
Как-то раз мне понадобилось несколько наборов строк с коллизией по хеш-коду. То есть таких, чтобы значение
String::hashCode() совпадало для всех строк в наборе.Блуждание по интернету не дало результатов, примеров было мало и все они довольно однообразны. Поиск по словарям подарил забавную пару
"javascript's".hashCode() == "monocle".hashCode(), но практической пользы не принёс. Полный перебор не рассматривался в виду скорой тепловой смерти вселенной.Тот самый случай, когда проще сделать всё самому. Стандартная хеш-функция строки в Java считается криптографически нестойкой, так что знаний из школьного курса математики должно быть достаточно.
Коллизии
Для начала взглянем на
String::hashCode() из Java 8:
String::hashCode()
/** * Returns a hash code for this string. The hash code for a * {@code String} object is computed as * <blockquote><pre> * s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1] * </pre></blockquote> * using {@code int} arithmetic, where {@code s[i]} is the * <i>i</i>th character of the string, {@code n} is the length of * the string, and {@code ^} indicates exponentiation. * (The hash value of the empty string is zero.) * * @return a hash code value for this object. */ public int hashCode() { int h = hash; if (h == 0 && value.length > 0) { char val[] = value; for (int i = 0; i < value.length; i++) { h = 31 * h + val[i]; } hash = h; } return h; }
Хеш-код непустой строки вычисляется по формуле:
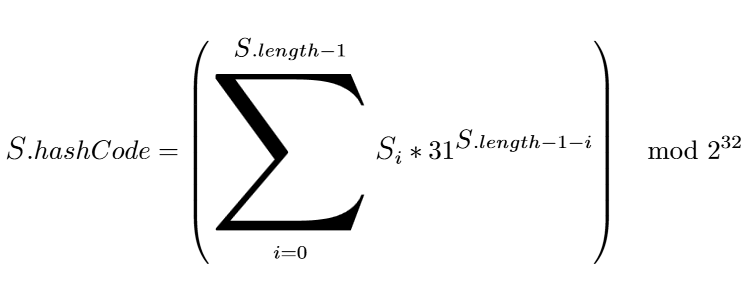
Взятие остатка от деления случается при переполнении разрядной сетки типа
int, остальная часть формулы очевидна из кода и описания.Так как каждое слагаемое зависит только от кода символа и его удалённости от конца строки, то мы можем заменить произвольную подстроку на другую с таким же хеш-кодом и длиной, хеш-код модифицированной строки при этом будет совпадать с хеш-кодом оригинальной.
При замене начала строки требование на совпадение длин исчезает, так как больше нет символов, на которые такое несовпадение может повлиять.

Простейший алгоритм генерации коллизий очевиден:
- Берём произвольные два подряд идущих символа в строке, Ci и Ci + 1
- Код символа Ci увеличиваем на целое положительное число N
- Компенсируем увеличение первого символа уменьшением кода символа Ci + 1 на 31 * N.
- Повторяем это действие с произвольными парами символов в строке до тех пор, пока нам не надоест.
Главное ограничение: коды изменённых символов должны оставаться в диапазоне значений типа
char, от 0 (\u0000) до 65_535 (\uFFFF) включительно.Именно этот приём чаще всего используется в примерах из интернета.
https://stackoverflow.com/a/1465719:
"0-42L" "0-43-"
https://stackoverflow.com/a/12926279:
"AaAa" "BBBB" "AaBB" "BBAa"
Если же пара строк с идентичными хеш-кодами нужна нам здесь и сейчас, а калькулятора под рукой нет, то добавив в начало любой строки префикс
"Хабрахабр -- торт! ЧЫМДШРС " (без кавычек) мы с лёгкостью получим такую пару в своё распоряжение.Прообразы
Это было совершенно не трудно. Пойдём дальше и попробуем найти первый прообраз, то есть сгенерировать строку, имеющую нужный нам хеш-код.
Алгоритм расчёта хеш-кода строки очень похож на перевод 31-ричного числа из строкового представления в числовое, воспользуемся этим. Нашими «цифрами» будут 31 первых символа Unicode, от
\u0000 до \u001E, а алгоритм — совершенно стандартным. В рамках данной статьи будем рассматривать хеш-код как 32-битное беззнаковое целое, представление в дополнительном коде позволяет нам такую вольность.
private static String findFirstPreimage(int hash) { StringBuilder builder = new StringBuilder(); for(long current = Integer.toUnsignedLong(hash); current != 0; current /= 31L) { builder.insert(0, (char) (current % 31L)); } String result = builder.toString(); assert hash == result.hashCode(); return result; }
Как нетрудно убедиться, этот подход действительно работает и выдаёт строки с нужными нам параметрами. Но есть у него и серьёзный недостаток: все символы в сгенерированных строках — непечатные. IntelliJ IDEA, к примеру, показывает такие строки и в отладчике, и во встроенной консоли неотличимыми от состоящих из одних пробелов.
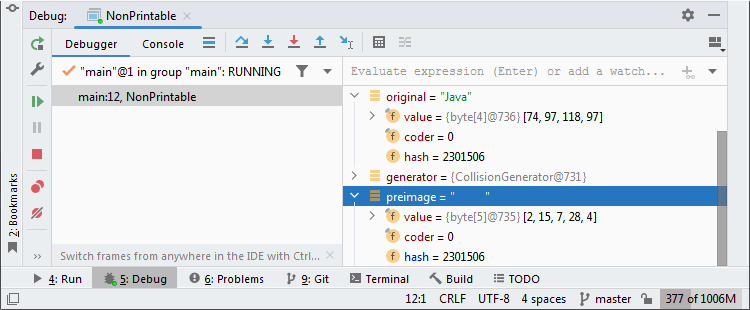
Отлаживать программу с такими значениями неудобно, а кое-где такие строки и вовсе могут посчитать некорректными входными данными.
Впрочем, ничто не мешает нам использовать любые другие идущие подряд символы. Диапазон
Б… Я отлично подойдёт на эту роль. Хеш-коды генерируемых строк при такой подмене по-прежнему будут монотонно возрастать с шагом в единицу, но появится и несколько особенностей.Хеш-код сгенерированной строки будет иметь смещение, напрямую зависящее от её длины и первого символа используемого диапазона, он выступает в роли нуля. К примеру, для строки длиной в три символа и буквы
Б в качестве первого символа алфавита оно будет равно Integer.toUnsignedLong("БББ".hashCode()).Это смещение необходимо учитывать и делать на него поправку. Причём, для каждой пары ( <первый символ диапазона>, <длина> ) эта поправка будет своей.
Все наши вычисления проходят в кольце вычетов по модулю 232, а потому узнать величину поправки элементарно. Достаточно взять строку из
N «нулей» и вычесть хеш-код этой строки из значения 232. Результатом будет число, на которое нужно увеличить значение хеш-кода для генерации правильной последовательности символов.Так мы приходим к улучшенной версии нашего алгоритма. Для удобства использования реализуем его в виде итератора.
class PreimageGenerator { ... }
import java.util.Arrays; import java.util.Iterator; import java.util.NoSuchElementException; /** * * String hash preimage generator. * * @author Maccimo * */ public class PreimageGenerator implements Iterator<String> { private static final long MODULO = (1L << 32); private static final double LOG_31 = Math.log(31); private static final char MAX_ALLOWED_CHAR = Character.MAX_VALUE - 30; private final char alphabetStart; private final long[] hashCorrectionTable; private long nextHash; /** * Construct string hash preimage generator. * This constructor accept ordinary string hash code, as if returned from {@link String#hashCode()}. * * @param hash string hash code * @param alphabetStart first of 31 consequent symbols, used to generate strings * * @throws IllegalArgumentException thrown if {@code alphabetStart} value is too large */ public PreimageGenerator(int hash, char alphabetStart) { this(Integer.toUnsignedLong(hash), alphabetStart); } /** * Construct string hash preimage generator. * This constructor accept unsigned long hash code, can be calculated from ordinary hash code by invoking * {@link Integer#toUnsignedLong(int)}. * * @param hash string hash code * @param alphabetStart first of 31 consequent symbols, used to generate strings * * @throws IllegalArgumentException thrown if {@code alphabetStart} value is too large or {@code hash} value is negative */ public PreimageGenerator(long hash, char alphabetStart) { if (alphabetStart > MAX_ALLOWED_CHAR) { throw new IllegalArgumentException( String.format( "Wrong alphabetStart value U+%04X. We need at least 31 symbol to work properly, only %d available.", (int) alphabetStart, Character.MAX_VALUE - alphabetStart + 1 ) ); } if (hash < 0) { throw new IllegalArgumentException( String.format( "Wrong hash value %,d. Must be non-negative.", hash ) ); } this.nextHash = hash; this.alphabetStart = alphabetStart; this.hashCorrectionTable = precomputeHashCorrection(alphabetStart); } /** * Returns {@code true} if preimage generator has more elements. * (In other words, returns {@code true} if {@link #next} would * return an element rather than throwing an exception.) * * @return {@code true} if preimage generator has more elements */ @Override public boolean hasNext() { return nextHash >= 0; } /** * Returns the next colliding string for given hash code. * * @return the next colliding string * @throws NoSuchElementException if the iteration has no more elements */ @Override public String next() { if (nextHash < 0) { throw new NoSuchElementException(); } int length; int correctedLength = 0; long hashCorrection; do { length = correctedLength; hashCorrection = hashCorrectionTable[length]; correctedLength = calculateLength(nextHash + hashCorrection); } while (correctedLength > length); String result = generate(nextHash + hashCorrection, length); nextHash = nextHash + MODULO; return result; } private String generate(long hash, int length) { assert hash >= 0 : hash; char[] buffer = new char[length]; Arrays.fill(buffer, alphabetStart); int i = length - 1; for(long current = hash; current != 0; current /= 31L) { buffer[i--] = (char) (alphabetStart + current % 31L); } return String.valueOf(buffer); } private static long[] precomputeHashCorrection(char alphabetStart) { int maxLength = calculateLength(Long.MAX_VALUE); long[] result = new long[maxLength + 1]; int correction = 0; for (int i = 0; i < result.length; i++) { result[i] = (MODULO - Integer.toUnsignedLong(correction)) % MODULO; correction = correction * 31 + alphabetStart; } return result; } private static int calculateLength(long number) { return number == 0 ? 0 : 1 + (int) log31(number); } private static double log31(long number) { return (Math.log(number) / LOG_31); } }
Простейшим примером использования будет код, генерирующий 16 строк с таким же хеш-кодом, что и у строки
"Java".public class PreimageGeneratorDemo { private static final int COUNT = 16; private static final char ALPHABET_START = 'Б'; private static final String ORIGINAL_STRING = "Java"; public static void main(String... args) { PreimageGenerator generator = new PreimageGenerator( ORIGINAL_STRING.hashCode(), ALPHABET_START ); boolean allHashesValid = true; for (int i = 0; i < COUNT; i++) { String preimage = generator.next(); allHashesValid &= (ORIGINAL_STRING.hashCode() == preimage.hashCode()); System.out.printf("\t\"%s\"%n", preimage); } System.out.println(); if (allHashesValid) { System.out.println("All generated strings are valid."); } else { System.out.println("Some of generated strings are invalid!"); } System.out.println(); System.out.println("Done."); } }
Хеш-код, для которого нам нужно найти первый прообраз и начальный символ используемого алфавита передаются параметрами в конструктор класса
PreimageGenerator. Каждый вызов метода next() будет возвращать всё новые и новые значения первого прообраза для заданного хеш-кода.Так будет длиться до тех пор, пока метод
hasNext() не вернёт значение false. Внутреннее состояние генератора представлено типом long, что даёт нам примерно два миллиарда различных значений.Two billion strings ought to be enough for anybody.
Десерт
На десерт нам досталась фраза
"Хабрахабр -- торт! " (без кавычек). Мы хотим научиться вставлять её в начало любой строки и в результате получать строку с тем же хеш-кодом, что был у оригинала. Как мы уже выяснили в первой главе, для такого фокуса хеш-код вставляемой строки должен быть равен нулю.У нашей фразы он отличен от нуля и значит необходимо вычислить строку, добавление которой изменит его в нужную сторону.
Для этого решим уравнение

Вспомним формулу из первой главы и преобразуем уравнение в эквивалентное

Значение
P.hashCode нам уже известно, это хеш-код нашей фразы, интерпретированный как 32-битное беззнаковое целое. Подставив его в формулу мы сможем найти нужный нам хеш-код суффикса. Генерировать подходящую строку по известному хеш-коду мы научились во второй главе.Для фразы
"Хабрахабр -- торт! " он равен -1_287_461_747 или 3_007_505_549L, если рассматривать его как беззнаковое целое. Для упрощения расчётов зафиксируем длину суффикса 7 символами.
Полученную константу
3_196_431_661L используем для инициализации PreimageGenerator и получаем набор подходящих суффиксов.
Они же, в виде текста
"Хабрахабр -- торт! ИГУБЧПЮ" "Хабрахабр -- торт! МЭУХЦЙГ" "Хабрахабр -- торт! СШФКХВЗ" "Хабрахабр -- торт! ЦУФЮУЪЛ" "Хабрахабр -- торт! ЫОХУТУП"
Остался последний штрих: наша строка-префикс неэстетично сливается с остальным текстом, обособим её пробелом в конце.
Для этого в правой части уравнения вместо нуля должно быть значение хеш-кода строки до того, как финальный пробел обнулит его. Чтобы получить нужное значение вычтем из нуля код символа пробела, он равен 32, и разделим полученное значение на 31.
Так как нам нужно целое неотрицательное решение, то вычитание 32 из нуля мы заменим на сложение с его противоположным числом, равным 232 — 32, а деление полученной разницы на
31 — умножением на обратное ему число — 3_186_588_639L.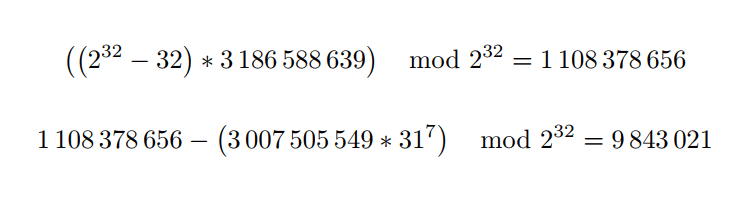
Константу
9_843_021L всё так же используем для инициализации PreimageGenerator и смотрим что получится.
Они же, в виде текста
"Хабрахабр -- торт! ДРЙСЭНБ " "Хабрахабр -- торт! ЙЛКЖЬЖЕ " "Хабрахабр -- торт! ОЖКЪЪЮЙ " "Хабрахабр -- торт! УБЛПЩЧН " "Хабрахабр -- торт! ЧЫМДШРС " "Хабрахабр -- торт! ЬЦМШЧЙХ "
Заключение
Задача выполнена полностью и теперь в нашем распоряжении бесконечное количество строк с совпадающими хеш-кодами.

