В данной серии статей я подробно рассказываю о том, как написать на Java собственный интерпретатор объектно-ориентированного диалекта SQL с использованием Spark RDD API, заточенный на задачи подготовки и трансформации наборов данных.
Краткое содержание предыдущей серии, посвящённой API расширения и разного рода технической обвязке:
Расширяемость. API подключаемых функций
Режимы запуска. Пакетный режим, сборка для разных окружений, автотесты
Теперь можно поговорить о последних штрихах, делающих инструмент — инструментом, а именно, об интерактивно-отладочном режиме, то есть, REPL, клиенте и сервере, а также о генераторе документации.
Уровень сложности данной серии статей — высокий. Базовые понятия по ходу текста вообще не объясняются, да и продвинутые далеко не все. Поэтому, если вы не разработчик, уже знакомый с терминологией из области бигдаты и жаргоном из дата инжиниринга, данные статьи будут сложно читаться, и ещё хуже пониматься. Я предупредил.
11. Автоматический документатор
Как мы помним из раздела с описанием интерфейсов подключаемых функций, они изначально содержат большое количество полезной человеко-ориентированной информации, а не только технически необходимые интерпретатору метаданные.
Вот из этого-то материала генератор документации и скомпонует нам нормальное человеко-понятное описание каждой функции — в виде куска связного текста. Более того, мы ещё хотим сделать так, чтобы если в класпасе тестов есть ресурс скрипта, имя которого соответствует имени соответствующей функции, генератор в доку даже и его вставил как пример вызова. С подсветкой синтаксиса.
С первой частью никаких закавык возникнуть не может — для генерации текста (такого, как HTML) можно использовать любой знакомый текстовый шаблонизатор. Мне знаком Apache Velocity, так что я использую его — вам-то, вероятно, такая древность покажется страшной архаикой, но мне достаточно того, что он работает, и я помню, как именно. Так что мы просто итерируемся по всем пакетам, а затем и подключаемым функциям из кеша контекста исполнения, и предаём в шаблонизатор классы их метаданных, чтобы получить текстовую часть доки. Подробно разбирать не буду.
Со второй частью на самом деле тоже никаких закавык нет, потому что у нас с самого начала есть антлеровский лексер. Так что мы просто берём подходящий по имени скрипт из ресурсов тестового скопа, и разбираем его на токены, которым присваиваем какой-то класс расцветки.
Примерно так:
public enum Highlight { OPERATOR, KEYWORD, NULL, BOOLEAN, OBJLVL, SIGIL, IDENTIFIER, NUMERIC, STRING, COMMENT; static public Highlight get(int tokenType) { switch (tokenType) { case S_AMPERSAND: // ... case S_XOR: { return OPERATOR; } case S_SCOL: case K_ANALYZE: // ... case K_WHERE: { return KEYWORD; } case S_NULL: { return NULL; } case S_FALSE: case S_TRUE: { return BOOLEAN; } case T_POINT: // ... case T_VALUE: { return OBJLVL; } case L_IDENTIFIER: { return IDENTIFIER; } case S_DOLLAR: case S_AT: case L_UNARY: { return SIGIL; } case L_NUMERIC: { return NUMERIC; } case L_STRING: { return STRING; } case L_COMMENT: { return COMMENT; } } return null; } } public SyntaxHighlighter(String script) { CharStream cs = CharStreams.fromString(script); TDL4Lexicon lexer = new TDL4Lexicon(cs); input = new CommonTokenStream(lexer); } public String highlight() { StringBuilder text = new StringBuilder(); input.fill(); String cls = null; Highlight highlight; for (Token token : input.getTokens()) { highlight = Highlight.get(token.getType()); if (highlight == null) { text.append(token.getText()); } else { switch (highlight) { case OPERATOR: { cls = "tdl-operator"; break; } // ... case COMMENT: { cls = "tdl-comment"; break; } } text.append("<code class=").append(cls).append(">").append(token.getText()).append("</code>"); } } return text.toString(); }
В шаблоне (по которому у нас генерируется HTML) каждый класс токенов будет иметь соответствующее оформление (заданное через класс CSS). А чтобы получить «печатный» вариант доки, мы прогоним полученный HTML через библиотеку pdfbox в PDF.
Вызов документатора добавим в фазу package билда, чтобы он всегда вызывался:
<plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>exec-maven-plugin</artifactId> <version>3.1.0</version> <executions> <execution> <phase>package</phase> <goals> <goal>java</goal> </goals> <configuration> <addResourcesToClasspath>true</addResourcesToClasspath> <classpathScope>test</classpathScope> <mainClass>io.github.pastorgl.datacooker.doc.DocGen</mainClass> <arguments> <argument>${docs.output}</argument> <argument>${distro.name}</argument> </arguments> </configuration> </execution> </executions> </plugin>
В параметрах указываем путь, по которому будет положена сгенерированная дока и (забегая вперёд) наименование нашего дистрибутива.
Таким образом, у нас при сборке всегда сгенерируется свежая документация ко всему подключаемому, что только лежит в нашем класпасе. Очень удобно, когда после коммита имплементации какой-нибудь новой функции в репу аналитики получают копию актуальной доки по этой функции сразу же после сборки — и даже неважно, где собирать, на CI или локально у себя. Эт я понимаю, действительно самодокументируемый код.
Ну, хорошо. Пакетно запускаемся хоть в облаке, хоть локально, тесты гарантированно рабочие, и дока всегда у нас под рукой. Остаётся только отладить какой-нибудь новый процесс, причём, хотелось бы интерактивности.
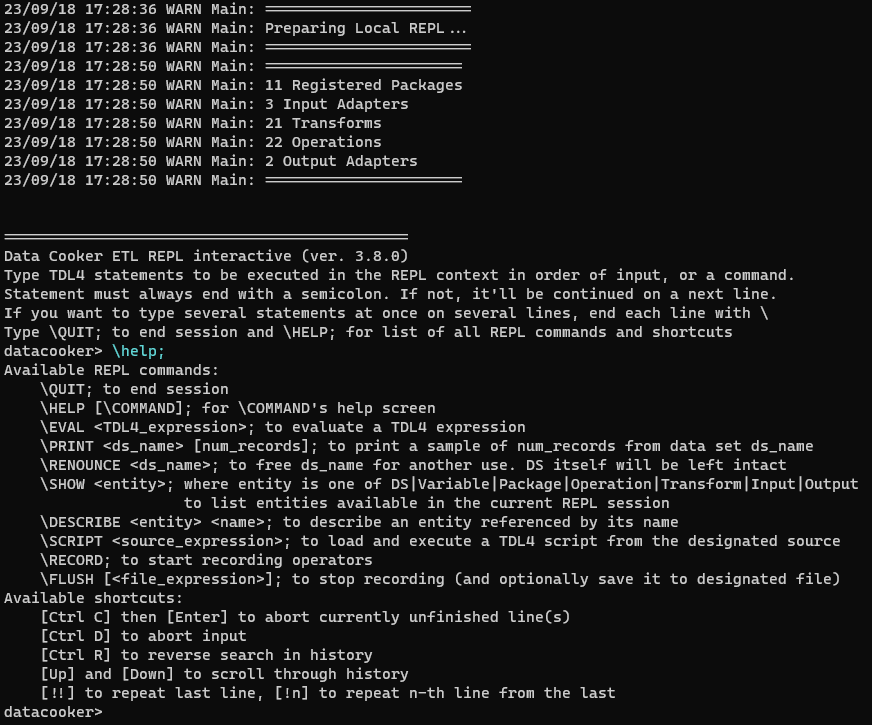
12. Режимы запуска. REPL. Локальный интерактивный режим
Как мы видим, раскрасить синтаксис скрипта — это дело на раз плюнуть. Да и сам интерпретатор написать, в принципе, не настолько сложная задача, сколько муторная. И вообще, куда больше времени уходит на проектирование языка и подготовку инфраструктуры кучи разных контекстов. Как тогда насчёт консольного отладчика?
О. Как показала практика, это полный и окончательный кабздец.
Интерактивный шелл в командной строке — боль великая и морока неимоверная. Особенно, если проект пишется на Java.
Впрочем, поначалу я об этом даже и не догадывался. Требование №6 — сделать интерактивный отладочный шелл — долгое время оставалось задачей низкоприоритетной, поэтому и времени на неё было выделено не настолько много, сколько на полировку остальной функциональности. Но когда дело дошло до имплементации, стало понятно, насколько трудозатраты были недооценены.
Во-первых, что такое вообще этот ваш «Read Evaluate Print Loop», оно же «интерактивный шелл»?
Некая командная строка, которая позволяет вводить оператор за оператором, вычислять их в контексте сессии, и показывать результат вычисления в той же самой командной строке. Но что тогда такое «командная строка»?
Использовать жабовские стандартные readln() для чтения ввода / writeln() для отображения в терминал — фигня на постном масле. Пользователи привыкли к развитым командным строкам, в которых есть раскраска синтаксиса, автоподстановка и автозавершение по TAB, история с поиском по Ctrl+R, макросы типа !!, и тэдэ и тэпэ. Так что не-умный ввод-вывод ни разу не прокатит. А пытаться написать это всё богатство поведенческих нюансов с нуля — проще сразу убиться веником, потому что объём работ не просто велик, он невероятен.
То есть, на самом деле надо найти какую-то либу, которая позволяла бы иметь уже готовую командную оболочку со всем хозяйством, и расширить её, кастомизировав для нашего кейса.
И вот тут оказывается, что в экосистеме Java таких, в достаточной степени продвинутых, либ, существует ровно одна — jline. И всё, нет больше никаких альтернатив, которые не были бы сколько-нибудь функциональны, и не заброшены лет этак десять назад.
Но jline — это монстр, комбайн, комок спагетти-кода, и гоблинский джаггернаут на паровом ходу.
Целью разработчиков jline явно было повторить / сэмулировать промпт sh, vim, и одновременно emacs на всех возможных разновидностях терминалов. Поэтому в составе либы сотни всяких мелких виджетов, свистелок и перделок, подвязанных на великое множество событий, причём с поддержкой непередаваемого количества управляющих флажков — с целью эмуляции несовместимых и разнонаправленных командных систем. При этом огромная куча нюансов поведения, реализованных в разных шеллах неодинаково, наоборот, тупо захардкожена в недрах приватных методов, и не поддаётся управлению вообще.
Например, Ctrl+C перехватить стандартным способом, — через обработчики сигналов, — невозможно, и остаётся только грубо влазить в чужой код. Причём, в отличие от всех остальных сигналов, которые отлично перехватываются. Почему? Да фиг его знает, почему, но нас бы устроило прерывать текущий оператор по Ctrl+C, а не аварийно завершать весь шелл.
Или prompt continuation (то есть, ввод многострочных команд) ведёт себя настолько недружелюбно к разработчику, что гораздо проще и быстрее реализовать его из собственного кода, не полагаясь на эту стандартную фичу либы совсем. Вероятно, потому что её авторы вообще не предполагали, что кто-то попробует использовать secondary prompts для ввода полных операторов в операторных скобках (как у нас между BEGIN и END).
Или при вставке через буфер обмена куска текста, который превышает текущий размер вьюпорта терминала, он будет свёрнут в многоточие (в котором к тому же четыре точки, карл, не три), и это никак не отключается. Но если терминал тупой (флаг DUMB), то вставить можно сколько хочешь текста, и он не будет свёрнут. А добраться до этого флага, чтобы временно его проставить, можно только рефлексией, и никак иначе. Почему же так, карл? А нигде не объясняется.
Документация по jline вообще ужасно бестолковая, состоящая большей частью из высокоуровневых примеров, и зачастую разобраться в причине поведения какого-нибудь виджета можно только путём глубокого курения под отладчиком исходников, написанных в далеко не самом приятном стиле.
Короче, самая жесть оказалась там, где я ну никак не ожидал её встретить.
Но делать нечего. Инструмент без инструментария бесполезен. Нам нужно отлаживать ETL процессы интерактивно, поэтому хоть тушкой, хоть чучелом, но REPL сделать необходимо.
И для начала неплохо бы понять, как именно мы будем отлаживаться. То есть, какие команды интерактивного шелла нам нужны. В отличие от операторов, выполняемых интерпретатором, команды будут напрямую обращаться к соответствующему контексту движка напрямую, и позволят делать вещи, невозможные в пакетном режиме.
Запроектируем следующий набор команд (для команд используем сигил \ на первой позиции ввода, чтобы перехватывать их на этапе разбора и пускать обработку по отдельной ветке):
\QUIT—ESC : q !,\HELP— странно, если такой команды не будет,\EVAL— посчитать «выражение россыпью» и показать результат,\PRINT— отсэмплировать (материализовать) и показать сколько-то случайных записей из набора данных,\RENOUNCE— освободить имя набора данных, если выбрали что-то не то, а имя заняли хорошее (если у нас есть сигилы, значит, можно отрекаться),\SHOW— показать имена сущностей контекста исполнения (наборы данных, подключаемые функции, переменные, и всё что у нас есть остальное, — то есть, с подкомандой на каждый вид сущностей),\DESCRIBE— описать сущность из контекста (то же, что и в\SHOW),\SCRIPT— подгрузить скрипт из файла и выполнить его,\RECORD— начать запись операторов в буфер,\FLUSH— выгрузить записанный буфер операторов в файл скрипта.
Всем этим командам назначим однобуквенные алиасы, и добавим автодополнение по TAB. С учётом всего фарша, который привносит jline (типа, истории команд и макросов), получается минимально достаточный набор для пошаговой отладки скриптов, и интерактивного написания новых.
Так что унаследуемся от LineReaderImpl, склонируем в нём несколько методов, в которых нам надо будет изменить поведение, и с грацией гиппопотама, танцующего на клумбе с тюльпанами, грубо исправим их. После чего можно написать сам main loop в классе REPL — длинный-предлинный switch по командам, в котором внутри каждой команды ещё куча if, и прочей скучной цикломатики.
Для подсветки синтаксиса и отображения подсвеченной строки нам потребуется унаследоваться от jline-овских ParsedLine, Parser и Highlighter. А для автодополнения — от Completer, и вот уж там-то с цикломатикой всё будет совсем настолько плохо, что идеевский анализатор на нём слегка подвисает. Впрочем, иначе подобные штуки не имплементируются. Очень многословно и опять чертовски скучно.
Короче, ровно та же история, что и с интерпретатором TDL, так что описывать эту возню подробно в данной статье смысла нет. Если интересно — перейдите по ссылкам из предыдущего абзаца и попробуйте разобраться самостоятельно.
Что есть смысл описать, так это механизм для обращения к контексту исполнения для подкоманд \SHOW и \DESCRIBE, которых у нас будет немало: DS, VARIABLE, PACKAGE, TRANSFORM, OPERATION, INPUT, OUTPUT, и OPTION. Он же, кстати, у нас и в автодополнении участвует.
То есть, потребуется несколько «провайдеров», организующих доступ в контексты через чёрный ход:
public abstract class DataProvider { public abstract Set<String> getAll(); public abstract boolean has(String dsName); public abstract StreamInfo get(String dsName); public abstract Stream<String> sample(String dsName, int limit); public abstract void renounce(String dsName); } public abstract class VariableProvider { public abstract Set<String> getAll(); public abstract VariableInfo getVar(String name); } public abstract class EntityProvider { public abstract Set<String> getAllPackages(); public abstract Set<String> getAllTransforms(); public abstract Set<String> getAllOperations(); public abstract Set<String> getAllInputs(); public abstract Set<String> getAllOutputs(); public abstract boolean hasPackage(String name); public abstract boolean hasTransform(String name); public abstract boolean hasOperation(String name); public abstract boolean hasInput(String name); public abstract boolean hasOutput(String name); public abstract String getPackage(String name); public abstract TransformMeta getTransform(String name); public abstract OperationMeta getOperation(String name); public abstract InputAdapterMeta getInput(String name); public abstract OutputAdapterMeta getOutput(String name); } public abstract class OptionsProvider { public abstract Set<String> getAll(); public abstract OptionsInfo get(String name); }
В DataProvider мы также вынесем методы для других команд, обращающихся к наборам данных (\PRINT и \RENOUNCE). И мы объявили их всех абстрактными классами, потому как REPL у нас может быть не только локальный, но и удалённый. Не проблема дёргать за методы того, что крутится в той же JVM, но без man-in-the-middle было бы сложновато организовать доступ к контекстам на другом хосте из того же самого кода.
А ещё нам потребуется отдельный «провайдер» для обращения к интерпретатору, чтобы исполнять операторы языка и делать \EVAL выражений:
public abstract class ExecutorProvider { public abstract Object interpretExpr(String expr); public abstract String read(String pathExpr); public abstract void write(String pathExpr, String recording); public abstract void interpret(String script); public abstract TDL4ErrorListener parse(String script); }
Также этот провайдер задействует механизмы движка для чтения и записи скриптов для команд \SCRIPT и \FLUSH.
Имплементировать провайдеры будем анонимными классами прямо в обёртке Local.
Наконец, что ещё нам потребуется для организации локального интерактивного режима, так это заставить контекст Spark чуточку приумолкнуть, а то по умолчанию он сыплет в консольный лог на уровне INFO овердофига отладочной информации. Так что мы поставим ему log level = WARN. Для этого у нас, кстати, в контексте исполнения предусмотрен параметр @log_level, который при желании можно задавать через OPTIONS, и наслаждаться ходом выполнения этапов Spark.
Таким образом, базовый класс REPL будет у нас исполнять в цикле операторы и команды до тех пор, пока не встретит команду \QUIT, а доступ к контексту исполнения ему обеспечат провайдеры в исполнителях режимов Local и Client.
Кстати, о клиенте. Раз он есть, должен быть и сервер.
13. Режимы запуска. «REST», «клиент», и «сервер»
Почему в заголовке всё в кавычках? Ну, потому что у нас не настоящий REST, а типичный для современного ынторпрайза REST-ish protocol, а, во-вторых, протоколом этим не предусмотрено ни авторизации, ни никакой вообще секурности. Впрочем, я как уже говорил, весь наш интерактив — это одна большая отладочная фича, и нужна она не для продакшена. Тем более, что контекст у нас один, и многопользовательская работа дизайном не предусмотрена.
Что же в таком случае будет представлять собой «сервер»?
В современной жабе поднять себе маленький HTТP с поддержкой JAX-RS не так уж и сложно. Отдельный enterprise контейнер не нужен, потому что тот же glassfish давно уже разобран на маленькие кусочки, типа jersey, которыми можно пользоваться внутри обычного приложения.
Единственное, чтобы всё сделать с минимумом усилий, надо задействовать какой-нибудь простенький механизм инжекции зависимостей, типа guice, потому что гласфишевский внутренний HK2 — та ещё гадость. Плюс ко всему, он внутренний, а значит до него и добираться неудобно. К счастью, есть библиотечка guice-jersey, как раз и предоставляющая нам guice внутри jersey, а это означает, что нам надо сконфигурировать парой строк инжекты, написать насколько эндпоинтов, обвесить их аннотациями, и дело в шляпе.
Что касается клиента, то есть Client, то данная обёртка над REPL потребует лишь наличия какого-то простенького запросчика к эндпоинтам. Тут можно взять готовый JerseyClient, и имплементации провайдеров делать через него. Например:
vp = new VariableProvider() { @Override public Set<String> getAll() { return new HashSet<String>(rq.get("variable/enum", List.class)); } @Override public VariableInfo getVar(String name) { return rq.get("variable", VariableInfo.class, Collections.singletonMap("name", name)); } };
Кода будет немного. И в обработчике режима Server кода тоже получается очень мало, буквально считанные строки. Да и в самих эндпоинтах — тоже не больше, мы как в истинном энтерпрайзе вовсю пользуемся готовыми аспектами, подключаемыми через аннотации.
Каждый эндпоинт будет отвечать на вызовы какого-то одного провайдера. Например:
@Singleton @Path("variable") public class VariableEndpoint { final VariablesContext vc; @Inject public VariableEndpoint(VariablesContext vc) { this.vc = vc; } @GET @Path("enum") @Produces(MediaType.APPLICATION_JSON) public List<String> variables() { return new ArrayList<>(vc.getAll()); } @GET @Produces(MediaType.APPLICATION_JSON) public VariableInfo variable(@QueryParam("name") @NotEmpty String name) { return new VariableInfo(vc.getVar(name)); } }
Часть неизменных ответов (таких, как список операций, например, или описание какой-то из OPTIONS) будем кешировать на клиенте, чтобы второй раз за ними не ходить, потому как они без перезапуска сервера с другим класпасом не поменяются, а если такое происходит, то и клиент надо перезапускать, потому что мы релиз более новой версии задеплоили.
Ага, gotcha. Значит, нам требуется ещё один дополнительный эндпоинт для возврата версии сервера, чтобы при несовпадении с клиентом можно было выплюнуть на консоль сообщение о необходимости использовать правильную версию клиента.
Выцеплять версию будем прямиком из манифеста нашего FatJAR:
public static String getVersion() { try { URL url = Main.class.getClassLoader().getResource("META-INF/MANIFEST.MF"); Manifest man = new Manifest(url.openStream()); return man.getMainAttributes().getValue("Implementation-Version"); } catch (Exception ignore) { return "unknown"; } }
Чтобы добавить в него эту строку, используем возможности плагинов maven, такие как генерация расширенного манифеста в jar plugin:
<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-jar-plugin</artifactId> <version>3.3.0</version> <configuration> <archive> <index>true</index> <manifest> <addClasspath>true</addClasspath> <addDefaultImplementationEntries>true</addDefaultImplementationEntries> </manifest> </archive> <finalName>datacooker-etl-cli</finalName> </configuration> <executions> <execution> <goals> <goal>test-jar</goal> </goals> </execution> </executions> </plugin>
И задание самой версии через пропертю, для чего необходим flatten plugin:
<properties> <revision>3.8.0</revision> </properties> <plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>flatten-maven-plugin</artifactId> <version>1.5.0</version> <configuration> <updatePomFile>true</updatePomFile> <flattenMode>resolveCiFriendliesOnly</flattenMode> </configuration> <executions> <execution> <id>flatten</id> <phase>process-resources</phase> <goals> <goal>flatten</goal> </goals> </execution> <execution> <id>flatten.clean</id> <phase>clean</phase> <goals> <goal>clean</goal> </goals> </execution> </executions> </plugin>
Данный рецепт позволяет нам прямо по красоте указывать версию релиза в одном-единственном месте всего дерева исходников.
Что ж. Получается, что всё у нас сделано как у больших, настоящих SQL-движков. Язык, система типов, контекст исполнения, автодокументатор, разные режимы запуска, и даже удалённая интерактивная отладка через клиентский консольный шелл есть. С подсветочкой синтаксиса и автодополнением.
Прекрасно, можем продолжать ETL-ить терабайты даты эври божий дэй, но теперь с большим на 287.53% удобством.
14. Заключение
На самом деле, я чуточку лукавлю, когда говорю о том, что на нашем проекте внедрён Data Cooker ETL. На самом-то деле, у нас на проекте используется проприетарный расширенный форк, в который добавлено большое количество патентованной аналитической алгоритмики, специфичной для проекта, в виде набора операций.
Соответственно, используется этот приватный форк отнюдь не только для автоматизации ETL процессов, но и непосредственно аналитиками — как основной движок для обработки нашей географической и популяционной бигдаты. Именно они его напрямую и юзают (а то почему я всю дорогу говорил про аналитиков), а я сам вот даже и не data engineer proper, а скорее лид разработки инструментальных средств, и влажу в продакшен только тогда, когда надо что-то настроить, либо имплементировать очередную операцию, исходя из ТЗ.
Так что Data Cooker ETL изначально разрабатывался как white label инструмент — от диспетчера Main можно унаследоваться, и указать собственное имя, если необходимо брендировать инструмент под конкретного заказчика. Код открыт, лицензия почти BSD, и единственное, что она запрещает, так это использовать его силовикам (любой страны) для военных действий.
А всем остальным — можно, причём каким угодно образом. Форк целиком, сабмит новых фич через репу в GitHub, либо заимствование кода отдельных компонентов, — пожалуйста, как пожелаете. Я, как лид разработки, буду только рад, если расскажете, что вам понравилось, но это не обязательно.
Также мы, как контора, не предполагаем продавать сам инструмент, но не откажемся технически поддерживать ETL процессы, построенные с его использованием, за небольшую денежку по подписке.
Поэтому, если данная серия статей вызвала у вас интерес к инструменту, или желание продуктивно пообщаться на тему разработки подобных решений, предлагаю использовать группу в телеграм Data Cooker ETL — и её же для установки коммерческих контактов.
Надеюсь, было интересно. Не переключайтесь, будет ещё одна, — итоговая, — статья с суммарным FAQ.

