Microsoft выпускает библиотеку с открытым исходным кодом под названием DeepSpeed, которая значительно расширяет возможности обучения для больших моделей естественного языка. Она дает возможность обучения нейросетей на моделях со 100 млрд параметров и более. DeepSpeed совместима с PyTorch.
Одна часть этой библиотеки, называемая ZeRO, представляет собой оптимизатор, который помогает масштабировать большие модели независимо от топологии. Ее уже использовали для создания Turing Natural Language Generation (Turing-NLG), крупнейшей общеизвестной языковой модели с 17 млрд параметров.
Zero Redundancy Optimizer (ZeRO) — это новая технология оптимизации памяти для крупномасштабного распределенного глубокого обучения. ZeRO способна тренировать модели глубокого обучения со 100 млрд параметров для кластеров графических процессоров текущего поколения с пропускной способностью, в три-пять раз превышающей пропускную способность лучшей из существующих систем. ZeRO может открыть доступ к обучению на моделях с триллионом параметров, уверены в Microsoft.
Современные крупные модели, такие как OpenAI GPT-2, NVIDIA Megatron-LM и Google T5, используют 1,5 миллиарда, 8,3 миллиарда и 11 миллиардов параметров соответственно.
Microsoft утверждает, что повышенная пропускная способность ZeRO может снизить стоимость обучения. Например, для обучения модели с 20 миллиардами параметров DeepSpeed потребует в три раза меньше ресурсов.
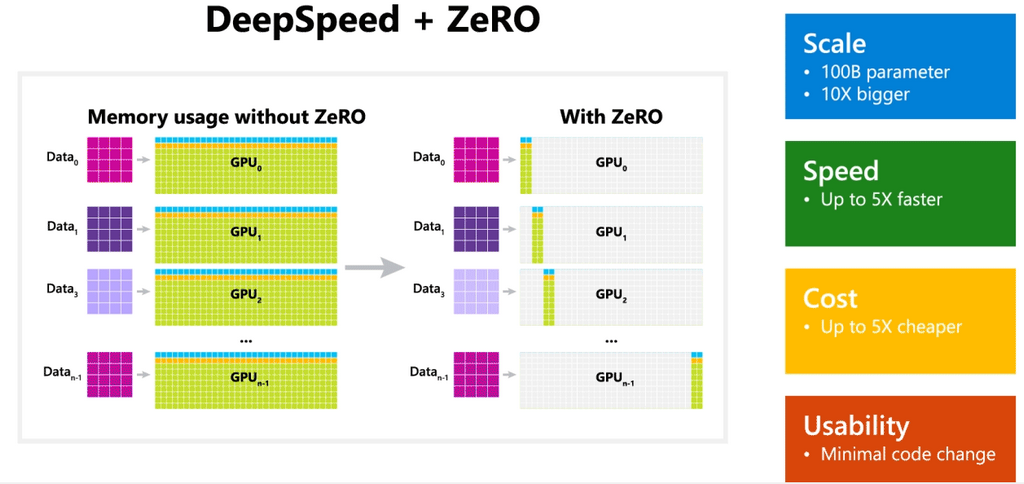
Разработка устраняет избыточность памяти в параллельных процессах данных путем разделения состояний модели — параметров, градиентов и состояния оптимизатора — между параллельными процессами данных вместо их репликации. Динамический график обмена данными во время обучения используется, чтобы разделить необходимое состояние между распределенными устройствами и сохранить вычислительную детализацию и объем передачи параллелизма данных. Параллелизм данных на основе ZeRO может соответствовать моделям произвольного размера — при условии, что совокупная память устройства достаточно велика для совместного использования состояний модели.
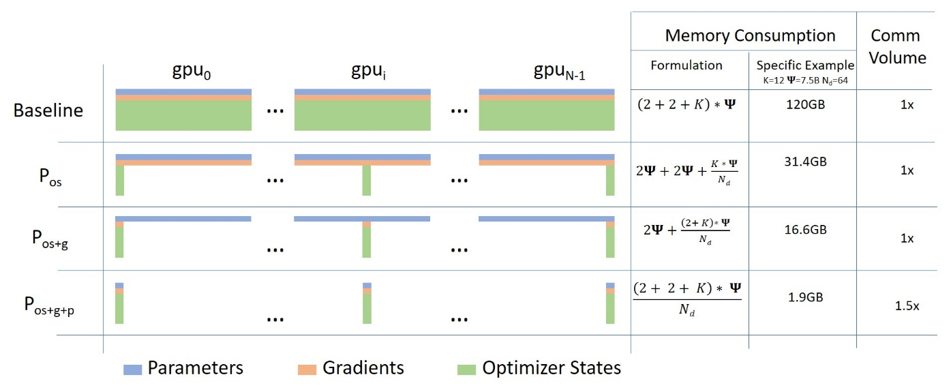
ZeRO может обучать модель с триллионами параметров всего на 1024 графических процессорах NVIDIA. Для модели с триллионами параметров и оптимизатором, таким как Adam с 16-битной точностью требуется приблизительно 16 терабайт (ТБ) памяти для хранения состояний оптимизатора, градиентов и параметров. 16 ТБ, разделенное на 1024, равно 16 ГБ, что находится в разумных пределах для графического процессора.
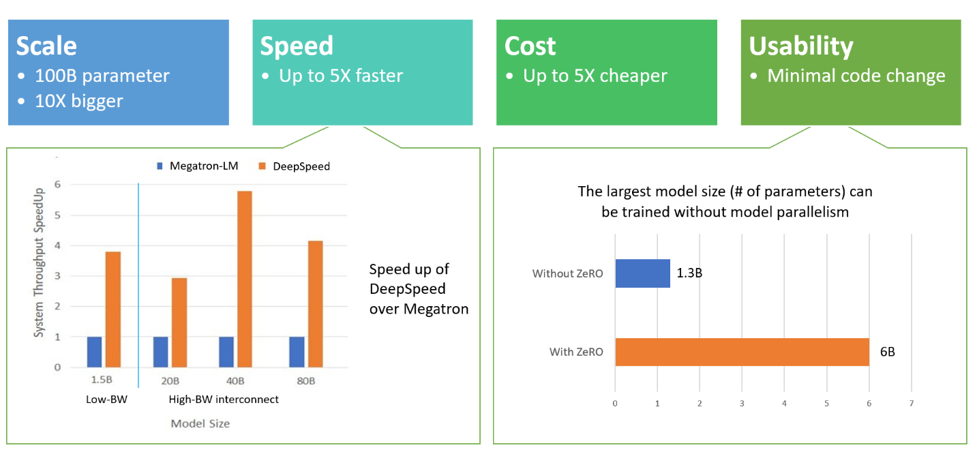
Компания утверждает, что с помощью всего лишь нескольких измененных строк кода в модели PyTorch можно использовать DeepSpeed для решения основных проблем с производительностью и повысить скорость и масштабность обучения. DeepSpeed не требует редизайна кода или рефакторинга модели, заверила разработка.
Кстати, ранее исследовательская фирма по искусственному интеллекту OpenAI объявила, что при реализации будущих проектов перейдет на платформу машинного обучения PyTorch от Facebook, отказавшись от платформы TensorFlow от Google. В компании отметили эффективность, масштабы и адаптивность PyTorch.
См. также: «Сравнение фреймворков для глубокого обучения: TensorFlow, PyTorch, Keras, MXNet, Microsoft Cognitive Toolkit, Caffe, etcСсылка на репозиторий уже опубликована на GitHub, а текст работы можно прочитать на arXiv.org.

