В первой части я рассказал про то, почему я пришел к необходимости создания собственной СДО. Итак, на текущий момент имеем: сайт, работающий на самописном PHP frameworke, отдельные скрипты JS, подключаемые на определённых страницах с соответствующим типом задания (тест, квест). Тип задания и необходимость загрузки скриптов определяется выполнением кода PHP на конкретной странице. JS работает локально (база данных используется только PHP).
Появилась задача взаимодействия JS с базой данных для расширения функционала интерактивных возможностей СДО. Так как ранее я работал с PHP, было принято решение передавать сведения, полученных PHP из базы данных в JS. Для хранения массивов в SQL сначала я использовал сериализацию и base64, но быстро отказался от такого подхода ввиду сложности понимания структуры данных, хранящихся в базе.
Я был нацелен на достижение скорейшего результата в виде работающего приложения, поэтому было принято решение хранить объекты JS и массивы PHP в виде JSON строки в обычном поле формата text. Да, спустя время я понимаю, что можно было рассмотреть возможность использования нереляционных (NoSQL-систем) баз данных типа MongoDb (впоследствии, я возможность перехода протестировал, но значимых плюсов не нашел для решения конкретных задач, в первую очередь потому, что приходится в основном работать с отношениями «многие ко многим»).
Следует сказать о 2 типах информации, которую было необходимо сохранить в базе данных. Первый – это обычные массивы PHP и объекты JS (по сути, ассоциативные массивы PHP). С этим форматом особых сложностей не было. Гораздо большую сложность представлял формат хранения слайдов.

Что представлял собой слайд. Это некая область в дереве DOM, сформированная с помощью JS и содержащая избыточную информацию о, элементах, расположенных в ней:
Фоновое изображение.
Информация о расположении иконок на слайде (позиционирование было абсолютным и достигалось путем Drag and Drop из библиотеки JQuery UI, расположенной справа).
CSS стили оформления, пути к изображениям элементов и т.д.
Каждая иконка имела соответствующий вид, тип и событие, которое наступало при клике на ней.
Слайд содержал информацию об анимации перехода, является ли он начальным или финальным.
Информация о каждом слайде хранилась в объекте JS в виде массива объектов, каждый из которых имел ключ – номер слайда и значение – html сущность в виде строки (чуть позднее использовался MAP). Для сохранения квеста, содержащего множество слайдов в SQL отправлялся ajax POST запрос, содержащий информацию о названии, категории, авторе и html коде 2 блоков страницы (навигация и рабочая область). Библиотека в базе не сохранялась.
Страшно сейчас представить, что хранилось в базе данных и как постоянно я боролся с ошибками кириллицы, валидности html и json при постоянном обмене между JS и PHP.
Часть примера POST.

С целью более упорядоченной работы с квестами и учитывая, что уже получался вполне самодостаточный проект, было решено вынести его в отдельный поддомен и связывать с основным СДО в будущем с помощью базы данных и межсайтовыми запросами. Сайты были разделены.
Итак, имеются уже 2 сайта, сделанные на самописном frameworke.
1. Главный сайт, реализующий следующий функционал: регистрация пользователей, возможность создания категорий (дисциплин) и заданий. Из сделанных заданий были: тестирование на статических файлах JS и проверка преподавателем ответов, присылаемых студентами. Сводная таблица содержала данные по оценкам, выставленным преподавателем исходя из ручной проверки решений заданий, вставляемых студентами в «textarea» и отправляемых с помощью формы POST запросом на сервер.
2. Квестовая подсистема (на поддомене), позволяющая реализовать простые пошаговые переходы между слайдами путем клика на соответствующие иконки. По сути, происходила полная замена html содержимого блока с помощью Jquery на другой код html, содержащийся в значении ключа слайда объекта и сохраненный туда ранее.

Желая максимально ускорить работу сайтов, я старался минимизировать количество запросов к базе данных. Доходило даже до крайностей: к примеру, данные авторизованного пользователя хранились в Cookie (id, ФИО, роль) в открытом виде. Это впоследствии привело к ряду проблем, что желая изменить ФИО пользователя или его роль, мне приходилось вручную просить людей выйти из системы, а потом снова войти, чтобы заново поставить куки, так как будучи «очень продвинутым» я сразу ставил время жизни куки – 5 лет. Логика рассуждений была проста – зачем пользователю постоянно логиниться, ведь что может поменяться? Я был неправ и не только в этом.
Как я пришел к API. Необходимость загружать мультимедийный контент в виде видеофайлов для демонстрации пользователям на страницах заданий предопределило необходимость поиска оптимального хранилища для этого. Варианты загрузки файлов на YouTube, другие ресурсы и дальнейшая вставка на сайт не рассматривались. Пришлось думать над созданием собственного сервера. Почему-то в тот момент не подумал о поднятии сайта сразу на своем сервере.
Готовые серверы рассматривать не стал, но выдвигалось пара требований – пассивный блок питания и минимальный размер. Был приобретен mini-itx корпус (5х20х20см.) с блоком питания PSU (внешний блок без вентиляторов на 90 ватт) как у ноутбуков. Установлен SSD на 240 Gb, 12 Гб оперативной памяти (думал с запасом для запуска виртуальных машин). Процессор Intel G4600 (2 ядра, 4 потока) на сокете LGA 1151. Материнская плата оборудована Wi-fi.
У провайдера была подключена услуга статического белого IP адреса, поднят OpenServer на Windows машине.
Маршрутизатор с прошивкой Padavan. Прошивка неплохая за исключением того, что умеет работать только с SMB версии 1, которая в Windows уже отключена по причине безопасности. На роутере был настроен проброс 8080 порта на адрес локальной машины, привязанной статическим адресом через MAC-адрес (чтобы dhcp не давало другие IP адреса после перезагрузки).
Установив сервер и настроив A-запись созданного поддомена api.***.ru на хостинге через несколько часов получил доступ из сети Интернет на apache сервер OpenServera. Также был настроен alias для направления запросу на внутреннюю папку с доменом.
API захотелось написать самостоятельно (думаю, можно было использовать для этих целей SlimPhp 4 или Lumen).
API представляло собой небольшой framework, имеющий единую точку входа. Классы подключались автолоадером composer. Дальнейшая маршрутизация осуществлялась с проверкой метода и параметров query запроса:
$items = explode("/", $_GET['query']); $endpoint = $items['0']; $params = $items['1']; Нужный файл подключался путем: require_once('api/1.0/' . $endpoint . '.php'); Так как payload запроса был в формате JSON, я преобразовал его так (для дальнейшей работы нужны были оба формата): $POST_JSON = json_decode(file_get_contents('php://input'), true); $POST = file_get_contents('php://input');
Ядро системы составлял файл Db с подключением к базе данных (шаблон - синглтон), а также содержащий основные методы работы на низком уровне PDO. Абстрактный класс модели содержал высокоуровневые запросы типа findOne (поиск по id), findLike, count и т.д. Также были созданы 2 класса моделей, наследующих (расширяющих основной класс модели): (пользователи, квесты), отдельный файл вспомогательных функций (helpers), а также 3 файла основного API – library (библиотека), quests (квесты) и users (пользователи). Была создана примитивная защита от CSRF атак, представляющая собой передачу на сервер 2 полей, в одном из которых хранился цифровой код, генерируемый рандомно, а во втором ответ. Смысл проверки был в математическом преобразовании первого поля по заранее известному алгоритму, описанному в коде, чтобы получить второе значение.
Немного забегая вперед (когда я отошел от сохранения в базе html кода и стал использовать в полном объеме реляционность базы данных) приведу подход, вызванный ленью для вставки или обновления базы. Приведенная функция позволяла автоматически формировать запрос SQL (уж очень не хотелось копировать каждый раз поля):
//------------------------ДЛЯ INSERT UPDATE PDO function pdoSet($source = array()) { $fields = array_keys($source); $set = ''; $values = array(); foreach ($fields as $field) { if (isset($source[$field]) and $field !== 'id') { $set .= "`" . str_replace("`", "``", $field) . "`" . "=:$field, "; $values[$field] = $source[$field]; } } return substr($set, 0, -2); } В модели функция применялась так: public function saveIcon($icon) { $sql = "INSERT INTO icons SET " . pdoSet($icon) . " ON DUPLICATE KEY UPDATE " . pdoSet($icon); return $this->pdo->save($sql, $icon); }
Не преследуя цели детального технического описания работы системы, остановлюсь на ряде трудностей, с которыми пришлось столкнуться в тот момент.
Как передавать файлы. У меня было на рассмотрении 2 варианта – передача сразу напрямую в бинарном формате (либо base64, так как файлы были небольшими) на сервер, либо загрузка файлов на хостинг, а потом копирование file_get_contents сервером к себе. И я выбрал сложный вариант – не знаю почему (нет, знаю – в интернете были такие примеры): сначала файлы заливались на хостинг, а потом я их копировал на сервер. С именами и местом расположения файлов были отдельные сложности, так как я хотел расположить файлы в папке с именем/логином пользователя, а логином был адрес электронной почты. Наличие точек в имени папки в отдельных случаях вводило в ступор скрипты php. Думаю, что подробности не будут так интересны широкой массе, но хлопот мне это доставило. Решение: замена спецсимволов и точек (я заменил на дефис, хотя для JS это не очень хорошо, но как есть).
Сложности единой авторизации на 2 сайтах под одной учетной записью. На первых этапах решалось это путем передачи GET параметров в адресной строке. Подход, конечно, не эффективный и очень небезопасный, но рабочий. Стал искать решение, оказалось, что можно передавать через кроссдоменные запросы Coockie, дополнять и возвращать на сайт. Coockie, прилетевшая с API содержала в себе заголовок, который видоизменял Coockie в браузере пользователя и авторизовывал его. За это отвечает атрибут SameSite. В 2019 году такую возможность в целях безопасности усложнили, поэтому у меня все перестало работать. Вчера работало, а сегодня уже нет (вышло обновление браузера). Пришло искать причину. Решением проблемы оказался переход на https (о нем ниже) и явное указание в заголовках «SameSite=None, Secure». Конечно, можно было использовать OAuth, но…знал бы прикуп…
Протокол http. Сайты изначально работали на протоколе http, уже тестировал сокеты (о них далее), и тут думаю, что же все с замком в адресной строке, а я в каменном веке. Сделал себе на хостинге Let’s Encrypt сертификат и активировал. Проведя немного тестов, понял, что сокеты не работают и надо (смешанное содержимое – mixed content) откатился назад. SSL и https отключил. О настройках .htaccess рассказывать не буду, но нервы мне это помотало (оказалось, что задержка хостинга была несколько десятков минут при изменении параметров). Я и многие пользователи столкнулись с проблемой появления предупреждения браузера, что, конечно, было неприятно. Объяснять пользователям как указать браузеру заходить по http, когда он уже удачно 1 раз по https мне оказалось не под силу. Решено – переходим на https снова.
Адаптивность. Несмотря на то, что я как «современный веб-мастер» использовал адаптивную верстку, предоставляемую Bootstrap проблема была в абсолютном позиционировании элементов. Основная рабочая область («div» с размером 1200 на 800 пикселей) была рассчитана под экраны компьютера с разрешением fullHD, пока о телефонах речи не шло. Оказалось, что такие экраны есть далеко не у всех и верстка слетала. Да, можно было поправить сжатие области (фон также уменьшался в размерах) путем задания процентных соотношений ширины 100%, однако элементы и иконки, имеющие абсолютное позиционирование, не хотели сами следить за фоном и образовывали хаос. Меня посетила мысль перебирать в цикле позиционирование элементов и выставлять новые значения исходя из размера рабочей области, однако надо было переделывать и добавление иконок с корректным сохранением их в базе данных, масштаб текста и т.д. В тот момент я отказался от такого подхода (сейчас все делают Хуки React для всех разрешений и динамическом изменении размера, к примеру – поворот мобильного устройства, за что отдельное спасибо разработчикам).
Пример как это неудачно выглядело на небольших экранах.

Взаимная интеграция. Были сложности с взаимным обменом данных между сайтами. Изначально я рассчитывал осуществлять обмен с помощью базы данных SQL, однако каждый из сайтов изначально работал со своей базой, расположенной на своем localhost, поэтому на сервере была сделана еще одна база, доступ к которой был открыт удаленно. Получилось много баз с разными полями, иногда повторяющими друг друга. Работать с хранимыми процедурами, а также использовать FEDERATED Storage Engine я не потянул, поэтому получились сложные и часто однотипные запросы к разным базам для выборки типа JOIN. И тут же столкнулся с проблемами: разработка приложения требовала активную работу с БД и пришлось менять во всех местах аналогичные части кода. Бывало, и 4 места, содержащих почти одинаковый код. Сделал урок для себя: дублирование кода очень – весомая ошибка при проектировании программ.
Нагромождение кода приложения. Квестовая система, позволяющая осуществлять переход по ссылкам и заменить содержимое DOM-дерева вроде работала, но я подумал – а где же сами квесты? Где диалоги, вопросы, пароли для прохождения в секретные зоны и т.д. Решено – будем делать. Начал я с простого – создал новый тип иконок (первый вид – просто переход по слайдам), который отвечал за открытие модального окна Bootstrap и демонстрации текста и фото. Смысл этого окна был в показе детального описания и фото предмета, находящегося в рабочей зоне слайда. Потом Остапа понесло пришла мысль: а как же диалоги – какой квест без диалогов? Сделано. А где же тесты – это ведь СДО – пришлось интегрировать, а точнее заново написать систему тестирования. Далее – хочешь пройти в какую-то локацию – назови пароль (ответь на вопрос). Итог: сделано окно с вопросом и проверкой ответа.
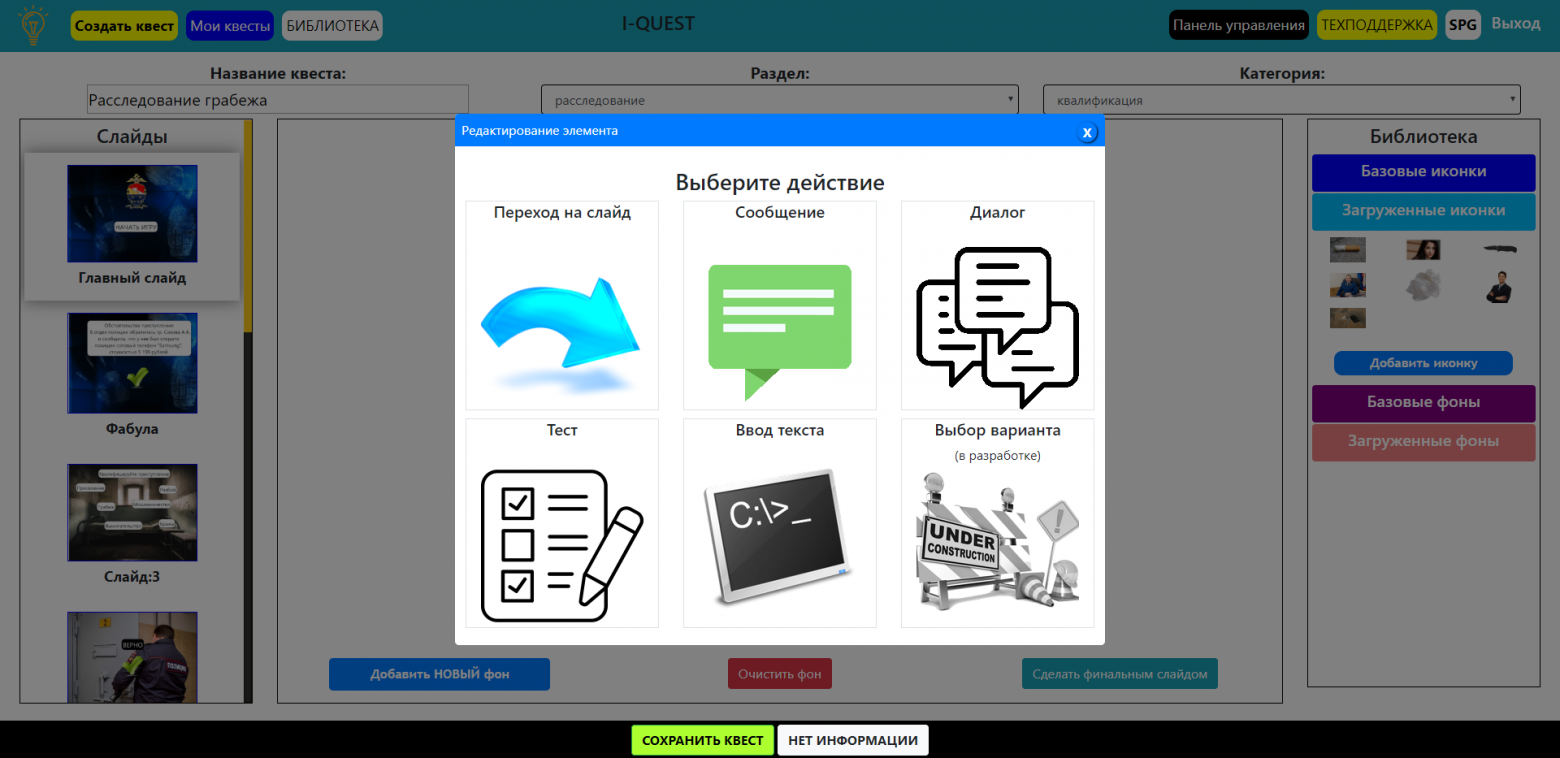
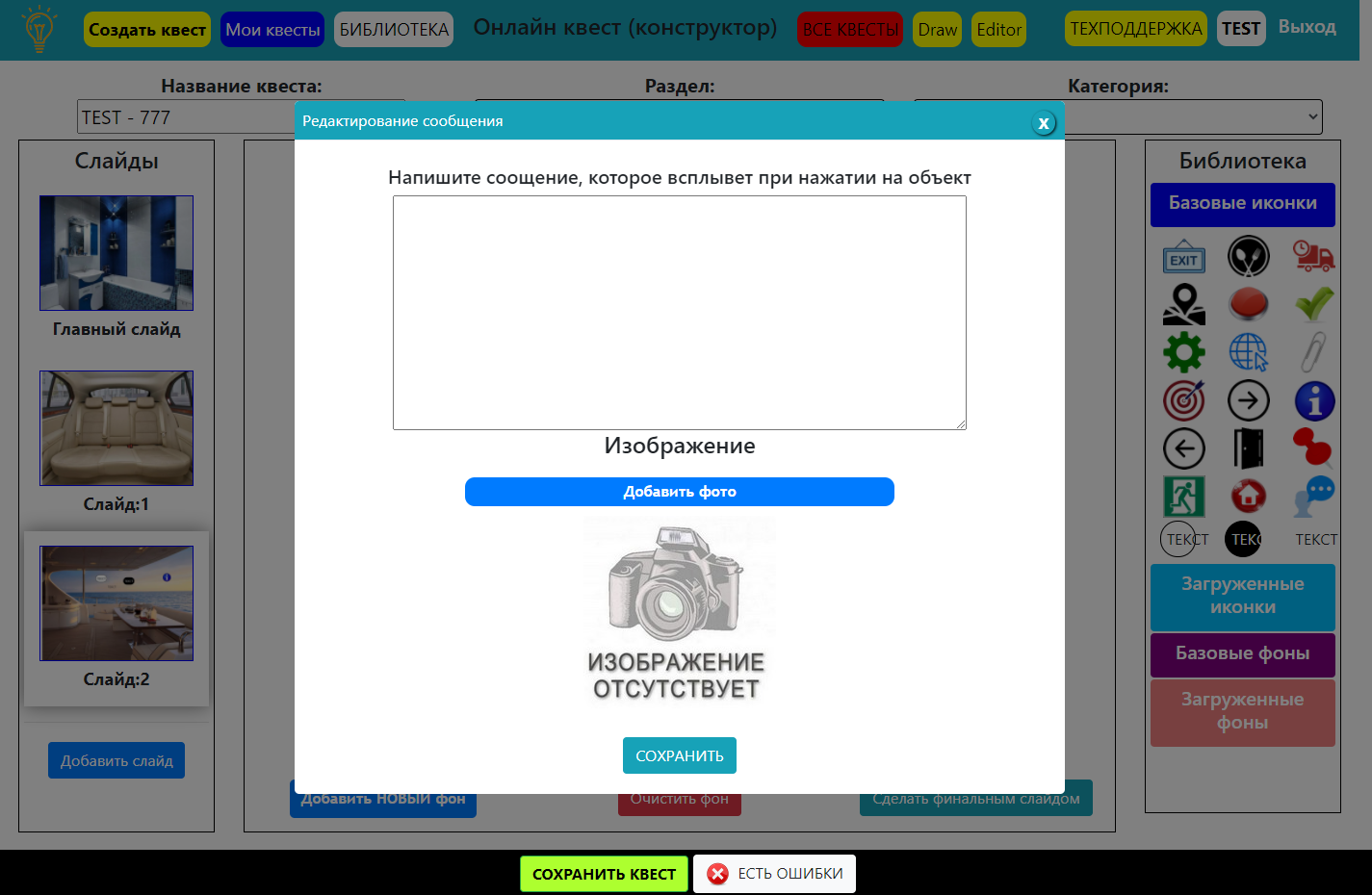
Как итог: скрипты сильно разрослись в размере, стало сложно что-то понимать через пару дней. Так как все работало в процедурном стиле на асинхронных функциях, то было все очень запутанно и вообще… слов нет от такого бардака. Работа с кодом велась в большей степени с помощью replace строковых данных на новые id и замене data-атрибутов.
Пример функции активации перетаскивания иконки:
//==========АКТИВАЦИЯ ПЕРЕТАСКИВАНИЕ======= function activeDrop() { console.log('сработала: activeDrop'); $(".drop-td").droppable({ accept: '.item_library, .clone', // hoverClass: "bg-info", drop: function (event, ui) { if (ui.draggable.hasClass('fon')) { $.ajax({ url: '<?= TEMPLATE ?>/ajax/ajaxCopyImage', dataType: 'text', type: 'post', data: {type: $(ui.draggable).attr('data-type'), name: $(ui.draggable).attr('data-img'), path: $(ui.draggable).attr('data-path')}, success: function () { number_slide = $("#work_zone").attr('data-slideWork'); img = $(ui.draggable).attr('data-img'); $("#table_zone").css("background-image", "url(../public/LIBRARY/USE_CONTENT/<?= EMAIL ? EMAIL : '' ?>/backgrounds/" + img + ")"); $.when(screenshot()).then(function (data) { refresh_arrays(); }).then(function () { ajaxSaveSlide(); }); } }); return false; } else if (ui.draggable.hasClass('clone')) { pos_Y = $(ui.draggable).position().top; pos_X = $(ui.draggable).position().left; $(ui.draggable).css({'position': 'absolute', 'left': pos_X, 'top': pos_Y}); $.when(screenshot()).then(function (data) { refresh_arrays(); }); return false; } else if (ui.draggable.hasClass('item_library')) { clone = ui.draggable.clone(); var parentOffset = jQuery('.drop-td').offset(); $(this).append(clone.removeClass("ui-draggable item_library").addClass('clone').css({'position': 'absolute', 'left': (ui.position.left - parentOffset.left) + 'px', 'top': (ui.position.top - parentOffset.top) + 'px'})); // ----------------- // clone = ui.draggable.clone(); // $(this).append(clone.removeClass("ui-draggable item_library").addClass('clone').css('position', 'relative')); // pos_Y = $(clone).position().top; // pos_X = $(clone).position().left; // $(clone).css({'position': 'absolute', 'left': pos_X, 'top': pos_Y}); // ------------------ if ($(clone).is('[src]')) { $.ajax({ url: '<?= TEMPLATE ?>/ajax/ajaxCopyImage', dataType: 'text', type: 'post', data: {type: $(ui.draggable).attr('data-type'), name: $(ui.draggable).attr('data-img'), path: $(ui.draggable).attr('data-path')}, success: function () { src = $(clone).attr('src'); if ($(ui.draggable).attr('data-path') == 'system') { src_new = src.replace("LIBRARY", "LIBRARY/USE_CONTENT/<?= EMAIL ?>"); } else { src_new = src.replace("USERS", "USE_CONTENT"); } $(clone).attr('src', src_new); } }); } $.when(screenshot()).then(function (data) { refresh_arrays(); }).then(function () { ajaxSaveSlide(); }); } $(".clone").draggable({ revert: "invalid", distance: 10 }); } });
Пару слов о создании скриншотов, расположенных слева от рабочей области. Был создан наблюдатель, который все изменения фиксировал путем:
$(function () { var target = document.getElementById('work_zone'); var observer = new MutationObserver(function (mutations) { mutations.forEach(function (mutation) { // refresh_arrays(); }); }); var config = {attributes: true, childList: true, characterData: true, subtree: true}; //var config = {attributes: true, childList: true}; observer.observe(target, config); }); refresh_arrays() вызывала скриншот. //========================СКРИНШОТ function screenshot() { console.log('сработала: screenshot'); number_slide = get_number_slide(); // html2canvas(document.querySelector("body")).then(function (canvas) { // document.body.appendChild(canvas); // }); scrollTop = 0 - window.pageYOffset; return html2canvas(document.querySelector("#table_zone"), {logging: false, scrollY: scrollTop}) .then(canvas => { // document.body.appendChild(canvas); dataURL = canvas.toDataURL(); old = $("[data-slide=" + number_slide + "] [data-fonSlide='']").css('background-image'); old = old.slice(4, -1).replace(/"/g, ""); }) .then(function () { return $.ajax({ url: '<?= TEMPLATE ?>/ajax/ajaxLibraryAddSlide', dataType: 'text', type: 'post', data: {base_64: dataURL, old: old}, success: function (data) { $("[data-slide=" + number_slide + "] [data-fonSlide='']").css("background-image", 'url(' + data + ')'); } }); }).then(function () { }); }
В какой-то момент я понял – так жить нельзя, учитывая, что это всего лишь малая часть задуманного мною приложения, а я уже запутался и сам иногда не разберусь в своем же коде. Если с PHP ситуация проще – там ООП, то здесь – тушите свет. Писать в стиле ООП JS я не умел, а признаться честно, и сейчас не умею – пробовал, но понял, что смысла для решаемых мною задач особо нет, но этом далее.
Какие выводы можно сделать? Архитектуру приложения надо продумывать с точки зрения трудозатрат, да и временных рамок более серьезно, чем писать код – это я еще не раз пойму дальше.
Конец 2 части.
Часть 4. Выбор фреймворка и переход на Laravel в рамках создания собственной СДО
Часть 5. Переход на ReactJs, внедрение flux, SOLID и интеграция в Laravel.
Часть 6. Внедрение нейронных сетей в работу СДО.

