Модели обработки естественного языка (Natural language processing, NLP) на основе архитектуры Трансформеров, такие как BERT, RoBERTa, T5 или GPT3, успешно применяются в самых различных задачах и являются стандартом современных исследований в области NLP. Гибкость (универсальность) и надёжность Трансформеров способствовали их широкому распространению, что, в свою очередь, позволило легко адаптировать подобные модели для разнообразных задач обработки текстовых последовательностей, как в качестве seq2seq моделей для перевода, суммаризации, генерации текста и т.д., так и как самостоятельного энкодера для анализа тональности, частеречной разметки, машинного чтения и др. Главным изобретением Трансформеров стал механизм внутреннего внимания, который подсчитывает метрику схожести для всех возможных пар токенов входной последовательности независимо (параллельно), что позволяет избежать последовательной зависимости рекуррентных нейронных сетей. Благодаря этому механизму Трансформеры существенно превосходят более ранние модели обработки текстовых последовательностей, такие как LSTM.
Однако модели на основе Трансформеров и их производные имеют свои ограничения. Так, механизм внутреннего внимания требует вычислений, квадратичных длине входной последовательности. С нынешними мощностями и размерами моделей это обычно ограничивает входную последовательность до 512 токенов и не позволяет напрямую применять Трансформеры к задачам, требующим большего контекста, таким как вопросно-ответные системы, суммаризация документов или классификация фрагментов генома. Естественным образом возникает два вопроса:
- Можно ли достичь тех же эмпирических результатов, что и традиционные «квадратичные» Трансформеры, но используя разреженные модели, у которых требования к вычислительной мощности и памяти возрастают линейно с увеличением входной последовательности?
- Можно ли теоретически обосновать то, что эти «линейные» Трансформеры сохраняют выразительность и гибкость своих «квадратичных» собратов?
На оба эти вопроса авторы постарались ответить в своих недавних статьях. Так, в «ETC: Encoding Long and Structured Inputs in Transformers», представленной на конференции EMNLP 2020, было предложено построение расширенного Трансформера (Extended Transformer Construction, ETC) – новый метод разреженного внимания, в котором используется информация о структуре данных для ограничения числа подсчитываемых пар оценок сходства (similarity score). Это позволяет привести квадратичную зависимость к линейной и получить хорошие эмпирические результаты в NLP задачах. Затем в статье «Big Bird: Transformers for Longer Sequences», представленной на конференции NeurIPS 2020, авторы предложили другой метод разреженного внимания – BigBird, который позволяет использовать технологию ETC для более общих сценариев, характеризующихся недоступностью предварительного знания о структуре данных той или иной предметной области. Авторы также теоретически доказали, что предложенный механизм разреженного внимания сохраняет выразительность и гибкость традиционного «квадратичного» Трансформера. Предложенные методы задают новую планку качества для задач обработки длинных последовательностей, включая вопросно-ответные системы, суммаризацию документов и классификацию фрагментов генома.
Внимание – это граф
Модуль внимания, использующийся в моделях на основе Трансформера, подсчитывает оценку сходства для всех пар токенов во входной последовательности. Полезно представить себе механизм внимания в качестве направленного графа, где в узлах графа находятся токены, а на гранях – оценки сходства (similarity score). В этом смысле модель внимания представляет собой полный граф. В основе подхода авторов статьи лежит идея тщательного проектирования таких разреженных графов, в которых подсчитывается только линейное число оценок сходства.

Механизм полного внимания может быть представлен в виде полного графа.
Extended Transformer Construction (ETC)
Для NLP задач, требующих длинных и структурированных входных последовательностей, авторы предлагают структурированный разреженный механизм внимания, т.н. Extended Transformer Construction, ETC (Построение расширенного Трансформера). Чтобы достичь структурированного разрежения внутреннего внимания был разработан механизм глобально-локального внимания. Так, входная последовательность Трансформера разделяется на две части: глобальный вход (global input), где токены получают неограниченное внимание, и «длинный» вход (long input), где токены могут относиться или к глобальному входу, или к локальному окружению. Это приводит к возможности линейного масштабирования внимания, что позволяет ETC значительно увеличить длину входной последовательности.
Также ETC включает в себя несколько дополнительных разработок, касающихся структуры длинных документов: использование информации об относительной позиции токена, а не абсолютной; использование дополнительной цели обучения помимо традиционного маскированного языкового моделирования (Masked Language Model, MLM) в языковых моделях вроде BERT; гибкое маскирование для контроля соотносящихся токенов. Например, пусть дан длинный фрагмент текста; глобальный токен применяется к каждому предложению, соединяя таким образом все токены внутри предложения, а также к каждому абзацу, объединяя токены внутри одного абзаца.

Пример структуры документа на основе разреженного внимания ETC модели. Глобальные переменные обозначаются как C (синий) для абзаца, S (желтый) для предложения, в то время как локальные переменные обозначаются как X (серый) для токенов, соответствующих длинному входу.
Этот подход позволяет достичь выдающихся результатов на пяти сложных наборах данных, требующих длинных или структурированных входных последовательностей: TriviaQA, Natural Questions (NQ), HotpotQA, WikiHop и OpenKP.

Результат на тестовом поднаборе для задачи ответов на вопросы. Для обоих наборов данных TriviaQA и WikiHop, использование ETC позволяет установить новую планку качества.
BigBird
Продолжая наработки ETC, авторы представили BigBird – механизм разреженного внимания, также имеющий линейную зависимость относительно количества токенов во входной последовательности, который заменяет традиционный механизм внимания в Трансформерах. В отличие от ETC, для BigBird не требуется априорного знания структуры исходных данных.
Разреженное внимание в BigBird состоит из трех основных частей:
- набор глобальных токенов, соотносимых со всеми частями входной последовательности;
- все токены соотносятся с токенами локального окружения;
- все токены соотносятся с некоторым числом случайных токенов.
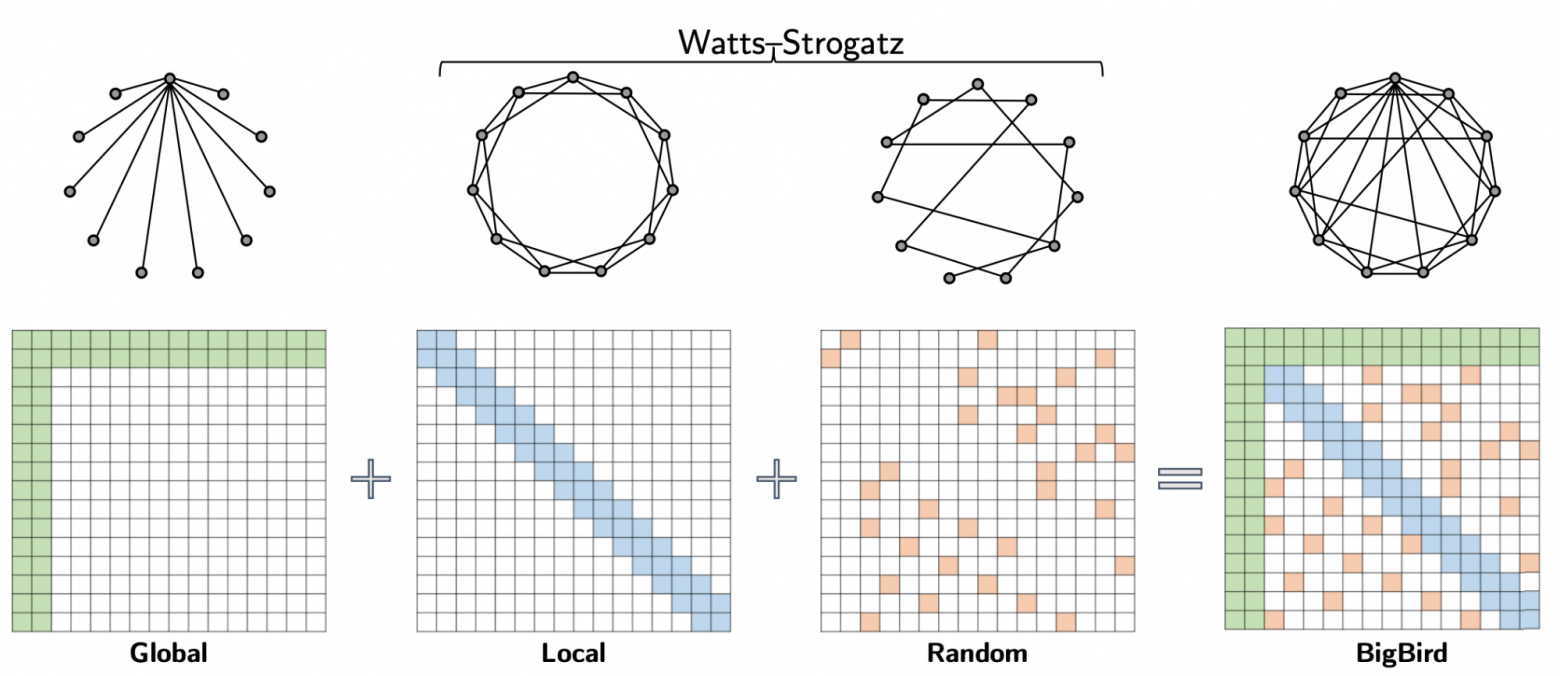
Разреженное внимание в BigBird можно представить как граф Ватца-Строгаца, в который добавили несколько глобальных токенов.
В статье, посвященной BigBird, авторы поясняют, почему разреженное внимание оказывается достаточным для приближения квадратичного внимания, объясняя отчасти успех ETC. Принципиально важным наблюдением является существование внутреннего противоречия между количеством подсчитываемых оценок сходства и потоком информации, передаваемой между узлами (т.е. способности одного токена влиять на другой). Глобальные токены служат своеобразным каналом для информационного потока и, как доказали авторы статьи, механизм разреженного внимания с глобальными токенами может быть столь же мощным, как и механизм полного внимания. В частности, авторы показали, что BigBird имеет такую же выразительность, что и оригинальный Трансформер, при этом является вычислительно универсальным (см. работы Yun et al. и Perez et al.), а также универсальным аппроксиматором непрерывных функций. Более того, авторы отмечают, что случайные графы могут еще больше облегчить передачу информации, что стимулирует использование компонента случайного внимания.
Такой подход позволяет работать с длинными последовательностями как в задачах со структурированными, так и с неструктурированными данными. Дальнейшее масштабирование можно осуществить с помощью контрольных точек градиента (gradient checkpointing) путем достижения компромисса между длиной последовательности и временем обучения. Это позволяет расширить разреженный Трансформер для задач генерации, требующих энкодера и декодера. Так, на задаче суммаризации документов авторы достигли наилучшего качества среди прочих моделей на текущий момент.

Метрика ROUGE для задачи суммаризации длинных документов. Новая планка качества достигнута на наборах данных BigPatent и ArXiv.
Более того, тот факт, что BigBird является более общей заменой традиционного механизма внимания, позволяет применять данный подход и в новых доменах, даже не имея предварительного знания предметной области. В частности, авторы предлагают использовать модели на основе Трансформера для новой прикладной задачи – выделение контекстных представлений последовательностей генома (ДНК). Более долгое предварительное обучение маскированной языковой модели позволяет BigBird достичь наилучших результатов в таких задачах, как предсказание промоторной области (promoter-region prediction) и предсказание профиля хроматина (chromatin profile prediction).

BigBird бьёт базовые результаты на многочисленных генетических задачах, таких как предсказание промоторной области, предсказание профиля хроматина включая транскрипционные факторы (transcription factors, TF), обнаружение гистонов (HM) и гиперчувствительности к ДНКазе (histone-mark (HM) and DNase I hypersensitive (DHS) detection). Более того, результаты авторов показывают, что Трансформеры могут применяться в генетике для многочисленных задач, которые пока еще малоизучены.
Основная идея реализации
Одним из основных препятствий для повсеместного внедрения разреженного внимания является тот факт, что разреженные операции достаточно неэффективны на современном оборудовании. Как в случае с ETC, так и с BigBird, одним из ключевых нововведений авторов является эффективная реализация механизма разреженного внимания. Поскольку современные ускорители, такие как GPU и TPU, превосходно используют операции с объединенной памятью, которые загружают блоки смежных байтов одновременно, неэффективно выполнять небольшие спорадические запросы, вызванные скользящим окном (для локального внимания) или выборкой случайных элементов (случайное внимание). Вместо этого авторы преобразуют разреженное локальное и случайное внимание в плотные тензорные операции, чтобы в полной мере использовать современные технологии с одиночным потоком команд, множественным потоком данных (single instruction, multiple data, SIMD).
Для этого авторы сначала «блокируют» механизм внимания, чтобы лучше использовать GPU/TPU, которые предназначены для работы с блоками. Затем вычисление механизма разреженного внимания преобразуется в плотное тензорное произведение с помощью ряда простых матричных операций, таких как изменение формы, вращение и сборка, как показано на анимации ниже.
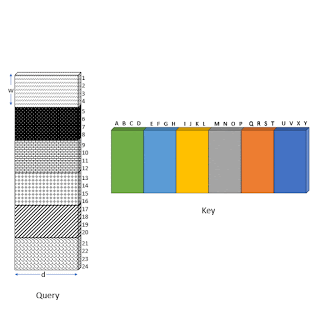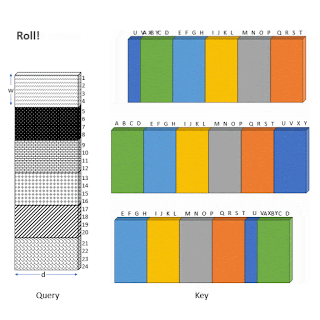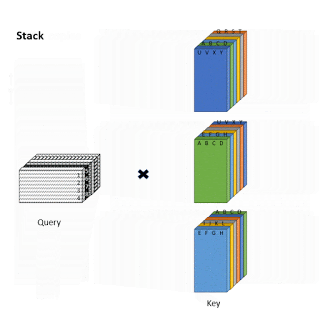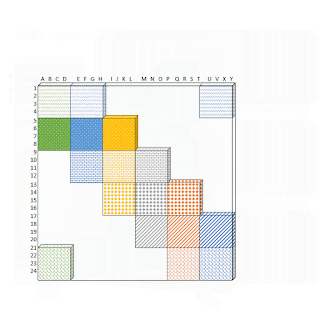
Иллюстрация того, как разреженное внимание в «окне» эффективно вычисляется с помощью прокрутки и изменения формы без небольших спорадических запросов.
Недавно в статье «Long Range Arena: A Benchmark for Efficient Transformers» был представлен эталонный тест из шести задач, требующих длинного контекста, и проведены эксперименты по тестированию всех существующих Трансформеров для длинных последовательностей. Результаты показывают, что модель BigBird, в отличие от своих аналогов, явно снижает потребление памяти без ущерба для производительности.
Заключение
В своем исследовании авторы показали, что тщательно разработанное разреженное внимание может быть столь же выразительным и гибким, как исходная модель полного внимания. Наряду с теоретическим обоснованием, авторы обеспечили весьма эффективную реализацию, которая позволяет масштабироваться для гораздо более длинных входных последовательностей. Это позволяет достичь наилучших результатов в задачах вопросно-ответных систем, суммаризации документов и классификации фрагментов генома. Учитывая общий характер предложенного механизма разреженного внимания, этот подход должен быть применим ко многим другим задачам, таким как синтез программного кода и вопросно-ответные системы в открытой предметной области. Авторы опубликовали исходный код как для ETC (github), так и для BigBird (github), эффективно работающий для длинных последовательностей на GPU и TPU.
Авторы
- Автор оригинала – Avinava Dubey
- Перевод – Смирнова Екатерина
- Редактирование и вёрстка – Шкарин Сергей

