(Q-learning, SARSA, DQN, DDPG)
Обучение с подкреплением (RL далее ОП) относится к разновидности метода машинного обучения, при котором агент получает отложенное вознаграждение на следующем временном шаге, чтобы оценить свое предыдущее действие. Он в основном использовался в играх (например, Atari, Mario), с производительностью на уровне или даже превосходящей людей. В последнее время, когда алгоритм развивается в комбинации с нейронными сетями, он способен решать более сложные задачи.
В силу того, что существует большое количество алгоритмов ОП, не представляется возможным сравнить их все между собой. Поэтому в этой статье будут кратко рассмотрены лишь некоторые, хорошо известные алгоритмы.
1. Обучение с подкреплением
Типичное ОП состоит из двух компонентов, Агента и Окружения.
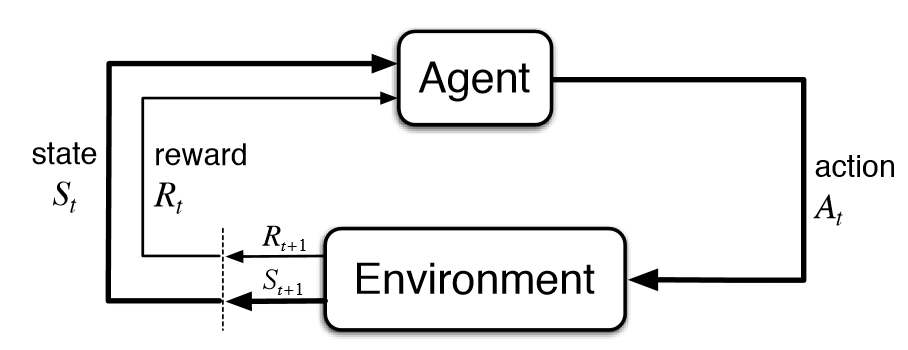
Окружение – это среда или объект, на который воздействует Агент (например игра), в то время как Агент представляет собой алгоритм ОП. Процесс начинается с того, что Окружение отправляет свое начальное состояние (state = s) Агенту, который затем, на основании своих значений, предпринимает действие (action = a ) в ответ на это состояние. После чего Окружение отправляет Агенту новое состояние (state’ = s’) и награду (reward = r) Агент обновит свои знания наградой, возвращенной окружением, за последнее действие и цикл повторится. Цикл повторяется до тех пор, пока Окружение не отправит признак конца эпизода.
Большинство алгоритмов ОП следуют этому шаблону. В следящем параграфе я кратко расскажу о некоторых терминах, используемых в ОП, чтобы облегчить наше обсуждение в следующем разделе.
Определения:
1. Action (A, a): все возможные команды, которые агент может передать в Окружение (среду)
2. State (S,s): текущее состояние возвращаемое Окружением
3. Rewrd (R,r): мгновенная награда возвращаемое Окружением, как оценка последнего действия
4. Policy (π ): Политика - стратегия, которую использует Агент, для определения следующего действия (a’) на основе текущего состояния среды.
5. Value (V) или Estimate (E) : ожидаемая итоговая (награда) со скидкой, в отличии от мгновенной награды R, является функцией политики Eπ(s) и определяется, как ожидаемая итоговая награда Политики в текущем состоянии s. (Встречается в литературе два варианта Value – значение, Estimate – оценка, что в контексте предпочтительней использовать E – оценка. Прим. переводчика)
6. Q-value (Q): оценка Q аналогична оценки V, за исключением того, что она принимает дополнительный параметр a (текущее действие). Qπ(s, a) является итоговой оценкой политики π от состояния s и действия a
, on-policy (алгоритм, где Агент включен в политику, т.е. обучается на основе действий, производных от текущей политики), off-policy (Агент обучается на основе действий, полученных от другой политики")
Безмодельные алгоритмы против алгоритмов базирующихся на моделях
Модель предназначена для моделирования динамики Окружения. То есть модель изучает вероятность перехода T(s1|(s0, a)) из пары состояния S0 и действия a в следующее состояние S1 . Если эта вероятность успешно изучена, то Агент будет знать, насколько вероятно получить определённое состояние, если выполнить действие a в текущем состоянии. Однако алгоритмы, построенные на моделях, становятся непрактичными по мере роста пространства состояний и действий (S*S*A для табличного представления)
С другой стороны, безмодельные алгоритмы опираются на метод проб и ошибок для обновления своих знаний. В результате им не требуется место для хранения комбинаций состояние / действие и их оценок.
2. Разбор Алгоритмов
2.1. Q-learning
Q-learning это не связанный с политикой без модельный алгоритм ОП, основанный на хорошо известном уравнении Беллмана:

Мы можем переписать это уравнение в форме Q-value:

Оптимальное значение Q, обозначенное как Q*, может быть выражено как:
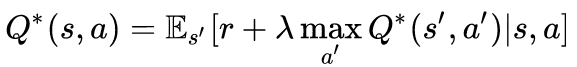
Цель состоит в том, чтобы максимизировать Q-значение. Прежде чем углубиться в метод оптимизации Q-value, я хотел бы обсудить два метода обновления значений, которые тесно связаны с Q-learning.
Итерация политики
Итерация политики представляет собой цикл между оценкой политики и ее улучшением.

Оценка политики оценивает значения функции V с помощью «жадной политики» полученной в результате последнего улучшения политики. С другой стороны, улучшение политики обновляет политику, генерирующую действия (action – a), что максимизирует значения V для каждого состояния (окружения). Уравнения обновления основаны на уравнении Беллмана. Итерации продолжаются до схождения.

Итерация Оценок (V)
Итерация оценок содержит только один компонент, который обновляет функцию оценки значений V, на основе Оптимального уравнения Беллмана.

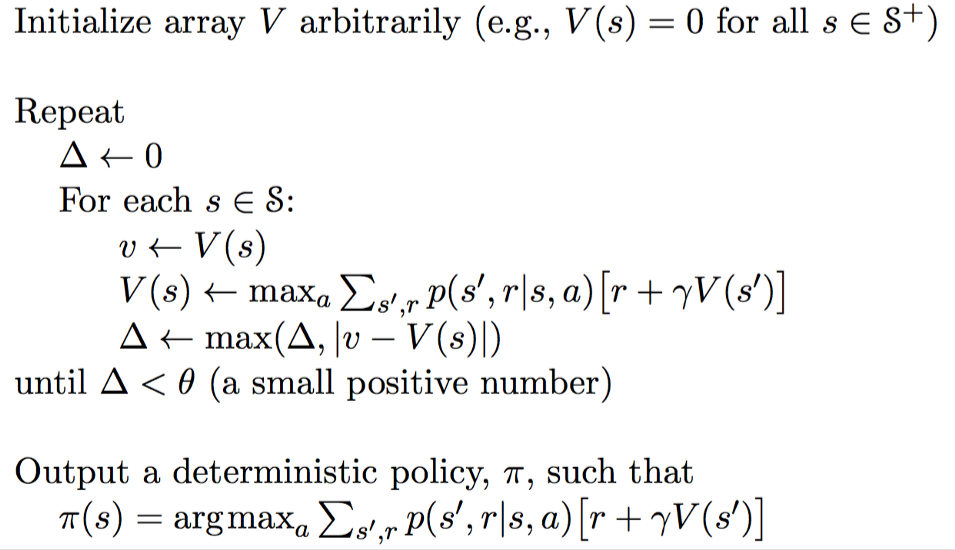
После того, как итерация сходится, оптимальная политика напрямую выводится путем применения функции максимального аргумента для всех состояний.
Обратите внимание, что эти два метода требуют знания вероятности перехода p, что указывает на то, что это алгоритм на основе модели. Однако, как я упоминал ранее, алгоритм, основанный на модели, страдает проблемой масштабируемости. Так как же Q-Learning решает эту проблему?

Здесь a (альфа) скорость обучения (т.е. как быстро мы приближаемся к цели) Идея Q-learning во многом основана на итерациях оценок (v). Однако уравнение обновления заменяется приведенной выше формулой. В результате нам больше не нужно думать о вероятности перехода (p).

Обратите внимание, что следующее действие a’ выбирается для максимизации Q-значения следующих состояний вместо того, чтобы следовать текущей политике. В результате Q-learning относится к категории вне политики (off-Policy).
2.2. State-Action-Reward-State-Action (SARSA)
SARSA очень напоминает Q-learning. Ключевое отличие SARSA от Q-learning заключается в том, что это алгоритм с политикой (on-policy). Это означает, что SARSA оценивает значения Q на основе действий, выполняемых текущей политикой, а не жадной политикой.
Уравнения ниже показывают разницу между рассчетом значений Q
Q-learning: Q(st,at)←Q(st,at)+α[rt+1+γmaxaQ(st+1,a)−Q(st,at)]
SARSA: Q(st,at)←Q(st,at)+α[rt+1+γQ(st+1,at+1)−Q(st,at)]
Где действие at+1 – это действие выполняемое в следующем состоянии st+1 в соответствии с текущей политикой.
Они выглядят в основном одинаково, за исключением того, что в Q- learning мы обновляем нашу Q-функцию, предполагая, что мы предпринимаем действие a, которое максимизирует нашу Q-функцию в следующем состоянии Q (st + 1, a).
В SARSA мы используем ту же политику (например, epsilon-greedy), которая сгенерировала предыдущее действие a, чтобы сгенерировать следующее действие, a + 1, которое мы запускаем через нашу Q-функцию для обновлений, Q (st + 1, at+1). (Вот почему алгоритм получил название SARSA, State-Action-Reward-State-Action).
Интуитивно понятно, что SARSA – это on-policy алгоритм , потому что мы используем одну и ту же политику для генерации текущего действия в точке и следующего действия в точке +1. Затем мы оцениваем выбранные действия нашей политики и улучшаем их, улучшая оценки Q-функции.
В Q-learning у нас нет ограничений на то, как выбирается следующее действие a, у нас есть только оптимистичный взгляд на то, что все последующие выборы действий a в каждом состоянии s будут оптимальными, поэтому мы выбираем действие a, чтобы максимизировать оценку Q (st+1, a). Это означает, что с помощью Q-learning мы можем генерировать данные политикой с любым поведением (обученной, необученной, случайной и даже плохой), при наличии достаточной выборки мы получим оптимальные значения Q

Из псевдокода выше вы можете заметить, что выполняется выбор двух действий, которые всегда соответствуют текущей политике. Напротив, Q-learning не имеет ограничений для следующего действия, пока оно максимизирует значение Q для следующего состояния. Следовательно, SARSA - это алгоритм, действующий в соответствии с политикой (on-policy).
2.3. Deep Q Network (DQN)
Хотя Q-learning - очень мощный алгоритм, его главная слабость - отсутствие общности. Если вы рассматриваете Q- learning, как обновление чисел в двумерном массиве (пространство действий * пространство состояний (action space * state space)), оно фактически напоминает динамическое программирование. Это указывает на то, что для состояний, которые агент Q-Learning не видел раньше, он не знает, какое действие предпринять. Другими словами, агент Q-Learning не имеет возможности оценивать значение для невидимых состояний. Чтобы справиться с этой проблемой, DQN избавляется от двумерного массива, введя нейронную сеть.
DQN использует нейронную сеть для оценки значений Q-функции. На вход сети подаются текущие кадры игрового поля, а выходом - соответствующее значение Q для каждого возможного действия.

аваВ 2013 году DeepMind применил DQN к игре Atari, как показано на рисунке выше. Входными данными является необработанное изображение текущей игровой ситуации. Оно проходит через несколько сверхточных слоев, а затем через полно связный слой. Результатом является Q-значение для каждого действия, которое может предпринять агент.
Вопрос сводится к следующему: как мы обучаем сеть?
Ответ заключается в том, что мы обучаем сеть на основе уравнения обновления Q-learning. Напомним, что целевое значение Q для Q-learning:
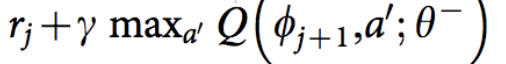
φ эквивалентно состоянию s, в то время как θ обозначает параметры в нейронной сети, что не входит в область нашего обсуждения. Таким образом, функция потерь для сети определяется как квадрат ошибки между целевым значением Q и выходным значением Q из сети.

Еще два метода также важны для обучения DQN:
1. Воспроизведение опыта: поскольку обучающие батчи в типичной настройке ОП(RL) сильно коррелированы и менее эффективны для обработки данных, это приведет к более сложной конвергенции для сети. Одним из способов решения проблемы выборки батчей является воспроизведение опыта. По сути, батчи переходов сохраняются, а затем случайным образом выбираются из «пула переходов» для обновления знаний.
2. Отдельная целевая сеть: целевая сеть Q имеет ту же структуру, что и сеть, которая оценивает значение. Каждый шаг C, в соответствии с приведенным выше псевдокодом, целевая сеть принимает значения основной сети. Таким образом, колебания становятся менее сильными, что приводит к более стабильным тренировкам.
2.4. Deep Deterministic Policy Gradient (DDPG)
Хотя DQN добилась огромных успехов в задачах более высокой размерности, таких как игра Atari, пространство действий по-прежнему остается дискретным. Однако для многих задач, представляющих интерес, особенно для задач физического контроля, пространство действий непрерывно. Если вы слишком дискретизируете пространство действия, вы получите слишком большой объем. Например, предположим, что степень свободной случайной системы равна 10. Для каждой степени вы делите пространство на 4 части. У вас будет 4¹⁰ = 1048576 действий. Чрезвычайно сложно получить схождение для такого большого пространства действий, а это еще не предел.
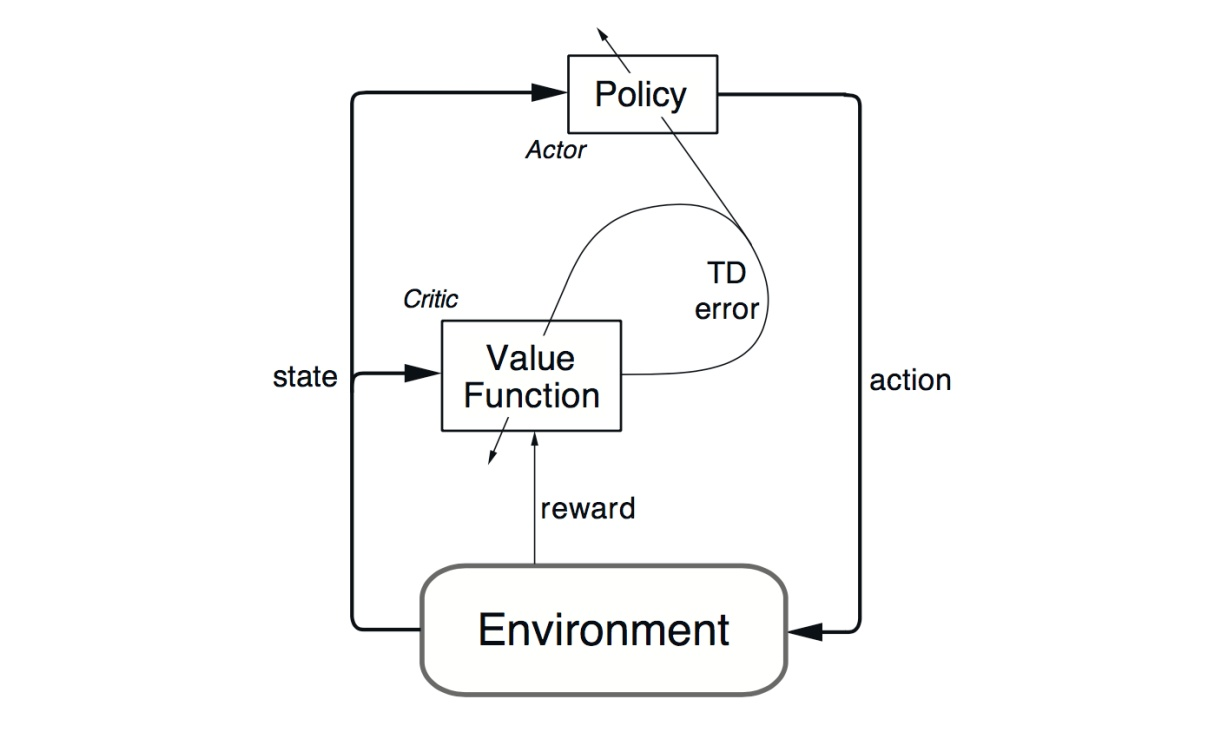
DDPG реализует архитектуру «актор-критик» с двумя одноименными элементами - актором и критиком. Актор используется для настройки параметра ? функции политики, то есть для определения наилучшего действия для определенного состояния.
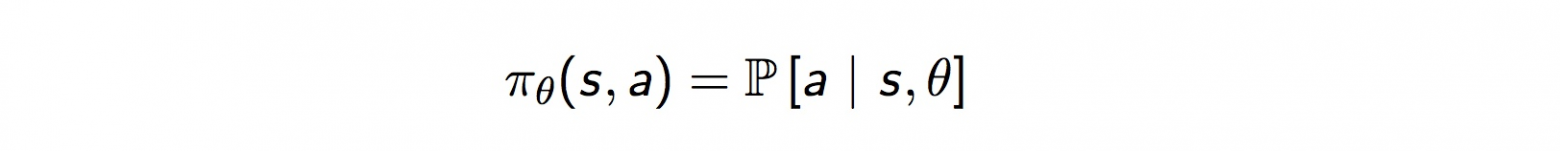
Критик используется для оценки функции политики Актора в соответствии с ошибкой временной разницы (TD)

Здесь u обозначает политику Актора. Знакомо? Да! Это похоже на уравнение обновления Q-learning. TD-learning – это способ научиться предсказывать значение в зависимости от будущих значений данного состояния. Q-learning это особый тип TD-learning для получения Q значений
DDPG также заимствует идеи воспроизведения опыта и отдельной целевой сети от DQN. Другой проблемой для DDPG является то, что он редко выполняет поиск действий. Решением для этого является добавление шума в пространство параметров или пространство действий (action).

Утверждается, что добавление шума в пространство параметров лучше, чем в пространство действий, согласно статье написанной на OpenAI.


