Классификация текста количеством более двух меток одна из самых сложных задач в машинном обучение. Как, правило сырые данные перед обучением модели требуют серьёзной обработки.
Впервые с подобной задачей я столкнулся на своей работе – было необходимо обработать текст обратной связи посетителей портала с ограниченным количеством символов - около ста слов – сообщения могли состоять как из одного слова, так и из нескольких предложений. Количество классов – пять, от очень плохой «эмоциональной окраски» сообщения до очень хорошей.
Данные

По причине NDA я не могу демонстрировать данные, которые предоставил клиент, поэтому специально для этой статьи я собрал собственный сет данных отзывов об отелях – стандартная история для классификации тональности.
Мой «демонстрационный» сет данных содержит 163830 текстовых сообщений (желающие могут скачать по ссылке), как и у данных клиента, в сете присутствует сильный дисбаланс в классах, что очень ощутимо сказывается на итоговой точности предсказания.

На порядок меньше отзывов с метками 1 и 3, и напротив крупный перевес представляет 5-ый класс.
Так же тексты весомо отличаются по своей длине, при средней длине отзыва 50 токенов присутствуют крупное кол-во, превышающее значения 100 токенов – встречаются тексты и более тысячи.
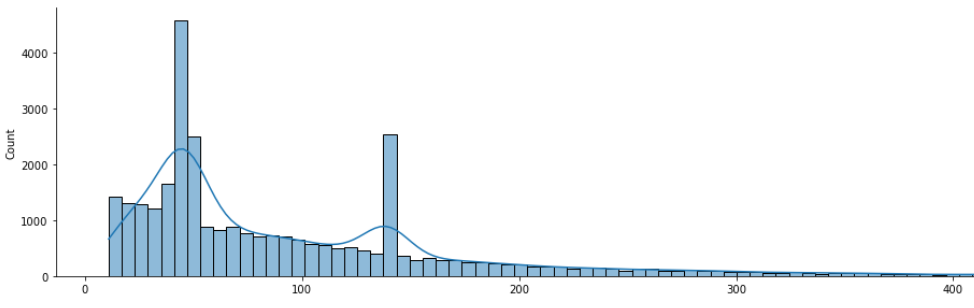
Тестовые данные для чистоты эксперимента я выделил в отдельный фрейм размером 25000 строк – по 5000 сообщений на каждый класс. Моделируя реальную задачу, в тестовый набор я добавлял только сообщения с количеством токенов от 1 до 100.
Задача
В этом исследование я хочу разобрать отдельный сегмент предобработки данных, а именно показать, насколько балансировка тренировочных данных может качественно повлиять на конечный результат, а также чуть глубже погрузиться в суть работы механизма взвешивания слов TF-IDF
Генерация данных
Первым делом определимся с необходимым количеством отзывов для каждого класса. Я посчитал что 30-35 тысяч отзывов будет оптимальным решением. Необходимо сгенерить 20к текстов для первого и для третьего класса, а 15 тысячами текстов для 5-го придётся пожертвовать.
Существует множество способов генерации текста, в том числе с применением различных библиотек, я же реализую наиболее «дешевый» с точки зрения времени вычисления вариант, основанный на частоте использования биграмм тренировочного корпуса. В данной задаче для нас не имеет значение семантический аспект генерируемых предложений, так для взвешивания токенов будет использоваться метод TF-IDF. Далее в статье я подробней остановлюсь на этом методе, а здесь оставлю мой вариант скрипта, генерирующего текст для первого класса (очень плохие отзывы).
Первым делом напишем функцию (tokenize_sentences) разбиения текстов корпуса, которая возвращает список токенов, разделённых фиктивным токеном ('END_SENT_START') в конце каждого предложения. ['начнем', 'с', 'того', 'что', 'в', 'этом', 'отеле', 'не', 'берут', 'деньги', 'только', 'за', 'воздух', 'END_SENT_START', 'звонок', 'с', 'телефона', ...]
import pandas as pd import numpy as np import sklearn import re import nltk from nltk import tokenize from nltk.tokenize import RegexpTokenizer def get_text_for_label(df, label): # Получим список с текстами для каждого класса label = 'label == ' + str(label) df_label = df.query(label).drop(['label'], axis=1) return df_label.feedback.values.tolist() feedback_label_1 = get_text_for_label(df_fin_feedback, 1) # К примеру, список для первого класса def tokenize_sentences(text_corp): # Функцию разбиения текстов корпуса на токены с разбивкой по предложениям token_corp = [] for text in text_corp: text = re.sub(r'\s+', ' ', text, flags=re.M) for sent in re.split(r'(?<=[.!?…])\s+', text): sent = sent.replace('\n',' ') for word in sent.split(): token = re.search(r'[а-яёА-ЯЁa-zA-Z]+', word, re.I) if token is None: continue token_corp.append(token.group().lower()) token_corp.append('END_SENT_START') # В конце каждого предложения добавляем фиктивный токен return token_corp token_label_1 = tokenize_sentences(feedback_label_1) # К примеру, список для первого класса
На вход следующей функции поступает получившийся список токенов. Функция возвращает словарь с группированными биграммами: ключи – отдельные токены, в значение – список слов которые следуют за ними в корпусе с собственной частотой ( { 'отель': [('отличным', 4.116e-06), ('вобщем', 2.058e-06), …)
from collections import Counter, defaultdict def get_bigramms(token_list): bigramm_corp = [] for i in range(len(token_list)-1): bigramm = token_list[i] + ' ' + token_list[i+1] bigramm_corp.append(bigramm) # Получим список биграмм unique_token_count = len(set(bigramm_corp)) # кол-во уникальных биграмм bigramm_proba = {} # Создаю словарик для результата: Ключ - биграмма. Значение - вероятность count_bigramm = Counter(bigramm_corp) # Создаю словарь для хранения частот биграмм count_token = Counter(token_list) # Создаю словарь для хранения частот токенов # Создаю словарь с группированными биграммами: ключи – отдельные токены, # в значение – список слов которые следуют за ними в корпусе # с собственной частотой ( { 'отель': [('отличным', 4.116e-06), ('вобщем', 2.058e-06), …) grouped_bigramms = defaultdict(list) for bigramm in set(bigramm_corp): first_word, second_word = bigramm.split() proba = (count_bigramm[bigramm] + 1) / (count_token[first_word] + unique_token_count) # Формула Лапласа grouped_bigramms[first_word].append((second_word, proba)) return grouped_bigramms grouped_bigramm_1 = get_bigramms(token_label_1) # На примере первого класса
Дальше код для самой генерации предложений. Скрипт выдаёт 4 предложения по 15 слов каждое, примерно следующего содержания :)
'советовали как и вся мебель в качестве вступления хочу от отеля не звонила на пользу выбора. округа говорит по часа видимо поэтому администрация обратит внимание что пробовать желания нет чайника ни сосисок. отнесен к сведенью, линию стали ждать пока мы были с сухариками, отфутболивают, вечерний рынок где то. чернышевской, привлекательными чем я уезжала из санатория а тут просто праздник но очень экономит особенно если.'
import random def generate_texts(token_label, grouped_bigramm, label, count_text, count_sent, count_word): # Создаём словарь для подсчёта биграмм "исключений" exceptions_bigramm = defaultdict(int) # Создаём список уникальных токенов для старта предложения unique_token = list(set(token_label)) texts = [] for it_text in range(count_text): # Цикл с диапазоном кол-ва текстов text = '' unique_word = set() # Цикл с диапазоном кол-ва предложений в тексте for it_sent in range(count_sent): len_sent = count_word # Генерим случайное слово для начала предложения для обеспечения стохастического процесса генерации предложения start_word = random.choice(unique_token) # Записываем в строку с финальным предложением первое стартовое слово final_sent = start_word # Множество уникальных слов, которые уже сгенерились в предложение (чтобы геенерация не зацикливалась) unique_word.add(start_word) for step in range(count_word): next_word = None # Создаём переменную для нового слова frequency = 0 # Переменная-счётчик для частоты каждого нового слова # Проходим циклом по словарю с ключом биграммы и значением её частоты for second_word, freq in grouped_bigramm[start_word]: bigramm = start_word + ' ' + second_word # Устанавливаем значение максимального повторения слова в одном тексте if exceptions_bigramm[bigramm] > 3: continue if freq > frequency and second_word not in unique_word and second_word != 'END_SENT_START': next_word = second_word frequency = freq # Если второе слово проходит условие запоминаем его if next_word is None: # Если подходящего по условиям слова не найдено, перезаписываем стартовое слово и начинаем поиск заново start_word = random.choice(unique_token) final_sent += ', ' + start_word unique_word.add(start_word) else: # Если после цикла нашли подходящее слова (которое запомнили в цикле) - записываем его в предложение exceptions_bigramm[start_word + ' ' + next_word] += 1 start_word = next_word final_sent += ' ' + next_word unique_word.add(start_word) final_sent += '. ' text += final_sent texts.append(text) generation_text_df = pd.DataFrame(texts, columns=['feedback']) # Формируем фрейм из списка generation_text_df['label'] = label return generation_text_df[['label', 'feedback']] label_1_df = generate_texts(token_label_1, grouped_bigramm_1, label=1, count_text=15000, count_sent=4, count_word=15)
Как, я упоминал ранее при данной задаче, для генерации семантика не имеет принципиального значения, важней частота появления слова в корпусе и именно на такой результат заточен алгоритм. И теперь, запамятовав вышесказанное, перейдём к следующей части работы.
Баланс данных
Сгенерировав недостающее количество текстов, следует привести к балансу длину самих текстов. Для чего? Что бы ответить на этот вопрос, вспомним как работает механизм взвешивания текста TF-IDF.
Мера TF-IDF является произведением двух сомножителей.

TF - частота слова - отношение числа вхождений некоторого слова к общему числу слов документа. Таким образом, оценивается важность слова в пределах отдельного документа.

IDF - обратная частота документа - инверсия частоты, с которой некоторое слово встречается в документах коллекции. Учёт IDF уменьшает вес широкоупотребительных слов. Для каждого уникального слова в пределах конкретной коллекции документов существует только одно значение IDF.

Большой вес в TF-IDF получат слова с высокой частотой в пределах конкретного документа и с низкой частотой употреблений в других документах. То есть, если мы имеем корпус с текстами с сильно различным количеством слов, мы рискуем получить завышенный показатель IDF если слово встречается только в маленьких текстах и наоборот если слово часто встречается много раз только в одном крупном тексте.
Ещё раз по-другому
Первый случай. Слово t встречается пять раз в тексте длинной 500 слов: знаменатель формулы IDF получит 1 бал и завысит показатель самого IDF, а следовательно, общий вес слова.
Второй случай. Слово t встречается по одному разу в пяти текстах длинной 100 слов: знаменатель формулы IDF получит 5 балов и занизит показатель самого IDF, а следовательно, общий вес слова.
Подводя черту, выходит, что, зная длину текстов тестовых данных, мы можем качественно повлиять на результат взвешивания слов, корректируя длину текстов для тренировочных данных. Если мы знаем, что в тестовой выборке сообщения длиной не более 100 слов, нам выгодней использовать веса, определённые во втором случае. Проверим гипотезу на практике
Приведём токены к их леммам
from nltk.tokenize import RegexpTokenizer from nltk import tokenize import nltk import pymorphy2 morph = pymorphy2.MorphAnalyzer() def lemmatize(text): pattern = '[а-яёА-ЯЁ]+' tok = tokenize.RegexpTokenizer(pattern) text = tok.tokenize(text) def normalize(word): return morph.parse(word.lower())[0].normal_form return " ".join([normalize(it) for it in text if len(it) > 2]) df_feedback_train['feedback'] = df_feedback_train['feedback'].apply(lambda value: lemmatize(value))
Пропустим наш корпус через функцию разбиения/склеивания текстов и получим новый корпус с длинами документов, в заданном тестовым набором, диапазонах – от одного до ста токенов.
В функцию передаются аргументы: 1. сам корпус; 2. нижний порог слов в тексте; 3. верхний порог слов; 4. нижний порог слов в текстах «под отсечение».
list_feedback_label_1 = get_text_for_label(df_feedback_train, 1) # Снова получим список документов из фрейма (пример для первого класса) def balance_text(corp, low_thresh, high_thresh, low_remove_tresh): new_corp, temp = [], [] for text in corp: if low_thresh <= len(text) <= high_thresh: # Если длина текста в пределах диапазона - оставляем текст без изменения new_corp.append(text) elif len(text) < low_thresh: # Если длина текста меньше нижнего порога - запоминаем, затем склеиваем с таким же текстом if len(temp) >= low_thresh: new_corp.append(temp) temp = text else: temp.extend(text) else: # Если длина текста больше верхнего порога - сплитим на меньшие тексты в рамках диапазона # Совсем мелкие хвостовые части не добавляем for j in range(0, len(text) - low_remove_tresh, high_thresh): new_corp.append(text[j:min(len(text), j + high_thresh)]) if len(temp) > low_remove_tresh: new_corp.append(temp) return new_corp label_1_feedback_balance = balance_text(list_feedback_label_1, 50, 100, 10) # Получаем сбалансированный текст для первого класса # Всё тоже проделываем для всех 5-ти классов.
В результате получим следующее распределение количества токенов в документах.
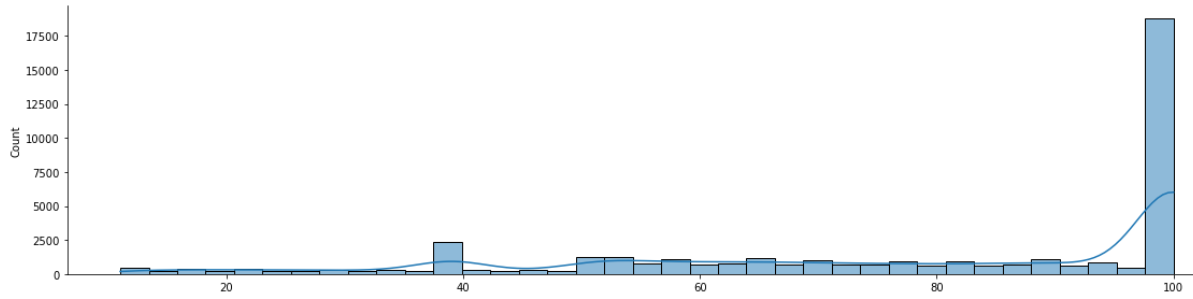
Здесь следует сделать отступление. Если взглянуть на аналогичный график распределения слов для первого класса тестовой выборе (график ниже), мы увидим картину идеального нормального распределения. Следовательно, и распределение для тренировочной выборки я стремился сделать схожим – нормальным, но именно нормальное распределение в тренировочной выборке дало худший показатель точности, а самый оптимальный представлен на графике выше.

Итак, мы получили корпуса со сбалансированным количеством слов, теперь отсечём лишнее – думаю 40к доков для каждого класса будет достаточно для демонстрации, затем обучим классификатор и сравним результат с результатами на разных этапах предобработки тренировочных данных. В связке с TF-IDF неплохо работает логистическая регрессия.
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.linear_model import LogisticRegression from sklearn.metrics import classification_report, confusion_matrix, accuracy_score %matplotlib inline import matplotlib.pyplot as plt import seaborn as sns # Отсекаем лишнее количество документов для выравнивания кол-ва текстов в представленных классов между собой label_1_feedback_balance = label_1_feedback_balance[:40000] # Так для каждого класса # Склеиваем один фрейм для тренировочных данных def list_to_df(texts, label): # Функция для получения фрейма для каждого класса feedback = [' '.join(it) for it in texts] labels = [label for i in range(len(texts))] return pd.DataFrame(list(zip(labels, feedback)), columns =['label', 'feedback']) df_label_1 = list_to_df(label_1_feedback_balance, 1) # Так для каждого класса (получаем фрейм) df_feedback_train_balance = pd.concat([df_label_1, df_label_2, df_label_3, df_label_4, df_label_5], axis=0) # Склеиваем df_feedback_train_balance = df_feedback_train_balance.sample(frac=1).reset_index(drop=True) # Не забыть перемешать тексты X_train_text = df_feedback_train_balance['feedback'].values X_test_text = df_feedback_test['feedback'].values y_train = df_feedback_train_balance['label'].values y_test = df_feedback_test['label'].values v = TfidfVectorizer(norm=None, max_df=0.8, max_features=500, decode_error='replace') # Взвешиваем вектора X_train_vector = v.fit_transform(X_train_text) X_test_vector = v.transform(X_test_text) clf = LogisticRegression( random_state=64, solver='lbfgs', max_iter=10000, n_jobs=-1) # Обучаем классификатор clf.fit(X_train_vector, y_train) y_pred = clf.predict(X_test_vector) # Вывод результатов print(accuracy_score(y_test, y_pred)) print(classification_report(y_test,y_pred)) T5_lables = ['5','4','3','2','1'] ax= plt.subplot() cmm = confusion_matrix(y_test,y_pred) sns.heatmap(cmm, annot=True, fmt='g', ax=ax); ax.set_xlabel('Predicted labels');ax.set_ylabel('True labels'); ax.set_title('Confusion Matrix'); ax.xaxis.set_ticklabels(T5_lables); ax.yaxis.set_ticklabels(T5_lables);
Модель с загруженными начальными данными (не прошедшими предобработку) показала точность 0.51211. Классы сильно разбалансированы, это хорошо просматривается в показателях precision и recall.

Модель с добавлением сгенерированных данных в слабо представленных классах дала результат точности предсказания в 0,56897.
Модель же с добавлением сгенерированных данных и балансировкой текстов по длине показала точность 0,64984. Уточнённые показатели так же выглядят приятней, да и прирост в точности в 8% при многоклассовой классификации довольно ощутимый результат.

Спасибо за внимание!
Буду рад Вашим замечанием, с удовольствием отвечу на вопросы в комментариях.

