Бесплатное распознавание речи для всех желающих
После относительно недавнего релиза мы сделали наше распознавание речи бесплатным для всех индивидуальных пользователей на страничке по адресу — https://audio-v-text.silero.ai/.
Да, вы не ослышались. Это не шутка, не очередная кампания по продаже "шпионских" гаджетов, не альтруизм и не обман:
- Да, сервис сделан для простых людей, и там есть разумные ограничения на объем, перепродавать не получится (а если у кого-то получится, то нам придется или закрутить все сильнее, или закрыть сервис).
- Да, мы предприняли разумные меры, чтобы сделать все безопасным как для нас, так и для пользователей.
- Да, этот сервис будет бесплатным.
- Да, мы полностью независимы и никак не аффилированы с теми самыми компаниями (если вы понимаете, о чем я).
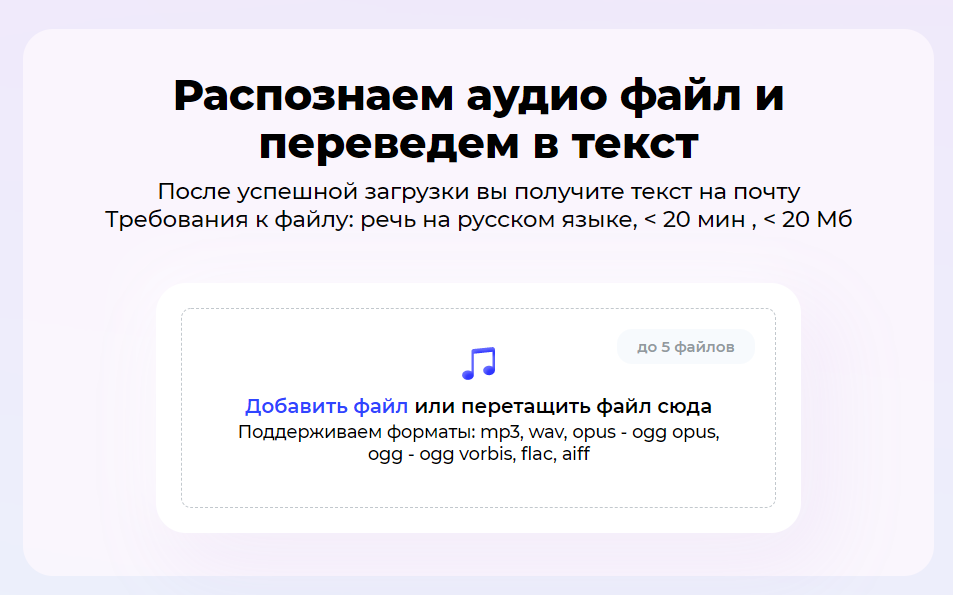
Как Пользоваться
Инструкция простая до банальности:
- зайти на страничку,
- опционально попробовать демку с микрофоном,
- залить свой файл в формочку,
- получить распозанный файл на email.
По идее должно работать во всех основных браузерах. Рекомендуется заходить с ноутбука или десктопа, но и со смартфона в принципе тоже должно работать.
Не лишним будет упомянуть: правильно указывая, из какого домена (какого типа) ваше аудио, вы поможете повысить качество распознавания вашего аудио.
Идея Сервиса
Если сейчас обычному физическому лицу нужно что-то транскрибировать, то на рынке есть опции:
- Есть решения, требующие регистрации, оплаты, создания личного кабинета.
- Есть ограниченное количество корпоративных решений, которые, по очевидным причинам, тоже не закрывают этот случай.
- Есть большое количество ML репозиториев, устаревших решений или поделок народных "умельцев". Но "обычный" пользователь вряд ли может ими воспользоваться.
Резюмируя: нет качественных решений для "маленьких"/одноразовых случаев использования (без геморроя и высокого порога входа). Мы решили это исправить. Будем признательны за вашу конструктивную обратную связь.
Текущие Ограничения
У сервиса в текущем виде есть ряд ограничений, часть которых решается технологически, а часть только процессуально:
- Хотя мы можем разделять заранее известное количество говорящих, это не вошло в MVP сервиса.
- Многоканальное аудио в MVP не разделяется и обрабатывается после усреднения каналов.
- Наличие большого количества жаргона, англицизмов или очень редкой уникальной лексики негативно влияет на распознавание. Конечно это решается, но скорее уже в рамках отдельного проекта или с помощью ручной пост-обработки.
- Чем лучше качество исходного аудио, тем лучше качество транскрибации.
- На данный момент пунктуация и заглавные буквы автоматически в сервисе не проставляются, хотя мы в это умеем.
- Для некоторых случаев, даже при хорошем качестве аудио и с учетом автоматической простановки знаков препинания, нужна пост-обработка людьми. Мы пока не предлагаем такой сервис.
Безопасность и Использование Данных
Мы используем лучшие из доступных нам инструментов. Мы шифруем трафик и данные. Мы блокируем ботов и пресекаем нецелевое использование.
Для любителей разоблачений и теорий заговора: основной целью сервиса является улучшение качества распознавания в конкретных доменах с использованием данных пользователей. По этой причине просим всех пользователей прочитать оферту и убедиться, что все посылаемые данные не содержат чувствительной или запрещенной информации. Мы не будем публиковать или делиться этими данными с третьими сторонами, но, естественно, подходите к своим и чужим данным ответственно и используйте сервис на свой страх и риск.

