Здравствуй %хабраюзер%.
Хочу поделиться с тобой идеей/реализацией аналога технологии ajax которая в отличии от первого лишена основных его недостатков. Из вики об ajax мы знаем что:
Придуманная идея Template client cache (далее TCC) обладает те ми же достоинствами, что и ajax, но полностью лишена её недостатков.
В случае с ajax основная «фишка» заключается в загрузке отдельных блоков, что значительно экономит трафик. Но большой проблемой ajax является сильная несовместимость как со старыми браузерами и поисковиками, так и сложная интеграция в существующие проекты. Решая головоломку переписыванием очередного сайта на блоки с ajax я подумал, не уж то при помощи современных технологий нельзя добиться аналогичного результата но с меньшими затратами по внедрению и совместимости? Итак… закончим лить воду… идея до безумия проста: грузить только то, что нам необходимо обновить (ну правда, очень смахивает на идею ajax). Весь вопрос в реализации. За основу были взяты современные стандарты по поддержке некого хранилища для нужд JS (такие как localStorage) и идея кеширования шаблонов на стороне сервера. Скрестив их мы и получили TCC. Т.е., как и в случае шаблонов на сервере обычно вся страница делиться на куски, которые обрабатываются и формируются отдельными файлами (кусками кода), совмещаются и выбрасываются пользователем. Зачастую некоторые куски кешируются и не формируются повторно в течении некоторого времени. Идея заключается в переносе этого кеша некоторых кусков на сторону клиента и создание инфраструктуры для передачи информации от клиента к серверу и обратно для поддержания кеша в ликвидном состоянии. Т.е. получиться, что при загрузке страницы мы будем так же, как и обычно её формировать на стороне сервера, пропуская некоторые блоки, но не беря их из кеша сервера, а просто оставляя пустыми, и в таком виде будем передавать клиенту, где уже он будет объединять их с существующим кешем и отображать итоговую страницу пользователю. Из описания понятно, что:
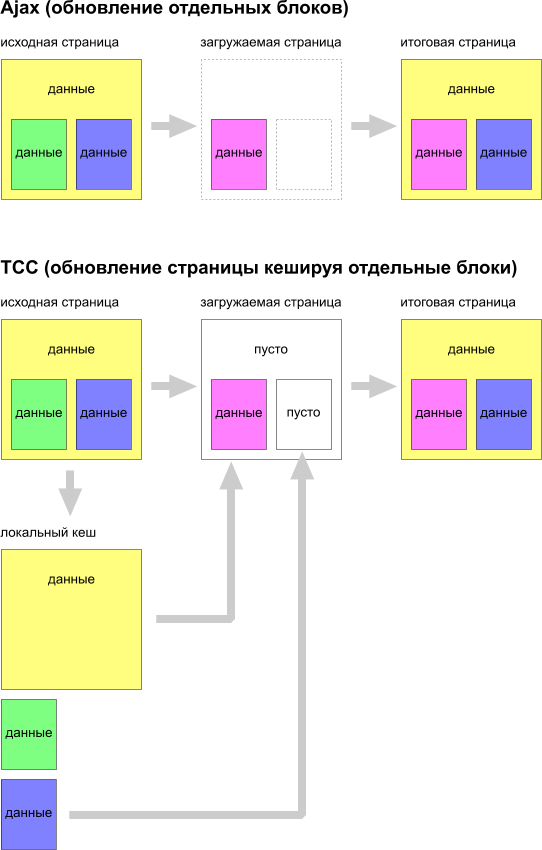
Итого, последовательность работы TCC можно представить так:
Понятно, что собирать я буду демо-пример и за короткий строк, а потому на многие вещи буду закрывать глаза (как то, например, использование jQuery для парсинга html, а так же некоторые облегченности для получения быстрого результата).
Список того, что можно будет улучшить и как я приведу ниже, так что не стоит относиться к демо-примеру критически (с точки зрения применения на продакшене).
Для начала нам нужно определиться с тем, как мы будем маркировать блоки для кеширования. Для простоты я взял стандартный html-элемент span, так как он мало влияет на содержащиеся в нем блоки (т.е. нормально работает и с плавающими вложенными блоками и с инлайновым контекстом). Для маркирования, что это именно маркер, был выбран спец класс именуемый по следующему принципу:
tcc_<ID>_<MODE>[_<TTL>];
Где:
<ID> — Уникальный номер блока;
<MODE> — Режим кеширования (о нем ниже);
<TTL> — Время жизни кеша;
Режим кеширования предназначен для указания клиенту, с каким именно блоком он имеет дело. Было выделено три режима кеширования:
r (realtime) — блок, не подлежащий кешированию (обновляющийся при каждой перезагрузки страницы);
s (server) — блок, сформированный на сервере и подлежащий кешированию (создаётся в случае, если необходимо сформировать или заменить блок в кеше);
c (client) — блок, сформированный на сервере пустым, в который клиент должен поместить закешированные данные;
Перейдем к реализации (код сервера будет на PHP, но думаю не составит большого труда переписать его на что угодно). Для начала напишем простенькую функцию формирования начала блока (по сути эта функция исходя из некоторых входных данных должна формировать стандартный span со спец-классом).
Как видно, в функции используется две внешних переменных, $curTime (текущее время в нужном формате), а так же $tcc (список кешей клиента, а его получении на сервере с клиента мы поговорим ниже). В остальном логика функции очень проста и понятна.
Далее, нам необходимо на стороне клиента (т.е. на стороне JS) написать некоторый набор сервисных функций для работы со стораджем (в данном случае с localStorage).
Здесь тоже всё просто… в storSet мы сохраняем данные не забывая указать id и сохранить ttl для проверки валидности блоков. В storGet мы извлекаем блок по его id, проверяем валидность ttl и, в случае успеха, возвращаем закешированный блок.
Затем нам необходим мегапарсер, который и будет разбирать всё полученное от сервера.
Говорить тут тоже особо не о чем, так как код достаточно прозрачен. Нашли блок -> поняли что это -> произвели необходимое действие.
В итоге, единственное, что нам осталось сделать на стороне клиента — дать знать серверу, что за кешем мы обладаем, что бы сервер мог правильно сформировать последующие страницы. В виде транспорта был выбран простой и элементарный — печеньки.
Кукисы формируются вполне прозрачно, проходимся по хранилищу выискивая наши блоки и заполняем список в кукисах указывая ID и TTL каждого блока. В приведенном куске код используется еще одна сервисная функция storExist, которая почти аналогична storGet за тем лишь исключением, что она возвращает TTL блока в случае, если этот блок есть и валиден.
Ну вот, на стороне клиента мы по сути всё сделали, теперь вернемся к серверу. В самом начале я упомянул некий массив $tcc (для функции формирования маркерных блоков), который нам и необходимо сформировать.
Всё элементарно.
Надо сказать, что результатом эксперимента я вполне доволен. В итоговом скрипте я получил простую систему, которая на автоматике обрабатывает кеш, мержит и передает так мало трафика, как только возможно. Итоговый JS скрипт (который в идее должен всегда передаваться от клиента к серверу) занимает 2к трафика сжатого YUV но несжатого GZip, что по мне, так вполне приемлемо. Так же стоит отметить, что в случае старых браузеров или поисковиков, на стороне клиента не будет поддержки JS, localStorage или Cookie, а значит сервер будет всегда думать, что кеша на стороне клиента нет и будет всегда формировать полную страницу (т.е. мы получили автоматическую систему совместимости со старичками, что по мне, так очень здорово). Так же стоит отметить достаточно простую серверную реализацию, которая может легко быть совмещена с каким либо шаблонизатором и производить маркирование блоков и кеширование их как на стороне клиента, так и сервера без лишнего геморроя для программиста. Так же, опционально, можно кешировать таким образом JS и CSS помещенные прямо в тело документа (в тело документа, кстати, в этом случае можно инклюдить все необходимые скрипты и стили). В этом случае, разделив и выделив каждый JS или CSS в отдельный блок, мы получим удобную и элементарную систему погрузки только необходимого JS и CSS кода сократив до минимума запросов к серверу (даже если этот запрос просто проверка валидности кеша).
Явно необходимо избавляться от jQuery (ну это и так понятно).
Изменить маркировку блоков на что-то типа <!-- cc_<ID>_<MODE>[_<TTL>] -->, в этом случае мы сможем маркировать блоки не заботясь о совместимости со стандартами и целостностью разделяемого html (как ни как, с блоками span нам бы пришлось вырезать только законченные блоки html иначе, в случае не поддержки со стороны браузера TCC у нас бы всё развалилось).
Основными же минусами самой идеи являются:
Ну собственно вот и всё…
Хотелось бы услышать разумную критику и идеи оптимизации. С удовольствием отвечу на все вопросы.
P.S. К сожалению, не могу выложить пример рабочего скрипта, если кто подскажет местечко для 1 php файла, буду благодарен.
UPD. P.S. Ссылка на рабочий пример: catsmile.heliohost.org/Mear/tcc.php (спасибо пользователю catsmile за местечко)
UPD.2 P.P.S. Для ликвидации неясности понимания целей данного топика уточню. Я не предлагаю замену ajax в прямом смысле это слова. Я предлагаю лишь рассмотреть вариант клиентского кеширования в какой то конкретной реализации. Так же продемонстрированный код не претендует на завершенность и создан лишь для целей демонстрации подхода. Основными целями же данного топика являются сбор идей и замечаний по поводу идеи кеширования некоторых блоков на стороне клиента и методы работы с этими блоками.
Хочу поделиться с тобой идеей/реализацией аналога технологии ajax которая в отличии от первого лишена основных его недостатков. Из вики об ajax мы знаем что:
Преимущества
- Экономия трафика;
- Уменьшение нагрузки на сервер;
- Ускорение реакции интерфейса;
Недостатки
- Отсутствие интеграции со стандартными инструментами браузера;
- Динамически загружаемое содержимое недоступно поисковикам;
- Старые методы учёта статистики сайтов становятся неактуальными;
- Усложнение проекта;
Придуманная идея Template client cache (далее TCC) обладает те ми же достоинствами, что и ajax, но полностью лишена её недостатков.
Идея
В случае с ajax основная «фишка» заключается в загрузке отдельных блоков, что значительно экономит трафик. Но большой проблемой ajax является сильная несовместимость как со старыми браузерами и поисковиками, так и сложная интеграция в существующие проекты. Решая головоломку переписыванием очередного сайта на блоки с ajax я подумал, не уж то при помощи современных технологий нельзя добиться аналогичного результата но с меньшими затратами по внедрению и совместимости? Итак… закончим лить воду… идея до безумия проста: грузить только то, что нам необходимо обновить (ну правда, очень смахивает на идею ajax). Весь вопрос в реализации. За основу были взяты современные стандарты по поддержке некого хранилища для нужд JS (такие как localStorage) и идея кеширования шаблонов на стороне сервера. Скрестив их мы и получили TCC. Т.е., как и в случае шаблонов на сервере обычно вся страница делиться на куски, которые обрабатываются и формируются отдельными файлами (кусками кода), совмещаются и выбрасываются пользователем. Зачастую некоторые куски кешируются и не формируются повторно в течении некоторого времени. Идея заключается в переносе этого кеша некоторых кусков на сторону клиента и создание инфраструктуры для передачи информации от клиента к серверу и обратно для поддержания кеша в ликвидном состоянии. Т.е. получиться, что при загрузке страницы мы будем так же, как и обычно её формировать на стороне сервера, пропуская некоторые блоки, но не беря их из кеша сервера, а просто оставляя пустыми, и в таком виде будем передавать клиенту, где уже он будет объединять их с существующим кешем и отображать итоговую страницу пользователю. Из описания понятно, что:
- + Мы не будем формировать лишние блоки и не будем тратить на них время на стороне сервера (плюс в производительности, включая затраты на кеширование этих блоков);
- + Мы не будем передавать лишнюю (повторяющуюся) информацию от сервера к киленту (плюс в скорости загрузки и уменьшении трафика);
- + Мы по сути не меняем структуру и метод формирования документа (плюс в простоте интеграции в существующие движки/сайты, а так же отсутствие проблем с поисковиками и старыми браузерами, так как в случае отсутствия у них поддержки TCC они будут получать всегда полную версию страницы со всеми блоками);
Итого, последовательность работы TCC можно представить так:
- Клиент запрашивает страницу;
- Сервер формирует html разделяя его на логические блоки специальными маркерами блоков;
- Клиент получив эту страницу разделяет её по маркерам и помещает в кеш;
- Клиент переходит по ссылке на другую страницу этого же сайта;
- Сервер. зная какие блоки помещены в кеш, формирует страницу состоящую из пустых маркеров блоков и заполнеными маркерами блоков только для тех блоков, которые не актуальны в кеше (т.е. по сути формирует diff между старой и новой страницей);
- Клиент, получив такой diff, извлекает из кеша необходимые блоки и наполняет страницу;
- Profit;
Реализация
Понятно, что собирать я буду демо-пример и за короткий строк, а потому на многие вещи буду закрывать глаза (как то, например, использование jQuery для парсинга html, а так же некоторые облегченности для получения быстрого результата).
Список того, что можно будет улучшить и как я приведу ниже, так что не стоит относиться к демо-примеру критически (с точки зрения применения на продакшене).
Для начала нам нужно определиться с тем, как мы будем маркировать блоки для кеширования. Для простоты я взял стандартный html-элемент span, так как он мало влияет на содержащиеся в нем блоки (т.е. нормально работает и с плавающими вложенными блоками и с инлайновым контекстом). Для маркирования, что это именно маркер, был выбран спец класс именуемый по следующему принципу:
tcc_<ID>_<MODE>[_<TTL>];
Где:
<ID> — Уникальный номер блока;
<MODE> — Режим кеширования (о нем ниже);
<TTL> — Время жизни кеша;
Режим кеширования предназначен для указания клиенту, с каким именно блоком он имеет дело. Было выделено три режима кеширования:
r (realtime) — блок, не подлежащий кешированию (обновляющийся при каждой перезагрузки страницы);
s (server) — блок, сформированный на сервере и подлежащий кешированию (создаётся в случае, если необходимо сформировать или заменить блок в кеше);
c (client) — блок, сформированный на сервере пустым, в который клиент должен поместить закешированные данные;
Перейдем к реализации (код сервера будет на PHP, но думаю не составит большого труда переписать его на что угодно). Для начала напишем простенькую функцию формирования начала блока (по сути эта функция исходя из некоторых входных данных должна формировать стандартный span со спец-классом).
function blockStart($id, $ttl = false)
{
global $curTime;
global $tcc;
if (!$ttl)
{
echo '<span class="tcc_' . $id . '_r">';
return true;
}
else if (isset($tcc[$id]) && ($tcc[$id] > $curTime))
{
echo '<span class="tcc_' . $id . '_c_' . $tcc[$id] . '">';
return false;
}
else
{
echo '<span class="tcc_' . $id . '_s_' . $ttl . '">';
return true;
}
}
Как видно, в функции используется две внешних переменных, $curTime (текущее время в нужном формате), а так же $tcc (список кешей клиента, а его получении на сервере с клиента мы поговорим ниже). В остальном логика функции очень проста и понятна.
Далее, нам необходимо на стороне клиента (т.е. на стороне JS) написать некоторый набор сервисных функций для работы со стораджем (в данном случае с localStorage).
function storSet(id, ttl, value)
{
localStorage.setItem('tcc_' + id, ttl + ':' + value);
}
function storGet(id, ttl)
{
var data = localStorage.getItem('tcc_' + id);
if (data == null) return null;
var data_ttl = data.substr(0, 12).split(':', 1)[0];
if ((data_ttl != ttl) || (data_ttl <= curTime)) return null;
return data.substr(data_ttl.length + 1);
}
Здесь тоже всё просто… в storSet мы сохраняем данные не забывая указать id и сохранить ttl для проверки валидности блоков. В storGet мы извлекаем блок по его id, проверяем валидность ttl и, в случае успеха, возвращаем закешированный блок.
Затем нам необходим мегапарсер, который и будет разбирать всё полученное от сервера.
function tcc()
{
var item;
while ((item = $('[class^=tcc_]:first')) && (item.length != 0))
{
var cn = item.attr('class').split('_');
if (cn[2] == 's')
{
var nItem = item.clone();
var cItem;
while ((cItem = nItem.find('[class^=tcc_]:first')) && (cItem.length != 0))
{
cItem.replaceWith('<span class="cache_' + cItem.attr('class') + '"></span>');
}
storSet(cn[1], cn[3], nItem.html());
}
else if (cn[2] == 'c')
{
var data = storGet(cn[1], cn[3])
if (data == null)
{
alert('critical error');
}
else
{
var nItem = $('<span>' + data + '</span>');
var cItem;
while ((cItem = nItem.find('[class^=cache_tcc_]:first')) && (cItem.length != 0))
{
var ncn = cItem.attr('class').split('_');
var rItem = item.find('[class^=tcc_' + ncn[2] + '_]');
if (rItem.length != 0)
{
cItem.replaceWith('<span class="' + rItem.attr('class') + '">' + rItem.html() + '</span>');
}
else
{
cItem.remove();
}
}
item.replaceWith(nItem.html());
}
}
if (cn[2] != 'c')
{
item.replaceWith(item.html());
}
}
...
}
Говорить тут тоже особо не о чем, так как код достаточно прозрачен. Нашли блок -> поняли что это -> произвели необходимое действие.
В итоге, единственное, что нам осталось сделать на стороне клиента — дать знать серверу, что за кешем мы обладаем, что бы сервер мог правильно сформировать последующие страницы. В виде транспорта был выбран простой и элементарный — печеньки.
function tcc()
{
...
var storage = '';
for (var i = localStorage.length - 1; i >= 0; i--)
{
var key = localStorage.key(i);
var prefix = key.split('_', 1)[0];
var key = key.substr(prefix.length + 1);
if (prefix != 'tcc') continue;
var ttl = storExist(key);
if (ttl != null)
{
if (storage.length != 0) storage += ',';
storage += key + '_' + ttl;
}
else
{
localStorage.removeItem('tcc_' + key);
}
}
var cookie = 'tcc=' + escape(storage) + ';path=/';
if (storage == '') cookie += ';expires=Thu, 01-Jan-1970 00:00:01 GMT';
document.cookie = cookie;
}
Кукисы формируются вполне прозрачно, проходимся по хранилищу выискивая наши блоки и заполняем список в кукисах указывая ID и TTL каждого блока. В приведенном куске код используется еще одна сервисная функция storExist, которая почти аналогична storGet за тем лишь исключением, что она возвращает TTL блока в случае, если этот блок есть и валиден.
function storExist(key)
{
var data = localStorage.getItem('tcc_' + key);
if (data == null) return false;
var data_ttl = data.substr(0, 12).split(':', 1)[0];
if (data_ttl <= curTime) return null;
return data_ttl;
}
Ну вот, на стороне клиента мы по сути всё сделали, теперь вернемся к серверу. В самом начале я упомянул некий массив $tcc (для функции формирования маркерных блоков), который нам и необходимо сформировать.
if (isset($_COOKIE['tcc']))
{
$list = explode(',', $_COOKIE['tcc']);
for ($i = 0; $i < count($list); $i++)
{
$item = explode('_', $list[$i]);
if (count($item) == 2)
{
$tcc[$item[0]] = $item[1];
}
}
}
Всё элементарно.
Подведение итогов
Надо сказать, что результатом эксперимента я вполне доволен. В итоговом скрипте я получил простую систему, которая на автоматике обрабатывает кеш, мержит и передает так мало трафика, как только возможно. Итоговый JS скрипт (который в идее должен всегда передаваться от клиента к серверу) занимает 2к трафика сжатого YUV но несжатого GZip, что по мне, так вполне приемлемо. Так же стоит отметить, что в случае старых браузеров или поисковиков, на стороне клиента не будет поддержки JS, localStorage или Cookie, а значит сервер будет всегда думать, что кеша на стороне клиента нет и будет всегда формировать полную страницу (т.е. мы получили автоматическую систему совместимости со старичками, что по мне, так очень здорово). Так же стоит отметить достаточно простую серверную реализацию, которая может легко быть совмещена с каким либо шаблонизатором и производить маркирование блоков и кеширование их как на стороне клиента, так и сервера без лишнего геморроя для программиста. Так же, опционально, можно кешировать таким образом JS и CSS помещенные прямо в тело документа (в тело документа, кстати, в этом случае можно инклюдить все необходимые скрипты и стили). В этом случае, разделив и выделив каждый JS или CSS в отдельный блок, мы получим удобную и элементарную систему погрузки только необходимого JS и CSS кода сократив до минимума запросов к серверу (даже если этот запрос просто проверка валидности кеша).
Минусы (или что можно сделать иначе)
Явно необходимо избавляться от jQuery (ну это и так понятно).
Изменить маркировку блоков на что-то типа <!-- cc_<ID>_<MODE>[_<TTL>] -->, в этом случае мы сможем маркировать блоки не заботясь о совместимости со стандартами и целостностью разделяемого html (как ни как, с блоками span нам бы пришлось вырезать только законченные блоки html иначе, в случае не поддержки со стороны браузера TCC у нас бы всё развалилось).
Основными же минусами самой идеи являются:
- Необходимость на стороне сервера следить за актуальностью кеша для каждого клиента (например, в случае корзины товаров в интернет магазине, также должен меняться при изменении корзины и быть уникальным для клиента, т.е. мы должны как то понимать, что кеш клиента устарел);
- Потенциальное разрастание cookie, что ведет за собой увеличение трафика от клиента к серверу (но это именно потенциальная проблема, так как в итоге всё зависит от выбранных TTL блоков и их количества;
Ну собственно вот и всё…
Хотелось бы услышать разумную критику и идеи оптимизации. С удовольствием отвечу на все вопросы.
UPD. P.S. Ссылка на рабочий пример: catsmile.heliohost.org/Mear/tcc.php (спасибо пользователю catsmile за местечко)
UPD.2 P.P.S. Для ликвидации неясности понимания целей данного топика уточню. Я не предлагаю замену ajax в прямом смысле это слова. Я предлагаю лишь рассмотреть вариант клиентского кеширования в какой то конкретной реализации. Так же продемонстрированный код не претендует на завершенность и создан лишь для целей демонстрации подхода. Основными целями же данного топика являются сбор идей и замечаний по поводу идеи кеширования некоторых блоков на стороне клиента и методы работы с этими блоками.

