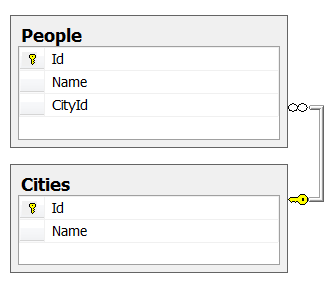
История стара как мир. Две таблицы:
- Cities – 100 уникальных городов.
- People – 10 млн. людей. У некоторых людей город может быть не указан.
Распределение людей по городам – равномерное.
Индексы на поля Cites.Id, Cites.Name, People .CityId – в наличии.
Нужно выбрать первых 100 записей People, отсортированных по Cites.
Засучив рукава, бодро пишем:
select top 100 p.Name, c.Name as City from People p
left join Cities c on c.Id=p.CityId
order by c.Name
При этом мы получим что-то вроде:
За… 6 секунд. (MS SQL 2008 R2, i5 / 4Gb)
Но как же так! Откуда 6 секунд?! Мы ведь знаем, что в первых 100 записях будет исключительно Алматы! Ведь записей – 10 миллионов, и значит на город приходится по 100 тыс. Даже если это и не так, мы ведь можем выбрать первый город в списке, и проверить, наберется ли у него хотя бы 100 жителей.
Почему SQL сервер, обладая статистикой, не делает так:
select * from People p
left join Cities c on c.Id=p.CityId
where p.CityId
in (select top 1 id from Cities order by Name)
order by c.[Name]
Данный запрос возвращает примерно 100 тыс. записей менее чем за секунду! Убедились, что есть искомые 100 записей и отдали их очень-очень быстро.
Однако MSSQL делает все по плану. А план у него, «чистый термояд» (с).
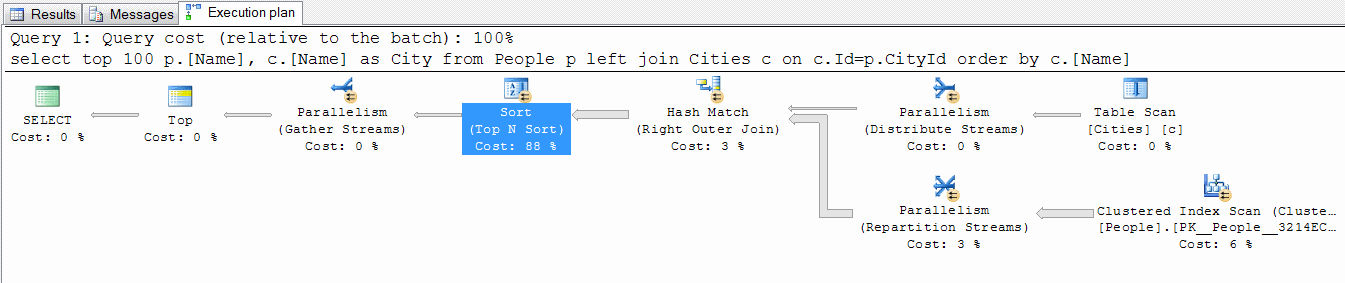
Вопрос к знатокам:
каким образом необходимо исправить SQL запрос или сделать какие-то действия над сервером, чтобы получить по первому запросу результат в 10 раз быстрее?
P.S.
CREATE TABLE [dbo].[People] (
[Id] uniqueidentifier NOT NULL,
[Name] nvarchar(50) NOT NULL,
[CityId] uniqueidentifier
)
ON [PRIMARY]
GO
CREATE TABLE [dbo].[Cities] (
[Id] uniqueidentifier NOT NULL,
[Name] nvarchar(50) NOT NULL,
)
ON [PRIMARY]
GO
P.P.S
Откуда растут ноги:
Задача вполне реальная. Есть таблица с основной сущностью, от нее по принципу «звезда» отходит множество измерений. Пользователю нужно ее отобразить в гриде, предоставив сортировку по полям.
Начиная с некоторого размера основной таблицы сортировка сводится к тому, что выбирается окно с одинаковыми (крайними) значениями, (вроде «Алматы») но при этом система начинает жутко тормозить.
Хочется иметь ОДИН параметризированный запрос, который будет эффективно работать как с малым размером таблицы People так и с большим.
P.P.P.S
Интересно, что если бы City были бы NotNull и использовался InnerJoin то запрос выполняется мгновенно.
Интересно, что ДАЖЕ ЕСЛИ поле City было бы NotNull но использовался LeftJoin – то запрос тормозит.
В комментах идея: Сперва выбрать все InnerJoin а потом Union по Null значениям. Завтра проверю эту и остальные безумные идеи )
P.P.P.P.S Попробовал. Сработало!
WITH Help AS
(
select top 100 p.Name, c.Name as City from People p
INNER join Cities c on c.Id=p.CityId
order by c.Name ASC
UNION
select top 100 p.Name, NULL as City from People p
WHERE p.CityId IS NULL
)
SELECT TOP 100 * FROM help
Дает 150 миллисекунд при тех же условиях! Спасибо holem.

