
Привет! Меня зовут Галя, я работаю продакт-менеджером в MTS AI. Мы разрабатываем решения для автоматизации коммуникаций в различных сферах. Среди наших проектов: боты-консультанты для входящей и исходящей коммуникаций, голосовые помощники и другие решения для бизнеса.
Вместе с моей коллегой Ангелиной (@angelina_ku), руководителем группы внедрения NLP-решений, мы исследовали личность бота — из чего она складывается и как формируется. С докладом на эту тему мы выступили на конференции CONVERSATIONS'22. Сейчас решили, что узнать о выводах нашего исследования было бы полезно и интересно всем пользователям Хабра, и написали эту статью. Она будет состоять из двух частей: методологической и технической. Из моей части, методологической, вы узнаете:
зачем боту нужна личность, и почему ее создание может стать тяжелой задачей;
как человек воспринимает личность, и по каким деталям он ее оценивает (тон, лексика, ошибки) —тут добавим немного психологии и сценаристики;
ответим на вопрос, нужна ли вашему боту личность (спойлер: может так сложиться, что и нет);
поговорим о том, как виртуальный персонаж может помочь бизнесу донести ценность до клиента.
Что такое личность бота, почему она важна
Если вы не тратите массу времени на создание героя и проработку его мотивации, то люди могут спроецировать на ваше приложение мотивы, черты характера и другие качества, которые вы не хотите ассоциировать с вашим брендом. — Орен Джейкоб (Google I/O '17)
Забегая вперед, обращу ваше внимание на цитату, с которой склонна согласиться - если вы заранее не подумаете о личности, клиенты сделают это за вас. А результат может оказаться непредсказуемым.
Итак, наше исследование началось с главного вопроса: что такое личность в контексте разработки виртуального помощника, важна ли она?
Как известно, боты, которые используются бизнесом для решения повседневных задач автоматизации коммуникации, не всегда имеют продуманную личность/черты характера и визуальное представление. Но как бы бизнес ни сопротивлялся идее прорабатывания личности, личность эта у виртуального помощника всегда есть. Дело в том, что с ним общаются люди, которые в своем сознании наделяют собеседника чертами одушевленного существа (будь то человек, робот, животное или фантастический персонаж), особым характером. Причина тому – существенные отличия диалога с ботом от других видов компьютерного взаимодействия. Такое общение часто похоже на переписку в мессенджерах или разговор по телефону с оператором один на один.
Люди присваивают боту черты характера зачастую неосознанно. И здесь возникает вопрос в том, как и насколько удачно бизнес/заказчик бота поучаствовал в формировании определенного представления о боте и его айдентики в сознании людей.
Никак – и тогда результаты могут неприятно удивить; вы же не даете пользователям самим выбирать название для компании или продукта? Почему же с личностью не так?
Частично – какие-то черты бота были продуманы, остальное домыслили пользователи.
Полностью – у бота появилась полноценная личность, характер, визуальное представление, а индивидуальные интерпретации пользователей свелись к минимуму.
Польза для бизнеса
Окей, казалось бы негативные последствия очевидны: негативные ассоциации с брендом, неправильного позиционирования, но а в чем плюсы? Для чего бизнесу нужен контроль над представлением о личности бота?
Бот – продолжение айдентики самого продукта/компании, а значит полноценный маркетинговый инструмент и канал продвижения продукта/услуг; когда пользователи говорят с вашим ботом, они проживают/чувствуют бренд через виртуального помощника.
Боты с проработанной личностью могут вовлечь пользователей во взаимодействие с продуктом (и как следствие, например, увеличить конверсию), создадут эмоциональную связь между клиентами и продуктом с помощью диалогового интерфейса.
Саппорт – лицо бизнеса, точка соприкосновения с пользователями, и продуманная личность виртуального помощника, его цельный образ улучшают показатели клиентских метрик (NPS, CSat и др.) в каналах поддержки.
Для разработчиков решения (в том числе сценаристов) личность становится базой, на основе которой легче продумать функционал бота, его конечную цель и набор навыков.
Отдельно стоит отметить, что сама по себе продуманная личность не является панацеей от низкого качества бота, так как напрямую не влияет на уровень оказываемых услуг. Следовательно, не стоит сосредотачиваться на проработке личности, если это идет в ущерб техническим и консультационным характеристикам самого решения автоматизации коммуникаций. Качественный функционал в данном случае выступает первоочередной и наиболее важной задачей, вокруг которой строится личность бота.
Разные подходы к параметризации личности | методология
Принимая во внимание все вышесказанное, мы решили проанализировать главные составляющие личности бота, которые так или иначе должны находить свое отражение в реакциях, поведении и во внешнем виде виртуального ассистента, а главное – должны быть четко описаны на этапе проектирования.
Нами были проанализированы два основных подхода к описанию любой личности:
психологический (черты характера, темперамент, акцентуации и пр.);
сценарный (история персонажа, вехи развития, цели и мотивы).
Вместе с психологом мы выделили основные группы характеристик личности. И вот лишь некоторые из них:
юмор и его стиль;
темперамент, базовые эмоции и черты характера бота;
отношение к людям, компании, конкурентам;
какие эмоциональные реакции должен проявлять бот: печаль, радость, злость.

Если хотите получить полную схему со всеми характеристиками бота, напишите мне или Ангелине в личку, мы вам ее пришлем.
После этого этапа стало очевидно, что нужно прорабатывать способы проявления той или иной характеристики непосредственно в речи и поведении самого ассистента. Тут в игру вступила сценаристка, ее взгляд на проблему описания личности позволил описать способы выражения определенных характеристик непосредственно в речи и поведении.
Давайте рассмотрим, как раскладывается на конкретные аспекты юмор.
ирония (см. афоризмы Оскара Уайльда),
сарказм (подойдет для малоэмоциональных персонажей),
абсурдный юмор (Монти Пайтон),
черный юмор (сюда же - юмор висельника),
туалетный юмор,
детский юмор (когда персонаж ведет себя как ребенок, показывает язык, говорит "нет, ТЫ виноват!", или читает стишок про жадину-говядину),
смех над собой (самоуничижительный).
смех над другими (юмор наблюдателей, часто используется в стендапе),
физическая комедия (нужно визуальное отображение, самый яркий пример - Чарли Чаплин),
музыкальный юмор (нужны музыкальные эффекты),
как раскрывается →
пародийное/карикатурное обыгрывание каких-то черт во внешности или действиях персонажа;
"внутренние" шутки, которые выходят из повторяющихся тем в ответах;
фонетические шутки: комичное повышение или понижение тона ("детский"голосок как после вдыхания гелия), имитация какого-то звука (например, трубы или чего похлеще ??️), имитация заезженной пластинки, воспроизведение какой-то подходящей к случаю мелодии (свадебного или похоронного марша), пародирование чьего-то голоса или манеры говорить/петь;
возраст, темперамент, основные черты характера и степень эмпатии влияют на стиль юмора (взрослому робкому персонажу-меланхолику с высокой степенью эмпании вряд ли подойдет туалетный юмор);
визуальные эффекты могут отражать стиль юмора персонажа;
интересно работает контраст: например, тонкий голосок у персонажа-глыбы или глубокий бас у цыпленка;
безэмоциональные реплики или выражения лица могут дать дополнительный смешной эффект, когда персонаж произносит шутку (добить можно монотонным звукоподражанием "ХА-ХА");
Кстати, оказалось, что юмор влияет примерно на все аспекты личности, проявляется практически в любых реакциях, так что без должного внимания к нему при построении личности не обойтись.
Разные подходы к параметризации личности | реализация
Это все конечно очень увлекательно, но что с этим делать, подумали мы и показали всю эту красоту техническим специалистам. Они странно на нас посмотрели, и тогда мы наконец поняли вот что:
личность – многокомпонентное понятие, для определения и описания которого необходим глубокий анализ всех его составляющих;
хотя личность может находить выражение не только в речи, но и в визуальном образе и поведенческих особенностях помощника, разработчики бота в первую очередь отвечают именно за речевое ее представление;
для того чтобы бизнес-заказчик мог описать личность своего будущего ассистента, ему необходимо предоставить четкую (и, возможно, упрощенную) систему координат, где каждая характеристика личности будет иллюстрироваться конкретным примером ее выражения в речи/поведении;
основная сложность реализации — перенос выбранных характеристик личности на конкретный диалог, выбор нужного лексического обрамления;
технические возможности тонкой настройки личности в функционале, который основан не на правилах, а на ML-инструментах, ограничены, а значит, мы должны управлять ожиданиями заказчика, для чего и проводится глубокий анализ представлений о личности.
Из последнего тезиса выходит, что необходимы дополнительные исследования возможностей ML-инструментов в сфере тюнинга личностных характеристик Open Domain ботов. Про ML будет позже.
Взаимодействие личности и функционала бота | умения бота
Полноценный анализ личности и способов ее выражения невозможен без тесной связи этих характеристик с тем функционалом, которым бот обладает. Следующим этапом работы стало аналитическое исследование опыта взаимодействия и взаимовлияния личности и скиллов (навыков) конкретных ботов, разработанных в нашей компании.
Теперь к упомянутой выше схеме параметров личности добавилась классификация скиллов на основе их функциональных особенностей (Развлекательный/Социальный, Функциональный, Поддерживающий) и транслируемого контента (Контентный – ретранслируем контент, Неконтентный – выполняем функцию). Примеры конкретных скиллов, встроенных в матрицу такой классификации, – ниже:
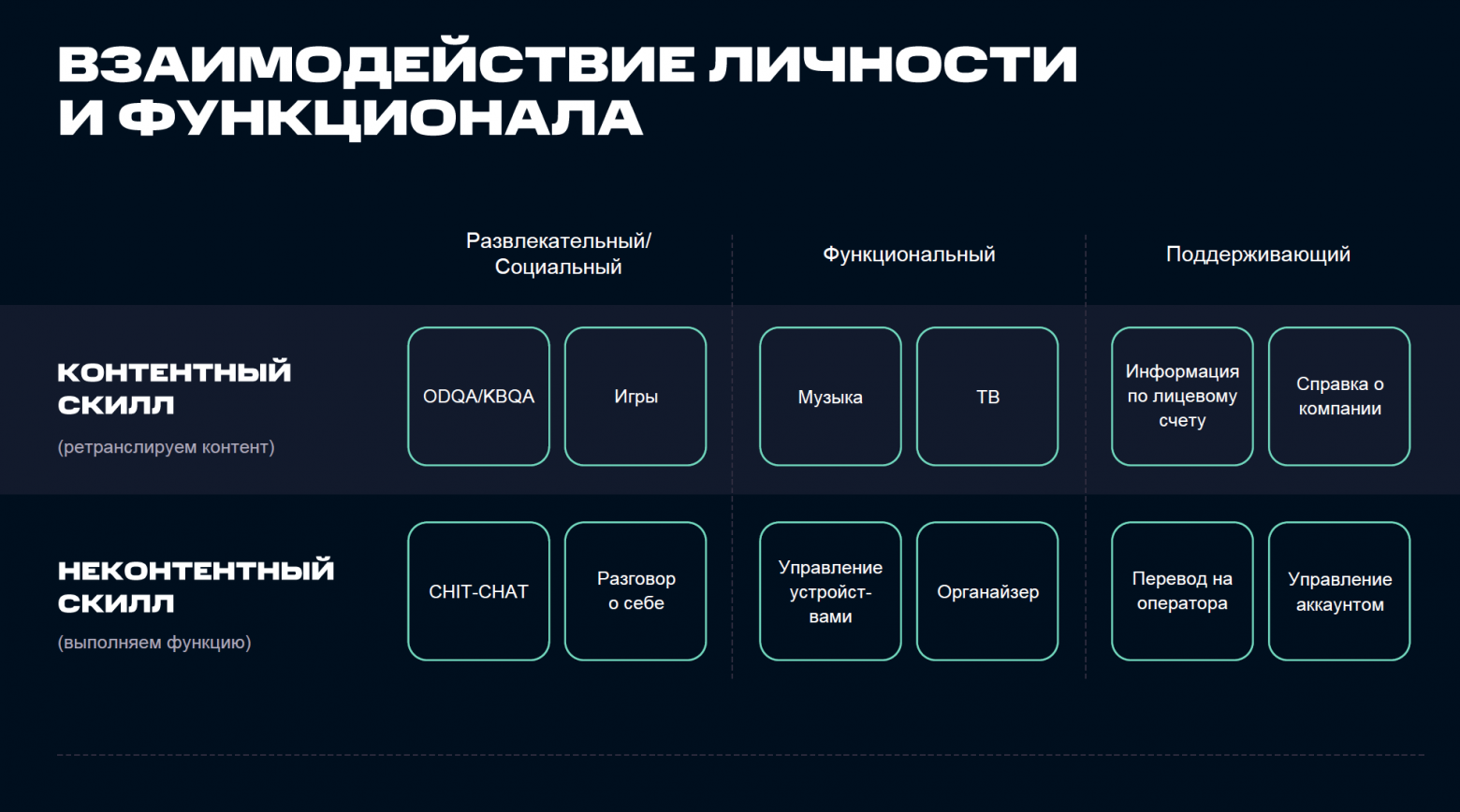
Мы попробовали приложить составленную классификацию к степени важности описания личности (и степени ее участия) для каждой такой группы скиллов и построить условный график степени проявления личности по скиллам различного типа:

Таким образом, мы получаем наглядное представление связи личности бота и его функционала на практике. Это позволяет гибко настраивать глубину проработки и выражения личностных характеристик (черт характера и специфики поведения) бота в зависимости от задач, которые ставит перед собой бизнес, автоматизируя коммуникацию.
Основные выводы по окончании данного этапа работы:
функционал и личность бота тесно связаны между собой;
различные скиллы помощника по-разному соотносятся с проявлениями личности и помогают выражать его личностные характеристики;
уже на этапе продумывания скилла необходимо понять, как он встроится в общий набор личностных характеристик бота, не разрушит ли он целостную личность, не повлияет ли на общее представление о боте;
и наоборот: на этапе разработки личности необходимо иметь (хотя бы верхнеуровневый) набор скиллов/функционал будущего помощника, для того чтобы личность этому функционалу не противоречила, а поддерживала его и превращала из разрозненного набора умений в единое целое.
Но тут мы упираемся в противоречие: чем сильнее мы продумываем личность, тем сильнее поляризуется наша аудитория — сильно любят, сильно не любят яркую личность. Где остановиться — решать вам.
Ожидания заказчиков
Параллельно с теоретической частью исследования мы собирали представления о личности бота у наших коллег-заказчиков различных способов автоматизации коммуникаций, которые уже используют или только планируют использовать ботов в своих целях. Это было нужно не только, чтобы из первых уст узнать о потребностях бизнеса в создании личностно наполненных ботов, но и чтобы синхронизировать представления о личностных характеристиках разных участников рабочего процесса. Другими словами: каждый из нас имеет какое-то представление о том, что значит хорошее чувство юмора или доброжелательный собеседник, но совпадают ли наши представления о чувстве юмора? Для кого-то критерием хорошего чувства юмора будет умение рассказать анекдот, а для кого-то – способность дать ироничный комментарий в ответ на колкость от пользователя.
Именно для выявления такой многозначности терминов, для сбора общих представлений о базовых личностных характеристиках мы и решили попросить наших заказчиков заполнить бриф по личности бота (если кому то нужна ссылка на бриф - с радостью поделюсь, стучитесь за ним в личку).
Основные выводы анализа заполненных брифов:
важность продуманной личности для разных продуктов будет разной (duh) – и это подтверждает выводы, сделанные выше в разделе анализа функционала;
личность тесно связана с целями продукта, характеристиками бренда и мотивацией автоматизации коммуникаций;
выбор характеристик личности бота напрямую зависит от той аудитории, которая с этим ботом будет общаться (ее ожидания от общения накладывают ограничения на финальный образ результата);
необходима четкая система координат для описания личности, словесные расплывчатые описания на основе индивидуальных представлений заполняющего бриф по личности не могут стать отправной точкой для разработчиков бота, так как не учитывают технические ограничения инструментария разработки подобных решений.
Именно поэтому нам необходимо сформировать ожидания заказчика, скорректировав их техническими ограничениями разработки и предоставить понятную и лаконичную систему характеристик для описания личности. Примером такого описания может служить подобная визуальная анкета.

Итак, мы выделили параметры, описали характеристики, вывели способы выражения этих черт - речь, аудиоэффекты, имя и пр. Как это все теперь реализовывать? Передаю слово своей коллеге Ангелине @angelina_ku.
Технические аспекты реализации личности бота
Представим, что у вас уже есть некий образ, который вы хотите воплотить в реальность.
Чтобы реализовать его, первой и самой важной задачей будет научить бота общаться в определенной манере: вежливой, ироничной или неформальной. Все зависит от того, какие черты личности вы выбрали. Отмечу, что стиль текста – это комплексная характеристика, которая затрагивает все уровни языка (синтаксис, семантику, морфологию), и, соответственно, стиль может по-разному проявляться в тексте – он может быть выражен в определенных синтаксических конструкциях, может отражаться в выборе слов.
Text style transfer
Одним из наиболее популярных методов, с помощью которого можно модифицировать реплики бота, чтобы они отражали нужную личностную характеристику, является text style transfer. Задача этого подхода состоит в том, чтобы преобразовать исходный текст в текст с нужным стилем с сохранением смысла.
Для решения задачи text style transfer используются два типа датасетов – параллельные и непараллельные. В параллельных датасетах есть взаимно однозначное соответствие между текстом одного стиля и текстом другого стиля. Например, текстам делового стиля противопоставлены тексты разговорного. Объем параллельных наборов данных обычно не очень большой, потому что их достаточно сложно составлять.

Чаще всего с такими наборами данных используются seq2seq-модели. Рассмотрим пример из статьи [Toshevska, Gievska, 2021]. Работает все достаточно просто: на вход в энкодер подается эмбеддинг исходного предложения и эмбеддинг текущего стиля текста, а на вход в декодер подается эмбеддинг желаемого стиля текста. На выходе мы получаем то же по смыслу предложение, что и на входе, только в другой манере.

В исследованиях используются также непараллельные данные, сбор которых происходит гораздо проще, поэтому их объем в разы превышает количество параллельных. Тексты непараллельного датасета представляют собой наборы данных, которым приписана та или иная метка стиля текста: юмор, флирт и кликбейт.

Здесь стоит сказать, что для обучения на таких датасетах тоже подходят seq2seq-модели. Однако их архитектура может отличаться от предыдущей: в работе [Hu et al., 2017] в качестве промежуточного состояния сети выдается представление, состоящее из двух компонентов, один из которых отвечает за содержание предложения, а другой — за стиль. Также у этой модели есть модуль-дискриминатор, который в процессе обучения посылает сигналы нейронной сети, чтобы генерируемые ей реплики соответствовали заданному стилю.

Еще один подход можно условно назвать редактированием прототипа. Что он из себя представляет?
В исходном предложении детектируются слова, которые характеризуют тот или иной стиль,
Из корпуса текстов, обладающих теми характеристиками, которыми мы хотим наделить наш исходный текст, извлекаются новые маркеры стиля.
С помощью этих новых данных мы можем модифицировать наше предложение.
На рисунке представлен пример подобной архитектуры модели из исследования [Tran et al., 2020], которая превращает оскорбительные реплики в нейтральные.

Датасеты для персонализации чат-ботов
Рассказывая о том, как создать виртуальную личность, нельзя не упомянуть еще одну интересную тему: датасеты типа персона-чат. Данные такого типа тоже позволяют персонифицировать виртуальных помощников.
Первый подобный набор данных для английского языка [Zhang et al., 2018] создала команда Facebook AI research (принадлежит Meta, организации, признанной в РФ экстремистской). Исследователи предложили небольшие описания выдуманных личностей. Каждая персона описана в пяти предложениях, где рассказывается о ее увлечениях, роде деятельности и так далее, например:
I am a vegetarian.
I like swimming.
My father used to work for Ford.
My favorite band is Maroon5.
I got a new job last month, which is about advertising design.
Все подобные датасеты схожи по своей структуре, и такой датасет есть и на русском языке - Toloka Persona Chat Rus. Он содержит профили более 1500 виртуальных персон и свыше 10 000 диалогов между участниками исследования разговорного искусственного интеллекта, которое проходило в МФТИ.
В аналогичном наборе данных на китайском языке [Zheng et al., 2020] есть также разметка возраста, пола и места жительства участников диалога. Отмечу еще одну работу [Mazare et al., 2018], в которой подобный датасет создавался из данных Reddit, а характеристики пользователей автоматически извлекались с помощью заранее заданных эвристик.
Однако у всех этих наборов данных есть существенные недостатки.
Диалоги чаще всего касаются только заданных характеристик личности, поэтому модели могут плохо справляться с ответами на реплики, которые к ним не относятся. Например, модель, обученная на таких данных, может сгенерировать не очень уместный ответ или начать противоречить информации, которую сама сгенерировала ранее.
Характеристики личности в подобных датасетах касаются по большей части интересов и увлечений и не отражают темперамент, эмоциональные реакции, базовые эмоции, черты характера.
Объем таких датасетов не очень большой, поэтому с их помощью практически невозможно создать большую генеративную модель, ориентированную на определенные черты личности.
Чтобы наделить своего бота личностью, необязательно выдумывать какого-то принципиально нового персонажа. Можно взять на вооружение героев любимых сериалов, фильмов и даже анимации. Так, появилась модель, которая может генерировать реплики в стиле героев мультсериала Adventure Time и «Крепкого орешка» [Han et al., 2022]. Также есть работы, в которых модели научились генерировать реплики в стиле какого-нибудь героя известного сериала [Li et al., 2016], [Tikhonova et al., 2021].
Подобные методики персонализации должны помочь в установлении контакта людей с ботами и формировании положительного отношения к ним.

Как научить ботов понимать эмоции?
Еще один большой пласт исследований касается ботов, обладающих эмпатией. Они умеют чутко реагировать на эмоциональное состояние пользователя. Обратите внимание на размеченные обучающие диалоги датасета EmpatheticDialogues [Rashkin et al., 2019]. В нем каждый диалог промаркирован эмоцией, которую испытывает пользователь.

Походы, которые применяются для обучения таких ботов, очень разнообразные: могут включать в себя обучение специальных моделей на каждый тип эмоционального состояния [Lin et al., 2019], могут использовать обучение с подкреплением [Shin et al., 2020], встроенный анализ тональности [Zaranis et al., 2021], а также специализированные языковые модели [Li et al., 2020].
Помимо эмпатии боты могут выражать определенные эмоции в своих репликах, например, радость, грусть, отвращение и многие другие.

Ранкер ответов
Последнее направление исследований, про которое я бы хотела рассказать, касается тюнинга ранкера ответов. Нейронная сеть, которая генерирует ответ, выдает несколько вариантов реплик. Помимо этого, иногда в чат-ботах используются заранее заготовленные реплики. И для того, чтобы финальная реплика, которая уже будет показана пользователю, соответствовала личностным характеристикам персоны бота, все эти варианты требуется отфильтровать. Для этого и используются различные методики настройки ранкера ответов бота: [Yi et al., 2019], подход ReplikaAI (retrieval model inference).
Немного про наш опыт
Личность — это синтез множества разных характеристик. Как мы видим, для каждой значимой характеристики, например, базовых эмоций, темперамента или юмора, требуется специализированный датасет и создание отдельной модели со своей уникальной архитектурой. Есть аспекты личности, которые технически реализовать проще, например, позитивную тональность текста. Для этого существует множество датасетов, и сама методика обучения моделей для такой задачи достаточно хорошо изучена. А, например, сделать бота, обладающего эмпатией уже куда более нетривиальная задача, требующая много усилий как для составления датасета, так и для проработки самой архитектуры модели. В наших собственных исследованиях и разработках мы придерживаемся гибридного подхода — таким образом, бот состоит из нескольких разных компонентов, каждый из которых выполняет свою особенную функцию.
В качестве генеративной модели используется GPT3. Обучение проходит с помощью специально отобранных текстов, по стилю и tone of voice соответствующих необходимым аспектам личности, которые мы хотим придать боту. На выходе из такой модели генерируется несколько вариантов реплик, и дальше они проходят дополнительное ранжирование и фильтрацию. Ранкер ответов позволяет выбрать наиболее подходящий по контексту вариант, который не должен противоречить личности бота и предыдущим репликам. В качестве ранкера в основном используется BERT, который обучается на специально созданном датасете, обогащенном adversarial-примерами.
Помимо этого, в общей архитектуре есть два фильтра: детоксификатор и классификатор запретных тем. Детоксификатор позволяет переписать предложение, которое звучит токсично и оскорбительно, в нормальный вид. Существует он в нескольких разных архитектурах — BERT, GPT, rut5, которые обучались на датасете из текстов Одноклассников и Пикабу. Классификатор чувствительных тем детектирует запросы, которые могут потенциально влиять на репутацию компании. К чувствительным темам относятся следующие – игромания, проституция, религия, бодишейминг, расизм, наркотики и т.п. В качестве классификатора использовался BERT. Для обучения модели использовались данные Двача и ответов мэйл.ру. Отмечу, что дополнительно размечалась не только тема высказывания, но и является ли оно приемлемым или нет. Приведу пример: если мы говорим, что «религия одурманивает народ» — то это неприемлемо, но если мы встретим предложение «в каком веке возник ислам?», то это вполне приемлемое предложение, не подразумевающее никаких оскорблений. Такой компонент-цензор позволяет отфильтровывать реплики бота.
Самым сложным этапом в реализации виртуальных личностей стал сбор подходящих данных и разметка. На это требовалось огромное количество времени и сил.
И, к сожалению, как бы ни старались наши разработчики, боты все равно будут делать ошибки. У нас, например, один бот заявил, что «Большой Лебовски» — очень хороший сериал. Чтобы предотвратить такие ситуации, нужно либо усложнять архитектуру генеративной модели, либо добавлять компонент фактчекинга.
Кроме того, такая многокомпонентная архитектура, включающая в себя достаточно тяжелые модели, нуждается в оптимизации, чтобы она работала быстро и эффективно.
Таким образом, моделирование персоны — это очень сложный исследовательский вопрос, на который еще не дан однозначный ответ. Сейчас для того, чтобы учесть все необходимые характеристики, приходится идти на различные архитектурные ухищрения и тратить очень много времени на сбор релевантных текстовых данных. Но мы верим, что игра стоит свеч.
Спасибо, что дочитали до конца.
Делитесь своими мнениями по этой теме в комментариях.
-----------------------------------------------------------------------------------------------------
Источники
Jin D. et al. Deep learning for text style transfer: A survey //Computational Linguistics. – 2022. – Т. 48. – №. 1. – С. 155-205.
Rao S., Tetreault J. Dear Sir or Madam, May I Introduce the GYAFC Dataset: Corpus, Benchmarks and Metrics for Formality Style Transfer //Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). – 2018. – С. 129-140.
Briakou E. et al. Olá, bonjour, salve! XFORMAL: A benchmark for multilingual formality style transfer //
Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. – 2021. – С. 3199-3216.Gan C. et al. StyleNet: Generating Attractive Visual Captions with Styles //2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). – IEEE Computer Society, 2017. – С. 955-964.
Xu W. et al. Paraphrasing for style //Proceedings of COLING 2012. – 2012. – С. 2899-2914.
Carlson K., Riddell A., Rockmore D. Evaluating prose style transfer with the Bible //
Royal Society open science. – 2018. – Т. 5. – №. 10. – С. 171920.Cao Y. et al. Expertise Style Transfer: A New Task Towards Better Communication between Experts and Laymen //Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. – 2020. – С. 1061-1071.
Toshevska M., Gievska S. A review of text style transfer using deep learning //IEEE Transactions on Artificial Intelligence. – 2021.
dos Santos C., Melnyk I., Padhi I. Fighting Offensive Language on Social Media with Unsupervised Text Style Transfer //Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). – 2018. – С. 189-194.
Tran M., Zhang Y., Soleymani M. Towards A Friendly Online Community: An Unsupervised Style Transfer Framework for Profanity Redaction //Proceedings of the 28th International Conference on Computational Linguistics. – 2020. – С. 2107-2114.
Huang Y. et al. Cycle-Consistent Adversarial Autoencoders for Unsupervised Text Style Transfer //
Proceedings of the 28th International Conference on Computational Linguistics. – 2020. – С. 2213-2223.Voigt R. et al. RtGender: A corpus for studying differential responses to gender //Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018). – 2018.
Hu Z. et al. Toward controlled generation of text //Proceedings of the 34th International Conference
on Machine Learning-Volume 70. – 2017. – С. 1587-1596.Zhang S. et al. Personalizing Dialogue Agents: I have a dog, do you have pets too? //Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). – 2018. – С. 2204-2213.
Mazare P. E. et al. Training Millions of Personalized Dialogue Agents //Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. – 2018. – С. 2775-2779.
Zheng Y. et al. Personalized dialogue generation with diversified traits //arXiv preprint arXiv:1901.09672. – 2019.
Rashkin H. et al. Towards Empathetic Open-domain Conversation Models: A New Benchmark and Dataset //Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. – 2019. – С. 5370-5381.
Shin J. et al. Generating empathetic responses by looking ahead the user’s sentiment //ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). – IEEE, 2020. – С. 7989-7993.
Lin Z. et al. MoEL: Mixture of Empathetic Listeners //Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). – 2019. – С. 121-132.
Zaranis E. et al. EmpBot: A T5-based Empathetic Chatbot focusing on Sentiments //
arXiv preprint arXiv:2111.00310. – 2021.Li S. et al. EmoElicitor: an open domain response generation model with user emotional reaction awareness //Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence. – 2021. – С. 3637-3643.
Zhou H. et al. Emotional chatting machine: Emotional conversation generation with internal and external memory //Proceedings of the AAAI Conference on Artificial Intelligence. – 2018. – Т. 32. – №1.
Demszky D. et al. GoEmotions: A Dataset of Fine-Grained Emotions //Proceedings of the 58th Annual Meeting
of the Association for Computational Linguistics. – 2020. – С. 4040-4054.Li J. et al. A Persona-Based Neural Conversation Model //Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). – 2016. – С. 994-1003.
Han S. et al. Meet Your Favorite Character: Open-domain Chatbot Mimicking Fictional Characters with only a Few Utterances //arXiv preprint arXiv:2204.10825. – 2022.
M. Tikhonova, E. Telesheva, S. Mirzoev, P. Tarantsova, S. Petrov and A. Fenogenova, "Style transfer in NLP:
a framework and multilingual analysis with Friends TV series," 2021 International Conference Engineering and Telecommunication (En&T), 2021, pp. 1-6, doi: 10.1109/EnT50460.2021.9681722.Yi S. et al. Towards Coherent and Engaging Spoken Dialog Response Generation Using Automatic Conversation Evaluators //Proceedings of the 12th International Conference on Natural Language Generation. – 2019. – С. 65-75.

