когда нам нужно по каким-то причинам все-таки выполнять запрос и небольшое отставание в реплике иметь. На самом деле все эти причины среди наших клиентов, как правило, разбиваются о наши доводы. И это предмет большой дискуссии, зависящий от конкретной задачи бизнеса. Но если вам это действительно нужно, вы можете это включить. Только не злоупотребляйте этим – максимум одна машинка.
От hot_standby_feedback страдает автовакуум, растут размеры таблиц, индексов, просаживается производительность запросов и базы данных, поэтому не забывайте об этом.
И есть параметр synchronous_standby_names. И с помощью этого параметра мы себе устраиваем двухфазный коммит, трехфазный коммит, т. е. сколько реплик там пропишем. Там немножко сложнее алгоритм, но для общего понимания – мы ждем подтверждения от кучи реплик, что везде у нас закоммитились данные. И тут надо понимать, что, прописав синхронные реплики, вы получаете консистентное состояние между базами данных, но при этом получаете просадку в производительности по записи. Потому что вам необходимо дождаться подтверждения совершенной транзакции с каждой реплики. И это может растянуться на долгое время, потому что если у вас с сетью проблема или в какой-то момент возникает пик в сетевой нагрузке, то могут быть проблемы. В общем, параметр существует, но к использованию не рекомендуется.
Единственный толковый – это max_standby_streaming_delay, а остальные используются в очень редких случаях. И если вы задумались – нужен ли он вам или не нужен, то не нужен он вам.
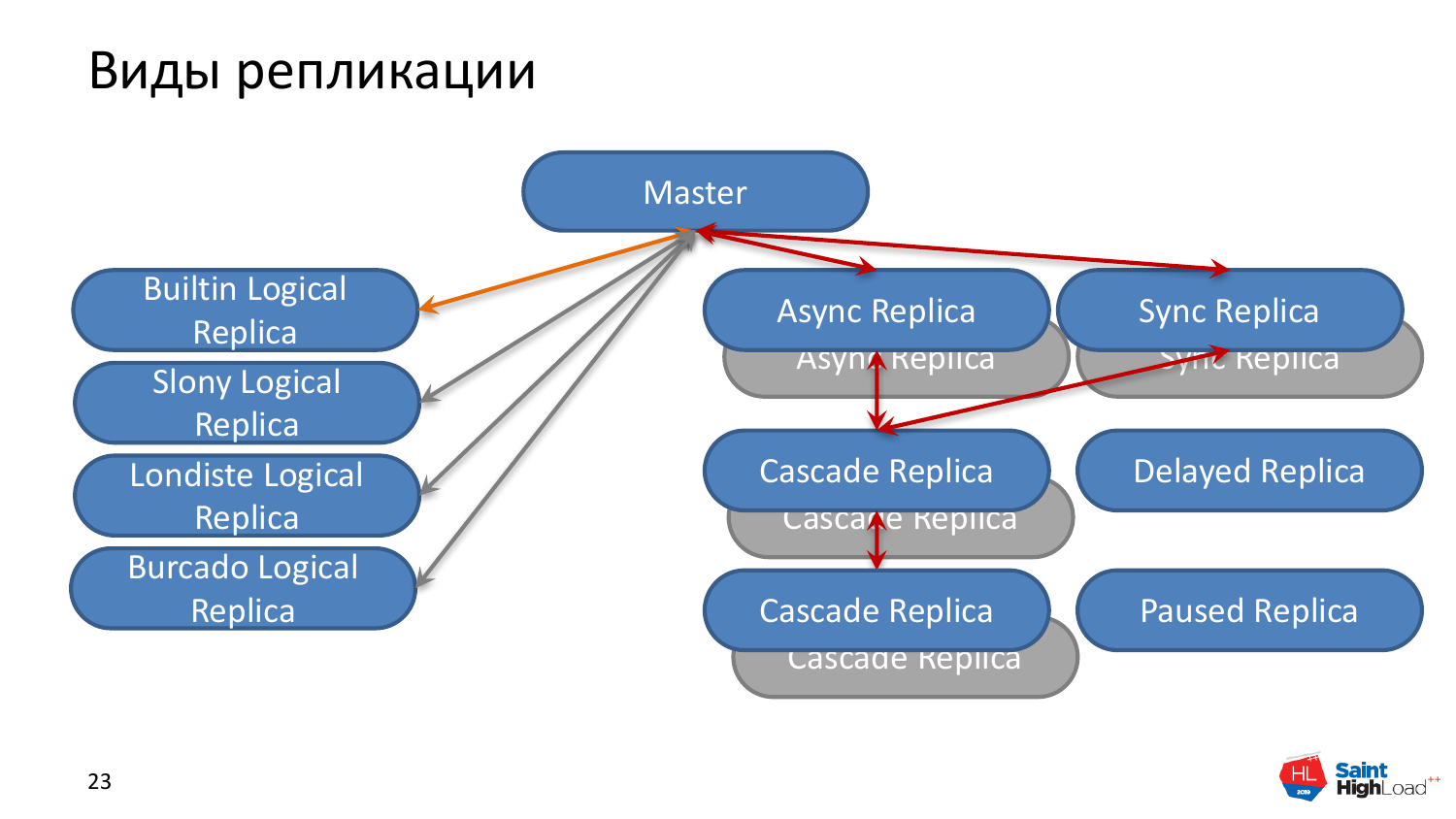
И немного поговорим о том, какие типы репликации бывают в Postgres, т. е. именно почти из коробки.
От мастер-сервера есть два типа репликаций. Есть потоковые бинарные репликации, когда мы копируем базу данных, бинарные как есть. И есть асинхронные реплики, т. е. они идут с каким-то запозданием, связанным с тем, что данные нужно передать по сети и применить на сервер-реплике. Их может быть установлено какое угодно количество к мастер-серверу. Как правило, мы на практике делаем одну-две реплики и не более того.
Есть синхронная реплика, которую вы прописали в конфиге на мастере, от которой мы ждем подтверждение, что там тоже совершился коммит данных, чтобы сделать его на мастере. И это единственная разница между синхронной и асинхронной репликой. Данные на нее также медленно заползают, но это зависит еще от сети.
Есть каскадные реплики. Эта штука была сделана для того, чтобы не перегружать мастер и не перегружать сеть на мастер-сервере, потому что, если мы пишем достаточно много на мастер-сервер, мы можем сетевые интерфейсы забить потоковыми репликациями, если мы целый зоопарк реплик натравим на мастер-сервер. Поэтому были сделаны каскадные реплики, которые тянут изменения из любого типа реплики: синхронной или асинхронной. Они обычно используются для запросов, по которым не нужны совсем свежие данные с миллисекундными задержками. Очень удобная вещь, в большинстве случаев так и делают. Мастер, несколько синхронных реплик к нему и дальше уже каскадные реплики, если очень сильно надо масштабироваться по нагрузке.
Есть такая вещь, как delayed реплика. Есть файл recovery.conf в Postgres и мы там можем указать, что, допустим, эта реплика у нас должна быть отстающей на три дня. И она будет стабильно на три дня отставать от мастер-сервера.
Зачем это нужно? Для deploy. Допустим, мы задеплоились, там какой-то большой апдейт данных сделали, а потом через сутки поняли, что неправильно сделали. И у нас есть delayed реплика, где данные еще неиспорченные и мы можем их оттуда достать.
И есть поставленная реплика на паузу. Мы делаем паузу репликации. Это в случае, когда у нас небольшие deploy. На паузу поставили реплику, изменения на нее не применяются, задеплоились, проверили – все ли хорошо. И можем откатиться, если надо.
И еще есть триггерные реплики и встроенные логические. Это логические репликации, которые идут кусочками. В принципе, в нашем контексте пока они не интересны. Просто знайте, что они есть.
У меня все. Доклад про очевидные вещи, но практика показывает, что многим они помогают очень сильно.

Андрей, спасибо! В настройках WAL есть всякие параметры буферизации задержек. В плане репликации есть ли вариант, чтобы через это сократить объемы трафика, чтобы реплицировать не все подряд, а то, что поменялось к какому-то моменту? Например, если у нас обновляется одно и то же по двести раз подряд.
Потоковая репликация непрерывная, т. е. если мы конкретно о бинарной говорим. И если мы много изменений делаем, то никуда не денешься, их будет много. Тут в сетевой протокол больше упремся и в однопоточность процесса наката репликации и отдачи. Поэтому как-то регулировать и смысла особого нет, потому что реплики нужны, чтобы у нас там были данные более-менее актуальные, т. е. сколько наделали дел в мастере, столько в какой-то момент должны получить в реплике. Можно через файловый архив, т. е. есть же репликация через архив WAL логов. И через него можно каким-то образом регулировать. Но потоковую навскидку нет.
Все равно трафик не сократит это?
Да-да, трафика будет ровно столько же. Это изменение страниц в памяти как они хранятся на диске, т. е. они ровно так и идут. Там ничто не изменишь. Единственно, что там есть всякие WAL-G, они как-то там выжимку делают. Но, честно говоря, доверия очень мало, когда какой-то сторонний софт сделал выжимку данных и страниц, а потом применил на реплике. И уверенности в том, что он это сделал корректно, не очень много. Поэтому такому механизму в системе бэкапирования я не очень сильно доверяю.
Спасибо!
Здравствуйте! Спасибо за доклад! Я хотел спросить по поводу соединений. Насколько правильно я вас понял, что самая оптимальная стратегия соединений – это когда мы устанавливаем PgBouncer в транзакционный режим? И каким образом мы действуем? Мы per_request отправляем? Т. е. держим соединение, открываем его, отправляем на PgBouncer запрос и закрываем соединение, а PgBouncer уже самостоятельно решает – необходимо ли ему открывать новое соединение?
Сейчас вкратце объясню, как он работает. В режиме transaction у PgBouncer создаются пуллы на пару база-пользователь. Т. е. для каждой пары база-пользователь он выделяет сколько-то idle-соединений, база устанавливает, поднимает их. И все, что приходит к нему снаружи, т. е. для кого он, как база данных выглядит, он вот эти все запросы пользователь-база себе в очередь помещает и эту очередь обрабатывает по мере того, как у него соединения освобождаются. Если вы будете бомбить долгими запросами, то, соответственно, у вас забьются все эти соединения, старые будут в очереди висеть. Но, в общем, он позволяет выигрывать, потому что он не тратит ресурсы базы данных на переинициализацию сессий, которые довольно тяжелые.
Т. е. правильно короткими запросами его бомбить?
Можно и большие запросы через PgBouncer делать. В этом ничего страшного нет. Приложение должно ходить через PgBouncer в большинстве случаев. Он стоит у вас перед базой. И это краник, которым вы регулируете поток запросов в базу данных от конкретного пользователя. Вот это основной его плюс, который позволяет более эффективно базу данных использовать.
Спасибо!
Здравствуйте, Андрей! Спасибо за доклад! Есть ли успешные сценарии репликаций, когда реплики между ДЦ находятся, а в худшем случае даже в разных странах, т. е. когда живость канала нельзя гарантировать?
Есть успешные сценарии географически разнесенных реплик – это когда вы платите очень много денег за сеть между этими ДЦ.
Если два канала есть, но их живость нельзя 100 % гарантировать?
Тут вы должны понимать, что у вас в любой момент может случиться разрыв, и реплика отстанет на какой-то момент. Все упирается в количество WAL-сегментов, которые вы храните на мастере или где-нибудь архивируете, и вы можете пережить такой разрыв. Т. е. консистентное состояние реплики и мастера в разных ДЦ только от сети зависит. Чем лучше сеть между ними, тем они более консистентные.
Каких-то архитектурных приемов в данном случае нет совсем?
У вас будет все медленно. Обычно хотят, чтобы было все быстро и хорошо. Нужно понимать, что будет медленно и быстро там никогда не будет. Т. е. быстро будет задорого.
Спасибо!
Спасибо большое за доклад, Андрей! Вы рассказали про распределение нагрузки. У нас есть мастер, есть реплика. Реплика с отставанием асинхронная, просто синхронная. Еще где-нибудь с боку есть каскадная реплика. И как в таком случае настраивается failover? Т. е. как будет настраиваться перетасовка – какой из серверов станет синхронным с отставанием? Вы поняли?
Я понял, вопрос о том, что у нас есть много реплик разного типа и есть еще отдельные tools, которые позволяют auto_failover для Postgres строить, и в случае аварии с мастером сервером запромоутить какую-то реплику, которая станет мастером-сервером и переключит туда нагрузу. Какого общего решения нет, т. е. каждое решение принимается по своим каким-то принципам, т. е. решение о том, кто станет мастером. Но обычно выбирается реплика с наименьшим отставанием, у которой большее количество WAL логов было проиграно к этому моменту. Обычно эта реплика и станет мастер-сервером. Но эти вещи настраиваемые, потому что можно исключить некоторые реплики из auto_failover, чтобы туда никогда не переключалось. Это конкретно от каждого решения зависит, которое вы выберете.
Спасибо!
А можно ли сделать репликацию какой-то таблицы саму в себя, базу данных саму в себя? Например, мы большую таблицу реплицируем в эту же базу данных, но в другую таблицу с другим именем, которая реиндексирована по-другому и более удобна для других видов поиска.
Я сейчас рассказывал в контексте потоковой репликации. Там весь instance Postgres копируется как есть. У вас вопрос из разряда того, как использовать логическую репликацию. Все зависит оттого, какой инструмент вы выберете: или встроенную логическую, или триггерную, или сами напишите. Но ничто не запрещает это сделать, подобрав нужный инструмент. Но должен быть написан дополнительный код вами. И это требует некоторых знаний, как это сделать. Это сторонние утилиты в большинстве случаев и нужно покопаться с ними. А так – да, кому надо, те так и делают.
Привет! Спасибо за доклад! У меня есть вопрос, что делать с COUNT, если они все-таки нужны в регулярных запросах? Например, можно их триггерами считать или функциональным индексом, или какой подход вы рекомендуете?
Если вы каждый раз задаете COUNT, то, во-первых, нужно задать вопрос себе – а зачем они вообще нужны? Это, наверное, больше вопрос к бизнесу, который затребовал этот функционал. Например, возьмем таблицу, в которой 10 миллионов строк. И мы считаем COUNT по всей таблице. И понятно, эти 10 миллионов строк через 5 строк добавленных или удаленных сильно не изменятся. И останутся те же самые 10 миллионов. И вопрос стоит задать бизнесу – зачем тебе это знать каждый раз? Тут статичная ситуация. Понятное дело, когда вы отбираете 3-5 строчки.
Да-да, такой сценарий и имеется в виду.
Тут именно нужно смотреть на запросы и смотреть на их адекватность. Если у вас COUNT идет по 100 000 строчкам, то эти 100 000 через 5 минут так же и будут теми же сами 100 000 строчками, а вы, допустим, этот COUNT запускаете раз в секунду. Это нецелесообразно. Это вопрос взаимодействия разработчика и того, кто ему ставит задания по бизнес-логике приложения, которое нужно. К базе данных оно почти не имеет отношения.
Ок, хорошо, спасибо!
Андрей, спасибо за доклад! Было интересно проследить за эволюцией проблем, которые возникают у ваших клиентов и за эволюцией решений. И вопрос следующий. С вынесением аналитических запросов на отдельную реплику, как можно наилучшим образом организовать приложение? Можно ли это сделать в PgBouncer или в какой-то другой утилите, чтобы приложение само не решало на какой instance ему идти, не поддерживало соединение с этим instance? Есть ли какие-то инструменты, практики?
Понял я ваш вопрос. Это конфликт интересов между администратором базы данных и разработчиками. Разработчики хотят, чтобы за них кто-то подумал и распределил запросы. У вас там какая-то хранимая функция написана, вы делаете логику к базе данных, там хранимка. Как вы вызываете эту хранимку? SELECT, имя хранимки и параметры. Что внутри хранимки? Это запрос на чтение, на запись? Автоматические инструменты есть в природе, но пользоваться ими крайне не рекомендую, потому что это надо смотреть в рамках бизнеса и того, какая логика у приложения. В самом приложении должно быть прописано, что эти запросы могут работать только на мастере, эти можно запустить на реплику. Т. е. лучше будет, если вы пойдете путем, когда об этом сразу приложение будет знать. У него будет два соединения. Одно для реплики, второе для мастера.
Как получать эти соединения? Можно автоматически через сервис Discovery, можно прописать. Но все зависит от инфраструктуры, которая у вас используется при разработке. Но если вы пойдете путем, когда это делает приложение и не будете искать инструментов, вы избежите кучу бед. Пример одной из беды я привел.
Я понял, спасибо! Но я имею в виду, что этот инструмент, естественно, предполагал бы, что мы могли бы настроить его и допустим, сказать, какие-то по маске запросы. Можете сказать, какие инструменты есть? Хотя я понял, что лучше это делать руками в приложении.
PgPool есть, который это может, но по факту мы не рекомендуем его использовать.
Понятно, спасибо!

