Искусственный интеллект все чаще используется в медицинских целях, в частности для анализа медицинских изображений. Это прекрасный помощник для врачей-рентгенологов, который позволяет определять даже едва различимые человеческому глазу признаки патологий и вообще разгружает медицинских специалистов за счет автоматизации ряда рутинных задач.
Мы, в том числе, создаем нейросети для обработки КТ-исследований, например для оценки поражения легких при COVID-19 пневмонии (кстати, вы знали, что врачи оценивают процент поражения легких ковидного пациента “на глаз”?). Процесс создания качественной и эффективной нейросети долгий и дорогой. Более того, данных для обучения зачастую недостаточно.
Например, для классического обучения нейронных сетей необходимо много размеченных данных. Это ресурсозатратный процесс, как по стоимости, так и по времени, так как в качестве аннотаторов выступают врачи-рентгенологи. Кроме того, размеченным снимкам необходима повторная валидация. Например, пропуск диагнозов при анализе врачом КТ-снимков может составлять до 42% [1]. Также данные довольно разнообразны, это тоже проблема: разные дозы облучения при исследовании, положение пациента, особенности КТ-аппарата.
Именно по этим причинам мы решили исследовать различные подходы, которые могли бы помочь сократить число необходимых аннотированных данных для получения модели того же качества. Это может позволить не только сократить время и расходы на аннотацию, но и ускорить цикл поставки новых моделей.
В результате нашего исследования, мы нашли лучший подход, который помог сохранить точность работы алгоритма при использовании лишь 20% разметки.
Магия - нет, расскажем подробнее…
Целевая задача
Мы решили создать модель для анализа КТ органов грудной клетки “ковидных” пациентов, в качестве патологии выбрали матовое стекло. Почему именно этот симптом? Во-первых, он часто возникает на фоне COVID-19 (у 61.4%-91% пациентов [2, 3]). Патология представляет собой уплотнения легочной ткани, альвеолы заполняются жидкостью и, как следствие, затрудняется дыхание. Во-вторых, патология может иметь сложные паттерны, что затрудняет исследование (см. рисунок ниже). При обнаружении “матового стекла” необходимо тщательно обследовать пациента, так как он подвергается большой опасности при заболевании COVID-19.

При анализе снимков необходимо учитывать, что КТ-снимок — это объемное изображение (3D), содержащее целевой орган. Эту особенность можно использовать в анализе объемных патологий – на вход алгоритму подается не один снимок, а набор последовательно идущих, что позволяет передать контекст и дает больше информации алгоритму об окружении.

План эксперимента
Для имеющихся данных (КТ-снимков легких) решается задача сегментации патологии “матовое стекло” с использованием классической нейронной сети U-net [6], лежащей в основе модели .
Для получения референсных значений мы обучили целевую модель классическим способом (supervised) на данных с полной аннотацией (размечен каждый срез на всех исследованиях).

Качество работы данной модели берется как эталонное, именно такие метрики мы и хотим сохранить или улучшить при дальнейших экспериментах. Вторым этапом мы проверяем, какое качество мы получим, если классическим образом supervised обучим ту же модель на данных с 20% аннотации. Для этого этапа и последующих экспериментов срезы с аннотацией выбираются не случайно, а по следующему правилу: в каждом исследовании берется разметка только для каждого пятого срезы. Далее мы начали пробовать более свежие методы, которые являются представителями подходов self-supervised и semi-supervised, используя также только часть аннотации.

Исследование подхода №1
Semi-supervised Contrastive Learning for Label-efficient Medical Image Segmentation
Основная идея контрастивного обучения заключается в подготовке пространства признаков за счет использования только исходных данных. Сейчас наша задача – обучить сеть давать схожие вектора признаков на схожих примерах. В данном случае на вход подается два примера – оригинальное изображение x и аугментированное x’ и расстояние между векторами должно быть минимальным. Таким образом можно быстрее и качественнее обучить сеть на целевую задачу благодаря утилизации всех неразмеченных данных. Зачастую при использовании такого подхода предобучается только Encoder на всех данных (a)[4], после чего Decoder обучается обычным supervised на размеченных данных (c)[4]. Метод отличается тем, что авторы статьи придумали, как обучать ещё и Decoder с помощью подхода локального контрастивного обучения (b)[4]. Это достигается за счет работы не с векторами признаков, полученными из энкодера, а уже с картами признаков, получаемыми из ветки декодера.

Таким образом на первом этапе обучается только Encoder; фичи, полученные после AVG слоя, сравниваются с помощью контрастивного лосса:
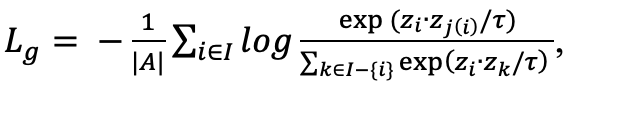
где z_i и z_j - значения выхода Encoder x и x’, а z_t – все остальные результаты обработки батча.
Как было сказано ранее, первый этап - лишь подготовка части модели, далее следующим мы дообучаем модель с аннотацией в supervised манере. На рисунке ниже показан полный пайплайн обучения.

Достаточно часто в качестве функции потерь используют Dice [7], он обозначает меру схожести классов между ground truth и prediction (также известный как F-1 мера):
D(P, G) = 2 |G∩P| / (|G| + |P|)
Однако он имеет несколько недостатков, так как оперирует целыми числами и не учитывает вероятностных значений prediction. Во-первых, необходимо подобрать threshold, который будет напрямую влиять на правильность результата. Во-вторых, для классического Dice без разницы, какая вероятность была у класса, например, если граничное значение равно 0, то значение 0.1 и 0.9 будут одинаково расценены как класс 1.
![a - Continuous Dice учитывает низкие вероятности при расчете ошибки, b - все ошибки для Dice - равноценны [8]](https://habrastorage.org/r/w1560/getpro/habr/upload_files/459/df5/dc2/459df5dc26532f43c626b2cad89a3da9.png "a - Continuous Dice учитывает низкие вероятности при расчете ошибки, b - все ошибки для Dice - равноценны [8]")
Continuous Dice – более подходящая функция ошибки в рамках данной задачи, так как он учитывает вероятности выхода и штрафует за ошибки аддитивно их вероятностям.

Исследование подхода №2
Transformation-consistent Self-ensembling Model for Semi-supervised Medical Image Segmentation
Не менее интересный подход – согласованная с преобразованием самоорганизующаяся модель для обучения с частичным привлечением учителя. Идею можно передать следующим примером – если мы подадим на вход нейронной сети повернутую на 90 градусов картинку, то получим тот же результат, если мы сначала повернем изображение на 90 градусов, а потом уже подадим в нейронную сеть. Таким образом, кроме поворота могут быть и другие преобразования (a)[5].
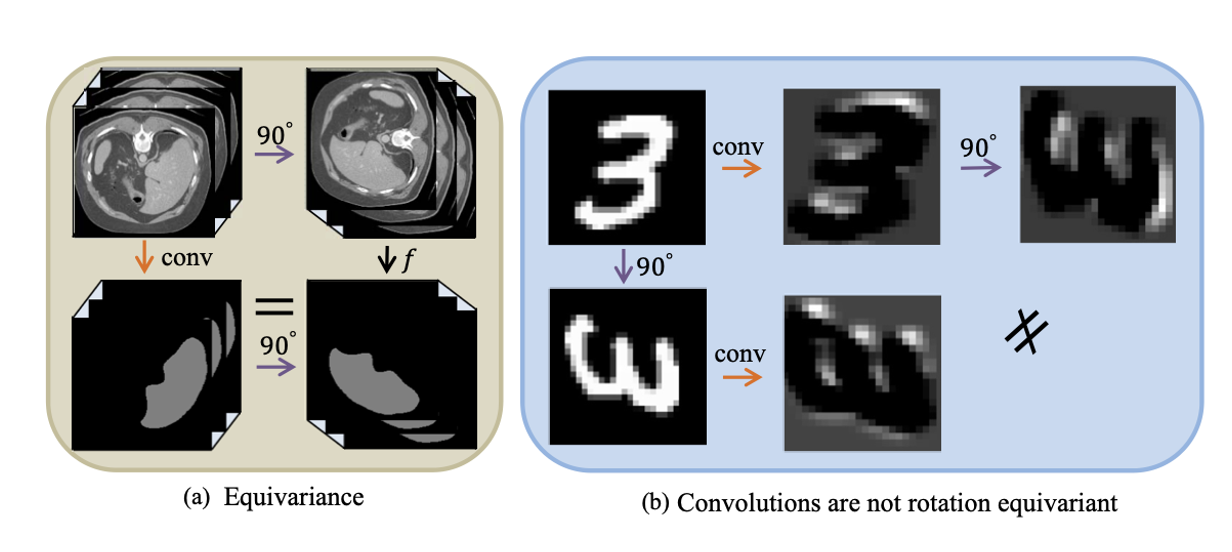
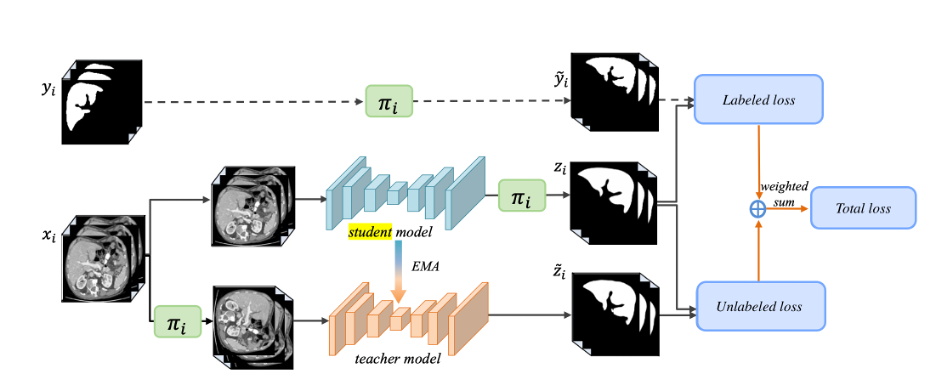
Однако важно понимать, что нейронные сети – нелинейные алгоритмы, поэтому одинаковые маски на выходе мы не получим (b)[5]. Эту идею сформулировать как функцию потерь.На основе этой идеи был создан алгоритм TCSM (transformation consistent self-ensembling model). Есть сеть “студент” и её копия ”учитель”, которая должна предсказывать маски. В сеть-ученик передается оригинальное изображение, в сеть-учитель – измененное, потом с помощью тех же самых преобразований меняем выход сети-ученик. Результат должен быть одинаковым. Так как сеть-учитель выступает в качестве среднего сглаживающего фильтра состояний модели-студента, то это позволяет использовать неразмеченные данные без потери консистентности предсказаний моделей (учитель, ученик) в процессе обучения. И так для всех исходных изображений обучаем таким пайплайном сети, используя соответственно Unlabeled loss. Для изображений с аннотациями – просто сравниваем выход сеть-учитель с целевой маской и используем для расчета ошибки labeled loss.
Результаты
Полученные модели мы оценили по метрикам Dice и объемный Dice (VolDice), который используется для оценки всего исследования как целого 3D объекта. Метрики были рассчитаны для каждого класса, где 0 - норма (отсутствие патологии), 1 - матовое стекло.
Dice_0 | Dice_1 | VolDice_0 | VolDice_1 | |
Supervised, 100% аннотированных данных | 0.997
| 0.423
| 0.997 | 0.627 |
Supervised, 20% аннотированных данных | 0.991
| 0.258
| 0.99
| 0.405
|
Contrastive Learning | 0.995
| 0.315
| 0.994
| 0.484
|
TCSM | 0.997
| 0.43
| 0.996
| 0.639
|
Из таблицы следует, что выбранные алгоритмы обучения позволяют сохранить качество модели при обучении на данных с низкой плотностью аннотации, при этом оба алгоритма по целевым метрикам превосходят модель, обученную на 20% аннотированных данных.
На рисунке приведены примеры результатов обработки КТ-снимков из тестового набора моделью, обученной на данных с полной аннотацией, и TCSM моделью, обученной на данных, имеющих в 5 раз меньше аннотаций. Примеры иллюстрируют, что согласованная модель может справляться с задачей сегментации не хуже, чем эталонная модель, что подкрепляет достигнутые метрики из таблицы
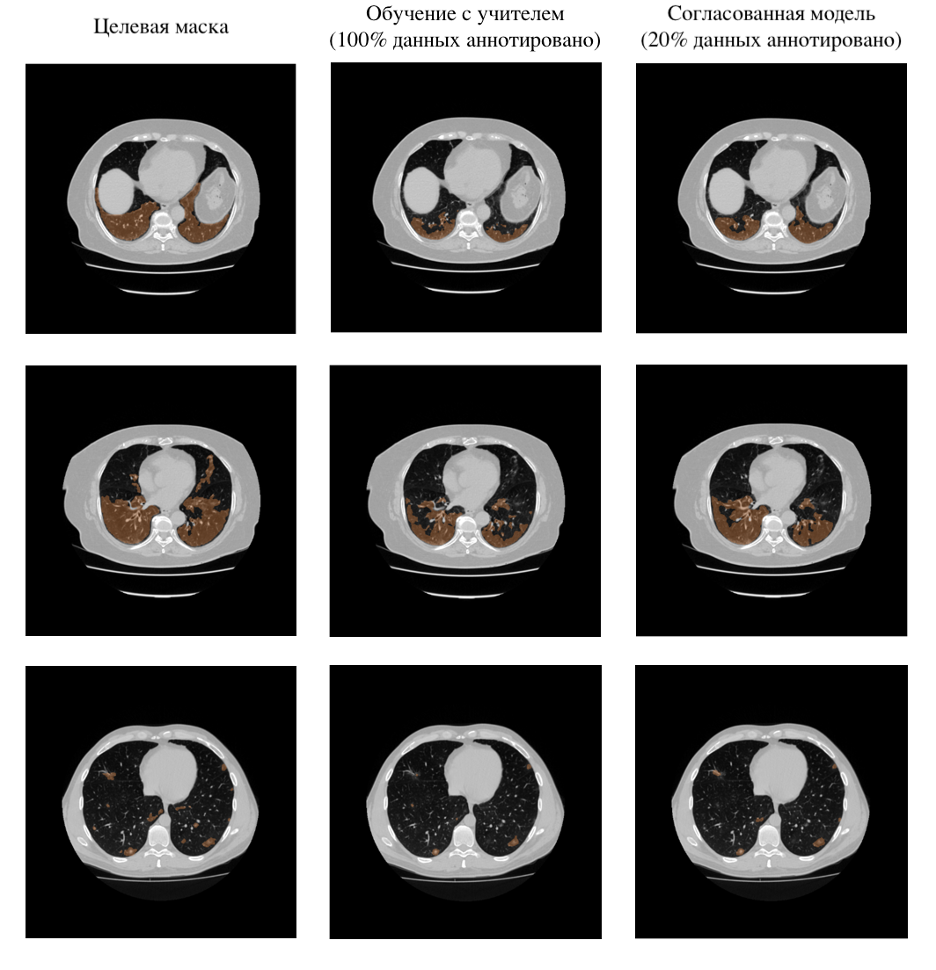
Таким образом, утилизация неразмеченных данных и использование подходов обучения моделей без учителя или с частичным его привлечением для сегментации КТ-снимков позволяет сохранить качество работы модели, при этом число необходимых данных с разметкой сокращено в 5 раз, а это уменьшает минимальную необходимую стоимость аннотации данных, сокращает время разметки в 3-4 раза, а, значит, сокращает и время на цикл разработки или улучшения моделей.
А как вы сокращали время и расходы на ручную аннотацию данных? Поделитесь опытом?:)
Беляков Дмитрий
Старобыховская Анастасия

