Привет Хабр!

Давным-давно, были компьютеры размером в несколько этажей, и несколько операторов работали с одни мощным ЭВМ. Затем это чудо техники смогли уменьшить до настольного размера и поставить его в каждый дом. Теперь опять, новшеством считаются «облачные вычисления», хм… всё ведь сводится к нескольким терминалам и одной мощной ЭВМ датацентру. Что ж, подождём, пока датацентр гугла уменьшат до размера ноутбука…
После 2000-го года в жизнь разработчиков и архитекторов, заказчиков и многих других, имеющих отношение к ИТ, вошёл термин-акроним SaaS (software as a service). Суть SaaS сводится к тому, что Исполнитель разрабатывает ПО, размещает его на серверах, поддерживает его работоспособность, безопасность, доступность для заказчиков (обычно во множественном числе) и естественно сам платит за сервера и иные расходы.
Клиент платит за использование сервисов и не думает о покупке серверов и их обслуживании. Такой подход дешевле для Клиента и окупается для Исполнителя (т.к. решает проблемы с лицензированием и пиратством, и самое главное один сервис может предоставляться нескольким клиентам). Однако Клиент должен доверять Исполнителю, т.к. все его данные располагаются далеко-далеко.
Естественно, что такое решение заставило искать компромиссы в области размещения и разделения данных.
Так как рассказывать что-либо без примера достаточно проблематично, рассмотрим абстрактную задачу.
Для Клиента удобство такой системы очевидно – сотрудники компании заходят в систему и видят все необходимые данные для более выгодной и удобной работы. Исполнитель же может не беспокоиться за несанкционированное использование разработанной системы, а самое главное, эту систему можно одновременно использовать для нескольких Клиентов, так как задача одна и та же, то и структура базы данных так же будет идентична. И вот тут дерево решений разветвляется, но об этом позже.
Итого: есть несколько заказчиков, которые пишут и читают в базу данных и ничего не знают друг о друге. Необходимо обеспечить их изоляцию друг от друга и эффективное использование аппаратуры и ПО.
Первое решение, которое приходит в голову, чтобы разделить данные разных заказчиков будем хранить их в разных базах данных (изолированный подход). Как альтернатива, можно хранить все данные в одной базе данных, введя дополнительное поле TenantID, по которому их различать (общий подход). Не смотря на всю двоичность логики, решений оказалось не два, а больше. Данный факт весьма убедительно представлен на картинке, позаимствованной из msdn'а:

Данное решение – первое, что приходит в голову, является простейшей реализацией разделения данных.
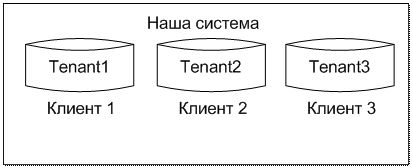
При таком подходе код разделяется между клиентами (используется общие файлы UI и бизнес логики), а данные логически (а возможно и физически) разделяются между собой.
В итоге, несмотря на высокую цену, это наиболее правильное решение для клиентов, главной целью которых является безопасность, и которые готовы заплатить (например, банки).
Итак, мы решили хранить всё в одной базе данных, как это сделать без введения дополнительного поля TenantID? Хранить информацию от разных клиентов в разных таблицах. Для реализации этого способа нам помогут схемы(schema). По сути, схемы это “пространства имён”, которые содержат определённые ресурсы (таблицы например), и на которые можно давать определённые разрешения.
Итог, если клиенты готовы жить по соседству, то вариант достаточно эффективный, т.к. позволит на одной машине поселить больше клиентов, чем в предыдущем варианте.
Самый третий вариант – хранить всё в одной базе данных и в общих таблицах. Для реализации такого варианта необходимым условием будет введение дополнительного поля TenantID (либо CustomerID как кому нравится) для разделения информации между заказчиками.
Итого, если клиентов у вас много, а серверов (денег) мало, и если у вас не полетят все винчестера в зеркале одновременно, то подход как раз для вас.
Так как первый вариант (разные базы данных) могут себе позволить не все, то наиболее целесообразным будет использовать вариант с общей базой данных. Но на этом пути нас ждёт несколько неожиданных внезапностей.

Итак, выберем самый дешёвый вариант как рабочий. Представим, что базы у нас не падают, а жёсткие диски вечны. И вот наша система целый год работает успешно и все довольны, накопились гигабайты данных, и внезапно всё начинает работать медленнее и медленнее. СУБД это не чёрный ящик, её тоже надо настраивать. Проблема банальна – данные пишутся в одну таблицу, в один файл, а значит, и на винчестер попадают друг за другом. А теперь представим, как происходит выборка данных для одного клиента: головка винчестера (да простят меня поклонники SSD винчестеров) медленно читает в буфер всё подряд, а записи с нужным TenantID могут появиться ещё не скоро. А теперь представьте, что нам надо перенести в архив данные одного клиента (удалив их в нашей базе).
Индексы скажете вы? – Дорого скажу я. Кроме того, даже при наличии индексов, данные всё равно будут лежать в разных частях диска.
Есть весьма элегантное решение, доступное в enterprise версиях СУБД называемое Partitioning (Секционирование), суть его можно посмотреть на рисунке:
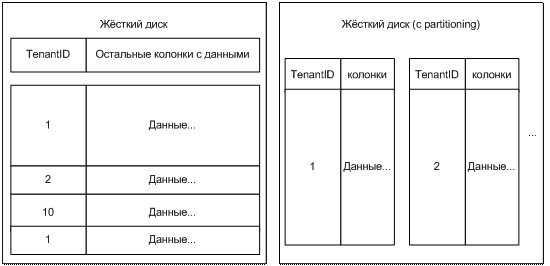
С partitoning, данные одного клиента располагаются последовательно, в отдельном от остальных месте. Для простоты можно считать, что данные каждого клиента лежат на отдельном логическом диске. Данная возможность поддерживается на уровне СУБД, так что писать драйверов и изобретать велосипедов не нужно.
Эта статья не является переводом, но естественно есть англоязычные источники, излагающие суть multi-tenant.
Некоторые ссылки по теме:
www.developer.com/design/article.php/3801931
msdn.microsoft.com/en-us/library/aa479069.aspx
msdn.microsoft.com/en-us/library/aa479086.aspx
Отдельное спасибо: Суркову Д.А. и DMinsky (это разные Дмитрии)
Пользуясьслужебным положениемслучаем, хочу всех поздравить с наступающей, самой последней, самой пятничной пятницей в этом году!
Давным-давно, были компьютеры размером в несколько этажей, и несколько операторов работали с одни мощным ЭВМ. Затем это чудо техники смогли уменьшить до настольного размера и поставить его в каждый дом. Теперь опять, новшеством считаются «облачные вычисления», хм… всё ведь сводится к нескольким терминалам и одной мощной ЭВМ датацентру. Что ж, подождём, пока датацентр гугла уменьшат до размера ноутбука…
Введение
После 2000-го года в жизнь разработчиков и архитекторов, заказчиков и многих других, имеющих отношение к ИТ, вошёл термин-акроним SaaS (software as a service). Суть SaaS сводится к тому, что Исполнитель разрабатывает ПО, размещает его на серверах, поддерживает его работоспособность, безопасность, доступность для заказчиков (обычно во множественном числе) и естественно сам платит за сервера и иные расходы.
Клиент платит за использование сервисов и не думает о покупке серверов и их обслуживании. Такой подход дешевле для Клиента и окупается для Исполнителя (т.к. решает проблемы с лицензированием и пиратством, и самое главное один сервис может предоставляться нескольким клиентам). Однако Клиент должен доверять Исполнителю, т.к. все его данные располагаются далеко-далеко.
Естественно, что такое решение заставило искать компромиссы в области размещения и разделения данных.
Так как рассказывать что-либо без примера достаточно проблематично, рассмотрим абстрактную задачу.
Задача
- Существует несколько крупных компаний, которым необходимо следить за новостями, чтобы иметь возможность конкурировать;
- Новости – информация, разбросанная по всему интернету;
- В качестве сервиса – система, которая определённым способом собирает нужную информацию на просторах интернета и сохраняет её в базу данных, чтобы затем показать клиенту;
- По истечении времени (полгода-год) данные будут переноситься в архив (удаляться из основной БД).
Для Клиента удобство такой системы очевидно – сотрудники компании заходят в систему и видят все необходимые данные для более выгодной и удобной работы. Исполнитель же может не беспокоиться за несанкционированное использование разработанной системы, а самое главное, эту систему можно одновременно использовать для нескольких Клиентов, так как задача одна и та же, то и структура базы данных так же будет идентична. И вот тут дерево решений разветвляется, но об этом позже.
Итого: есть несколько заказчиков, которые пишут и читают в базу данных и ничего не знают друг о друге. Необходимо обеспечить их изоляцию друг от друга и эффективное использование аппаратуры и ПО.
Решение: MULTI-TENANT
Первое решение, которое приходит в голову, чтобы разделить данные разных заказчиков будем хранить их в разных базах данных (изолированный подход). Как альтернатива, можно хранить все данные в одной базе данных, введя дополнительное поле TenantID, по которому их различать (общий подход). Не смотря на всю двоичность логики, решений оказалось не два, а больше. Данный факт весьма убедительно представлен на картинке, позаимствованной из msdn'а:
Разные Базы Данных
Данное решение – первое, что приходит в голову, является простейшей реализацией разделения данных.
При таком подходе код разделяется между клиентами (используется общие файлы UI и бизнес логики), а данные логически (а возможно и физически) разделяются между собой.
Преимущества:
- Простая расширяемость (чтобы добавить клиента достаточно создать новую базу данных и настроить конфигурационный файл);
- Простое масштабирование – можно разнести базы данных разных клиентов на отдельные сервера;
- Индивидуальность – можно производить индивидуальные настройки для некоторых клиентов (даже размещать базу на другом СУБД);
- Простое резервное копирование данных – если что-то сломалось у одного клиента, во время отката базы, других, это никак не заденет;
Недостатки:
- Дорого. Весьма дорого. Количество поддерживаемых баз данных одним сервером ограничено, а значит, для такого решения потребуется больше железа (в отличие от метода, где всё хранится в одной базе), больше железа – больше администраторов, площадь серверных и стоимость электроэнергии;
- Дорого. Опять дорого. Когда на одном сервере располагается несколько баз данных, суммарный объём которых больше оперативной памяти будет происходить скидывание данных в файл подкачки, а, следовательно, обращение к жёсткому диску, что очень медленно. Как выход из положения – купить больше серверов;
В итоге, несмотря на высокую цену, это наиболее правильное решение для клиентов, главной целью которых является безопасность, и которые готовы заплатить (например, банки).
Общая база данных, разные схемы
Итак, мы решили хранить всё в одной базе данных, как это сделать без введения дополнительного поля TenantID? Хранить информацию от разных клиентов в разных таблицах. Для реализации этого способа нам помогут схемы(schema). По сути, схемы это “пространства имён”, которые содержат определённые ресурсы (таблицы например), и на которые можно давать определённые разрешения.
Преимущества:
- Благодаря схемам, разделение доступа происходит на уровне СУБД и от нас не требуется дополнительной разработки (экономим человеко-часы);
- Меньше баз данных – меньше аппаратных ресурсов, опять сэкономили;
- Неплохая расширяемость – при добавлении клиента, создаём новую схему на основе стандартной, настраиваем доступ и готово. Не смотря на то что все схемы созданы на основе стандартной, они могут претерпевать некоторые изменения, т.к. изоляция сохраняется, а следовательно есть возможность редактировать колонки, таблицы и т.п.
Недостатки:
- И всё-таки данные хранятся вместе, разделяются они логически;
- Проблема с резервным копированием и восстановлением, ведь база данных одна, если слетели таблицы у одного клиента, простой откат базы вернёт в прошлое данные всех клиентов, а это неприемлемо. Тут потребуется выборочный откат и слияние старых и новых данных, процедура немного сложнее, чем просто откатить всю базу целиком (прочувствовал это на собственном опыте в один неудачный день, когда в raid зеркале умерло два винта почти одновременно. И на руках оказались бэкап и кусочки информации с умерших винтов …);
Итог, если клиенты готовы жить по соседству, то вариант достаточно эффективный, т.к. позволит на одной машине поселить больше клиентов, чем в предыдущем варианте.
Общая база данных, общая схема
Самый третий вариант – хранить всё в одной базе данных и в общих таблицах. Для реализации такого варианта необходимым условием будет введение дополнительного поля TenantID (либо CustomerID как кому нравится) для разделения информации между заказчиками.
Преимущества:
- Дёшево, в одном комплекте таблиц у нас будет храниться всё;
- Добавление клиента – просто создание новой записи в таблице клиентов;
Недостатки:
- Никакой гибкости, все клиенты используют один набор таблиц и колонок. Появление клиента-индивидуалиста – примета к костылям и заплаткам;
- Потраченные человеко-часы и нервы на разработку собственной системы разделения прав;
- С резервным копированием и восстановлением совсем беда, если в предыдущем подходе мы могли удалить таблицу целиком и восстановить её, то тут придётся выискивать в одной таблице нужные записи, и перезаписывать их, что обойдётся дороже в производительности;
Итого, если клиентов у вас много, а серверов (денег) мало, и если у вас не полетят все винчестера в зеркале одновременно, то подход как раз для вас.
Суровая реальность
Так как первый вариант (разные базы данных) могут себе позволить не все, то наиболее целесообразным будет использовать вариант с общей базой данных. Но на этом пути нас ждёт несколько неожиданных внезапностей.
Итак, выберем самый дешёвый вариант как рабочий. Представим, что базы у нас не падают, а жёсткие диски вечны. И вот наша система целый год работает успешно и все довольны, накопились гигабайты данных, и внезапно всё начинает работать медленнее и медленнее. СУБД это не чёрный ящик, её тоже надо настраивать. Проблема банальна – данные пишутся в одну таблицу, в один файл, а значит, и на винчестер попадают друг за другом. А теперь представим, как происходит выборка данных для одного клиента: головка винчестера (да простят меня поклонники SSD винчестеров) медленно читает в буфер всё подряд, а записи с нужным TenantID могут появиться ещё не скоро. А теперь представьте, что нам надо перенести в архив данные одного клиента (удалив их в нашей базе).
Индексы скажете вы? – Дорого скажу я. Кроме того, даже при наличии индексов, данные всё равно будут лежать в разных частях диска.
Есть весьма элегантное решение, доступное в enterprise версиях СУБД называемое Partitioning (Секционирование), суть его можно посмотреть на рисунке:
С partitoning, данные одного клиента располагаются последовательно, в отдельном от остальных месте. Для простоты можно считать, что данные каждого клиента лежат на отдельном логическом диске. Данная возможность поддерживается на уровне СУБД, так что писать драйверов и изобретать велосипедов не нужно.
Постскриптум
Эта статья не является переводом, но естественно есть англоязычные источники, излагающие суть multi-tenant.
Некоторые ссылки по теме:
www.developer.com/design/article.php/3801931
msdn.microsoft.com/en-us/library/aa479069.aspx
msdn.microsoft.com/en-us/library/aa479086.aspx
Отдельное спасибо: Суркову Д.А. и DMinsky (это разные Дмитрии)
После Постскриптума
Пользуясь

