
В докладе планируется рассмотреть малоизвестные или недостаточно хорошо освещённые в документации возможности ClickHouse: инкрементальная агрегация и манипуляции с состояниями агрегатных функций, межкластерное копирование, выполнение запросов без использования сервера и т.п. Будут приведены примеры из практики разработки сервисов Яндекса: как выжать из системы максимум возможного.

Всем привет! Меня зовут Алексей! Я делаю ClickHouse. И сегодня я хочу вам рассказать про некоторые возможности, которые я сам считаю интересными, но про которые не все знают.
Например, сэмплирование. И, соответственно, ключ сэмплирования. Это возможность выполнения приближенных запросов. Знает пара человек. Уже хорошо.
Рассмотрим типичную задачу для ClickHouse, именно ту задачу, для которой он предназначался изначально. Есть у вас какой-то clickstream. Например, рекламная сеть, система веб-аналитики. И, допустим, есть у вас Яндекс.Метрика.
И у вас есть куча событий, которые вы хотите хранить в неагрегированном виде, т. е. без какой-либо потери информации и генерировать отчеты налету в режиме онлайн.

И вы хотите генерировать отчеты для разных клиентов. И среди клиентов есть некоторые маленькие, например, маленькие сайты типа pupkin.narod.ru; есть средние и есть действительно крупные такие, как yandex.ru. И вы хотите для таких крупных клиентов получать отчеты мгновенно. Что значит мгновенно? Хотя бы за секунду.
И для этого есть отличное решение. Можно выполнять запросы не целиком, а по некоторому сэмплу. Для этого нужно просто объявить в вашей таблице MergeTree, ключ сэмплирования.

И вот, как это делается. CREATE TABLE. Дальше ORDER BY – первичный ключ. Кстати, структура точно такая же, как в Яндекс.Метрике для таблиц просмотров событий. Номер счетчика, т. е. идентификатор сайта, потом дата идет, а потом некий Hash от идентификатора пользователя. Дальше партиционирование. И в самом низу ключ сэмплирования. И в качестве ключа сэмплирования hash от идентификатора пользователя.

Рассмотрим, что это дает. Сначала возьмем какой-нибудь запрос и выполним его просто так. Таблица хитов, данные за месяц. Считаем количество уникальных посетителей по одному сайту.
Выполнился за 4,5 секунды и скорость приличная, т. е. 3,5 гигабайта в секунду. И это на одном сервере. Но 4,5 секунды ждать не хочется.

Давайте добавим простую секцию в запросе сэмпл 1/10. Прямо после from пишем такой синтаксис. Теперь тот же самый запрос выполняется за 0,6 секунды. Если посмотреть скорость в гигабайтах в секунду, то стало почему-то меньше, всего лишь 2,5 гигабайта в секунду. Но нас это не волнует, главное не скорость, а то, чтобы запрос выполнялся за маленькое время. А с какой скоростью в байтах он читает, обрабатывает – это уже его дело. Правда, количество уникальных посетителей получилось в 10 раз меньше. И его еще надо умножить, чтобы получить приблизительный результат.

Что нужно, чтобы все это работало?
- Во-первых, ключ сэмплирования должен входить в первичный ключ. Это как в нашем примере. Последний компонент первичного ключа, после него ничего другое не имеет смысла.
- Он должен быть равномерно распределенным в своем типе данных. Типичная ошибка, если мы в качестве ключа сэмплирования возьмем unix timestamp.
- Если нарисовать график количества событий в зависимости от timestamp, то там будет вот такая штука (рисует волну, размахивая рукой в воздухе). Все, кто работал админом, DevOps, видели такой график. Это график активности по времени суток. Так нельзя, потому что неравномерно.
- Надо что-нибудь захэшировать. Если захэшировать идентификатор пользователя, то все будет прекрасно.
- Ключ сэмплирования должен быть легким как для чтения из таблицы, так и для вычисления.
- Тоже плохой пример, когда берем url, хэшируем его и этот hash используем в качестве ключа сэмплирования. Это очень плохо, потому что, если просто выполняется запрос, то все нормально. А теперь добавляется сэмпл и запрос может работать дольше, потому что вам нужно будет этот url из таблицы прочитать. А потом еще и хэшировать какой-то сложной hash-функцией.
- Возьмите в качестве ключа сэмплирования что-нибудь маленькое.
- Вот это более распространенная ошибка. Надо, чтобы ключ сэмплирования не находился после мелко-гранулированной части первичного ключа.
- Например, в первичном ключе у вас есть время с точностью до секунды. Допустим, у вас логи и это естественно. А потом вы еще добавляете какой-то hash. И это будет работать плохо, потому что ключ сэмплирования позволяет именно с диска читать мало данных. И почему это работает? Потому что данные на диске упорядочены по первичному ключу. И если есть какие-то диапазоны префикса первичного ключа, то из них можно читать меньшие поддиапазоны ключа сэмплирования. А если там эти диапазоны маленькие для каждой секунды, то из них уже нет возможности эффективно какой-нибудь кусочек прочитать, придется читать все.
- В нашем примере из Яндекс.Метрики первичный ключ – это счетчик, дата и только затем ключ сэмплирования. И для больших счетчиков есть много данных за каждую дату. И из этих данных можно выбрать меньше данных достаточно эффективно.

Посмотрим, какие есть свойства, на которые можно полагаться:
- Во-первых, сэмплирование работает детерминировано, потому что у нас там не рандом, у нас нормальная hash-функция, т. е. выполняется запрос один раз, выполняется запрос другой раз и результаты одинаковые, отчеты прыгать не будет.
- И он работает консистентно для разных таблиц. Есть у вас таблица с просмотрами страниц, есть таблица с сессиями. В них объявляете один и тот же ключ сэмплирования. И вы можете эти данные джойнить. Т. е. выбирается подмножество 1/10 всех возможных hashes от посетителей и это подмножество будет одинаковым.
- И он реально позволяет читать меньше данных с диска, если все сделать правильно.

А в качестве бонуса применять его можно разными способами:
- Самый частый – это выбираем 1/10 всевозможных данных.
- Другой способ – мы можем написать сэмпл — какое-то большое число, например, 1 000 000. И в этом случае подмножество выберется динамически. Относительный коэффициент подберется динамически, чтобы выбрать не менее, чем 1 000 000, но и не сильно больше. Правда, в этом случае будут трудности с тем, чтобы узнать, какой же относительный коэффициент сэмплирования выбрался, какая это доля данных. Т. е. это 1 000 000 строк из 10 000 000 или из 1 000 000 000? И для этого есть никому не известная возможность – это виртуальный столбец _sample_factor. И теперь вы можете написать: x умножить на _sample_factor, получится все, что нужно.
- Еще одна интересная возможность – это SAMPLE OFFSET. Это очень просто. Вы выбрали 1/10 данных, а теперь вы можете сказать: «Дайте мне, пожалуйста, вторую 1/10 данных». И для этого просто напишите: SAMPLE 1/10 OFFSET 1/10. И так можно все эти данные перебрать.
- И еще один бонус. Если у вас в таблице есть ключ сэмплирования, то вы можете теперь распараллелить запрос не только по шардам, но и по репликам каждого шарда. На разных репликах будет выбираться разный сэмпл данных так, чтобы покрыть все множество. И, соответственно, запрос будет выполняться быстрее. Или не будет? Будет, если ключ сэмплирования выбран так, что его легко читать, вычислять и это само сэмплирование, добавленное в запрос, не потребует существенного overhead.

Теперь перейдем к следующей интересной возможности – это комбинаторы агрегатных функций. Есть обычные агрегатные функции такие, как сумма, среднее, count distinct, который можно записать с помощью uniq. И этих uniq есть 4 разных варианта или даже больше.
Но к каждой агрегатной функции можно еще справа приписать такой комбинатор. Дописывается прямо в имя. Например, If. Мы вместо суммы, пишем: sumIf. И теперь это у нас агрегатная функция принимает не один аргумент, а сразу два. Первый аргумент – это то, что мы суммируем, а второй – это условие, которое возвращает какое-нибудь число типа UInt8. И там, где не нули, мы это будем суммировать. А там, где нули, все будем пропускать.

Для чего это нужно? Типичное применение – это сравнение разных сегментов. Мы это используем для сравнения сегментов в Яндекс.Метрике.
В данном запросе мы за один проход считаем количество уникальных посетителей для Яндекса и количество уникальных посетителей для Google. Очень удобно.

Другой пример комбинатора агрегатной функции – это Array. Была у вас обычная агрегатная функция, вы прописали к ней Array. И теперь у вас получилась агрегатная функция, которая принимает массив из тех типов данных, которые раньше в качестве аргумента надо было передавать. И она просто применяет для всех элементов массива.
Рассмотрим пример. Есть у нас два массива разных. И мы сначала считаем количество разных массивов, потом количество разных элементов в объединении этих массивов.
Потом есть интересная агрегатная функция groupArray, но это немножко другое. Это агрегатная функция, которая все … значения собирает в массив. Т. е. теперь у нас в результате будет многомерный массив из двух массивов.
Потом groupUniqArray. Функция собирает все уникальные значения в массив.
И еще мы к этим функциям можем приписать комбинатор Array и получится что-то такое, что сначала выглядит несколько необычно и даже неудобно, но тем не менее к этому можно привыкнуть.
Итак, что такое groupArrayArray? Это значит взять массивы, взять все элементы этих массивов, а потом собрать их в один массив. Получится один массив из всех элементов.
А groupUniqArrayArray – это тоже самое, только для разных элементов.

Посмотрим, что получилось. Кажется, получилось все верно. В одном случае количество разных массивов, в другом случае количество разных элементов, в третьем случае массивы собрали в многомерный массив, в четвертом случае разные массивы собрали в многомерный массив, а потом собрали все элементы в один массив, а потом все разные элементы собрали в один массив.

Комбинаторы агрегатных функций можно комбинировать друг с другом. Т. е. взяли агрегатную функцию sum, приписали к ней Array, а потом можно еще If приписать, а можно, наоборот. Т. е. sumArrayIf и SumIfArray.
В чем разница? В одном случае у нас будет два аргумента массива. Мы возьмем элементы этих массивов соответствующие, а массивы должны быть одинаковых длин. И один элемент – это то, что суммировать, а другое – это условие: надо ли суммировать этот элемент или не надо. Это у нас будет sumIfArray. Т. е. комбинатор Array применяется к функции sumIf и превращает оба аргумента в массивы.
А в другом случае – sumArrayIf. Первый аргумент будет массивом, а второй – это условие: нужно ли применять функцию sumArray к массиву целиком или не нужно.

А еще они могут комбинироваться так. Тут очень много комбинаторов: sumForEachStateForEachIfArrayIfState. Я не знаю, что это делает, но я написал функциональный тест на этот случай, чтобы оно работало. Оно должно работать. Если для вашей задачи это нужно, то оно будет работать.

Агрегатную функцию можно вычислять не только до конца. Есть у вас агрегатная функция, например, сумма. Вычислили, получили сумму. Все просто.
Если есть агрегатная функция среднее, то вычислили и получили среднее, но в процессе вычисления мы будем накапливать некоторые состояния и это будет два числа. Это будет сумма и количество. А потом мы делим одно на другое.
Если это количество уникальных посетителей, то там тоже будет какое-то состояние, которое может быть довольно сложным.
Какое нужно состояние, чтобы посчитать count distinct? Hash table. Вчера был замечательный доклад про hash‑таблицы и как раз на эту тему.
И это нужно для многих применений, например, для распределенной обработки запроса. В случае распределенной обработки запроса мы отправляем некоторый маленький запрос на каждый сервер и говорим: «Вычисли мне эти агрегатные функции, но не до конца, до промежуточного состояния». А потом эти промежуточные состояния будут переданы на сервер-инициатор запроса и объединены вместе.
Это внутренний механизм, но он в ClickHouse доступен и для пользователя. Если вы возьмете агрегатную функцию и добавите к ней комбинатор –State, то вы получите это промежуточное состояние. И она вам вернет значение некоторого типа, который в других базах данных не встретить, типа AggregateFunction и там какие-то параметры.
И значение этого типа можно сохранять в таблицах, т. е. вы можете создать таблицу. Там будет столбец типа AggtregateFunction. И вы там сохраните промежуточные эти состояния и можете потом их доагрегировать, например, разные поисковые фразы.
И есть комбинатор –Merge. Он делает агрегатную функцию, которая в качестве аргумента принимает эти состояния, объединяет их вместе и возвращает готовый результат.
Давайте посмотрим, что получится.

Состояния вычислений агрегатных функций
Сначала вычислим среднее и uniq из двух чисел. Ничего интересного.

А теперь вычислим состояние. Приписали комбинатор –State. И он нам вернул какую-то вещь, которой пользоваться невозможно. Какие-то бинарные данные. Половина байт не выводится в терминал, потому что терминал кодировки UTF-8. А эти бинарные данные, естественно, не UTF-8.

А какого типа эти значения? Типа AggregateFunction с аргументами. Типы у нас могут быть параметризованными. Первый параметр – это имя агрегатной функции, а остальные параметры – это типы аргументов агрегатных функций.

И можем создать таблицу с такими типами. А потом мы можем из таблицы выбрать эти значения, промежуточные состояния, все их вместе объединить и получить готовый результат. Но зачем это все нужно?

Типичный сценарий использования – это инкрементальная агрегация данных.
Я все время говорю, что ClickHouse – это такая система, для которой самый лучший сценарий работы – это работа с неагрегированными данными. Есть у вас clickstream, логи, транзакции, события мониторинга. Сохраняйте все, что есть. ClickHouse нужен для того, чтобы можно было на лету выполнять всю агрегацию максимально эффективно.
Но все не так просто. Иногда агрегировать данные все-таки полезно, ведь их становится меньше, и запрос работает быстрее.
И мы поддерживаем этот сценарий работы. Достаточно создать таблицу типа AggregatingMergeTree. Это такая таблица, в которой данные будет доагрегироваться в фоне. Вы в ней определили некоторые столбцы с промежуточными состояниями агрегатных функций. Когда вы записываете в эту таблицу, у вас какие-то куски на диске. И эти куски в фоне мержатся. И для одного значения первичного ключа все эти состояния агрегатных функций будут объединены в одно более толстое состояние, т. е. вы можете инкрементально в около реальном времени добавлять данные, обновлять ваши статистики, count distinct, квантили.
Более того, этот движок таблиц очень удобно использовать в качестве движка для материализованных представлений. Это еще одна супервозможность ClickHouse, о которой я рассказывать не буду, потому что она есть в документации.

Но есть некоторые ограничения. И что мы могли бы сделать лучше?
- Сейчас эти состояния агрегатных функций – это бинарные данные, которые не версионируются. И мы попали в ловушку, потому что мы не можем их поменять. Я уже рассказал про эту возможность, вы будете ее использовать. И было бы очень плохо, если вы обновили бы ClickHouse-сервер, и она сломалась бы. Поэтому нам придется добавить туда версионирование как можно скорее.
- И надо определять больше случаев, когда состояния, казалось бы, разных агрегатных функций, на самом деле – это одно и то же. Состояние агрегатной функции sum и sumIf – это одно и то же, но сейчас они не совместимы.
- Тут написано, что должна быть возможность создавать состояние агрегатной функции с помощью обычной функции*. Сейчас это тоже можно, если функция, например, arrayReduce. Берем массив, указываем, какая нам агрегатная функция нужна, и она передает все эти данные в агрегатную функцию, все элементы массива. И мы получаем значение агрегатной функции. А если в качестве агрегатной функции указать агрегатную функцию с комбинатором –State, то мы получим состояние.
* по состоянию на 2020 год, добавлена функция initializeAggregation.

Еще одна интересная возможность ClickHouse – это настраиваемый режим консистентности.
По умолчанию, ClickHouse реализует репликацию асинхронную, т. е. сделали INSERT, получили подтверждение, когда данные записаны на одну реплику. И данные будут реплицированы в фоне. Успешный ответ от INSERT вовсе не означает, что данные на нескольких репликах. И вовсе не означает, что данные реплицированы.
Репликация conflict-free без конфликтов по причине того, что у нас нет update. Есть INSERT. Прекрасно коммутируются друг с другом, конфликтов друг с другом быть не может.
И за счет этого она работает mulit-master. Пишите на любую реплику. Если реплика недоступна, то вы можете тот же самый блок данных повторить на другой реплику. Даже если он на самом деле был записан, есть идемпотентность, т. е. будут дедуплицированы. И таким образом вы можете добиться надежной записи с exactly-once семантикой.
Но есть проблема, которая для многих сценарий является серьезным ограничением. Это то, что после подтверждения успеха от INSERT, если реплика, на которую записана единственная и она внезапно исчезла навсегда, а данные не успели до этого отреплицироваться, то данные будут потеряны.

И специально для таких случаев у нас есть магическая настройка. Теперь можно включить строгую консистентность, а точнее линеаризуемость INSERT.
У нас даже две настройки. Одна для INSERT, а другая для SELECT, потому что они обязательно должны идти с двух сторон.
Первая настройка – это включить кворумную запись для INSERT. Минимальное количество реплик, на которые данные должны быть записаны перед тем, как клиент получит успешное подтверждение записи. Ставите insert_quorum = 2. И будет записано на две реплики.
И более того, INSERT линеаризуется в том смысле, что они будут записаны на две реплики, которые при этом содержат все предыдущие INSERT, которые тоже были записаны с кворумом.
А со стороны SELECT есть такая настройка, как select_sequential_consistency. Может быть, ее имя даже не совсем точное. Надо было ее назвать select_linearizability, но переименовывать уже поздно.
В этом случае, если вы отправите SELECT, то будет сделан запрос в метаданные в ZooKeeper. И SELECT будет разрешен только на репликах, которые консистентные, т. е. содержат все раннее подтвержденные INSERT, записанные с кворумом.
Если обратились к другой реплике, то вы получите эксепшен, и клиент должен самостоятельно обратиться к какой-нибудь другой реплике консистентной, которая будет существовать. Это несколько неудобная настройка, но все это для тех случаев, когда это вам действительно нужно.
Я включать эти настройки не рекомендую, но тем не менее для многих сценариев они полезны. И, например, мы в компании это включили, чтобы записывать данные о рекламных кликах.

Теперь рассмотрим еще одну интересную возможность. Это агрегация во внешней памяти.
В документации почти все время был такой пункт, что промежуточные данные, формирующиеся при выполнении GROUP BY, должны помещаться в оперативку на каждом шарде, участвующем на выполнении запроса, а также на сервер-инициаторе запроса. И это больше неверно, вовсе не обязано.
Рассмотрим простой запрос. Считаем разные поисковые фразы. И для каждой поисковой фразы количество просмотров страниц и количество разных посетителей. Попробуем это посчитать.
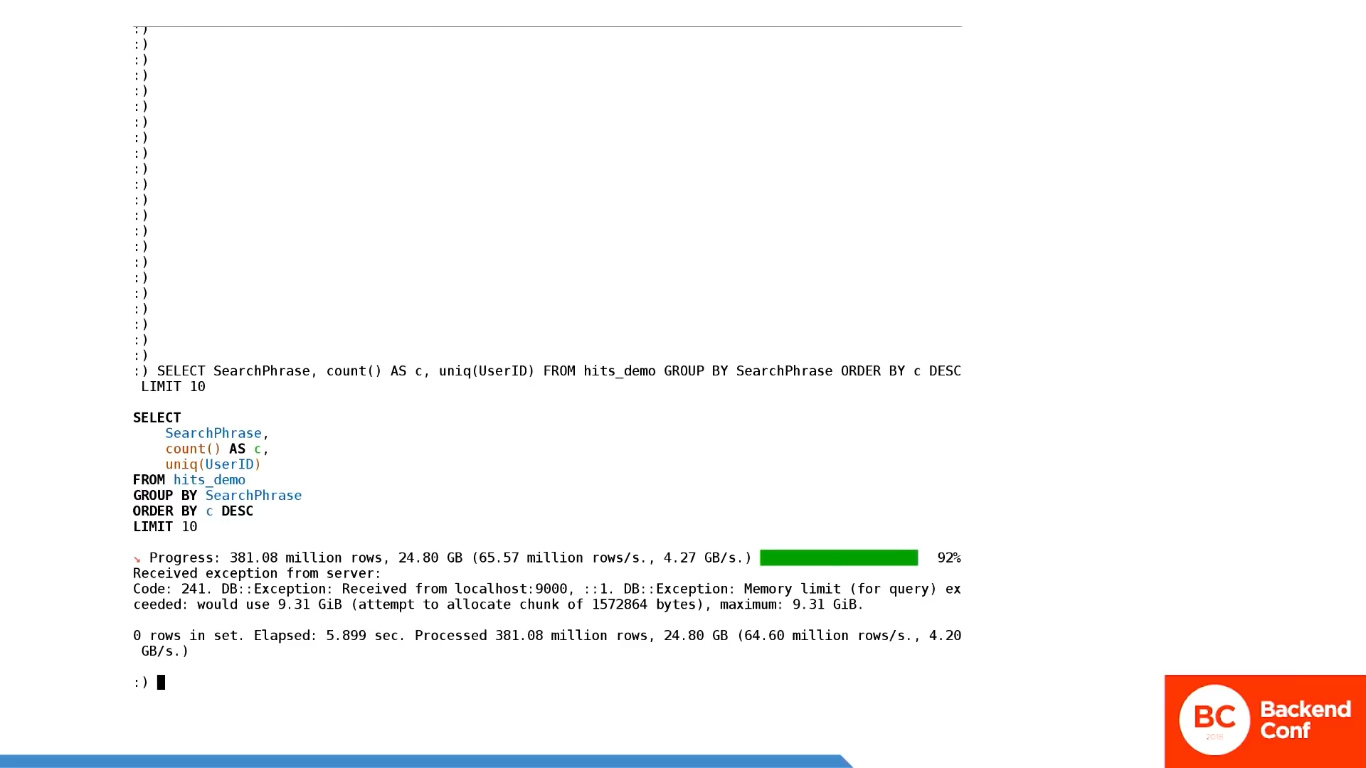
Вот он считает. Красивый progress-bar, мне он очень нравится. И ClickHouse-клиент – это тоже замечательная штука, я его очень люблю. К сожалению, он ничего не посчитал, потому что не хватило оперативной памяти. Он пишет, что для обработки этого запроса не хватило 9,31 гигабайта оперативной памяти, но это 10 млрд байт.
И первый вопрос, который стоит задать: «Почему именно 10 млрд байт?». Это по умолчанию такое ограничение. Вы можете его увеличить спокойно.

Давайте рассмотрим, почему не хватило оперативки. Посчитаем, сколько у нас данных было, сколько разных поисковых фраз. Где-то 0,5 млрд. Мы можем посмотреть на эти данные и подумать, что действительно много оперативной памяти надо, так и должно все работать.
Если у вас есть какой-то сервер, то там наверняка больше 10 гигабайтов оперативки. И, допустим, вы с этим сервером сейчас работаете один. Например, вы сидите ночью в выходные и вам очень надо посчитать какую-то аналитику.

Почему бы просто не сказать: «Давайте я увеличу max_memory_usage для себя»?
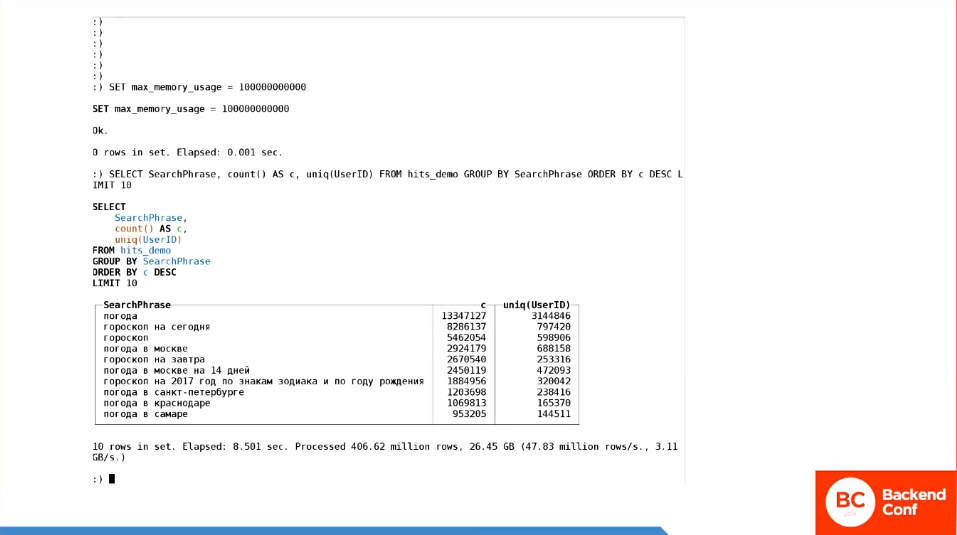
Я использую всю память на этом сервере, на всех остальных пользователей можно не обращать внимание. Вроде все нормально. Но это не тот способ, который можно использовать на production все время.

Правильный способ – это включить GROUP BY во внешней памяти. Что это значит? Это значит, что накапливаются какие-то данные в оперативке. Когда их становится много, мы их сбрасываем на диск. Потом снова накапливаются, снова сбрасываем на диск. Снова накапливаются, сбрасываем. А потом возьмем это все и будем мержить. Причем мержить будем с использованием маленького количества оперативки. Т. е. будем какие-то маленькие кусочки брать из каждого куска. И будем вот так мержить, и отдавать результат клиенту.
Есть две настройки, которые для этого предназначены:
- Первая – это максимальный объем оперативки, когда данные сбрасываются на диск.
- Вторая – это использовать эффективный по памяти merge, т. е. этот merge по кусочкам, при распределенной обработке запроса.
Обычно распределенная обработка запроса устроена так. Мы с каждого сервера весь временный dataset скачиваем по сети на сервер-инициатор запроса. Все объединяем и для этого нужна оперативка. А тут он будет скачивать эти datasets по каким-то кусочкам, по buckets. И будет объединять их в потоковом режиме.

Давайте проверим. Выставляем max_memory_usage в 10 гигабайт. Сбрасывать будем 8 гигабайт (max_bytes_before_external_group_by = 8 000 000 000, distributed_aggregation_memory_efficient = 1). И у нас progress-bar завис на какой-то момент. А потом дальше продолжил идти. Что это значит? Это значит, что именно в этот момент времени данные сбрасывались на диск. И как ни странно, запрос обработался даже не сильно дольше, чем запрос без этих настроек.
Тут есть некоторые забавные фокусы. Например, когда данные сбрасываются на диск, они на самом деле сбрасываются в файловую систему. А когда данные записываются в файловую систему, они вовсе не обязательно, что записываются на диск. Т. е. тут тоже используется оперативка, но не всегда.
И еще данные при этом жмутся, т. е. данные сбрасываются в сжатом виде. И вполне возможно, что у вас 10 гигабайтов оперативки использовалось для GROUP BY, а потом вы сжали, и получился всего 1 гигабайт.
На практике это приводит к тому, что запрос работает не более, чем в несколько раз медленнее, а в этом случае даже в полтора раза.

Давайте перейдем к следующей возможности. Это работа с географическими координатами.
Честно сказать, что ClickHouse – это не какая-то geospatial-система, но наши пользователи очень хотят складывать туда всякие координаты.
У нас в компании есть сервис – Метрика мобильных приложений. Она собирает логи. И, естественно, там есть координаты.
А что мы хотим делать с этими координатами? Конечно, мы хотим показывать рекламу. Например, вы прошли мимо какого-то магазина, но ничего не купили. А мы покажем вам объявление, что зря ничего не купили, вернитесь назад.
Что для этого нужно? Просто отфильтровать пользователей, у которых координаты в некотором полигоне.
Вот пример функции pointInPolygon. Первый аргумент – это кортеж: lat, lon, а дальше идет массив координат полигона. Этот массив должен быть константным*. Вы какую-то область этим полигоном зачеркиваете.
* по состоянию на 2020 год, поддерживаются и неконстантные полигоны тоже.
И там есть еще следующий аргумент, с помощью которого можно из этого полигона еще дырки вырезать. Даже, по-моему, много аргументов. В общем, такая продвинутая функция. И работает эффективно. Рекомендую.
Есть еще парочка функций, вместо которых я рекомендую использовать pointInPolygon, но они есть. Это pointInElliplses, которая позволяет задать несколько ellipses на координатах. Как не странно, ни на земле, ни на сфере, а просто на плоскости. И будьте осторожны, если у вас пользователи на Чукотке. Там есть этот разрыв координат. И просто вернет 0 или 1, если пользователь попал в эти ellipses.
И другая функция – это greatCircleDistance. Это расстояние на сфере*. Две точки. И считаем, сколько на сфере будет.
* по состоянию на 2020 год, присутствует также функция geoDistance, которая считает расстояние на WGS-84 эллипсоиде.

https://events.yandex.ru/lib/talks/5330/
Еще одна экспериментальная интересная вещь – это интеграция ClickHouse с моделями машинного обучения. Это не значит машинное обучение внутри ClickHouse. Это значит, что это машиннообученные модели, которые вы обучили где-то заранее. И теперь вы можете их загрузить в ClickHouse. Они будут доступны для выполнения.
Объявляются эти модели машинного обучения в некотором конфигурационном файле. Конфигурационные файлы можно обновлять налету без перезагрузки сервера. Объявляете имя, некоторые данные. И теперь они доступны в виде одной функции в виде modelEvaluate.
Первым аргументом вы передаете имя, а остальным передаете факторы, фичи для модели.
Например, вам нужно предсказать CTR или предсказать вероятность покупки. Про эту тему я подробно рассказывать не буду. Если интересует, то вот замечательная ссылка: https://events.yandex.ru/lib/talks/5330/. Там есть доклад про эту возможность и как ей пользоваться.
Сейчас у нас единственный метод машинного обучения доступен. Это CatBoost. Почему именно CatBoost? Потому что он лучше.

Что мы могли бы сделать, чтобы улучшить эту возможность?
- Часто нужно применять какие-то простые модели, но применять их много. Например, для каждого сайта какую-нибудь маленькую модель, и чтобы она быстро выполнялась. Для этого можно добавлять самые простые методы регрессии типа логистической регрессии*. И это должно соответствовать нашим принципам, что работать это должно быстро и тормозить не должно. Если какой-то сложный градиентный бустинг, то это работать будет быстро, но может быть будет тормозить. Нам этого не надо.
- Представьте, как было бы удобно, если можно было бы обучить модель в ClickHouse с агрегатной функции. Я показывал пример о промежуточном состоянии функции. А представьте, что у вас будет агрегатная функция – создать модель логистической регрессии. Вы передаете туда данные, получаете состояние, записываете в таблицу. И теперь можете взять и из этой таблицы поджоиниться, и применить это состояние в виде обычной модели. Это не то, что доступно в ClickHouse. Это мои фантазии. Но было бы круто.
- И, конечно, важно онлайн-обучение, т. е. чтобы модель сама адаптировалась к постоянно поступающим данным.
* эти методы уже добавлены в ClickHouse.

Следующая возможность тоже интересная. Это обработка данных с помощью ClickHouse без ClickHouse-сервера.
Есть у вас какая-то машина. Вы не хотите на нее ставить ClickHouse. Но у вас на ней есть какие-то логи. И вы админ.
Что вы обычно делаете? У вас обычно есть куча средств от grep, sed, awk или даже perl. И, например, вы где-то увидели, как круто в ClickHouse обрабатывать данные, можно написать запрос и не надо грепить и седить. Было бы очень заманчиво обрабатывать эти файлы с помощью ClickHouse без какой-либо загрузки, без преобразования. И такая возможность есть. Это утилита clickhouse-local.
Вы указываете некоторые параметры. Самое важное – это передать структуру, т. е. имена и типы столбцов. Это важно, потому что ClickHouse все-таки типизируемая система.
Указываете формат, в котором ваши данные лежат. Например, очень удобно, если у вас логи в JSON, то вы указываете формат JSONEachRow. Указываете запрос и прямо в stdin передаете ваши данные. И, пожалуйста, ваши данные обработаны. Конечно, это будет не так быстро, как если вы сначала все-таки загрузите данные в ClickHouse. Потому что эти данные надо будет распарсить и все, что нужно, с ними сделать. Но работать будет быстрее, чем awk, perl, sed. В некоторых случаях даже будет быстрее, чем grep, т. е. зависит от параметров.
Но если вам данные нужно обработать не один раз, а хотя бы два запроса выполнить, то, пожалуйста, не нужно мелочиться – поставьте себе ClickHouse-сервер. Много ресурсов не отнимет. И будет удобно работать.

И если у вас установлен ClickHouse-сервер, то вы можете его выключить и затем с помощью программы ClickHouse-local вы можете подключить данные, которые в нем находятся в локальной файловой системе. И обработать запросы прямо над ними, не поднимая ClickHouse-сервер для обслуживания клиентов.

Что сейчас эту возможность ограничивает? Что надо сделать, чтобы стало удобнее?
Мы сейчас весьма строги к форматам Date и DateTime. Date у нас, например, в формате ISO 8601, а в DateTime не поддерживается, чтобы можно было указать плюс-минус смещение или суффикс, или дробные секунды. И, естественно, было бы очень удобно, чтобы такая возможность была*.
И сейчас она у нас появилась, но в виде отдельной функции. Называется parseDateTimeBestEffort. И она без всяких аргументов парсит дату с временем в любом формате, кроме американского. Потому что в американском формате сначала месяц, а потом число. И можно не отличить. И если не в американском, то, пожалуйста, можно эту функцию использовать.
* а уже всё есть, смотрите настройку date_time_input_format.
Еще очень удобно было бы, если мы добавили бы такие форматы, которые более свойственны для Hadoop инфраструктуры. Чтобы вы могли запустить ClickHouse-local в качестве MapReduce jobs прямо в Hadoop.
Было бы очень хорошо, если бы мы добавили Parquet. И сейчас эта возможность появилась в виде pull request. Наверное, скоро помержим*.
* ура, помержили — теперь возможность есть!
Еще интересный вариант, если бы добавили такой формат данных, который я про себя называю trash SQL. Представьте, что вы могли бы данные разделить каким-нибудь regexp’ом на столбцы, а потом подать на вход clickhouse-local. Конечно, это можно сначала сделать с помощью Awk, но иногда было бы удобно, чтобы такая возможность была прямо внутри ClickHouse*.
* и это тоже добавили — смотрите формат Regexp.

Последний интересный пункт, о котором я хотел бы рассказать, это недавно появившаяся возможность межкластерного копирования.
В чем суть? Конфигурация кластера в ClickHouse довольно жесткая. Т. е. вы должны указать, сколько у вас шардов, сколько реплик на каждом шарде. И все прекрасно будет работать, пока вам не надо будет это перешардировать.
А как это перешардировать? Можно поднять еще один кластер рядом. Создать там такую же таблицу, а потом сделать INSERT SELECT из дистрибьютора таблицы в другой дистрибьютор таблицы. И оно поначалу будет работать. Если вам повезет, будет работать.
Но проблема в том, что это работает в один поток. Будет передавать данные через один сервер по сети. И если у вас данных достаточно, вы запустите, но оно поработает, например, недельку, а потом – сетевая ошибка и вам придется смотреть, какие данные скопировались, какие данные не скопировались. Или разделять это как-то вручную по партициям. Это неудобно.
И поэтому у нас есть специальный инструмент, который называется ClickHouse-copier. Это такая программа, которую вы можете в любом количестве экземпляров запускать на любых серверах. Она автоматически будет выбирать себе задачи и координироваться через Zookeeper. А задачи – это партиции одной таблицы на одном шарде того кластера, который вам нужно будет создать путем копирования.
Можно настроить ограничения по сетевой полосе. Можно настроить ограничения по количеству одновременных задач. И работать это будет отказоустойчиво. Серверы с этими программами могут падать, восстанавливаться.
Если какая-то партиция частично скопирована на другой сервер, то попытка скопировать будет повторяться. Какие-то частично скопированные данные удаляются и копируются заново.

И самое главное – эта возможность проверена в production.
Мы недавно завершили операцию межкластерного копирования в Яндекс.Метрике. У нас был один кластер на 538 серверов. И мы взяли другой кластер на 240 серверов. Меньше, потому что серверы более современные и туда больше помещается. Мы изменили в наших таблицах все.
Поменяли схему шардирования. Было шардирование по сайтам, сделали шардирование по пользователям. Изменили алгоритм сжатия. На старом кластере было lz4, на новом кластере zstd и запустили это все. И оно начало копировать. И у нас были проблемы, потом еще были проблемы и еще были проблемы. Мы дорабатывали ClickHouse-copier. Потому что это серьезная задача и с первого раза, конечно, ничего не работает. И где-то через месяц все скопировалось.
Когда мы копировали уже таблицу просто с просмотрами, то у нас был где-то один петабайт скопирован за неделю. И теперь можно запускать, и прямо забыть, оно свою задачу выполнит. Так что, если этим воспользовались мы, то, наверное, вы тоже сможете этим воспользоваться.
Все, спасибо!

Вопросы
Спасибо за доклад! Вопрос по поводу копира. Интересная возможность. Он в real time поддерживает дописывание данных, которые прилетели на старый кластер?
Нет. Копирует партиции, которые не изменяются.
Т. е., соответственно, когда вы копировали, вы уже читали с дистрибьютора между старым и новым кластером? Или читали только с нового кластера? Как это происходило?
Мы сделали так. Сначала в нашей программе, которая данные записывает, мы сделали так, чтобы она записывала на оба кластера. У нас на новом кластере создалась какая-то партиция за неделю или месяц. Кстати, схему партиционирования мы тоже поменяли. И она создалась неполной. Следующие партиции уже были с полными данными. Мы запустили копирование вплоть до этой последней неполной партиции. И этот копировальщик эти данные неполной партиции заменил на те данные, которые были на старом кластере. Т. е. теперь у нас есть бесшовные данные и мы может отключить запись на старый кластер. Но мы это делать не будем, потому что мы создали новый кластер для других задач. Мы на нем будем обрабатывать тяжелые аналитические запросы.
Т. е. как раз тестировать ClickHouse?
Нет, не для тестирования ClickHouse. У нас для разных сценариев нагрузки он. Т. е. если идут тяжелые запросы от внутренних аналитиков, они будут идти на новый кластер. И это очень удобно, потому что там данные не по счетчикам разбиты, а по пользователям. И эти запросы смогут использовать ресурсы всего кластера, если, скажем, обрабатывают запросы для рунета за день.
Здравствуйте! Раз вы уже смотрите на Avro, на Parquet, на замену MapReduce и machine learning, то есть какие-то наработки для того, чтобы запускать ClickHouse как какие-то jobs под управлением YARN, под управлением Mesos? Т. е. чтобы запускались так же, как Spark, шедулилось на кластер, запускалось рядом с данными, где лежат уже на конкретных нодах с хорошей date locality и вот это все было рядышком, все быстро обрабатывалось?
Да, такие планы есть, но с ними есть одна очень серьезная проблема, которая именно для вас очень серьезная. Дело в том, что в Яндексе не используется Hadoop и есть своя реализация MapReduce под называнием YT. И люди сделали так, чтобы ClickHouse запускался внутри YT, сам обрабатывал данные в его формате, передавал их друг с другом для распределенных запросов. Сделает ли это кто-нибудь для распространенных систем, это еще вопрос.
Понятно. Т. е. внутри Яндекса такие наработки по поводу применения на YT и запуск под конкретный ресурс-менеджер на кластере уже есть? Т. е. то, что уже не конкретно на каждой ноде установлен ClickHouse, а это уже как tool для обработки CSV уже распространяется в виде job?
У нас внутри компании эта задача находится в стадии эксперимента на последней стадии разработки*. И там сейчас сделано так, что какая-то часть кластера выделается. И на этой части кластера запускаются не ClickHouse-сервер, а какой-то другой бинарник, который содержит и ClickHouse, и часть YT. И оно все это читает и обрабатывает.
* уже в продакшене.
Спасибо за доклад! ClickHouse-local существует только в виде бинарника или есть еще какие-то модули для каких-нибудь языков или его куда-нибудь встраивать можно, например?
Встраивать нельзя, только как standalone-приложение. Единственный бонус – он встроен прямо в ClickHouse. Т. е. есть общий бинарник ClickHouse, там и сервер, и клиент, и local, и все, что угодно.
Спасибо! И второй вопрос есть. groupUniqArrayArray он не order делает, он их в рандомном порядке берет?
Да, в недетерминированном порядке, в зависимости оттого, в каком порядке данные обрабатываются на разных шардах и разных потоках.
Привет! Спасибо за доклад! У меня была практическая проблема с ClickHouse. Она немножко надуманная. Данные до этого лежали в Vertica. Люди там пытались писать запрос, но это все ужасно тормозило. Что я сделал? Я их выгрузил в CSV. Из CSV загрузил в ClickHouse. В ClickHouse заджойнил уже в другую таблицу, в которой все было в денормализованном виде. Но уже по ней запросы шли быстро. Проблемы была только в том, что если ты хочешь это все заджойнить, то тебе нужно очень много памяти, чтобы весь запрос в память влез. Я ничего лучшего не придумал, кроме, как еще памяти докинуть на этот момент. Но можно ли это как-то было решить другим путем?
Есть ли возможность в ClickHouse выполнить JOIN так, чтобы необязательно правая таблица или результат правого подзапроса помещался в оперативку? Пока нет*. Пока в ClickHouse реализован hash JOIN, т. е. правый результат, правая часть должна помещаться в эту hash-таблицу в оперативке. Но у нас есть план это изменить. Эти планы довольно серьезные. Правда, их серьезность в том числе связана еще и с тем, что это будет не так-то просто сделать. Для этого придется серьезно менять конвейер выполнения запросов, чтобы реализовать merge JOIN, чтобы он работал нормально, и в том числе в распределенном случае.
* уже да, смотрите настройку join_algorithm. И конвейер, кстати, тоже переписали.
Спасибо! Если или, когда появятся апдейты, то будет ли еще master-master репликация, если да, то, как? Если нет, то что надо делать, чтобы она работала?
По этому вопросу можно сказать – ура, потому что сейчас апдейты находятся в pull request. Мы их планируем домержить в мастер на этой неделе. Я сейчас здесь стою, а другие люди в офисе мержат. Master-master репликация продолжит работать. Во-первых, все операции в ClickHouse линеаризуются с помощью ZooKeeper. Там есть полный порядок этих операций. Если вы будете выполнять апдейты конкурентно на разных репликах, то, соответственно, в каком-то порядке они дойдут и в каком-то порядке выполнятся.
Здравствуйте! Спасибо за доклад! Поможет ли ClickHouse-copier решить задачу, когда необходимо вывести из шарда реплику и на новую реплику этого шарда скопировать данные, например, для проведения работ?
Для этой задачи ClickHouse-copier не нужен, потому что это очень простая задача и типичная operation-вещь. Вы просто создаете новую реплику. У вас, допустим, было две реплики, вы создаете новую. И теперь три реплики. Старую теперь можно удалять. Или одна реплика была, вы создаете новую. И она наливает сама данные. Самое главное, если у вас сервис с репликой с концами исчез куда-то, т. е. его больше нет, то надо удалить метаданные этой исчезнувшей реплики из ZooKeeper. Там есть особенность – накапливаются логи репликации и поэтому будут проблемы*.
* уже исправлено, теперь не накапливаются.

