Коллеги-сетевики, привет. К написанию данной статьи меня сподвигли задачи, с которыми приходилось сталкиваться во время работы с OSPF/IS-IS и тот набор решений, к которому я в конечном итоге пришел. Речь идет о насущном вопросе сетевых инженеров, когда приходится применять настройки на живой сети (пусть и с программируемым откатом на крайний случай) без возможности посмотреть как это отразится на всей сети в целом. Если отдельные команды и сценарии еще можно проверить в лабе, то получить полную реплику сети практически невозможно. В связи с этим я задался вопросом о наличии инструмента, который позволял бы строить слепок сети и рассчитывать её реакцию на ранее примененные настройки. Об этом сегодняшний туториал.
Теория. Задачи. Практика
Весь слепок сети (правильнее сказать слепок area) уже содержится компактно на каждом L3-устройстве в Link-State DataBase (LSDB) OSPF/IS-IS протокола. Достаточно лишь подключиться к одному устройству, сохранить её в текстовый файл и все связности в рамках одной области (area) у вас уже есть. Если областей несколько, то собрать LSDB с каждой из них. Далее достаточно правильно распарсить и построить математический граф с L3 устройствами в качестве нод (vertex) и OSPF/IS-IS соседством в качестве линков (edge) между ними. Имея такой граф, мы можем у себя на ПК делать с ним все, что захотим: удалять линки и изменять метрики на них, удалять сами ноды, строить маршруты и все это не затрагивая реальную сеть. К слову сказать на реальной сети можно и так посмотреть как будет проходить путь через tracert/traceroute/mtr, но не все устройства, в частности файерволы, покажут себя в этом выводе (пример №1). А также нет никакой возможности посмотреть какой будет резервный (backup) маршрут, если тот или иной участок из этого пути упадет. Именно это покажет нам граф-модель, в которой достаточно удалить edge и построить маршрут между теми же самыми устройствами заново. Тогда наикратчайший маршрут в измененной модели будет являться резервным маршрутом для нашего первоначального слепка сети (пример №2).
Представим, что сеть представляет собой совокупность разных по дизайну топологий: hub-and-spoke для подключения удаленных офисов и full или partial mesh между hub-ами. Каждый удаленный офис имеет основной (Primary) и запасной (Secondary,Backup) маршрутизатор и вы планируете перезагрузить secondary устройство. Повлияет ли это как-то на активный трафик? Если это резервный девайс, то через него не должно ничего проходить, но как это проверить? Оказывается достаточно просто — необходимо из каждой удаленной локации построить наикратчайший маршрут до нашей локации, где мы планируем провести работы, и тем самым убедиться используется ли secondary устройство для активного трафика или нет (пример №3). Дальше-больше, что, если мы действительно обнаружили такой трафик с таким flow, как нам это поменять? Тогда нам не обойтись без изменения метрик (cost) на сети.
Много достоинств у Link-State протоколов и мы уже оценили одно из них, когда одно устройство содержит в себе всю информацию по конкретной области, но есть и особенности, с которыми приходится считаться. В частности метрика назначается и принадлежит интерфейсу, а не префиксу, как это обстоит у BGP. Поэтому если мы изменили метрику на одном интерфейсе, то могли повлиять на traffic flow во всей area. Но рано или поздно менять метрики приходится и если на интерфейсе на данный момент выставлена метрика 10, то как это повлияет на распределение трафика, если выставить не 10, а 9 или 11? Вы уже наверное догадались, что и в этот раз мы можем себе позволить сделать это на графе и посмотреть реакцию сети на наши изменения (пример №4).
Сеть как живой организм — все в нем внутри тесно связан, взаимодействует между собой и состояние на «вчера» может отличаться от состояния текущего. Поэтому было бы неплохо также иметь возможность сравнивать состояние сети в разные отрезки времени. Имея копии LSDB, переведенные в граф, мы теперь уже можем сравнивать их и понимать: какие новые появились подсети, какие, наоборот, пропали, а также выявлять новые и старые L3-устройства (пример №5).
Прежде чем переходить к разбору примеров, хотелось бы остановиться на архитектуре найденного решения, на основе которого построена демонстрационная часть.
Архитектура. Безопасность
Решение представляет собой веб сервис, состоящий из Open-Source проектов:
Nginx,
MongoDB,
Topolograph.
Благодаря контейнеризации, все составные части описаны в одном конфигурационном файле и запускаются одной docker compose up -d командой на Linux или Windows хосте. Такой подход имеет еще одно преимущество — безопасность, поскольку все загруженные данные о сети сохраняются в локальной MongoDB базе. Также данный сервис может быть помещен в DMZ зону, где разрешены только входящие HTTP запросы до Nginx, но запрещены все исходящие запросы за пределы зоны.

На рисунке изображена архитектура решения, которая запускается в среде Docker. При этом сервис может и не иметь доступа к сети, поскольку для построения графа необходим лишь текстовый файл с описанием OSPF/IS-IS LSDB.
Визуализация OSPF/IS-IS сети
Сбор LSDB с устройств различных вендоров
Для получения математической модели (графа) сети, необходимо сперва получить Link-State DataBase (LSDB) с реального устройства. Разные производители по-разному смотрят на формат вывода LSDB, но стоит отметить, что подавляющее большинство из них поддерживают RFC 2328.
Vendor | LSA1 | LSA2 | LSA5 |
Cisco | show ip ospf database router | show ip ospf database network | show ip ospf database external |
Quagga | show ip ospf database router | show ip ospf database network | show ip ospf database external |
Juniper | show ospf database router extensive | no-more | show ospf database network extensive | no-more | show ospf database external extensive | no-more |
Bird | show ospf state all | show ospf state all | show ospf state all |
Nokia | show router ospf database type router detail | show router ospf database type network detail | show router ospf database type external detail |
Mikrotik | /routing ospf lsa print detail file=lsa.txt | /routing ospf lsa print detail file=lsa.txt | /routing ospf lsa print detail file=lsa.txt |
Huawei | display ospf lsdb router | display ospf lsdb network | display ospf lsdb ase |
Paloalto | show routing protocol ospf dumplsdb | show routing protocol ospf dumplsdb | show routing protocol ospf dumplsdb |
Ubiquiti | show ip ospf database router | show ip ospf database network | show ip ospf database external |
Allied Telesis | show ip ospf database router | show ip ospf database network | show ip ospf database external |
Таблица с перечнем команд для сбора OSPF Link State DB. LSA1 и LSA2 являются обязательными для построения графа, в то время как LSA5 — опционален.
Vendor | Command |
Cisco | show isis database detail |
Juniper | show isis database extensive |
Nokia | show router isis database detail |
Huawei | display isis lsdb verbose |
Таблица с перечнем команд для сбора IS-IS Link State DB.
Построенный граф на основе OSPF/IS-IS вывода LSDB
Чтение LSDB, её парсинг и построение графа считается успешным, если после загрузки файла с Link-State базой, отобразится топология сети. Граф динамический и интерактивный, то есть его можно перетянуть в нужное место на поле или выбрать ноду, до/с которой построить маршрут, нажав на нужную ноду правой кнопкой.

Жирной линией на графе отображены множественные (2 и более) связности между двумя нодами.
Построение кратчайшего пути. Пример №1
В самом начале статьи описывалась задача с построением актуальных путей между двумя устройствами. Результат расчета пути представлен на рисунке ниже. Дополнительно описывается маршрут с указанием каждого L3-устройства на сети (в трассировке используется OSPF RID (router ID)), а также метрика маршрута.

На картинке выше изображены 4 наикратчайших маршрута (ECMP, Equal cost multipath) от L3 устройства с RID 123.14.14.14 до 123.123.30.30 с метрикой 41.
Представим также, что Вы знаете только IP адрес отправителя и IP адрес получателя. Для построения маршрута нужно знать на каком из L3-устройств затерминирована подсеть отправителя и получателя, и чтобы не тратить время на поиск, можно сразу начать вводить IP адреса в поле Focus/From и To. Терминирующие их устройства подставятся автоматически.
Нахождение резервного маршрута. Пример №2
Мы теперь знаем как выглядит наикратчайший маршрут, давайте посмотрим какой будет резервный путь, если устройство 123.10.10.10 потеряет связность с 123.30.30.30. Для этого достаточно лишь нажать на синий линк пути.

При потери связности между двумя устройствами, резервный путь будет состоять из четырех ECMP путей, иметь стоимость 50 и будет проходить через устройства 123.31.31.31 — 123.11.11.11.
Построение карты доступности устройства. Пример №3
Представим, что нода 123.30.30.30 основная, а 123.31.31.31 — резервная. Наша задача заключается в том, чтобы проверить доступность группы устройств слева от устройства 123.30.30.30 из любой точки нашей сети. Этого можно достичь при включенной опции «Print Minimum Shortest Tree (MST) for the node» и выбора меню «Build the shortest path to this node».

На рисунке выше изображены все наикратчайшие пути до ноды 123.123.30.30. Нода 123.30.30.30 действительно является основной для входящего трафика.
Построение карты сетевой доступности до всех устройств сети
Продолжая пример с активным и резервным роутером выше, теперь давайте убедимся, что это справедливо и для исходящего трафика. Для этого построим наикратчайшие пути от устройства 123.123.30.30 до всех нод в сети при выборе «Build the shortest path from this node».

По полученной диаграмме выше можно заметить, что резервный маршрутизатор 123.31.31.31 также используется для исходящего трафика. Получается, что мы нашли асимметричный трафик на нашей сети.
Для того, чтобы находить участки с несимметричными путями, можно воспользоваться отчетом, который сделает вышеупомянутые проверки для каждого устройства в графе и на выходе предоставить список несимметричных путей (при их наличии).

Все отчеты о сети помещены под графой Analytics. На момент написания статьи их представлено пять. Чуть подробнее об отчетах будет написано ниже.
Отчет о несимметричных путях на сети. Пример реальной сети
Когда отчет завершит проверку на наличие несимметричных путей, то появится список (слева) нод, относительно которых замечены такие маршруты. Если выбрать одну из нод в списке, то на графе будет отображена дельта во всех исходящих и во всех входящих маршрутах.

На рисунке изображен найденный отчетом несимметричный маршрут относительно ноды 10.5.0.115. Можно заметить как разительно отличается входящий и исходящий маршрут для этой ноды. Для реального трафика это может быть разное время прохождения пакета, что выражается в увеличенном джиттере.
Реакция сети на изменения в ней
В примере №2 текущей статьи мы увидели какой будет резервный маршрут при падении связности между 123.10.10.10 и 123.30.30.30. Для получения этих данных нам пришлось построить наикратчайший маршрут между удаленными устройствами графа и с имитировать падение линка. Для случаев, когда нам хотелось бы увидеть картину в целом как перестроится OSPF/IS-IS граф, если мы на время выключим тот или иной линк, сделан режим NetworkReactionOnFailure. В этом режиме мы можем увидеть через какие устройства будут перенаправлены наикратчайшие пути после изменений на сети, а через какие устройства маршруты больше строиться не будут. Стоит отметить, что backend topolograph оперирует именно числом наикратчайших маршрутов через ноду и не привязывает это как-то к объему трафика, так как не располагает такой информацией. Однако мы можем предположить, что чем больше будет проложено маршрутов через ноду, то и трафика через неё будет в конечном итоге больше. Рассмотрим это на примере.
Реакция сети на потерю линка
Если граф уже успешно загружен и выбран режим NetworkReactionOnFailure, то при нажатии на любой линк графа будет эмулироваться ситуация с его выключением. При этом серые стрелки показывают то, что на указанном направлении будет снижение числа построенных через этот линк путей, а синяя линия, наоборот, их увеличение.

На рисунке выше с эмулировано падение связности между нодой 123.30.30.30 и 123.10.10.10, при этом объем «трафика» в направлении от 123.11.11.11 до 123.31.31.31 увеличится на 200%, а в обратном направлении от 123.31.31.31 до 123.11.11.11 только лишь на 100%. В чем может быть причина?
Это связано с тем, что на линке 123.30.30.30 — 123.10.10.10 указаны разные метрики.

Из-за того, что стоимость до ноды 123.10.10.10 — 1, в то время, как в обратном направлении - 10, нижний линк через ноды 123.31.31.31 и 123.11.11.11 неравномеренно использовался. По этой причине на нем будет в два раза больше увеличение «трафика» при падении верхнего линка (отмеченного красным). Еще одной подсказкой где трафика станет больше или меньше может служить масштаб (ширина) стрелки, чем она шире, тем бОльше изменений.
Реакция сети на изменение метрики (cost). Пример №4
Помимо того, что можно имитировать падение связности, можно также посмотреть на реакцию сети на изменение стоимости на интерфейсе.
Имеем все тот же граф с асимметрично назначенными метриками и давайте посмотрим куда перенаправится трафик, если мы вместо стоимости 1, выставим стоимость 12 на интерфейсе.

На диаграмме выше прогнозировано указано, что трафик предпочтет следовать через нижние устройства 123.31.31.31 и 123.11.11.11, поскольку верхний путь теперь имеет уже худшую метрику, чем на нижнем пути. Таким образом, изменив заранее метрику на верхнем линке, мы можем эвакуировать трафик с этого направления и перевести его на альтернативное.
Реакция сети на падение устройства
При проведении работ на сети нередки случаи, когда нужно вывести трафик с устройства, перезагрузить его, при этом трафик должен перенаправится в нужном для нас направлении. В этом нам может помочь все тот же режим NetworkReactionOnFailure.

С эмулируем падение ноды 123.123.101.101 через соответствующий пункт контекстного меню правой кнопки мыши.

Результат реакции сети показывает, что нагрузку на себя возьмет нода 123.123.100.100, но обратите внимание, что объем трафика не одинаков. К примеру, трафика с правой верхней ноды 123.123.110.110 в левую часть схемы через 123.123.100.100 будет больше, чем в обратном направлении с 123.10.10.10 через все тот же 123.123.100.100. Объясняется это все тем же несимметрично назначенной метрикой в левой части схемы на линке 123.10.10.10 — 123.30.30.30.
Карта зарезервированности Stub сетей
При анализе Link-State DB учитываюся и сети (stub), которые анонсированы в OSPF/IS-IS домен. Какую полезную информацию можно получить из полученных данных? Если мы видим, что устройство 123.14.14.14 анонсирует сеть 10.0.0.0/24 и в тоже время другое устройство — 123.15.15.15 также включает её в свои анонсы, то мы можем сделать вывод, что оба эти устройства находятся в HSRP паре и данная сеть защищена на случай выхода из строя одного из устройств. Если проверить таким же образом каждую сеть, то можно построить карту с использованием градиента красного цвета там, где больше всего сетей без резервирования, и с зеленым цветом, где зарезервированных сетей больше.

На рисунке показаны все сети устройства 123.10.10.10, а также то, что сеть 10.99.0.0/21 и 99.99.99.0/24 настроена только на нем, т.е. без резервирования. Стоит отметить, что здесь могут быть исключения. К примеру, стековый свич представлен в OSPF/IS-IS домене как одно устройство с одним RID, но по факту он может обеспечить резервирование при выходе из строя одного из его юнитов, если имеет минимум два кабельных подключения в разные юниты.
Отчеты о сети
Для быстрого анализа настроек OSPF/IS-IS удобнее использовать отчеты, которые представляют собой набор стандартных проверок:
наличие соединений с асимметрично настроенной метрикой
наличие асимметричных путей
проверка, что резервный путь не проходит через устройства другого региона
резервирование сетей (stub)
Выводы с некоторых отчетов уже приводились в статье выше, приведем пример отчета по линками с асимметричной метрикой.

Все линки с асимметричной метрикой помечаются красным.
API
Для того, чтобы загрузить граф, не обязательно это делать через сохранение вывода OSPF/IS-IS LSDB в файл. Возможно воспользоваться любимым NetDevOps инструментом наподобие Ansible, netmiko, nornir и проч., сохранить через них вывод и сформировать POST запрос в Topolograph. Ответ будет содержать следующие данные:
Разницу с ранее загруженными слепками сети: новые и старые L3 устройства, новые и старые связности (edge)
ссылка на запрос списка всех сетей
статус некоторых отчетов
Пример загрузки слепка OSPF домена сети представлен ниже.

Из вывода POST запроса видно, что по сравнению с ранее загруженным слепком OSPF домена, пропали 4 связности между устройствами. Старых, как и новых L3 устройств в сети не появилось. Однако появилась 1 новая сеть и 1 сеть теперь уже не анонсируется устройством 123.10.10.10. Из прочей статистики указано общее число нод — 13 и общее число сетей - 39. Таким образом можно мониторить основные характеристики OSPF/IS-IS домена сети. Для собственной проверки можно делать слепок каждый раз до и после работ на сети. Если после работ изменений не выявлено, то можно уверенно утверждать, что работы проведены успешно (если конечно работы не предполагали каких-либо изменений настроек на сети).
Мониторинг изменений в OSPF домене из единой точки на сети в режиме Online
Имея возможность получать diff сети, можно задаться целью собирать слепки настолько часто, чтобы мы могли детектировать аварийные случаи. Но тогда нужно определиться насколько часто подключаться и сохранять их, чтобы с одной стороны не нагрузить устройство, а с другой — отловить начало и конец аварии (на тот случай, если падение связности между устройствами было кратковременным). Но гораздо эффективней и рациональней предоставить возможность сервису читать актуальные служебные сообщения OSPF (LSA) в режиме реального времени и таким образом логировать изменения на сети. Такая задача покрывается в другом, но схожем, open-source проектe Ospfwatcher, целью которого является мониторинг изменений в OSPF топологии и экспорт данных в ELK (Elasticsearch, Logstash и Kibana).
На данный момент имеет следующую архитектуру:
Linux хост с docker, с которого устанавливается GRE туннель до любого активного L3 устройства в сети
Quagga для установления OSPF соседства через GRE туннель и дебаг OSPF LSA сообщений в docker volume
Watcher модуль, который читает OSPF debug сообщения и переводить их в структурированный вид
Logstash, который делает экспорт логов в стек Elastic-Logstash-Kibana
Компоненты ospfwatcher также описаны в едином конфигурационном файле для запуска их через docker compose.

Как результат работы сервиса, мы имеем историческую справку обо всех изменениях на сети.
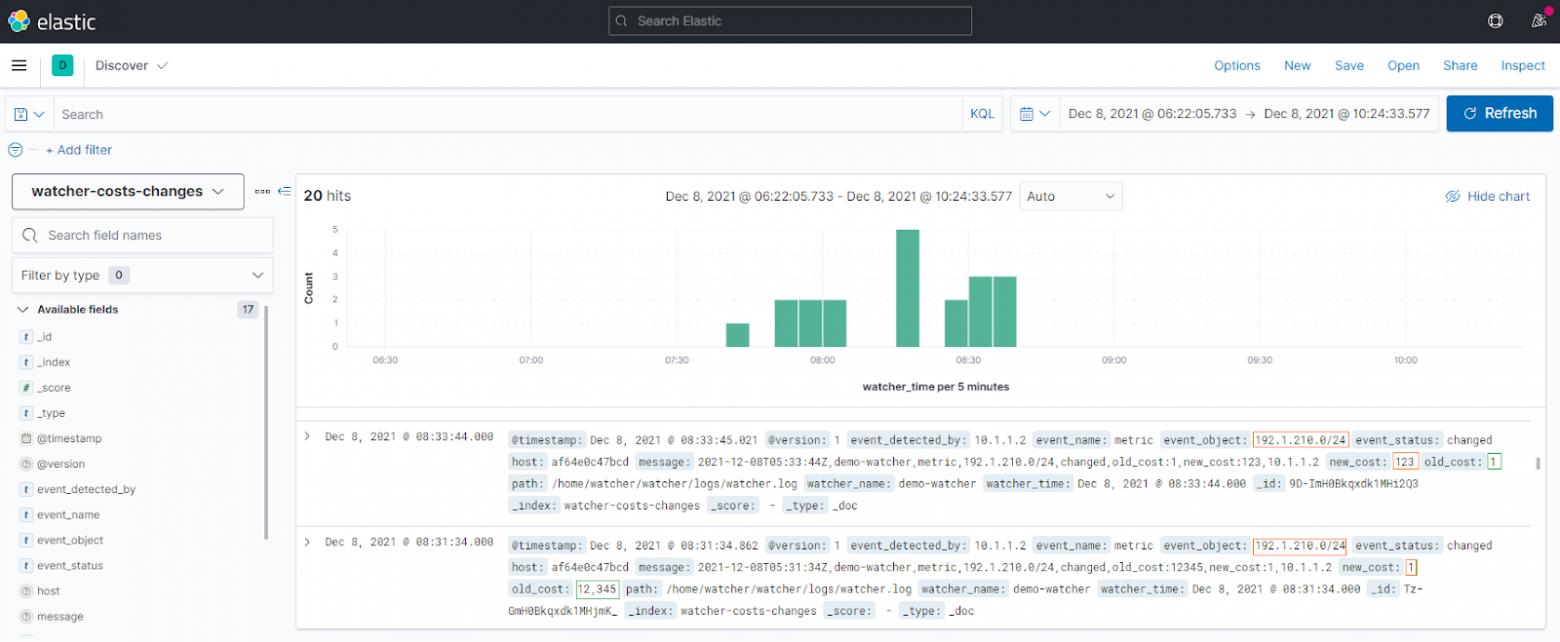
На рисунке выше представлена выборка логов по изменению OSPF метрики на сети в Elastic-e, а именно:
какое устройство обнаружило изменение,
какая была старая метрика и какая — новая.
Как это использовать
Приходя утром в офис Подключившись по удаленке через VPN, можно просмотреть, что было c OSPF за ночь. Или когда поступают жалобы в виде "сеть начала тормозить, когда как 5 минут назад все работало хорошо" можно проверить перестраивался ли OSPF, если нет, то следовать по привычным шагам далее - смотреть мониторинг, дашборды, уточнять детали. Если же граф перестраивался, то это даст подсказку где и что произошло.
Заключение
Этой статьей я хотел суммировать подходы к исследованию настроек OSPF/IS-IS сети с помощью доступных инструментов, с целью привнесения некоторой аналитики в legacy сети, которые по умолчанию этот сервис не предоставляют. Попробуйте применить озвученные подходы анализа к вашей сети, сделайте отчеты, будут ли у вас несимметричные пути?) Возможно, у кого серые IP адреса на Router ID и кто может показать свою топологий - также welcome, вместе посмотрим какой дизайн сети применяется чаще всего.


{kind=link}