Попытка интересная, но очень много смеси тёплого с мягким.
Например, посмотрим на модель данных. «Data warehouse» – это что за модель? В большинстве случаев хранилище данных – это реляционная СУБД.
«Решаемая проблема» в классификации по модели данных – тоже несколько надумана. Очевидно, что реляционная модель лучшая, а другие модели – плата за какие-то дополнительные возможности. Та же Cassandra не реляционная не потому, что её модель удобнее, а потому, что сделать такую же распределённую БД реляционной не так-то просто.
«Scale» – это хорошо, но правильнее делить БД на монолитные и распределённые. Из этого следуют все принципиальные отличия.
Приятно изучать такую эффектно выглядящую и профессионально составленную диаграмму! Я так и вижу, как можно успешно продать российскому бизнесу внедрение какого-либо решения с помощью ее презентации.
Ваша классификация подробная и понятная, даже если исключить конкретные реализации (которые, развиваясь, со временем могут перемещаться по диаграмме), можно проводить по ней сессии обмена знаниями в коллективе…
Интересно, с какой практической целью Вы составили эту диаграмму? Как Вы ее используете?
Эта диаграмма – часть учебного курса, сделанного по заказу Большой Корпорации.
Конкретные реализации на ней – самое важное, чтобы понимать, что классификация практическая, а не только теоретическая. Но Вы правы, спорить о том, куда поместить ту или иную иконку, можно долго :)
Пока не планирую. Может слишком много текста получиться… Мне понравилась книга «Designing Data Intensive Applications» автора Martin Kleppmann, в ней довольно хорошо разбирается почти все из моих диаграмм

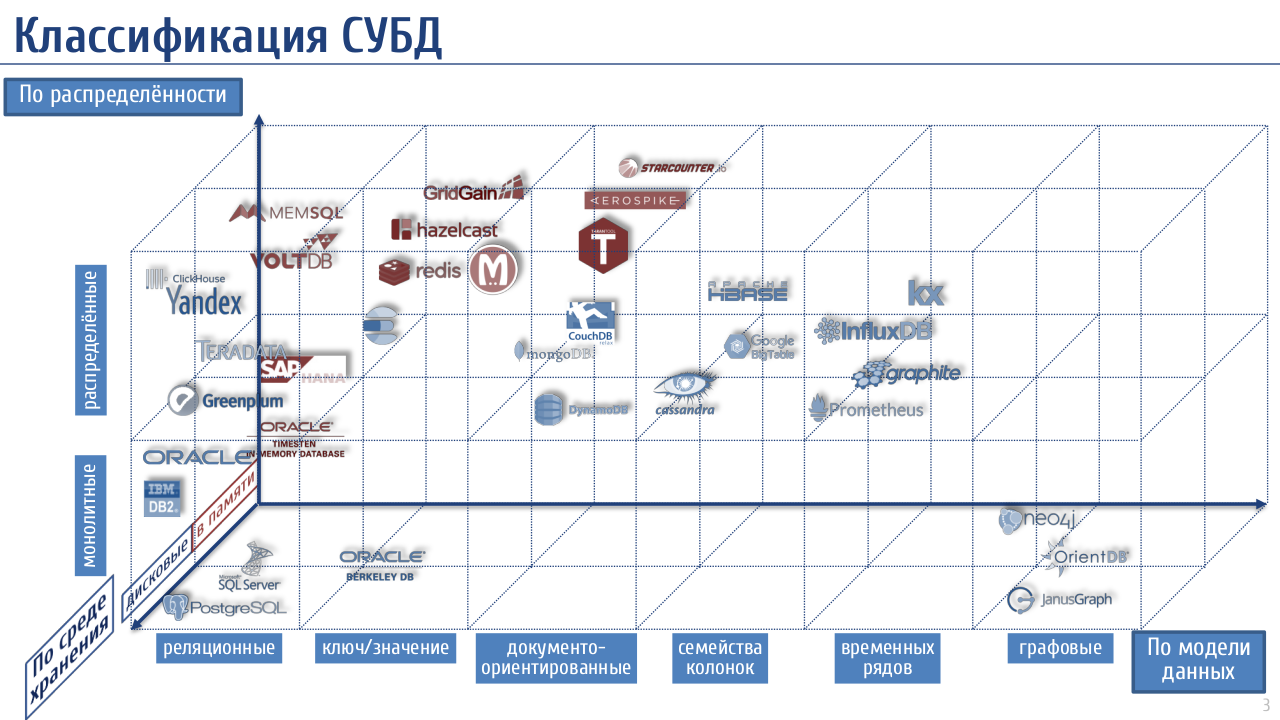
Сборник диаграмм классификаций баз данных