Добрый день, уважаемые хабражители. Я давно хотел опубликовать под GPL-лицензией свой «Текстовый анализатор» ([1]). Наконец, дошли руки. «Текстовый анализатор» — это исследовательский проект, который я разрабатывал три года на 3, 4 и 5-м курсах университета. Главная цель была: создать алгоритм распознавания авторства текста, используя нейросети Хэмминга или Хопфилда. Идея была такова: эти нейросистемы распознают образы, а к задаче распознавания образов можно свести задачу выявления авторства. Для этого необходимо по каждому тексту собрать статистику, и чем больше разных критериев, тем лучше: частотный анализ букв, анализ длин слов/предложений/абзацев, частотный анализ двухбуквенных сочетаний, и так далее. Нейросистема могла бы выявить, характеристики каких текстов наиболее сходны. Работы было — вал. Много кода, хитрые алгоритмы, ООП, паттерны проектирования. Помимо основной задачи я так же реализовал ещё одно ноу-хау: «Карту благозвучия». По задумке, такая карта должна показывать все плохо и хорошо звучащие места, выделяя их цветом. Критерии оценки благозвучия должны задаваться каким-то универсальным образом, например, правилами. Для этой цели я даже разработал специальный графический язык, RRL (Resounding Rules Language). Работы было — вал. Много кода, хитрые алгоритмы, ООП, паттерны проектирования. В итоге получилась большая и сложная программа, правда, с неприглядным интерфейсом. С этим проектом я даже выиграл в конкурсе дипломных работ, получил 1 и 3 места на университетских конференциях, а так же 2 место на международной научно-практической.
Прошло более двух лет, и я с трудом вспоминаю, как оно работает. Давайте вместе попробуем разобраться, что там под
(У статьи есть продолжение и окончание.)
Структура статьи:
- Анализ авторства
- Знакомство с кодом
- Внутренности TAuthoringAnalyser и хранение текстов
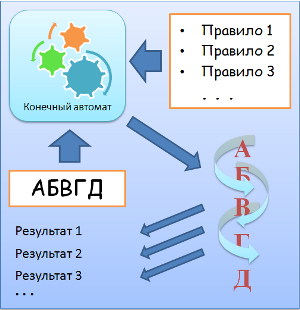
- Разбиение на уровни конечным автоматом на стратегиях
- Сбор частотных характеристик
- Нейросеть Хэмминга и анализ авторства
Дополнительные материалы:
- Исходники проекта «Текстовый анализатор» (Borland C++ Builder 6.0)
- Тестирование нейросистемы Хэмминга в Excel'е ([xls])
- Таблица переходов для КА, разбивающего текст на уровни ([xls])
- Расчет благозвучия отдельных букв ([xls])
- Презентация дипломного проекта «Текстовый анализатор» ([ppt])
- Презентация проекта «Карта благозвучия» ([ppt])
- Все эти материалы в сжатом виде ([zip], [7z], [rar])
1. Анализ авторства
Нужно:
- загрузить тексты-образцы и «ключевой» текст (авторство которго неизвестно);
- определить сравнимые образцы текстов:
- разбить тексты на слова, предложения, абзацы,
- составить одинаковые по длине блоки из слов, предложений, абзацев для каждого текста,
- выбрать только сравнимые блоки одинаковых размеров для уровней «слова», «предложения», «абзацы»;
- собрать статистику по этим трем уровням;
- загрузить данные в нейросистему Хэмминга;
- провести распознавание образа с её помощью;
- выявить на всех трех уровнях тексты-образцы, которые наиболее близки к ключевому тексту по характеристикам. Вероятно, авторам этих текстов и принадлежит ключевой текст.
Вот какие можно сделать выводы из плана:
- Будет работа с большими объемами данных, вплоть до мегабайтов — в зависимости от текстов.
- Тексты могут быть совсем разных размеров: от рассказов до многотомных романов. Следовательно, нужно как-то обеспечить базовую сравнимость разных произведений.
- Пункт 2 нужен для повышения точности распознавания, для дифференцирования процесса по уровням и для обеспечения базовой сравнимости текстов.
- Разбор текста по словам, предложениям и абзацам — это задача для конечного автомата.
- Статистик разных может быть много, хотелось бы, чтобы они собирались универсальным образом, чтобы всегда можно было добавить ещё какие-нибудь алгоритмы сбора.
- Нейросистема Хэмминга работает только с определенной информацией, а значит, нужно преобразовывать собранные данные к виду, который она понимает.
2. Знакомство с кодом
Для «разогрева» рассмотрим сначала класс главной формы — TAuthoringAnalyserTable ([cpp], [h]). (Если «разогрев» не нужен, можно сразу перейти к следующему разделу.) Сама форма ужасна, юзабилити, можно сказать, на нуле. Но нас интересует код, а не кнопочки-формочки.
В начале cpp-файла видим инстанцированние классов:
Copy Source | Copy HTML
- TVCLControllersFasade VCLFasade; // 1 - фасад по работе с VCL
- TAnalyserControllersFasade AnalyserFasade; // 2 - фасад алгоритмов анализа
- TVCLViewsContainer ViewsContainer; // 3 - контейнер визуальных компонентов

Здесь для (1) и (2) применен паттерн «Фасад» (Facade, [1], [2], [3], [4]). Внутри класса-фасада (1) скрыт большой интерфейс для работы с визуальными компонентами VCL. Именно там прописаны реакции на нажатие кнопок «Загрузить текст», на обновление списка текстов, и вообще на любое событие от формы. Форма обращается к этим функциям, не зная, что произойдет. Фасад скрывает от формы всё лишнее. Но, на самом деле, VCLFasade ([cpp], [h]) только связывает события от форм и алгоритмы; в нем нет этих алгоритмов, а лежат они где-то дальше в другом фасаде — (2), AnalyserFasade ([cpp], [h]). Класс (1) всего лишь перенаправляет вызовы объекту (2) и делает дополнительную работу вроде заполнения визуального компонента «Список». Да, такая вот монструозная конструкция: объект (1) знает об объекте (2) и его функциях. Откуда он знает? В конструкторе главной формы, чуть ниже, есть параметризация первого фасада вторым:
Copy Source | Copy HTML
- // .......
- VCLFasade.SetAnalyserControllersFasade(&AnalyserFasade); // Параметризация одного объекта другим.
- // .......
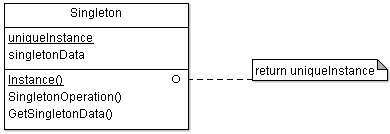
Сейчас я уже не уверен, что класс (1) — это «Фасад», возможно, это что-то другое, или вообще просто так. Хорошо было бы поместить фасады в паттерн «Одиночка» (Singleton, [1], [2], [3], [4]). К сожалению, два года назад я до этого не додумался. Не то чтобы программа пострадала, нет, всё работает, как и должно работать. Но мы теряем некоторые возможности, связанные с паттерном «Одиночка». Ведь мы не можем создавать несколько точек входа в одну подсистему? Не можем. Стоило бы это запретить.
Что ещё есть интересного в конструкторе главной формы?
Copy Source | Copy HTML
- // .......
- VCLFasade.SetViewsContainer(&ViewsContainer); // В фасад (1) передаются контейнер представлений
- VCLFasade.SetAuthoringAnalyserTable(this); // и указатель на главную форму.
-
- /* Прим.: Можно сделать вывод, что где-то есть циклические включения h-файлов и, <br/>возможно, предопределения. Конечно, это плохо, но вот так вот сложилось тогда. */
-
- // Параметризация фасада (2) репортинговой системой:
- AnalyserFasade.SetAuthoringAnalysisReporter(&AnalysisReporter);
- AnalyserFasade.SetResoundingAnalysisReporter(&AnalysisReporter);
- // .......
-
А дальше — большая простыня по заполнению контейнера визуальных компонентов (контролов). С формы берется элемент (например, кнопка) и заносится в контейнер, причем — в свою группу:
Copy Source | Copy HTML
- // .......
- TVCLViewsContainer * vc = &ViewsContainer; // Для сокращения имени.
-
- vc->AddViewsGroup(cCurrentTextInfo); // Создаём группу компонентов, cCurrentTextInfo - текстовое имя группы.
- vc->AddView(cCurrentTextInfo, LCurrentTextNumber); // LCurrentTextNumber, LCurrentTextAuthor,
- vc->AddView(cCurrentTextInfo, LCurrentTextAuthor); // LCurrentTextTitle и т. д. - это указатели на визуальные компоненты.
- vc->AddView(cCurrentTextInfo, LCurrentTextTitle); // Например: TLabel *LCurrentTextNumber;
- vc->AddView(cCurrentTextInfo, CLBTextsListBox);
- vc->AddView(cCurrentTextInfo, MSelectedTextPreview);
- vc->AddViewsGroup(cKeyTextInfo); // Создаём ещё одну группу.
- vc->AddView(cKeyTextInfo, LKeyTextNumber);
- vc->AddView(cKeyTextInfo, LKeyTextAuthor);
- vc->AddView(cKeyTextInfo, LKeyTextTitle);
- vc->AddView(cKeyTextInfo, CLBTextsListBox);
- // ...и так далее...
-
Довольно любопытный подход, хотя и не очень понятный. Контролы передаются в контейнер (3), который в свою очередь, передается фасаду (1). Там, очевидно, контролы каким-то образом используются. После рассмотрения классов TVCLViewsContainer ([cpp], [h]) и TVCLView ([h]), становится ясно, что всё, что делается с контролами — это Update, Show/Hide, Enable/Disable, причем группами. Целиком можно обновить одну группу, скрыть другую, зная только имя… Для чего это было нужно, сейчас могу только догадываться. Этот подход нарушает инкапсуляцию, поскольку с контролами можно сделать что угодно, вплоть до удаления. Они выносятся за скобки своей формы, чем рискуют быть измененными.
В классе главной формы больше ничего интересного нет, поэтому посмотрим поближе на класс (2) ([cpp], [h]). Этот второй фасад уже настоящий, без шуток, разве что название записано через S, а не C («Facade» — правильное написание слова, как оно дано везде, в том числе и в GOF ([1], [2], [3])). Класс упрощает работу с подсистемами анализа, скрывая реальные классы за интерфейсами. А реальных классов там три:
Copy Source | Copy HTML
- class TAnalyserControllersFasade
- {
- TTextsController _TextsController;
- TAuthoringAnalyser _AuthoringAnalyser;
- TResoundingMapAnalyser _ResoundingAnalyser;
- // .......
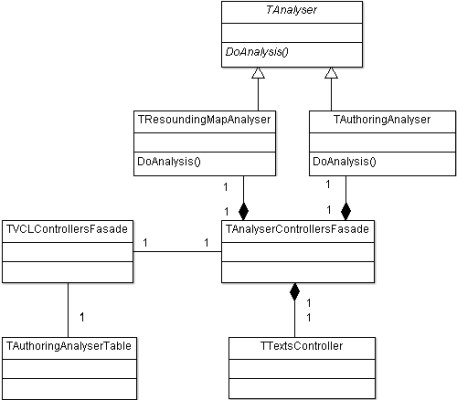
Простые функции класса TAnalyserControllersFasade обращаются к более сложным функциям трех реальных классов, но клиент ничего об этой сложности не знает. Это упрощает разработку и использование. Загружаем тексты (функции LoadAsPrototype(), LoadAsKeyText()), загружаем настройки анализаторов (LoadResoundingAnalysisRules()), запускаем анализ (функция DoAnalysis()), и оно каким-то магическим образом где-то там работает. Если приглядимся к функции DoAnalysis(), то увидим, что нужный анализ вызывается по текстовому имени. Это — хорошо. Плохо то, что в паре с фасадом это не очень расширяемое решение. Если бы я захотел провести еще какой-то анализ, например, проверку грамматики, мне нужно было бы добавить четвертый реальный класс — GrammarAnalyser, — и прописать в фасаде несколько дополнительных функций. А если я пишу суперуниверсальный инструмент для анализа текста, и у меня таких анализаторов — тьма-тьмущая? Тогда бы пришлось придумывать унифицированные интерфейсы, поднимать абстракцию над анализаторами, делать изменяемые в run-time алгоритмы… Получилось бы очень… очень. К счастью, я страдаю чуть меньшей манией гигантизма, да и не требовалось на тот момент.
3. Внутренности TAuthoringAnalyser и хранение текстов
Заглянем в класс TAuthoringAnalyser ([cpp], [h]) — реальный класс, делающий реальный анализ авторства. Уже в самом начале h-файла бросаются в глаза монструозные typedef's:
Copy Source | Copy HTML
- class TAuthoringAnalyser : public TAnalyser
- {
- public:
-
- typedef map<TTextString, ParSentWordFSM::TCFCustomUnitDivisionTreeItem, less<TTextString> > TTextsParSentWordTrees;
- typedef map<TUInt, TRangeMapsEqualifer::TEqualifiedMapsContainer, less<TUInt> > TLeveledEqualifiedMaps;
- typedef map<TUInt, TFrequencyTablesContainer, less<TUInt> > TLeveledFrequencyContainers;
- typedef map<TUInt, TTextString, less<TUInt> > TIndexToAliasAssociator;
- typedef map<TUInt, TIndexToAliasAssociator, less<TUInt> > TLeveledIndexToAliasAssociators;
-
- // <Небезопасный код> // Прим.: чем этот код небезопасен, вспомнить вряд ли удастся...
- typedef map<TUInt, TResultVector, less<TUInt> > TLeveledResultVectors;
- // </Небезопасный код>
- // .......
-
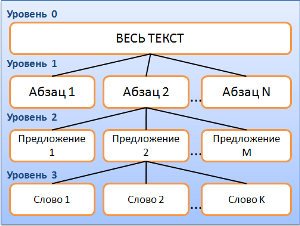
Эти типы нужны, чтобы хранить все промежуточные данные, вычисления, результаты. Так, TTextsParSentWordTrees содержит, очевидно, структурные деревья текстов: «Весь текст -> абзацы -> предложения -> слова»; TLeveledFrequencyContainers содержит распределенные по уровням частотные характеристики текстов, ну и так далее. Еще можно заметить, что переопределены все встроенные типы ([h]). TUInt == unsigned int, TTextString == AnsiString. Трудно представить, когда бы это могло пригодиться. Переопределенные типы, конечно, можно изменить за мгновение ока, не внося правок в файлы проекта, но как часто возникают подобные ситуации? Когда вдруг оказывается, что 32-битного целого не хватает? Когда внезапно AnsiString перестал нас удовлетворять, и мы захотели std::string? Слишком гипотетическая ситуация, и случается прежде всего с плохо спроектированной программой. Как бы то ни было, типы переопределены, не очень мешают, не очень помогают, — и к этому придётся привыкнуть.
Чуть ниже в защищенной секции нашего анализатора-фасада объявляются объекты этих и других типов:
Copy Source | Copy HTML
- // .......
- private:
- TTextsConfigurator *_AllTextsConfigurator;
- TTextsConfigurator _AnalysedTextsConfigurator;
- TTextsParSentWordTrees _Trees;
- TLeveledEqualifiedMaps _LeveledEqualifiedMaps;
- TLeveledFrequencyContainers _FrequencyContainers;
- TLeveledIndexToAliasAssociators _IndexToAliasAssociators;
- // .......
У класса TTextsConfigurator сложная структура. В его задачи входит загрузка, хранение и предоставление текстов — без их глубокого копирования. Хороша же была бы программа, если бы тексты, передаваясь в параметрах, полностью копировались. Тогда бы не хватило никакой памяти, никакого процессорного времени. Поэтому TTextsConfigurator предоставляет доступ через указатели. Считается, что будучи однажды загруженным, текст становится всегда доступен. «Конфигуратор текстов» так же хранит дополнительную информацию: является ли текст образцом или он — ключевой; активирован текст или нет (в программе можно исключать тексты из анализов), кто автор, какое название, и т.д. Как это реализовано, можно посмотреть в классах TTextsConfigurator ([cpp], [h]), TTextConfiguration ([cpp], [h]) TLogicalTextItem && TMPLogicalTextItem ([h]), TRawDataItem && TMPRawDataItem ([cpp], [h]) и TTextDataProvider ([cpp], [h]). Именно в таком порядке объекты этих классов вкладываются друг в друга, и мы получаем своеобразную матрёшку. Идея была в том, чтобы разделить логическое и физическое представление текста, а так же предоставить возможность загружать «сырые данные» из разных источников, ничего не зная ни об источниках, ни о формате, в котором хранится текст. Поэтому загрузчик «сырых данных» можно сменить. Помимо всего прочего, там используется паттерн «Умный указатель» (классы TMPRawDataItem и TMPLogicalTextItem) в его ипостаси «Master Pointer» ([1], [2]). Так же присутствует иерархия классов, позволяющая абстрагироваться от физического представления текстов. Всё это мне почти не пригодилось; возможно, я сделал лишнюю работу, зато приобрёл массу опыта и положительных эмоций.


