Статья приводится в сокращении из-за ограничения на объем материала.
Для меня программирование — это не только технология, но и, во многом — искусство. И, поэтому, большое значение имеет красота кода.
Последние несколько лет я собирал приемы программирования, разрушающие в программном коде его утонченную красоту:

- Объявление всех переменных в начале программы;
- Возврат результата функции через ее параметр;
- Отсутствие локальных функций;
- Отсутствие
else if; - Использование параллельных массивов;
- Хранение размера массива в отдельной переменной;
- Доступ к свойствам объекта через
obj.getProperty()иobj.setProperty(value); - Использование рекурсии для вычисления факториалов и Чисел Фибоначчи;
- Отсутствие именованных параметров функции;
- Невозможность объявления объектов «на лету».
Объявление всех переменных в начале программы
В двух словах:
Переменные должны объявляться в начале логического блока, в котором они используются, а НЕ в начале функции или программы.
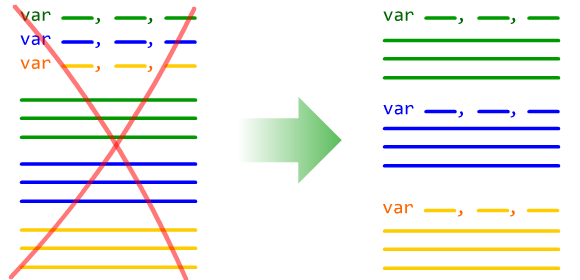
Все программные системы иерархичны. Программы делятся на пакеты, пакеты — на классы, классы разбиваются на отдельные функции.
Данные, относящиеся к тому или иному модулю программы, принято объявлять в начале этого модуля. Локальные переменные объявляются в начале функции; свойства, относящиеся ко всему классу, объявляются в начале определения класса и т.д.
Однако функции не являются последним уровнем в иерархии программы. Любая нетривиальная функция состоит из блоков, реализующих отдельны шаги выполнения алгоритма. Тех самых блоков, которые никак не обособляются в коде, разве что отделяются друг от друга парочкой пустых строк.
Однако эти блоки — полноценные элементы в иерархии программы. И они тоже имеют право на собственные «локальные» переменные! Которые объявляются в начале этого блока и используются только в его пределах.
| Объявление всех переменных в начале функции — страшное зло[1]. |
Это разрывает блок на две части: объявления данных (в начале функции) и использования этих данных (в самом блоке).
Это усложняет комментирование блока: в одном месте мы комментируем переменные, но не знаем, как их использовать; в другом месте мы комментируем алгоритм, но не знаем, с какими данными он работает.
Пример:
Вы только представьте: У нас есть функция в 300 строк кода [2]. Где-нибудь на 200-й строке нам надо поменять две переменные местами. Для этого мы лезем на 200 сток выше в начало функции, объявляем переменнуюtemp, которая не имеет никакого отношения ко всей функции, а используется только один раз в одном месте, потом опять возвращаемся к 200-й строке и меняем переменные местами… По-моему, это просто кошмар.
Хуже всего, что существуют языки, которые считают себя умнее разработчика и заставляют объявлять все переменные в начале функции. Например, такой уважаемый язык как Pascal/Delphi. Чего я ему простить не могу…
Возврат результата функции через ее параметр
В двух словах:
Функция должна возвращать результат, зависящий от ее параметров, а НЕ принимать результат в качестве аргумента.

Понятие функции (как в математике, так и в программировании) имеет четкий смысл: вычисление результата, зависящего от аргументов.
В нормальном программном коде ясно видно, что является результатом, а что аргументами:
результат = функция (аргумент1, аргумент2).Однако часто встречается прием, при котором возвращаемое значение передается в качестве аргумента функции: функция (аргумент1, аргумент2, &результат).Этот прием ужасен. При его использовании не видно, от чего функция зависит, а что возвращает. |
Существуют две основные причины, по которым языки заставляют нас прибегать к этому приему.
Первая причина состоит в том, что в некоторых языках функции не могут создавать и возвращать сложные объекты.
Пример:
Предположим, что мы хотим на C++ написать функцию, перемножающую две матрицы и возвращающую получившуюся матрицу в качестве результата. Матрицы мы решили представлять в виде двумерного массива.
Но мы не можем объявить в функции результирующий двумерный массив, а затем вернуть его:
int mtxResult [10][10] = mult (mtxA, mtxB);<br><br>Поэтому нам придется сначала вне функции объявить результирующий массив, а затем вызвать функцию перемножения, передав результат в качестве аргумента:
mult (mtxA, mtxB, mtxResult);
В данном случае от использования этого приема можно избавиться, храня результат в том виде, который функция может возвратить.
Пример:
Можно хранить матрицу не в виде двумерного массива, а в виде структуры или объекта:
Matrix mtxResult = mult (mtxA, mtxB);
Код станет менее лаконичным (из-за объявления дополнительных структур), но, зато, гораздо более красивым.
Вторая причина состоит в том, что в большинстве языков программирования функция не может возвращать несколько значений.
Пример:
Предположим, что мы хотим на C++ написать функцию, решающую квадратное уравнение. Функция принимает в качестве аргумента коэффициентыa,b,cи возвращает три результата:число корней,x1иx2.
Однако вернуть сразу три значения в C++ невозможно:
intRootsCount, numX1, numX2 = quadraticEquation (numA, numb, numC)<br><br>
intRootsCount = quadraticEquation (numA, numB, numC, &numX1, &numX2);
Здесь, опять же, от этого приема можно избавиться, возвращая объект или структуру, хранящую результаты выполнения функции в виде полей.
Пример:
Можно возвращать результаты решения квадратного уравнения в виде структуры с тремя свойствами[3]:
QuadrEqResult qerResult = quadraticEquation (numA, numB, numC);<br>intRootsCount = qerResult.count;<br>numX1 = qerResult.x1; <br>numX2 = qerResult.x2;
Однако и в первом, и во втором случае, при использовании структур или объектов, мы можем столкнуться с еще одной проблемой: необходимостью отдельно описывать эти структуры или классы.
Причем во многих языках, например на C++, мы не можем описать структуру или класс внутри самой функции (см. следующий раздел). Нам придется описывать их отдельно от функции, делая их неподчиненными функции сущностями, что уродует иерархию программы.
Слава богу, в других языках классы можно описывать прямо внутри функции, а, например в JavaScript можно просто возвратить объект, нигде отдельно не описывая его структуру.
Пример:
function quadraticEquation (numA, numb, numC)<br> {<br> //...<br> return ({<br> count: intRootsCount,<br> x1: intX1,<br> x2: intX2<br> });<br> }<br><br>var objResult = quadraticEquation (numA, numB, numC);<br>intRootsCount = objResult.count;<br>numX1 = objResult.x1; <br>numX2 = objResult.x2; <br>
Вот это настоящая красота!
Отсутствие локальных функций
В двух словах:
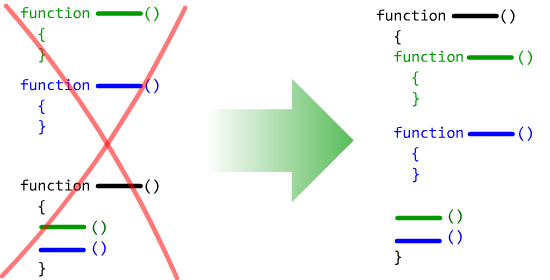
Как уже говорилось, программные системы (как объектно-ориентированные, так и процедурные) иерархичны и делятся на вложенные друг в друга модули (впрочем, это очевидно).
Каждый из модулей располагает своими локальными ресурсами, используемыми только в рамках этого модуля.
Например, локальные переменные являются ресурсами модуля функции.
Однако ресурсами функции являются не только переменные! Подфункции, классы, структуры и т.д. также являются полноправными ресурсами функции, подчиненными ей, и используемыми только в ее рамках.
| Объявление функций, структур и т.д. вне функции, которой они иерархически подчиняются — очень плохой прием. |
Пример:
Язык Pascal/Delphi поддерживает локальные функции, но, заставляет их объявлять только в начале функции. Это не так страшно, как объявлять только в начале все переменные, но тоже, иногда, бывает достаточно некрасиво.
Пример:
Предположим, у нас есть функция из нескольких блоков кода, каждый из которых выполняет отдельный шаг всего алгоритма.
Мы решили переписать один их блоков в рекурсивной форме.
Для этого мы переделали его в рекурсивную локальную функцию… после чего вынуждены перетащить этот блок кода (ставший теперь локальной функцией) с того места, где он используется, в начало основной функции.
program main (); function block3 (param: integer): integer; { (4)--¬ } begin { ^ v } Рекурсивный блок кода #3 { ^ v } end; { ^ v } {} { ^ v } procedure block5 (param: integer); { ^ v (7)--¬ } begin { ^ v ^ v } Рекурсивный блок кода #5 { ^ v ^ v } end; { ^ v ^ v } {} { ^ v ^ v } begin { ^ v ^ v } блок кода #1 { (1) ^ v ^ v } {} { v ^ v ^ v } блок кода #2 { (2) ^ v ^ v } {} { v ^ v ^ v } Прокручиваем на самый верх { v ^ v ^ v } и находим код рекурсивной функции block3 { v ^ v ^ v } block3 (param); { (3)--- v ^ v } {} { v ^ v } блок кода #4 { (5) ^ v } {} { v ^ v } Прокручиваем на самый верх { v ^ v } и находим код рекурсивной функции block5 { v ^ v } block5 (param); { (6)--- v } {} { v } блок кода #6 { (8) } end.
Как теперь прикажите читать эту функцию? Первый блок кода, второй, третий, пока, все нормально и понятно. Вдруг, хлоп, вызов рекурсивной подфункции, для чтения которой прокручиваем код к самому началу. Затем опять возвращаемся, назад и продолжаем читать обычные блоки. Не намного лучше, чем читать спагетти-код сgoto.
К счастью, поддержка локальных функций есть почти во всех «новых» языках, как динамических (JavaScript, Python), так и классических (Java). И надо только воспользоваться этой возможностью.
Отсутствие else if
В двух словах:
Уровень вложенности блока должен соответствовать его иерархическому положению в программе.
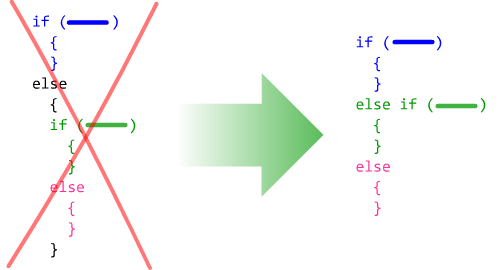
Блоки кода, имеющие одинаковый уровень вложенности, относятся к одному уровню иерархии программы. Соответственно, блоки кода с большим уровнем вложенности являются подчиненными по отношению к блокам с меньшей вложенностью.
Вроде бы, это очевидный факт.
Тем не менее, иногда, особенно в учебной литературе, я встречаю нарушение этого правила:
Когда блоки, логически находящиеся на одном уровне иерархии в программе, тем не менее, имеют разный уровень вложенности. Или наоборот, имеют разный уровень иерархии, но одинаковый уровень вложенности.
Пример 1:
Предположим, что нам надо приветствовать пользователя, в зависимости от времени суток. Приветствия «Спокойной ночи», «Доброе утро», «Добрый день», и «Добрый вечер» совершенно равноправны и относятся к одному уровню иерархии программы.
Поэтому этот код, где приветствия имеют разный уровень вложенности, страшно уродлив:
if (numHour >= 0 && numHour < 6)<br> {<br> print ("Спокойной ночи!");<br> }<br>else<br> {<br> if (numHour >= 6 && numHour < 12)<br> {<br> print ("Доброе утро!");<br> }<br> else<br> {<br> if (numHour >= 12 && numHour < 18)<br> {<br> print ("Добрый день!");<br> }<br> else<br> {<br> print ("Добрый вечер!");<br> }<br> }<br> }<br><br>Его надо переписать так, чтобы равноправные блоки имели равный уровень вложенности:
if (numHour >= 0 && numHour < 6)<br> {<br> print ("Спокойной ночи ");<br> }<br>else if (numHour >= 6 && numHour < 12)<br> {<br> print ("Доброе утро!");<br> }<br>else if (numHour >= 12 && numHour < 18)<br> {<br> print ("Добрый день!");<br> }<br>else<br> {<br> print ("Добрый вечер!");<br> }
Пример 2:
Предположим теперь, что мы должны проверить, зарегистрирован ли пользователь в системе, и, если зарегистрирован, то поприветствовать, а если нет — послать вон.
В данном случае, блоки кода приветствия имеют подчиненный уровень по отношению к блоку «зарегистрирован», а блок «пошел вон» — подчиненное к блоку «не зарегистрирован». Поэтому уродлив код, в котором все блоки имеют одинаковый уровень вложенности:
if (!isRegistred ())<br> {<br> print ("Вы не зарегистрированы в системе. Идите вон!");<br> }<br>else if (numHour >= 0 && numHour < 6)<br> {<br> print ("Спокойной ночи ");<br> }<br>else if (numHour >= 6 && numHour < 12)<br> {<br> print ("Доброе утро!");<br> }<br>else if (numHour >= 12 && numHour < 18)<br> {<br> print ("Добрый день!");<br> }<br>else<br> {<br> print ("Добрый вечер!");<br> }<br>
Его надо переписать так, чтобы уровень вложенности блоков соответствовал их иерархическому положению:
if (!isRegistred ())<br> {<br> /*<br> Не зарегистрирован<br> */<br> print ("Вы не зарегистрированы в системе. Идите вон!");<br> }<br>else<br> {<br> /*<br> Зарегистрирован<br> */<br> if (numHour >= 0 && numHour < 6)<br> {<br> print ("Спокойной ночи!");<br> }<br> else if (numHour >= 6 && numHour < 12)<br> {<br> print ("Доброе утро!");<br> }<br> else if (numHour >= 12 && numHour < 18)<br> {<br> print ("Добрый день!");<br> }<br> else<br> {<br> print ("Добрый вечер!");<br> }<br> }<br>
В некоторых старых языках программирования (по-моему, в каких-то древних версиях Паскаля или что-то в этом роде) были операторы
if и else, но отсутствовал оператор else if. Они навязывали прием, при котором каждый последующий блок в цепочке сравнений имел все больший уровень вложенности (как в примере №1).Но сейчас эти языки вымерли как динозавры, и все нормальные языки поддерживают
else if.Поэтому надо писать код, в котором уровень вложенности соответствует уровню иерархии блока, а также не поддаваться на провокации всяких вредных учебников.
Использование параллельных массивов
В двух словах:
При работе с вложенными данными следует соблюдать правила иерархии: свойства должны хранится внутри объекта,а НЕобъект — внутри свойства.
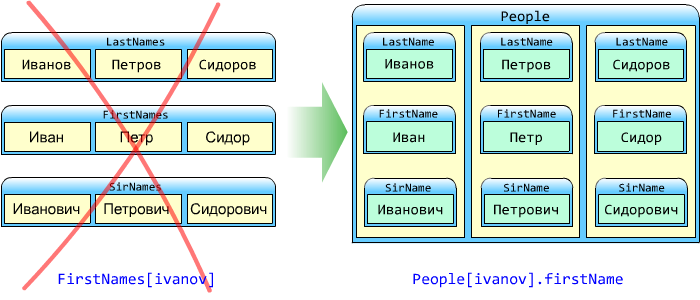
При работе с вложенными данными следует соблюдать правила иерархии.
Во-первых, связанные данные должны иметь общий контейнер.
Благодаря этому объект выглядит именно как объект, и не распадается на множество независимых свойств.
Также, мы можем работать с объектом как с единым целым, например, передавать его в качестве параметра функции и т.д.
Пример:
В данном примере видно, чтоlastName,firstName,sirNameотносятся к одному объекту:objPeople1.
objPeople1.lastName = "Пупкин";<br>objPeople1.firstName = "Василий";<br>objPeople1.sirName = "Иванович";<br><br><br>Мы можем работать с этим объектом не как с набором свойств, а как с единым целым:
doSomething (objPeople1);<br>
Во-вторых, при обращении к вложенным данным следует соблюдать иерархический порядок: сначала обращаться к корневому элементу, затем к вложенному в него элементу, затем к элементу с еще большей вложенностью и т.д.
Пример:
За время написания статьи Путин успел переехать:
World.Russia.Moscow./*Kremlin*/WhiteHouse.Putin<br>
Пример:
А в данном примере только с помощью иерархического порядка можно определить, что
синий пакет находится в красном:
redBag.blueBag.myThing<br><br>…или же красный в синем:
blueBag.redBag.myThing
В программах на объектно-ориентированных языках это правила иерархии почти всегда соблюдается.
Однако соблюдать правила иерархии при обращении к данным надо не только в объектно-ориентированных языках! Тем не менее, в программах на процедурных языках это правило нередко нарушается.
| Одним их вопиющих примеров уродского обращения к данным является использование так называемых параллельных массивов. |
Пример:
Предположим нам надо сохранить данные о советских лидерах, содержащие следующие свойства: фамилию, имя и отчество.
Каждое из этих свойств хранится в отдельном массиве:
char *lastNames [3] = {"Ленин", "Сталин", "Хрущев"};<br>char *firstNames [3] = {"Владимир", "Иосиф", "Никита"};<br>char *sirNames [3] = {"Ильич", "Виссарионович", "Сергеевич"};<br>const lenin = 0, stalin = 1, khrushchev = 2;
//Печатаем: "Никита Хрущев"<br>cout<<firstNames[khrushchev]<<" "<<lastNames[khrushchev];
При использовании параллельных массивов нарушаются все возможные правила работы с иерархичными данными.
Во-первых, записи распадаются на множество несвязанных полей. Мы не можем работать с записью как с единым объектом.
Пример:
doSomething(lastNames [lenin], lastNames [lenin], sirNames [lenin]);
Во-вторых, обращение к вложенным данным происходит «задом-наперед».
Запись
firstNames[khrushchev]
означает не Хрущева, хранящего свойствоfirstName, а, наоборот, свойство, хранящее внутри себя Хрущева!
<Текст сокращен из-за ограничений хабрапарсера...>
Разумеется, самым правильным и красивым решением является создание массива объектов или структур.Пример:
People *leaders [7] = <br> {<br> new People ("Ленин", "Владимир", "Ильич"),<br> new People ("Сталин", "Иосиф", "Виссарионович"),<br> new People ("Хрущев", "Никита", "Сергеевич"),<br> new People ("Брежнев", "Леонид", "Ильич"),<br> new People ("Андропов", "Юрий", "Владимирович"),<br> new People ("Черненко", "Константин", "Устинович"),<br> new People ("Горбачев", "Михаил", "Сергеевич")<br> };<br><br>//Эти константы – только для удобства чтения примера. В реальном коде их не будет<br>const lenin = 0, stalin = 1, brezhnev = 2, gorbachev = 6;<br><br><br>//Печатаем: "Владимир Ленин"<br>cout<<leaders [lenin].firstName<<" "<< leaders [lenin].lastName;<br><br>//Печатаем: "Леонид Брежнев"<br>cout<<leaders [brezhnev].firstName<<" "<< leaders [brezhnev].lastName;<br><br>//Печатаем: "Михаил Горбачев"<br>cout<<leaders [gorbachev].firstName<<" "<< leaders [gorbachev].lastName;<br>
Доступ к свойствам объекта через
object.getProperty () и object.setProperty (value)
В двух словах:
Для доступа к данным должны использоваться свойства, а НЕ методы.

У полей и методов объектов есть свое четкое предназначение:
Поля — хранят данные;
Методы — реализуют поведение объекта.
В нормальном коде ясно видно, где идет работа с данными, а где реализуется логика поведения объекта:
Работа с данными:
objObject.property1 = "value1";Поведение объекта:
objObject.doSomething (param1, param2);| Использование методов в качестве акцессора и мутатора поля — уродство. |
Нарушается естественная конструкция для доступа к данным через оператор присваивания. Оператор присваивания самой своей сутью подразумевает присваивание.
Вызов метода, само использование круглых скобок, подразумевает реализацию поведения объекта.
Во-вторых, чтение и запись свойства реализуется по-разному, что противоречит сути поля.
Пример 1:
При использовании свойств, для доступа к полю, как для чтения, так и для записи мы используем одну конструкцию:objObject.property1
intA = objObject.property1; //Чтение<br>objObject.property1 = intB; //Запись<br>
При использовании методов, для чтения и для записи поля используются разные конструкции:objObject.getProperty1 ()иobjObject.setProperty1 ():
intA = objObject.getProperty1 ();//Чтение<br>objObject.setProperty1 (intB); //Запись<br>
К полю не будет возможности применять стандартные операторы работы с данными, такие как
++, += и др. Пример 2:
Мы хотим увеличить значение свойства на 1.
objObject.property1++;
objObject.setProperty1 (objObject.getProperty1 () + 1);
Для обращения к защищенным полям объекта как к данным, используются свойства.
Пример 3:
КлассPersonхранит поле_money, доступ к которому осуществляется через свойство money:
class Person<br> {<br> private long _money;<br><br> public long money<br> {<br> get<br> {<br> return (_money);<br> }<br> set <br> {<br> _money = value;<br> }<br> }<br> }
Теперь мы можем нормально работать с данными:
Person psnBillGates = new Person (); lngOldRiches = psnBillGates.money; //Чтение psnBillGates.money = lngNewRiches; //Запись psnBillGates.money += 1000000000; //Инкрементация
Свойства поддерживает большое количество современных языков: Delphi, C#, Python, Ruby и др.
Однако немало языков свойства не поддерживают: C++, Java и даже гибкий и красивый JavaScript[4]…
Знаете, есть две вещи, которые обязательно надо добавить в JavaScript. Но это не классы и строготипизированные переменные, как думают многие. Отсутствие классов и строгих типов — это не баг, а фича, дающая JavaScript такую гибкость.
Две возможности, которых действительно не хватает в JavaScript — это перегрузка операторов и поддержка свойств[5].
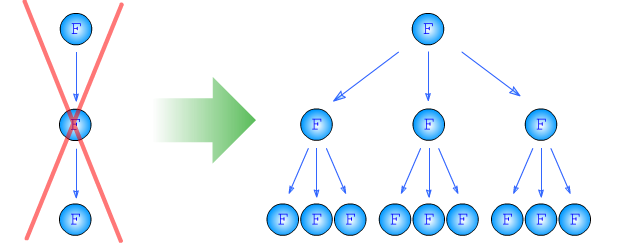
Использование рекурсии
для вычисления факториалов и Чисел Фибоначчи
В двух словах:
Рекурсию следует использовать только в тех случаях, когда решение задачи на каждом шаге разбивается на несколько подобных подзадач более низкого ранга
Здесь, в отличие от предыдущих разделов, я не буду столь категоричен.
Ибо рекурсия, или даже философия рекурсии, штука не такая простая.
И вопрос, когда следует (вернее, когда красиво) применять рекурсию, а когда нет, не столь однозначен.
Ну, в функциональных языках (таких как Lisp или Haskell) все понятно: рекурсия применяется всегда, когда надо выполнить любые повторяющиеся действия. Там даже сумма элементов массива (там он называется списком) определяется рекурсивно как сумма первого элемента + сумма оставшейся части. В этих языках такой подход гармонирует с философией языка и, потому, красив.
В императивных же языках все сложнее.
Мне кажется, что в этих языках смысл рекурсии состоит в разбиении задачи на несколько подобных подзадач более низкого ранга. А тех в свою очередь — на насколько под-подзадач, и так, в геометрической прогрессии, пока мы не дойдем до тривиального случая.
Пример 1:
При рекурсивном обходе дерева, мы разбиваем дерево на несколько поддеревьев (ветвей), каждое из поддеревьев на под-подеревья, и так, пока не дойдем до листов.
Пример 2:
При вычислении определителя матрицы, мы находим определители нескольких подматриц меньшего порядка (миноры), для нахождения же миноров, мы разбиваем каждую из подматриц на под-подматрицы и т.д. пока не дойдем до матриц 2*2.
Пример 3:
При сортировке массива слиянием мы сортируем несколько (обычно два) подмассивов этого массива. Для сортировки каждого подмассива мы сортируем их под-подмассивы, пока не дойдем до подпод…подмассивов длины 2.
Поскольку задача разбивается именно на несколько подобных подзадач, то количество данных (локальных переменных) на каждом шаге рекурсии увеличивается. Из-за этого заранее красиво объявить все эти локальные переменные в итеративном алгоритме не получится. Можно, конечно, вручную организовать стек, хранящий состояния каждой «итерации», но это уже будет замаскированная рекурсия, пусть и в обычном цикле без вызова функций. Что нелаконично, малопонятно и не очень красиво. И, соответственно лаконично и красиво использовать рекурсию.
Когда же задача не требует разбиения на несколько подобных, смысл рекурсии вырождается. И применять ее в таких случаях — некрасиво.
| Самым вопиющим примером уродского применения рекурсии является ее использование при вычислении факториала и чисел Фибоначчи. |
Как ни странно, эти задачи часто приводят в учебной литературе, причем в самом начале обучения рекурсии, в качестве первого примера. Быть может, рекурсия считается столь сложным для обучения приемом, именно из-за того, что ее объяснение ведется на совершенно противоестественных ее сути примерах…
Отсутствие именованных параметров функции
В двух словах:
Параметры любой нетривиальной функции должны задаваться по осмысленному имени, а НЕ положению в списке аргументов.
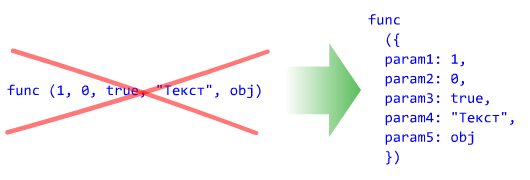
Никто не будет спорить с тем, что имена должны отражать суть перемененных. И что использование имен переменных вроде
a0, a1, a2 — не самый понятный и красивый прием.Точнее, не иметь осмысленного имени могут переменные, не являющиеся уникальными, входящие в состав коллекции, обрабатываемые не каждая отдельно, а вместе, в цикле.
Осмысленные имена должны быть у уникальных переменных, обрабатываемых отдельно.
Пример:
Программа, выводящая имя продукта, его кодовое имя и список глюков:
println ("Имя продукта: "+ objWinVista.name); //Windows Vista<br>println ("Кодовое имя: "+ objWinVista.codename); //Longhorn<br>println ("Число глюков: "+ objWinVista.bugsCount); //1 000 000 000 :-)<br>println ("Список глюков:");<br>for (long numBugNumber = 0; numBugNumber < objWinVista.bugsCount; numBugNumber++)<br> {<br> println (objWinVista.bugs [numBugNumber]);<br> }
В данном примереname,codenameиbugsCountявляются уникальными данными и обрабатываются отдельно, поэтому имеют осмысленные имена.
Каждый же из глюковbugs [i]уникальным не является, поэтому имеет не осмысленное имя, а просто номер.
Параметры функции являются такими же полноценными переменными. Однако при вызове функции мы задаем параметр не по его осмысленному имени, а по положению в списке параметров, т.е. по номеру. Это еще хуже, чем переменные
a0, a1, a2.Пример:
Вот примеры из официальной документации к Java 2D:
GradientPaint gp = new GradientPaint (50.0f, 50.0f, Color.blue, 50.0f, 250.0f, Color.green);
или
RotationInterpolator rotator = new RotationInterpolator (<br> new Alpha (-1, Alpha.DECREASING_ENABLE, 0, 0, 8000, 0, 0, 0, 0, 0),<br> xformGroup, axis, 0.0f, (float)Math.PI*2.0f);
Что означают эти параметры:-1, Alpha.DECREASING_ENABLE, 0, 0, 8000, 0, 0, 0, 0, 0?
Есть только два случая, когда можно использовать неименованные параметры функции.
Первый случай, это когда параметров немного (не больше 3), и их предназначение очевидно.
Пример:
Math.pow (2, 5)вряд ли можно интерпретировать иначе как 25. Ну, разве что, как 52 :-)
Второй случай, это когда каждый из параметров не является уникальным, и не имеет собственного предназначения.
Пример:
Функция, суммирующая числа:Math.summ (3, 7, 18, -2, 11, 2.3)
| Во всех остальных случаях параметры надо задавать по осмысленным именам. |
Пример (perl):
Функция перевода текста.
$strResult = translate text => "Hello, world!", from => $lngEnglish, to => $lngRussian, vocabulary => $vcblrGeneral, quality => 10;
Что же делать в остальных языках?
В процедурных языках (вроде C или Pascal) проблема вызова функций с большим количеством малопонятных параметров стоит особенно остро.
Для ее решения вместо передачи большого числа параметров, можно создать структуру, в которой поля будут соответствовать параметрам функции; затем, обращаясь через поля с осмысленными именами записать в структуру нужные данные; и вызвать функцию, передав ей структуру в качестве параметра.
Пример:
//rectangle1 – структура для хранения параметров функции Rectangle rectangle1; //Задаем параметры функции rectangle1.x = 80; //x rectangle1.y = 25; //y rectangle1.width = 50; //ширина rectangle1.height = 75; //высота rectangle1.rotation = 30; //угол наклона rectangle1.borderWeight = 2; //толщина контура rectangle1.borderColor = "red"; //цвет контура rectangle1.backgroundColor = "blue"; //цвет заливки rectangle1.alpha = 20; //процент прозрачности //Вызываем функцию, передавая ей структуру с параметрами drawRectangle (rectangle1);
Гораздо больше кода, но

