В мае 2017 мы, команда Manticore Software, сделали форк Sphinxsearch 2.3.2, который назвали Manticore Search. Ниже вы найдёте краткий отчёт о проделанной работе за три с половиной года, прошедших с момента форка.
Зачем был нужен форк?
Прежде всего, зачем мы сделали форк? В конце 2016 работа над Sphinxsearch была приостановлена. Пользователи, которые пользовались продуктом и поддерживали развитие проекта волновались, так как:
баги не фиксились
новые фичи, которые были давно обещаны не производились
коммуникация с командой Sphinx была затруднена.
По прошествии нескольких месяцев ситуация не поменялась и в середине июня группа инициативных опытных пользователей и клиентов поддержки Sphinx собрались, и было принято решение попытаться сохранить продукт в виде форка, под именем Manticore Search. Удалось собрать большую часть команды Sphinx (а именно тех, кто занимался непосредственно разработкой и поддержкой пользователей), привлечь инвестиции и в короткие сроки восстановить полноценную работу над проектом.
Чего мы хотели добиться?
Целей у форка было три:
Поддержка кода в целом: багфиксинг, мелкие и крупные доработки
Поддержка пользователей Sphinx и Manticore
И, по возможности, более интенсивное развитие продукта, чем это было раньше. К большому сожалению, на момент форка Elasticsearch уже много лет как обогнал Sphinx по многим показателям. Такие вещи, как:
отсутствие репликации
отсутствие auto id
отсутствие JSON интерфейса
невозможность создать/удалить индекс на лету
отсутствие хранилища документов
слаборазвитые real-time индексы
фокусировка на полнотекстовом поиске, а не поиске в целом
делали Sphinx очень узкоспециализированным решением с необходимостью доработки его напильником во многих случаях. Многие пользователи к тому моменту уже мигрировали на Elasticsearch. Это было очень досадно, так так фундаментальные структуры данных и алгоритмы в Sphinx потенциально и фактически во многих случаях превосходили Elasticsearch по производительности, а SQL, который в Sphinx был развит намного лучше, чем в Elasticsearch даже сейчас, был привлекателен для многих.
Кроме поддержки имеющихся пользователей Sphinx, глобальной целью Manticore была доработка вышеупомянутых и других характеристик, которые позволили бы сделать Manticore Search реальной альтернативой Elasticsearch в большинстве сценариев использования.
Что нам удалось сделать?
Намного более активная разработка
Если посмотреть на статистику гитхаба, то видно, что как только случился форк (середина 2017-го) разработка активизировалась:
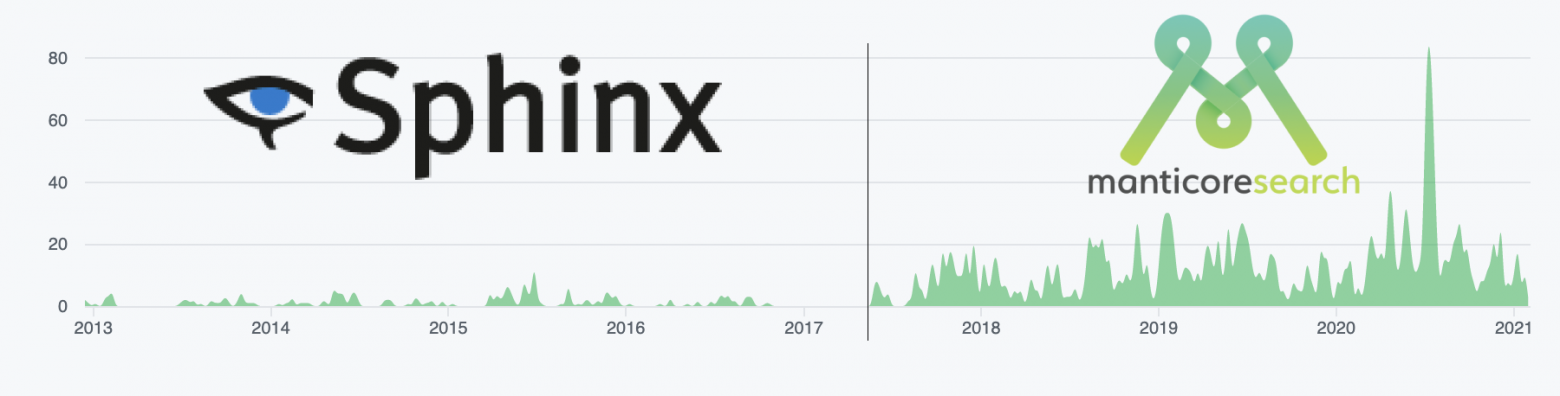
За три с половиной года мы выпустили 39 релизов. В 2020 году выпускались примерно каждые два месяца. Так и планируем продолжать.
Репликация
Многие пользователи ждали репликации в Sphinx много лет. Одной из первых крупных фичей, которые мы сделали в Manticore была репликация. Как и всё в Мантикоре, попытались сделать её максимально простой в использовании. Например, чтобы подключиться к кластеру достаточно выполнить команду:
JOIN CLUSTER posts at '127.0.0.1:9312';
, после чего в текущем инстансе появятся индексы из кластера. Репликация:
синхронная
основана на библиотеке Galera, которую так же используют MariaDB и Percona XtraDB.
Auto id
Без auto-id Sphinx / Manticore за исключением редких случаев можно использовать только как приложение к внешнему хранилищу документов и источнику ID. Мы реализовали auto-id на основе алгоритма UUID_SHORT. Гарантируется уникальность до 16 миллионов инсертов в секунду на сервер.
mysql> create table idx(doc text); Query OK, 0 rows affected (0.01 sec) mysql> insert into idx(doc) values('abc def'); Query OK, 1 row affected (0.00 sec) mysql> select * from idx; +---------------------+---------+ | id | doc | +---------------------+---------+ | 1514145039905718278 | abc def | +---------------------+---------+ 1 row in set (0.00 sec) mysql> insert into idx(doc) values('def ghi'); Query OK, 1 row affected (0.00 sec) mysql> select * from idx; +---------------------+---------+ | id | doc | +---------------------+---------+ | 1514145039905718278 | abc def | | 1514145039905718279 | def ghi | +---------------------+---------+ 2 rows in set (0.00 sec)
Хранилище документов
В Sphinx 2.3.2 и ранее хранить исходные тексты можно было только в строковых атрибутах. Они, как и все атрибуты требуют памяти. Многие пользователи так и делали, расходуя лишнюю память, что на больших объёмах было дорого и чревато другими проблемами. В Manticore мы сделали новый тип данных text, который объединяет полнотекстовую индексацию и хранение на диске с отложенным чтением (т.е. значение достаётся на самой поздней стадии выполнения запроса). По "stored" полям нельзя фильтровать, сортировать, группировать. Они просто лежат на диске в сжатом виде, чтоб не было нужды хранить их в mysql/hbase и прочих БД, когда это совсем не нужно. Фича оказалась очень востребованной. Теперь Manticore не требует ничего, кроме самой себя для реализации поискового приложения.
mysql> desc idx; +-------+--------+----------------+ | Field | Type | Properties | +-------+--------+----------------+ | id | bigint | | | doc | text | indexed stored | +-------+--------+----------------+ 2 rows in set (0.00 sec)
Real-time индексы
В Sphinx 2.3.2 и ранее многие пользователи опасались использовать real-time индексы, т.к. это часто приводило к крэшам и другим побочным эффектам. Большую часть известных багов и недоработок мы устранили, над некоторыми оптимизациями ещё работаем (в основном связанным с автоматически OPTIMIZE). Но можно с уверенностью сказать, что real-time индексы можно использовать в проде, что многие пользователи и делают. Из наиболее заметных фичей добавили:
многопоточность: поиск в нескольких дисковых чанках одного real-time индекса делается параллельно
оптимизации OPTIMIZE: по умолчанию чанки мерджатся не до одного, а до кол-ва ядер на сервере * 2 (регулируется через опцию cutoff)
Работаем над автоматическим OPTIMIZE.
charset_table = cjk, non_cjk
Раньше, если требовалась поддержка какого-то языка кроме русского и английского часто нужно было поддерживать длинные массивы в charset_table. Это было неудобно. Мы попытались это упростить, собрав всё, что может понадобиться во внутренние массивы с алиасами non_cjk (для большинства языков) и cjk (для китайского, корейского и японского). И сделали non_cjk настройкой по умолчанию. Теперь можно без проблем искать по русскому, английскому и, скажем, турецкому:
mysql> create table idx(doc text); Query OK, 0 rows affected (0.01 sec) mysql> insert into idx(doc) values('abc абв öğrenim'); Query OK, 1 row affected (0.00 sec) mysql> select * from idx where match('abc'); +---------------------+----------------------+ | id | doc | +---------------------+----------------------+ | 1514145039905718280 | abc абв öğrenim | +---------------------+----------------------+ 1 row in set (0.00 sec) mysql> select * from idx where match('абв'); +---------------------+----------------------+ | id | doc | +---------------------+----------------------+ | 1514145039905718280 | abc абв öğrenim | +---------------------+----------------------+ 1 row in set (0.00 sec) mysql> select * from idx where match('ogrenim'); +---------------------+----------------------+ | id | doc | +---------------------+----------------------+ | 1514145039905718280 | abc абв öğrenim | +---------------------+----------------------+ 1 row in set (0.00 sec)
Официальный Docker image
Выпустили и поддерживаем официальный docker image . Запустить Manticore теперь можно за несколько секунд где угодно, если там есть докер:
➜ ~ docker run --name manticore --rm -d manticoresearch/manticore && docker exec -it manticore mysql && docker stop manticore 525aa92aa0bcef3e6f745ddeb11fc95040858d19cde4c9118b47f0f414324a79 mysql> create table idx(f text); mysql> desc idx; +-------+--------+----------------+ | Field | Type | Properties | +-------+--------+----------------+ | id | bigint | | | f | text | indexed stored | +-------+--------+----------------+
Кроме того, в manticore:dev всегда лежит самая свежая development версия.
Репозиторий для пакетов
Релизы и свежие development версии автоматически попадают в https://repo.manticoresearch.com/
Оттуда же можно легко установить Manticore через YUM и APT. Homebrew тоже поддерживаем, как и сборку под Мак в целом.
NLP: обработка естественного языка
По NLP сделали такие улучшения:
сегментация китайского с помощью библиотеки ICU
стоп-слова для большинства языков из коробки:
mysql> create table idx(doc text) stopwords='ru'; Query OK, 0 rows affected (0.01 sec) mysql> call keywords('кто куда пошёл - я не знаю', 'idx'); +------+------------+------------+ | qpos | tokenized | normalized | +------+------------+------------+ | 3 | пошел | пошел | | 6 | знаю | знаю | +------+------------+------------+ 2 rows in set (0.00 sec)поддержка Snowball 2.0 для стемминга большего количества языков
более лёгкая в плане синтаксиса подсветка:
mysql> insert into idx(doc) values('кто куда пошёл - я не знаю'); Query OK, 1 row affected (0.00 sec) mysql> select highlight() from idx where match('пошёл'); +------------------------------------------------------+ | highlight() | +------------------------------------------------------+ | кто куда <b>пошёл</b> - я не знаю | +------------------------------------------------------+ 1 row in set (0.00 sec)
Новая многозадачность
Упростили многозадачность за счёт использования корутин. Кроме того, что код стал намного проще и надёжнее, для улучшения распараллеливания теперь не нужно выставлять dist_threads и думать какое значение поставить какому индексу, чтобы поиск по нему максимально оптимально распараллеливался. Теперь есть глобальная настройка threads, которая по умолчанию равна количеству ядер на сервере. В большинстве случаев для оптимальной работы вообще трогать ничего не нужно.
Поддержка OR в WHERE
В Sphinx 2/3 нельзя легко фильтровать по атрибутам через ИЛИ. Это неудобно. Сделали такую возможность в Manticore:
mysql> select i, s from t where i = 1 or s = 'abc'; +------+------+ | i | s | +------+------+ | 1 | abc | | 1 | def | | 2 | abc | +------+------+ 3 rows in set (0.00 sec) Sphinx 3: mysql> select * from t where i = 1 or s = 'abc'; ERROR 1064 (42000): sphinxql: syntax error, unexpected OR, expecting $end near 'or s = 'abc''
Поддержка протокола JSON через HTTP
SQL - это круто. Мы любим SQL. И в Sphinx / Manticore всё, что касается синтаксиса запросов можно сделать через SQL. Но бывают ситуации, когда оптимальным решением является использование JSON-интерфейса, как, например, в Elasticsearch. SQL крут для дизайна запроса, а используя JSON сложный запрос часто легче интегрировать с приложением.
Кроме того, HTTP сам по себе позволяет делать интересные вещи: использовать внешние HTTP load balancer'ы, proxy, что позволяет довольно-таки несложно реализовать аутентификацию, RBAC и прочее.
Новые клиенты для большего количества языков
Ещё легче может быть использовать клиент для конкретного языка программирования. Мы реализовали новые клиенты для php, python, java, javascript, elixir, go. Большинство из них основаны на новом JSON-интерфейсе и их код генерируется автоматически, что позволяет добавлять новые фичи в клиенты намного быстрее.
Поддержка HTTPS
Сделали поддержку HTTPS из коробки. Светить Мантикорой наружу всё ещё не стоит, т.к. встроенных средств аутентификации нет, но гонять трафик от клиента к серверу по локальной сети теперь можно безопасно. SSL для mysql-интерфейса тоже поддерживается.
Поддержка FEDERATED
Вместо SphinxSE (встроенный в mysql движок, который позволяет теснее интегрировать Sphinx/Manticore с mysql) теперь можно использовать FEDERATED.
Поддержка ProxySQL
И ProxySQL тоже можно.
RT mode
Одним из главных изменений стало то, что мы сделали императивный (т.е. через CREATE/ALTER/DROP table) способ работы со схемой данных Manticore дефолтным. Как видно из примеров выше - о конфиге, source, index и прочем речи теперь в большинстве случаев не идёт. С индексами можно полноценно работать без необходимости править конфиг, рестартить инстанс, удалять файлы real-time индексов и т.д. Схема данных теперь отделена от настроек сервера полностью. И это режим по-умолчанию.
Но декларативный режим всё так же поддерживается. Мы не считаем его рудиментом и не планируем от него избавляться. Как с Kubernetes можно общаться и через yaml-файлы и через конкретные команды, так и c Manticore:
можно описать всё в конфиге и пользоваться возможностью лёгкого его портирования и т.д.,
а можно создавать индексы на лету
Смешивать использование режимов нельзя и не планируется. Чтобы как-то обозначить режимы, мы назвали декларативный режим (как в Sphinx 2) plain mode, а императивный режим RT mode (real-time mode).
Percolate index
Решили задачу обратного поиска, когда в индексе лежат запросы, а документы поступают в запросах. Работает шустро по сравнению с эластиком.
mysql> create table t(f text, j json) type='percolate'; mysql> insert into t(query,filters) values('abc', 'j.a=1'); mysql> call pq('t', '[{"f": "abc def", "j": {"a": 1}}, {"f": "abc ghi"}, {"j": {"a": 1}}]', 1 as query); +---------------------+-------+------+---------+ | id | query | tags | filters | +---------------------+-------+------+---------+ | 8215503050178035714 | abc | | j.a=1 | +---------------------+-------+------+---------+
Новая удобная документация
Полностью переработали документацию - https://manual.manticoresearch.com
Для ключевой функциональности есть примеры для большинства поддерживаемых клиентов. Поиск работает так же через Manticore. Удобная умная подсветка в результатах поиска. HTTP примеры можно копировать одним кликом прямо в в виде команды curl с параметрами. Кроме того, специально зарегистрировали короткий домен mnt.cr, чтоб можно было очень быстро найти информацию по какой-то настройке, детали по которой подзабылись, например: mnt.cr/proximity , mnt.cr/quorum, mnt.cr/percolate
Интерактивные курсы
Сделали платформу для интерактивных курсов https://play.manticoresearch.com и, собственно, сами курсы, с помощью которых можно ознакомиться с работой Manticore прямо из браузера, вообще ничего не устанавливая. Проще уже, по-моему, некуда, хотя мы стараемся всё сделать максимально просто для пользователя.
Github в качестве bug tracker'а
В качестве публичного bug/task tracker'а используем Гитхаб.
Есть же Sphinx 3
В декабре 2017 года был выпущен Sphinx 3.0.1. До октября 2018 было сделано ещё три релиза и ещё один в июле 2020-го (3.3.1, последняя версия на момент февраля 2021). Появилось много интересных фич, в том числе вторичные индексы и интеграция с machine learning, которая позволяет решать некоторые задачи, требующие подходов машинного обучения. В чём же проблема? На кой вообще нужен этот ваш Manticore? Одной из причин является то, что к сожалению, ни первый релиз Sphinx 3, ни последний на текущий момент не open source:
в том смысле, что код Sphinx 3 недоступен
а также в более широком понимании open source. Cказано, что с версии 3.0 Sphinx теперь доступен под лицензией "delayed FOSS". Что именно это за лицензия и где можно с ней ознакомиться не разглашается. Непонятно:
то ли оно всё ещё GPLv2 (т.е. под "delayed FOSS" подразумевается отложенный GPLv2), т.к. код вероятно основан на Sphinx 2, который GPLv2 (как и Manticore). Но где тогда исходный код?
то ли нет, т.к. никакой лицензии к бинарным файлам не прилагается. И основан ли код вообще на Sphinx 2, который GPLv2? И действуют ли ограничения GPLv2? Или можно уже распространять исполняемые файлы sphinx 3 без оглядки на GPL? "delayed FOSS" за отсутствием какого-либо текста лицензии это ведь не запрещает.
релизов не было с июля 2020. Багов много. Когда они будут фикситься?
Вопросов много. Ответов нет. Всё это делает крайне затруднительным использование Sphinx 3 людьми и компаниями, которым важна юридическая сторона вопроса и стабильность проекта. Не все имеют возможность вкладывать время своих сотрудников во что-то настолько непонятное.
В общем и целом, Sphinx 3 сейчас можно воспринимать как проприетарное решение для ограниченного круга пользователей с ограниченными целями. Очень жаль, что open source мир потерял Sphinx. Можно только надеяться, что в будущем что-то поменяется.
Побенчим?
Дано:
датасет, состоящий из 1M+ комментов с HackerNews с численными атрибутами
plain index из этого датасета. Размер файлов индекса около 1 гигабайта
набор разнообразных запросов (132 запроса) от различных вариантов полнотекстового поиска до фильтрации и группировки по атрибутам
запуск в докере в равнозначных условиях на пустой железной машине с различными ограничениями по памяти (через cgroups)
запрос через SQL протокол клиентом mysqli из PHP-скрипта
перед каждым запросом перезапуск докеров с предварительной очисткой всех кэшей, далее 5 попыток, в статистику попадает самая быстрая
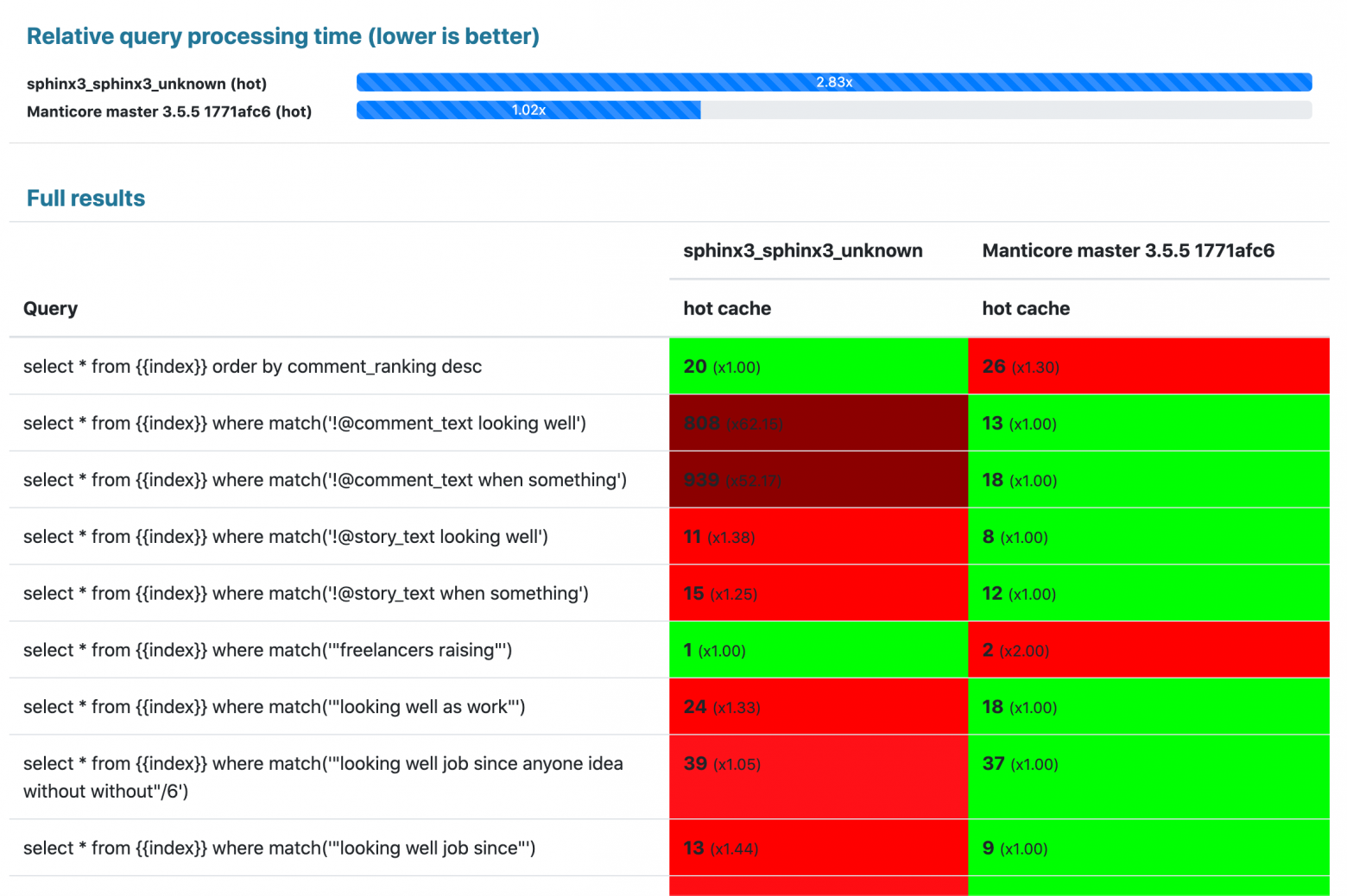
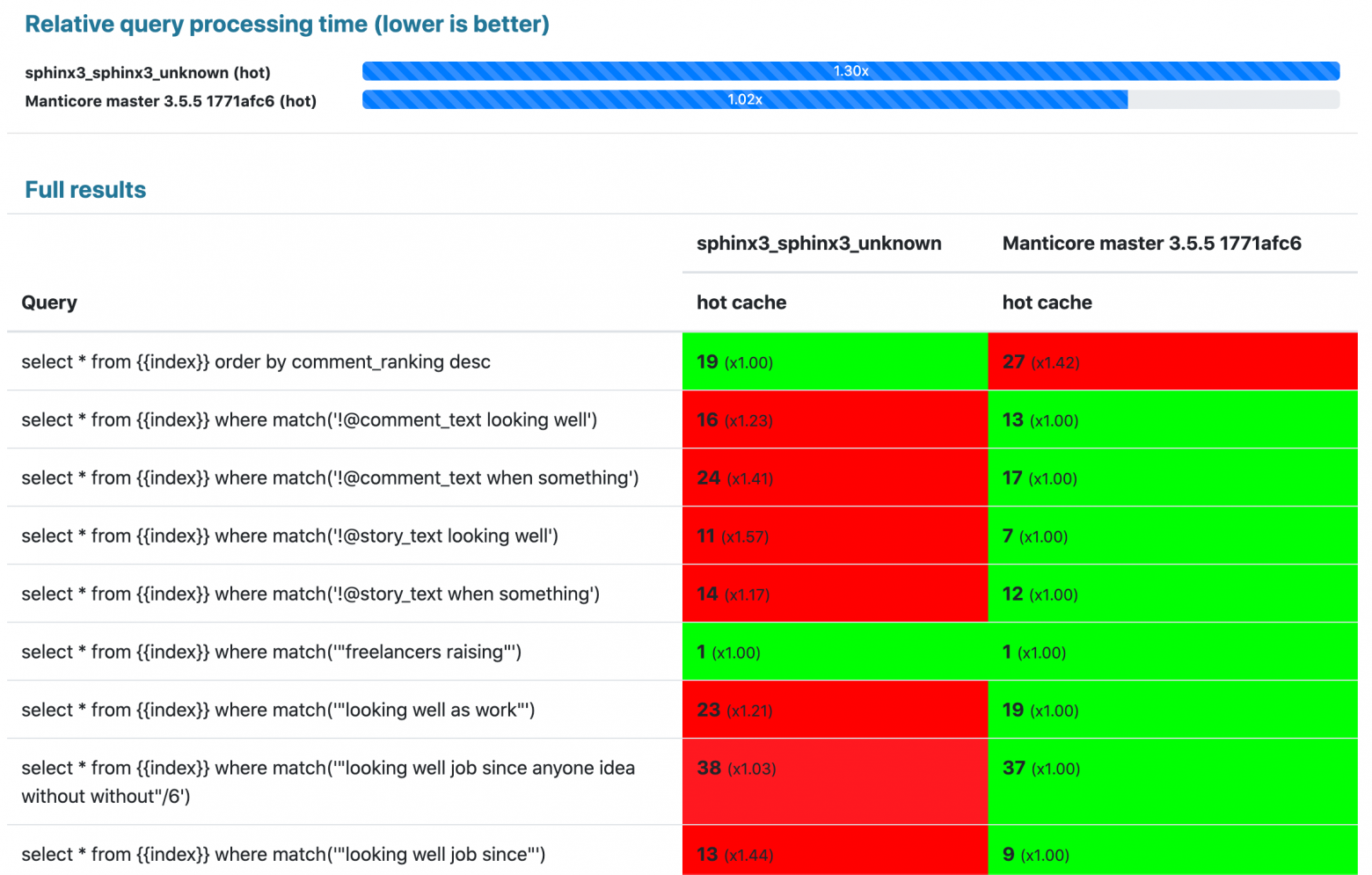
Результаты:
Лимит памяти 100 мегабайт:
500 мегабайт:
1000 мегабайт:

Будущее Manticore Search
Итак, у нас уже есть активно разрабатываемый продукт под всем понятной open source лицензией GPLv2 с репликацией, auto-id, нормально работающими real-time индексами, JSON интерфейсом, адекватной документацией, курсами и многим ещё чем. Что дальше? Роадмэп у нас такой:
Новый Manticore engine
С начала 2020 года мы работаем над библиотекой хранения и обработки данных в поколоночном виде с индексацией по умолчанию (в отличие от, скажем, clickhouse). Для пользователей Manticore / Sphinx это решит проблемы:
необходимости большого объёма свободной памяти при большом количестве документов и атрибутов
не всегда быстрой группировки
У нас уже готова альфа-версия и вот, например, какие получаются результаты, если использовать её в Manticore Search и сравнить её производительность на том же датасете с Elasticsearch (исключая полнотекстовые запросы, т.е. в основном группировочные запросы):

Но работы всё ещё много. Библиотека будет доступна под permissive open source лицензией и её можно будет использовать как в Manticore Search, так и в других проектах (может быть и в Sphinx).
Auto OPTIMIZE
Доделываем, надеемся выложить в марте.
Интеграция с Kibana
Так как с новым Manticore engine можно делать больше аналитики, то встаёт вопрос как это лучше визуализировать. Grafana - круто, но для полнотекста надо что-то придумывать. Kibana - тоже норм, многие знают и используют. У нас готова альфа версия интеграции Manticore с Кибаной. Работать будет прямо из коробки. Отлаживаем.
Интеграция с Logstash
JSON протокол у нас уже есть. В планах немного доработать его методы PUT и POST до совместимости с Elasticsearch в плане INSERT/REPLACE запросов. Кроме того, планируем разработку создания индекса на лету на основе первых вставленных в него документов.
Всё это позволит писать данные в Manticore Search вместо Elasticsearch из Logstash, Fluentd, Beats и им подобных.
Автоматическое шардирование
Проектируем. Уже понимаем с какими сложностями придётся столкнуться и более-менее как их решать. Планируем на второй квартал.
Альтернатива Logstash?
Logstash требует от пользователя потратить много времени для того, чтобы начать обрабатывать новый кастомный тип лога вашего приложения. А если добавите какую-нибудь строчку, то правила парсинга придётся поменять. Мы разрабатываем систему автоматического парсинга логов, которая позволяет разбить лог на составляющие с достаточной точностью для того, чтобы использовать полученные структурированные документы для фильтрации по полям, сортировки, группировки, а не только полнотекстового поиска по логам. Альфа-версия тоже имеется и в принципе задачу решает, но работы по окультуриванию её предстоит ещё много.
Если вам небезразличен проект, присоединяйтесь:
Будем рады любой критике. Оревуар!

