Прочитать в SQL Server табличку из Excel… В самом деле, что может быть проще? Для этого существует масса возможностей. Есть инструмент Integration Services, который бывшие DTS, есть мастер импорта/экспорта, который «за сценой» то же самое, можно по-быстрому сваять собственное ADO.NET-приложение, наконец, если неохота стрелять из пушек по воробьям, можно воспользоваться механизмом прилинкованных серверов, известным, как DTS, еще со времен семерки, который позволяет легко и элегантно увидеть теоретически любой ODBC/OLE DB-достижимый источник в виде таблицы (совокупности таблиц) или результата непосредственного (ad hoc) запроса. Так было до тех пор, пока 64-битная архитектура не перестала быть чем-то из области hi end и пришла на ноутбуки разработчиков и пользователей. Обычный пользователь, наверное, все-таки вряд ли будет ставить себе сервер баз данных, но для разработчика отнюдь не экзотична ситуация, когда на одной х64-машине уживаются 64-битный SQL Server с 32-битным MS Office. В этом случае создание прилинкованного сервера на Excel или Access вызывает проблему, потому что драйвера для них, понятно, 32-битные, которые SQL Server, будучи 64-битным, не понимает. Нет у него в списке известных ему провайдеров ничего похожего, хотя офис со всеми прибамбасами, включая connectivity, на компе стоит.
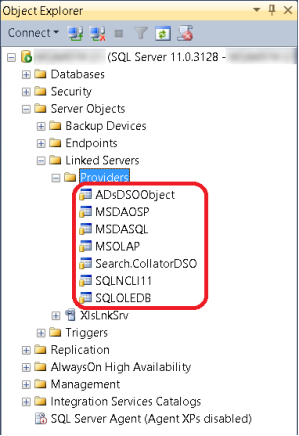
Рис.1
Соответственно, попытка использовать прилинкованный сервер на Excel, как
описано в документации, приводит к ошибке Msg 7302, Level 16, State 1, Line 1
Cannot create an instance of OLE DB provider «Microsoft.ACE.OLEDB.12.0» for linked server…
Возникает извечный вопрос «что делать»?


 В обязанности администратора баз данных входит много разных задач, которые, в основном, направлены на поддержку работоспособности и целостности базы данных. И если целостность данных можно проверить через команду CHECKDB, то с поиском невалидных объектов в схеме не все так гладко.
В обязанности администратора баз данных входит много разных задач, которые, в основном, направлены на поддержку работоспособности и целостности базы данных. И если целостность данных можно проверить через команду CHECKDB, то с поиском невалидных объектов в схеме не все так гладко.

 В данном топике хотелось бы поговорить о повышении производительности при работе с таблицами.
В данном топике хотелось бы поговорить о повышении производительности при работе с таблицами.
 В предыдущем посте была
В предыдущем посте была