Мы каждый день работаем с текстом, решая разные задачи. Проверяем текст на правильность ввода некоторых данных, ищем, заменяем некоторые значения, выделем некоторые данные из текста. Порой объём этих данных значительно возрастает и справиться с такими объёмами текстовой информации за актуальный промежуток времени не получается.
Нам на помощь прийдут регулярные выражение. Этот мощный инструмент многие специалисты уже давно используют очень успешно. Я говорю не только о разработчиках программного обеспечения, но и о людях других профессий, которым приходится работать с текстом (редакторы, маркетологи, копирайтеры).
Сегодня я хотел бы познакомить вас с книгой Яна Гойвертса и Стивена Левитана «Регулярные выражения. Сборник рецептов», которая поможет вам понять как работать с регулярными выражениями.
Давайте разберёмся что же за такой полезный инструмент эти регулярные выражения.
Немного трудно понять из описания что это такое, но постараюсь объяснить простым языком. У нас есть текст, который нужно обработать и есть требование как нам нужно его обработать. По требованию мы строим некоторый шаблон. Передаём наш шаблон и текст программе, которая сделает разбор. Так намного проще?
В книге показаны решения, основанные на использовании регулярных выражений, применённые к широкому кругу практических задач, связанных с обработкой текста, возникающих в различных приложениях.
Книга как бы разделена на две больших логические части. Первая часть посвещена теории регулярных выражений, синтаксису и описанию разных диалектов.
Глава 1. Введение в регулярные выражения;
Глава 2. Основные навыки владения регулярными выражениями;
Глава 3. Программирование с применением регулярных выражений.
Вторая часть посвещена решению разных задач, которые могут возникнуть.
Глава 4. Проверка и форматирование;
Глава 5. Слова, строки и специальные символы;
Глава 6. Числа;
Глава 7. URL, пути и адреса в Интернете;
Глава 8. Разметка и обмен данными.
Книга читается очень легко и понятна будет даже тем людям, которые никогда не имели навыков программирования. Все примеры построены по принципу — ставится задача, решается и после этого разбирается более подробно.
Ян Гойвертс является основателем компании Just Great Software, где занимается проектированием и разработкой некоторых популярнейших программных продуктов для работы с регулярными выражениями. Он является автором приложения RegexBuddy, единственного в мире редактора регулярных выражений, имитирующего особенности 15 диалектов, и PowerGREP, самого мощного инструмента grep для Microsoft Windows.
Стивен Левитан является ведущим экспертом по регулярным выражениям в JavaScript. Он ведет популярный блог, посвященный регулярным выражениям, по адресу http://blog.stevenlevithan.com. Расширение знаний о диалектах регулярных выражений и библиотеках поддержки было для него одним из увлечений на протяжении нескольких последних лет.
Я хотел бы остановиться на одном примере в книге. В нём рассмотрена проверка правильности ввода ISBN. Его я выбрал по некоторым причинам — он прост, он достаточно нагляден и по случайности в пример, который приведён в книге, написаный на Python закралась ошибка. Я решил переписать этот пример.
Для начала давайте убедимся, что страшный шаблон

Редактор нашёл одно совпадение. Шаблон правильный и мы можем приступить к написанию программы на Python (я использовал версию 2.6.1).
Проверим работу нашей программы, которая проверят правильность ISBN.
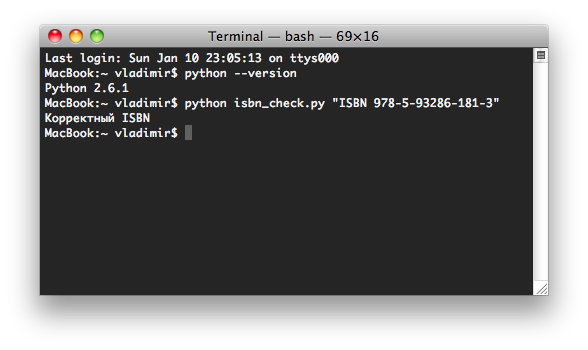
Программа работает корректно, а подробное обсуждение того, как это работает и некоторую справку можно прочитать в книге (§4.13). Хочу лишь добавить, что каждый рецепт, который дан в книге, подробно разбирается. Разбирается алгоритм и сам шаблон. Как пример возьмём рассмотрение этого шаблона в книге:
 Регулярные выражения — это очень мощный инструмент, который может упростить решения многих задач. Данная книга поможет в полной мере овладеть регулярными выражениями.
Регулярные выражения — это очень мощный инструмент, который может упростить решения многих задач. Данная книга поможет в полной мере овладеть регулярными выражениями.
«Регулярные выражения. Сборник рецептов»
Ян Гойвертс и Стивен Левитан
Издательство «Символ-Плюс», 2010, 608 страниц
ISBN 978-5-93286-181-3
Спасибо за предоставленную книгу издательству «Cимвол-Плюс». В интернет-магазине издательства книгу можно приобрести.
Нам на помощь прийдут регулярные выражение. Этот мощный инструмент многие специалисты уже давно используют очень успешно. Я говорю не только о разработчиках программного обеспечения, но и о людях других профессий, которым приходится работать с текстом (редакторы, маркетологи, копирайтеры).
Сегодня я хотел бы познакомить вас с книгой Яна Гойвертса и Стивена Левитана «Регулярные выражения. Сборник рецептов», которая поможет вам понять как работать с регулярными выражениями.
Давайте разберёмся что же за такой полезный инструмент эти регулярные выражения.
Регуля́рные выраже́ния (англ. regular expressions, сокр. RegExp, RegEx, жарг. регэ́кспы или ре́гексы) — система синтаксического разбора текстовых фрагментов по формализованному шаблону, основанная на системе записи образцов для поиска. Образец (англ. pattern), задающий правило поиска, по-русски также иногда называют «шаблоном», «маской».
Википедия
Немного трудно понять из описания что это такое, но постараюсь объяснить простым языком. У нас есть текст, который нужно обработать и есть требование как нам нужно его обработать. По требованию мы строим некоторый шаблон. Передаём наш шаблон и текст программе, которая сделает разбор. Так намного проще?
О книге
В книге показаны решения, основанные на использовании регулярных выражений, применённые к широкому кругу практических задач, связанных с обработкой текста, возникающих в различных приложениях.
Книга как бы разделена на две больших логические части. Первая часть посвещена теории регулярных выражений, синтаксису и описанию разных диалектов.
Глава 1. Введение в регулярные выражения;
Глава 2. Основные навыки владения регулярными выражениями;
Глава 3. Программирование с применением регулярных выражений.
Вторая часть посвещена решению разных задач, которые могут возникнуть.
Глава 4. Проверка и форматирование;
Глава 5. Слова, строки и специальные символы;
Глава 6. Числа;
Глава 7. URL, пути и адреса в Интернете;
Глава 8. Разметка и обмен данными.
Книга читается очень легко и понятна будет даже тем людям, которые никогда не имели навыков программирования. Все примеры построены по принципу — ставится задача, решается и после этого разбирается более подробно.
Об авторах
Ян Гойвертс является основателем компании Just Great Software, где занимается проектированием и разработкой некоторых популярнейших программных продуктов для работы с регулярными выражениями. Он является автором приложения RegexBuddy, единственного в мире редактора регулярных выражений, имитирующего особенности 15 диалектов, и PowerGREP, самого мощного инструмента grep для Microsoft Windows.
Стивен Левитан является ведущим экспертом по регулярным выражениям в JavaScript. Он ведет популярный блог, посвященный регулярным выражениям, по адресу http://blog.stevenlevithan.com. Расширение знаний о диалектах регулярных выражений и библиотеках поддержки было для него одним из увлечений на протяжении нескольких последних лет.
Пример
Я хотел бы остановиться на одном примере в книге. В нём рассмотрена проверка правильности ввода ISBN. Его я выбрал по некоторым причинам — он прост, он достаточно нагляден и по случайности в пример, который приведён в книге, написаный на Python закралась ошибка. Я решил переписать этот пример.
Для начала давайте убедимся, что страшный шаблон
^(?:ISBN(?:-1[03])?:? )?(?=[-0-9 ]{17}$|[-0-9X ]{13}$|[0-9X]{10}$)(?:97[89][- ]?)?[0-9]{1,5}[- ]?(?:[0-9]+[- ]?){2}[0-9X]$ действительно работает. Я проведу проверку в текстовом редакторе Espresso.Редактор нашёл одно совпадение. Шаблон правильный и мы можем приступить к написанию программы на Python (я использовал версию 2.6.1).
- # -*- coding: utf-8 -*-
- # file: isbn_check.py
-
- import re
- import sys
-
- # регулярное выражение проверяте соответствие формату ISBN-10 или ISBN-13
- regex = re.compile("^(?:ISBN(?:-1[03])?:? )?(?=[-0-9 ]{17}$|[-0-9X ]{13}$|[0-9X]{10}$)(?:97[89][- ]?)?[0-9]{1,5}[- ]?(?:[0-9]+[- ]?){2}[0-9X]$")
-
- subject = sys.argv[1]
-
- if regex.search(subject):
- # Удаляем символы, не имеющие отношения к ISBN
- cbuf = re.sub("[^0-9X]", "", subject)
-
- # Создаём массив
- chars = list()
-
- # Разбиваем номер на части и добавляем в массив
- for item in cbuf[:]:
- chars.append(item)
-
- # Перемещаем последнюю цифру из массива chars в переменную last
- last = chars.pop()
-
- if len(chars) == 9:
- # Вычисляем конторольную цифру ISBN-10
- val = sum((x + 2) * int(y) for x, y in enumerate(reversed(chars)))
-
- check = 11 - (val % 11)
-
- if check == 10:
- check = "X"
- elif check == 11:
- check = "0"
- else:
- # Вычисляем конторольную цифру ISBN-13
- val = sum((x % 2 * 2 + 1) * int(y) for x, y in enumerate(chars))
-
- check = 10 - (val % 10)
-
- if check == 10:
- check = "0"
-
- if (str(check) == last):
- print u"Корректный ISBN"
- else:
- print u"Некорректная контрольная цифра ISBN"
- else:
- print u"Некорректный ISBN"
Проверим работу нашей программы, которая проверят правильность ISBN.
Программа работает корректно, а подробное обсуждение того, как это работает и некоторую справку можно прочитать в книге (§4.13). Хочу лишь добавить, что каждый рецепт, который дан в книге, подробно разбирается. Разбирается алгоритм и сам шаблон. Как пример возьмём рассмотрение этого шаблона в книге:
^ # Проверка совпадения с началом строки
(?: # Группировка, но нисходящая
ISBN # Соответствует фрагменту ISBN
(?:-1[03])? # Необязательное совпадение с фрагментом "-10" или "-13"
:? # Необязательное совпадение с фрагментом ":"
\ # Соответствует фрагменту пробела (экранирован)
)? # Повторить группу ноль или один раз
(?= # Опережающая проверка возможности следующих совпадений
[-0-9 ]{17}$ # Соответствует 17 дефисам, цифрам или пробелам
| # за которыми следует конец строки. Или
[-0-9X ]{13}$ # Соответствует 13 дефисам, цифрам, "X" или пробелам
| # за которыми следует конец строки. Или
[0-9X]{10}$ # Соответствует 10 цифрам или "X", с последующем концом строки
) # Конец позитивной опережающей проверки
(?: # Группировка, но нисходящая
97[89] # Соответствует фрагменту "978" или "979"
[-\ ]? # Необязательное совпадение с "-" или пробелом (экранирован)
)? # Повторить группу ноль и один раз
[0-9]{1,5} # Соответствует от 1 до 5 цифр
[-\ ]? # Необязательное совпадение с "-" или пробелом (экранирован)
(?: # Группировка, но нисходящая
[0-9]+ # Цифра, которая соответствует 1 или более раз
[-\ ]? # Необязательное совпадение с "-" или пробелом (экранирован)
){2} # Повторить группу точно 2 раза
[0-9X] # Соответствует цифре или "X"
$ # Проверка с концом строки
Заключение
Регулярные выражения — это очень мощный инструмент, который может упростить решения многих задач. Данная книга поможет в полной мере овладеть регулярными выражениями.«Регулярные выражения. Сборник рецептов»
Ян Гойвертс и Стивен Левитан
Издательство «Символ-Плюс», 2010, 608 страниц
ISBN 978-5-93286-181-3
Спасибо за предоставленную книгу издательству «Cимвол-Плюс». В интернет-магазине издательства книгу можно приобрести.

