Эта статья об алгоритме распознавания авторства, реализованном в проекте «Текстовый анализатор». В окончании статьи мы рассмотрим, как собираются частотные характеристики, и в общих чертах познакомимся с нейросистемой Хэмминга. (Начало и продолжение).
Структура статьи:
Дополнительные материалы:

Наиболее полезны для распознавания авторства частотные характеристики отдельных символов, двух-, трёхбуквенных сочетаний, частотные таблицы слов и т.д. В этой программе реализовано только самое простое: подсчет частот символов. Конечно, для комплексного анализа этого недостаточно. Сейчас точность распознавания, надо признать, не очень высокая. Насколько помню, в тестах вероятность правильного ответа достигала 60-70 процентов, и то — в идеальных условиях. Разрабатывая программу, я надеялся когда-нибудь её переписать, добавив комплексный анализ авторства на основе многих методов. Кто знает, может, ещё и возьмусь…
Итак, сбор частотных характеристик символов. Класс TCharFrequencyCalculator ([h]) составляет частотную таблицу, выполняя один проход по тексту. Шаблонный класс TFrequencyTable ([h]) может хранить частотную таблицу для объектов любого типа.
// Использование:
TCharFrequencyCalculator calculator;
TFrequencyTable charFrequencyTable = calculator(text);

Стоит обратить внимание на то, что функций, подсчитывающих частоты, аж две. Первая принимает TTextStringWrapper ([cpp], [h]) — класс-обёртку над текстовой строкой. «Обёртка» ещё известна как паттерн Адаптер (Adapter, Wrapper, [1], [2], [3]). Он преобразует интерфейс одного класса в интерфейс другого. Можно было сделать по-настоящему универсальный калькулятор, но пришлось бы абстрагироваться от объектов, частоты которых мы подсчитываем. Калькулятора вообще не должно волновать, в каких списках, таблицах или массивах там хранятся данные, откуда берутся, сколько элементов, и в каком они порядке. Адаптированные под нужный калькулятору интерфейс, списки объектов обрабатывались бы единообразно… У вас не возникло ощущения дежа-вю? Правильно, мы это уже обсуждали, когда рассматривали менеджер конечного автомата. Там мы абстрагировались от списков событий с помощью паттерна «Итератор», а здесь — от списков элементов с помощью «Адаптер». Это его нетипичное применение, оно хуже, чем итераторы: нам бы пришлось наплодить иерархии адаптеров и частотных таблиц, чтобы их можно было оперативно заменять. В конце концов, адаптер перестал бы быть собой, а превратился в некий абстрактный контейнер. Примерно так бы это выглядело:
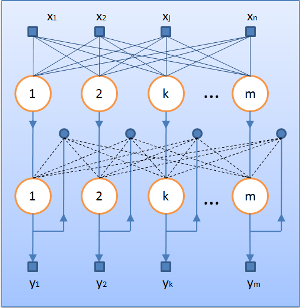
Наконец, мы с вами, уставшие и побитые, добрались до самого последнего шага. Нейросеть Хэмминга ([1], [2]) берёт за основу набор бинарных векторов одинаковой длины. Они называются образцами и хранятся в матрице образцов. На вход нейросети подаётся тестируемый вектор той же длины. Количество входов равно размеру вектора; для данных большого объёма входов может быть очень много. Одно из преимуществ ИНС Хэмминга (перед ИНС Хопфилда) в том, что какой бы ни была размерность входного вектора, структура нейросети не поменяется. Слоёв — два, причём первый фиктивный; выходов и нейронов в каждом слое ровно столько, сколько образцов в матрице. Нейросеть работает быстро. Её задача — найти в матрице образцов вектор, который больше всего «похож» на входной. Похожесть определяется так называемым расстоянием Хэмминга. Чем меньше это расстояние, тем более «похожи» два вектора. Условно говоря, расстояние Хэмминга показывает, сколько битов в этих векторах не совпадает. Посчитать расстояние Хэмминга несложно, да и вся нейросеть — это лишь удобное представление нескольких простых формул. Вычислив какие-то значения, нейросеть сходится к результату: на выходах будет получен вектор со всеми нуликами, — исключая какой-нибудь один выход, где появится единица. Индекс этого выхода указывает на искомый образец в матрице образцов.
Чтобы загрузить в нейросеть (класс THamNeuroSystem: [cpp], [h]) образцы текстов, их нужно преобразовать к бинарному виду. Это делает шаблонный класс-коннектор (THamNSConnector: [h]). Забавно видеть код нейросети и коннектора: я понимаю, что это можно сделать гораздо, гораздо проще.
На этом всё. Если не считать моих попыток улучшить нейросеть, больше рассказывать не о чем. Нейросеть возвращает индекс образца того текста, характеристики которого она считает более сходными с характеристиками текста неизвестного автора. Насколько правдив ответ, вы можете выяснить сами, скомпилировав программу. Меня на обширные тесты не хватило ни тогда, при написании диплома, ни сейчас. Надеюсь, статья была полезна.
С уважением.
Структура статьи:
- Анализ авторства
- Знакомство с кодом
- Внутренности TAuthoringAnalyser и хранение текстов
- Разбиение на уровни конечным автоматом на стратегиях
- Сбор частотных характеристик
- Нейросеть Хэмминга и анализ авторства
Дополнительные материалы:
- Исходники проекта «Текстовый анализатор» (Borland C++ Builder 6.0)
- Тестирование нейросистемы Хэмминга в Excel'е ([xls])
- Таблица переходов для КА, разбивающего текст на уровни ([xls])
- Расчет благозвучия отдельных букв ([xls])
- Презентация дипломного проекта «Текстовый анализатор» ([ppt])
- Презентация проекта «Карта благозвучия» ([ppt])
- Все эти материалы в сжатом виде ([zip], [7z], [rar])
5. Сбор частотных характеристик
Наиболее полезны для распознавания авторства частотные характеристики отдельных символов, двух-, трёхбуквенных сочетаний, частотные таблицы слов и т.д. В этой программе реализовано только самое простое: подсчет частот символов. Конечно, для комплексного анализа этого недостаточно. Сейчас точность распознавания, надо признать, не очень высокая. Насколько помню, в тестах вероятность правильного ответа достигала 60-70 процентов, и то — в идеальных условиях. Разрабатывая программу, я надеялся когда-нибудь её переписать, добавив комплексный анализ авторства на основе многих методов. Кто знает, может, ещё и возьмусь…
Итак, сбор частотных характеристик символов. Класс TCharFrequencyCalculator ([h]) составляет частотную таблицу, выполняя один проход по тексту. Шаблонный класс TFrequencyTable ([h]) может хранить частотную таблицу для объектов любого типа.
Copy Source | Copy HTML
- class TCharFrequencyCalculator
- {
- private:
-
- TFrequencyTable<TChar> _FTable;
-
- public:
-
- TFrequencyTable<TChar> & operator ()(TTextStringWrapper & tWrapper)
- {
- _FTable << ftm_Clear;
-
- TUInt i;
- TTextStringWrapper d; // Эта переменная, видимо, просто мусор в коде...
- for (i=tWrapper.Begin(); i<=tWrapper.End(); i++)
- _FTable << (tWrapper[i]);
- return _FTable;
- };
-
- TFrequencyTable<TChar> & operator ()(const TTextString & tTextString)
- {
- _FTable << ftm_Clear;
-
- for (TSInt i=1; i<=tTextString.Length(); i++)
- _FTable << tTextString[i];
- return _FTable;
- };
-
- TCharFrequencyCalculator(){};
- };
// Использование:
TCharFrequencyCalculator calculator;
TFrequencyTable charFrequencyTable = calculator(text);
Стоит обратить внимание на то, что функций, подсчитывающих частоты, аж две. Первая принимает TTextStringWrapper ([cpp], [h]) — класс-обёртку над текстовой строкой. «Обёртка» ещё известна как паттерн Адаптер (Adapter, Wrapper, [1], [2], [3]). Он преобразует интерфейс одного класса в интерфейс другого. Можно было сделать по-настоящему универсальный калькулятор, но пришлось бы абстрагироваться от объектов, частоты которых мы подсчитываем. Калькулятора вообще не должно волновать, в каких списках, таблицах или массивах там хранятся данные, откуда берутся, сколько элементов, и в каком они порядке. Адаптированные под нужный калькулятору интерфейс, списки объектов обрабатывались бы единообразно… У вас не возникло ощущения дежа-вю? Правильно, мы это уже обсуждали, когда рассматривали менеджер конечного автомата. Там мы абстрагировались от списков событий с помощью паттерна «Итератор», а здесь — от списков элементов с помощью «Адаптер». Это его нетипичное применение, оно хуже, чем итераторы: нам бы пришлось наплодить иерархии адаптеров и частотных таблиц, чтобы их можно было оперативно заменять. В конце концов, адаптер перестал бы быть собой, а превратился в некий абстрактный контейнер. Примерно так бы это выглядело:
Copy Source | Copy HTML
- class TFrequencyCalculator
- {
- TFrequencyTable * operator ()(TWrapper * tWrapper, TFrequencyTable *table)
- {
- table << ftm_Clear;
-
- for (int i=tWrapper->Begin(); i<=tWrapper->End(); ++i)
- table << (tWrapper->at(i));
- return table;
- };
- }
-
- class TWordWrapper : public TWrapper
- {
- // ......
- virtual int Begin() const;
- virtual int End() const;
- virtual Word at(const int &index) const;
- // ......
- };
-
- class TSentenceWrapper : public TWrapper {/*......*/};
- class TWordsFrequencyTable : public TFrequencyTable {/*......*/};
- class TSentenceFrequencyTable : public TFrequencyTable {/*......*/};
-
- // Использование:
- TWordWrapper wordWrapper = TWordWrapper(wordsList)
- TFrequencyCalculator wordCalc;
- TWordsFrequencyTable wordFrequencyTable = wordCalc(&wordWrapper, &wordFrequencyTable);
-
- TSentenceWrapper sentenceWrapper = TSentenceWrapper(sentencesMap)
- TFrequencyCalculator sentenceCalc;
- TSentenceFrequencyTable sentenceFrequencyTable = sentenceCalc(&sentenceWrapper, &sentenceFrequencyTable);
-
6. Нейросеть Хэмминга и анализ авторства
Наконец, мы с вами, уставшие и побитые, добрались до самого последнего шага. Нейросеть Хэмминга ([1], [2]) берёт за основу набор бинарных векторов одинаковой длины. Они называются образцами и хранятся в матрице образцов. На вход нейросети подаётся тестируемый вектор той же длины. Количество входов равно размеру вектора; для данных большого объёма входов может быть очень много. Одно из преимуществ ИНС Хэмминга (перед ИНС Хопфилда) в том, что какой бы ни была размерность входного вектора, структура нейросети не поменяется. Слоёв — два, причём первый фиктивный; выходов и нейронов в каждом слое ровно столько, сколько образцов в матрице. Нейросеть работает быстро. Её задача — найти в матрице образцов вектор, который больше всего «похож» на входной. Похожесть определяется так называемым расстоянием Хэмминга. Чем меньше это расстояние, тем более «похожи» два вектора. Условно говоря, расстояние Хэмминга показывает, сколько битов в этих векторах не совпадает. Посчитать расстояние Хэмминга несложно, да и вся нейросеть — это лишь удобное представление нескольких простых формул. Вычислив какие-то значения, нейросеть сходится к результату: на выходах будет получен вектор со всеми нуликами, — исключая какой-нибудь один выход, где появится единица. Индекс этого выхода указывает на искомый образец в матрице образцов.
Чтобы загрузить в нейросеть (класс THamNeuroSystem: [cpp], [h]) образцы текстов, их нужно преобразовать к бинарному виду. Это делает шаблонный класс-коннектор (THamNSConnector: [h]). Забавно видеть код нейросети и коннектора: я понимаю, что это можно сделать гораздо, гораздо проще.
Copy Source | Copy HTML
- template <class T> void THamNSConnector<T>::ByteToBinaryVector(T DataItem, TSInt SizeOfData, TSampleVector *DestinationVector)
- {
- vector <bool> BoolBits;
- T NewDataItem = DataItem;
-
- for (TSInt i=1; i<SizeOfData; i++)
- {
- BoolBits.clear();
-
- BoolBits.push_back( NewDataItem & bitOne );
- BoolBits.push_back( NewDataItem & bitTwo );
- BoolBits.push_back( NewDataItem & bitThree );
- BoolBits.push_back( NewDataItem & bitFour );
- BoolBits.push_back( NewDataItem & bitFive );
- BoolBits.push_back( NewDataItem & bitSix );
- BoolBits.push_back( NewDataItem & bitSeven );
- BoolBits.push_back( NewDataItem & bitEight );
-
- for (TUInt j= 0; j<BoolBits.size(); j++)
- {
- if (BoolBits[j]) DestinationVector->push_back(1);
- else DestinationVector->push_back( 0);
- }
-
- NewDataItem = NewDataItem >> 8;
- };
- };
-
- template <class T> TSampleVector THamNSConnector<T>::VectorToBinaryVector(TVector SourceVector)
- {
- TSInt SizeOfData;
- T DataItem;
- TUInt i;
- TSampleVector ResVector;
-
- SizeOfData = sizeof(T);
-
- for (i= 0; i<SourceVector.size(); i++)
- {
- DataItem = SourceVector[i];
- ByteToBinaryVector(DataItem, SizeOfData, &ResVector);
- };
-
- return ResVector;
- };
-
На этом всё. Если не считать моих попыток улучшить нейросеть, больше рассказывать не о чем. Нейросеть возвращает индекс образца того текста, характеристики которого она считает более сходными с характеристиками текста неизвестного автора. Насколько правдив ответ, вы можете выяснить сами, скомпилировав программу. Меня на обширные тесты не хватило ни тогда, при написании диплома, ни сейчас. Надеюсь, статья была полезна.
С уважением.

