
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Не работал в Тиньке, но работал много где еще. Такие именования видел, что аж поначалу страшно становилось от этих аббревиатур на 20+ символов.
Но, разумеется, что мешает именовать нормально и без дурацких сокращений, чтоб было понятно по названию колонки, а не часа ковыряний доки?
Хотя кстати иногда лучше даже длинное название дать, но читаемое. Во всяком случае, лучше чем:
* длинное и нечитаемое
* короткое нечитаемое
:D
что мешает именовать нормально и без дурацких сокращений
Тяжёлое оракловая травма в начале карьеры. До 10 версии оракул точно не разрешал имена длиннее 30 символов. А если ещё и по каким-нибудь правилам у таблиц должны быть определённые префиксы, то вообще караул.
...а там где я работаю, нет доки совсем.
И комментариев в таблицах и полях тоже нет.
И связей между таблицами.
И сокращения в названиях — ууу... Ладно 20 символов, тут хоть иногда можно догадаться о чем речь. А вот 2-3-4 символа это да.
Это вы с обфускацией наименований полей, таблиц, процедур и т.п. не сталкивались. Когда столкнулся (в финтехе тоже) был в шоке долгое время. Совсем как в фильме "Операция Ы". Помните причину почему Ы?
Мы недавно столкнулись с названием полей одной крупной интернет-компании (не будем тыкать пальцем), вот там вообще треш)) Просто tbl_clt_fr_crm_ld_ydx_t_cpn - что-то в таком духе)
А то, что микс русской и английской транскрипции вас не смущает?
first_nm + middle_nm + last_nm = fio ?
Почему б не full_nm. И раз уж без гласных, то fll_nm.
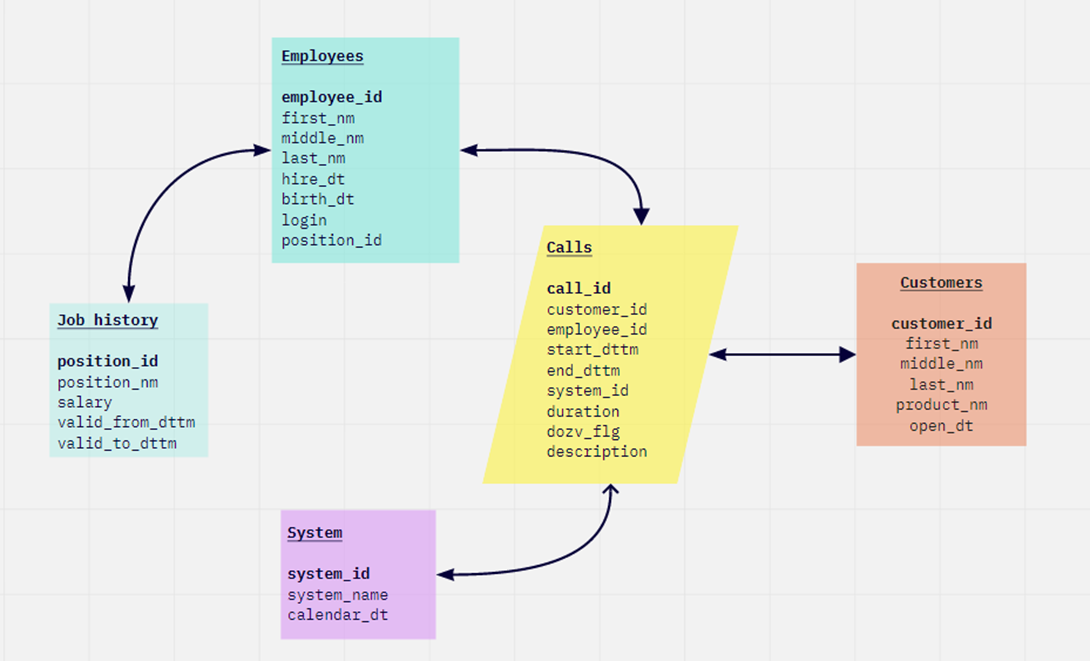
Структура таблиц в базе данных
Что за разноцветная ерунда? Там что, не верят в UML что ли?
Если уж страховаться от левых значений в dozv_flg, то стоит застраховаться от отсутствия там значений вообще, и избежать деления на ноль
Даже интересно стало, сколько они такому джуну предлагают бабла...
А потому что оператор
betweenпотеряет все записи за сегодня, если не преобразовать эти поля в дату (это особенность сравнения даты-времени в PostgreSQL). Опять же - мы просто перестраховались.
Спасибо, мы вам перезвоним. Вы потеряли индекс по дате, условие стало non-sargable.
вдруг там еще какие-то значения могут быть
Даже комментировать не буду.
Я правильно понимаю, что к дате надо было приводить сами граничные значения?
Поговорка времен позднего СССР - "лучше один раз снять дворники с чужой машины, чем каждый день снимать со своей" <==> лучше преобразовать границы условий сравнения в предикате один раз, чем преобразовавать сами данные при сравнении - типичнейшая ошибка вплоть до сеньорного уровня, которая, как сказал автор выше, делает индекс по сравниваемой колонке неприменимым
Мы ждали подобных комментариев) В них рождается истина))
А про "комментировать не буду" - если можно, все-таки прокомментируйте)
Ничего там зародиться не может, это просто детская безграмотность. Вы взялись за тему, в которой не понимаете абсолютно ничего, даже как работает индексный поиск.
Комментировать различие между БД и помойкой ("вдруг там еще какие-то значения могут быть") тем более не планировал.
Вы очень счастливый человек, если работаете только в тех компаниях, где БД не помойка, а круто спроектированная штука. Жаль, что в 99% случаев это не так.
Хотя, тогда странно, что вы такой не дружелюбный, раз на работе все так чудесно. Мы вроде до оскорблений не скатывались :)
Вы очень счастливый человек, если работаете только в тех компаниях, где БД не помойка, а круто спроектированная штука. Жаль, что в 99% случаев это не так.Где неизвестнодаже содержимое полей — 99%? Вы и тут чепуху пишете и упираетесь.
Мы вроде до оскорблений не скатывалисьТут нет вообще никаких оскорблений. А есть толстый намек, что писать в сообщество разработчиков, не имея даже начальных представлений о предмете — очень, очень нелепо и просто неразумно.
Это не наша база. Дана картинка с табличками - решите тестовое. Причем тут вообще мы :)
Если ваши представления настолько глубоки, что вы сходу можете сказать незнакомым людям, что "у них нет даже начальных представлений о предмете" - так может быть вы поделитесь свои опытом и напишете какую-нибудь статейку на тему? :) А то у вас статей 0, а такие "дилетанты" как мы вынуждены заполнять инфополе своим контентом)
А то у вас статей 0, а такие «дилетанты» как мы вынуждены заполнять инфополе своим контентом)Да, это действительно очень плохо. Но да, я статей лучше, чем, например, Брент Озар, Пол Рэндал или, если местами сразу по-русски, то Дмитрия Пилюгина — не напишу. И нет, это совсем не означает, что инфополе нужно гхм… «заполнять» абсолютно безграмотными статейками, лишь бы накрутить свою упоминаемость.
А потому что оператор
betweenпотеряет все записи за сегодня, если не преобразовать эти поля в дату (это особенность сравнения даты-времени в PostgreSQL). Опять же - мы просто перестраховались.
Если уж перестраховываться, то лучше привести Now к концу суток (или вместо Now тупо задать 9999 год, как удобнее. Но тут возникает вопрос, не может ли оказаться во входящих данных будущее время).
А если развить мысль, то, при условии нормальных данных, зачем там вообще верхняя граница?
Отдельный вопрос, насколько правильно считать данные за неполный месяц. Вдруг там внутри месяца есть своя динамика, и основная активность приходится на конец месяца? Тогда ваш MAU будет занижен...
Одна дата у кастомера тоже вызывает вопросы - если ставится дата первого обращения, то мау не посчитать, если дата последнего - имеет смысл только мау за последний некалендарный месяц (если кастомер может обращаться в компанию несколько раз)
Во второй задачке я бы вместо case использовал filter, который как-то логически кажется более уместным. Но могу ошибаться.
select
concat_ws('—', first_nm, middle_nm, last_nm) as fio,
birth_dt
from employeesИнтересно, а как в постгресс ведет себя эта функция, если один из операндов - Null или пустая строка? (Я просто не знаю). Для MSSQLSERVER - все будет гораздо вычурнее:
select
Stuff(concat('—' + Nullif(first_nm, ''), '-' + Nullif(middle_nm, ''), '-' + Nullif(last_nm,'')), 1, 1, '') as fio,
birth_dt
from employeesУ человека может не быть отчества, фамилии или даже имени. В любом сочетании.
select
start_dttm::date as "date",
count(case when dozv_flg=1 then 1 end) /
count(case when dozv_flg in (1, 0) then 1 end) as sla
from calls
where start_dttm::date between '2020-10-01' and now()::date
group by start_dttm::dateНе знаю, как в постгрессе (опять же, не специалист), в MSSQLSERVER так делать категорически нельзя. Я про where start_dttm::date
Это не саргабельно. В случае, если по start_dttm есть индекс, ОН НЕ БУДЕТ ЗАДЕЙСТВОВАН, ну, или будет задействован в режиме полного сканирования. Так что но, найн, нихт, отрывать руки по самый афедрон! Еще один момент: Функция count возвращает результат в int. Поделив int на int (а деление будет ЦЕЛОЧИСЛЕННЫМ, т.к. оба операнда - целые) - вы наверняка получите не то, что нужно.
Выглядеть должно так (в MSSQLSERVER):
select
Convert(date, start_dttm) as "date",
(count(case when dozv_flg=1 then 1 end) * 1.0) /
count(case when dozv_flg in (1, 0) then 1 end) as sla
from calls
where start_dttm >= '20201001' and start_dttm <= Convert(date, Dateadd(day, 1, Current_timestamp))
group by Convert(date, start_dttm)Как то так, остальные разборы разберу потом :-)
Про саргабельность - кажется, это тема заслуживает отдельной статьи. Уверены, что на эту позицию вполне допустимо такого не знать - по уровню заданий это понятно.
Но отличная мысль для следующего материала)
Вот так, конечно же start_dttm < Convert(date, Dateadd(day, 1, Current_timestamp)). Не вычитал, прошу прощения.
concat_ws завезли в MS SQL 2017 (https://docs.microsoft.com/en-us/sql/t-sql/functions/concat-ws-transact-sql).
Всё хорошо с null.
concat_ws('-', 'A', 'B', null, 'D') вернёт 'A-B-D'
а по фронтенду тоже разбираете?
А можно психотип человека кто идет после всего в теперь гос компанию? )
В следующем кейсе - явная ошибка, причем не технического плана, а именно ошибка реализации:
with a as (
select
to_char(calendar_dt, 'MM') as mon,
count(distinct id) as cnt
from clients
group by mon
)
select avg(cnt) as mau
from aДело в том, что в таблице clients могут быть данные ЗА РАЗНЫЕ ГОДЫ.
И тогда ваш запрос вернет хрень (простите мой французский).
Запрос должен выглядеть как:
with a as (
select
month(calendar_dt) as mon,
count(distinct id) as cnt
from clients
group by year(calendar_dt), month(calendar_dt)
)
select avg(cnt) as mau
from aНу, и не забываем, что среднее от int - будет int. А то вдруг вы там десятые ждете? Тогда avg(cnt * 1.0), ну, или явное преобразование к какому либо плавающему или фиксированному типу.
не забываем, что среднее от int - будет int.
Зависит от СУБД. Скажем, в PostgreSQL это не так. https://dbfiddle.uk/?rdbms=postgres_14&fiddle=8b050e6e76058df1b23f3b8e498f0fd4
можно спросить? а почему вы в вашем примере не вывели год? ведь я в вашем случае буду видеть больше строк с тем же месяцем, без понятия к какому году он относится...
Условие
Дана таблица clinets:
- id клиента
- calendar_at - дата входа в мобильное приложение...
Либо у меня приступ временной слепоты, либо я чего-то не понимаю. В схеме данных НЕТ таблицы clients. По полям похожая - только system...
---
Ну и резануло то, что в тексте задания расхождения по сравнению с кодом (clinets вместо clients, calendar_at вместо calendar_dt).
Или это дополнительный уровень проверки?
Задача 1 ...
Есть ещё проблема, которую Вы просмотрели. Видите ли, бывают люди, не имеющие отчества. В таблице в этом поле может оказаться NULL. И если использовать CONCAT() или оператор конкатенации, то некоторые СУБД вернут итогом NULL (что очевидно неверно), а некоторые отнесутся к нему как к пустой строке, и в конце итогового значения получится ни к чему не пристёгнутый дефис. В отличие от CONCAT_WS(). А если в поле может в описанном случае оказаться пустая строка - то потребуется ещё и NULLIF(). Ну или CASE - для универсальности.
Кстати, PostgreSQL в этом случае вообще оригинал - функция конкатенации CONCAT() и оператор конкатенации || ведут себя по-разному. Для многих это оказывается сюрпризом - иногда неприятным.
Задача 2
Мы просто перестраховались — вдруг там еще какие-то значения могут быть. Например, 2.
По-моему, условие чётко устанавливает, что для любого поступившего звонка значение поля может быть или 0, или 1 (или звонок принят, или нет). Никаких 2, никаких NULL и иных значений там быть не может, если считать условие задания верным. А поскольку непоступившие звонки в таблице присутствовать не могут, то насчёт перестраховки - это Вы совершенно безосновательно придумали.
И, если принять, что условие не содержит ошибок, CASE вообще становится не нужен, а процент считается простейшим SUM(dozv_flg)/COUNT(dozv_flg). Либо SUM(dozv_flg)/COUNT(*). Что выбрать - опять зависит от конкретной СУБД, в некоторых эти выражения могут дать разную итоговую производительность запроса.
where start_dttm::date between '2020-10-01' and now()::date
А это "прощай производительность". Правильно - не приводить поле к дате, чтобы можно было использовать красивый BETWEEN, а where start_dttm >= '2020-10-01' and start_dttm < CURRENT_DATE + INTERVAL '1 day'.
" — " в условии первого задания окружено пробелами (Имя - Фамилия - Отчество), в результате же будет без них: Имя-Фамилия-Отчество.
Ну и да, от нулов не перестраховались.
По поводу названий
иногда возникает ситуация что в витрине не совсем понятно что именно содержится ....
иногда .... ну конечно же ..... иногда ....
а в некоторых случаях плюнул и назвал колонки по Русски - что бы аналитики не приставали с вопросами - А где мне взять то-то ? А что здесь ?
:) вот такой лайф хак :)
{kind=link}
Разбор тестового задания в Тиньков [SQL]