 На просторах рунета можно найти достаточно много статей с введением в Verilog HDL. Все они описывают синтаксис и семантику языка, но, к сожалению, не раскрывают основных парадигм, используемых при проектировании цифровых схем. Представьте себе, что вам объясняют синтаксис языка Java, но не рассказывают ничего про объектно-ориентированное проектирование. Если вы знакомы с ООП, то такого введения будет достаточно, но если вы знаете только Си, то писать скорей всего будете “по-старому”, создавая огромные классы со сложными методами.
На просторах рунета можно найти достаточно много статей с введением в Verilog HDL. Все они описывают синтаксис и семантику языка, но, к сожалению, не раскрывают основных парадигм, используемых при проектировании цифровых схем. Представьте себе, что вам объясняют синтаксис языка Java, но не рассказывают ничего про объектно-ориентированное проектирование. Если вы знакомы с ООП, то такого введения будет достаточно, но если вы знаете только Си, то писать скорей всего будете “по-старому”, создавая огромные классы со сложными методами.Примерно так происходит с программистами, изучающими цифровую схемотехнику и языки описания аппаратуры. Быстро разобравшись с несложным синтаксисом языка, они начинают описывать конструкции, безумные с точки зрения хардверного инженера. Среди моих студентов встречались люди, написавшие “сортировку пузырьком” за такт, сумасшедшие асинхронные схемы, которые работали по-разному при каждом запуске и разной погоде за окном, огромные комбинационные делители, уводившие place&route в глубокую многочасовую задумчивость.
Для тех, у которых нет времени прочитать учебник для начинающих, но есть желание или
необходимость спроектировать несколько простых схем я решил написать это небольшое введение об основной современной парадигме проектирования цифровых схем – синхронных схемах. И об одном из языков, используемых для их описания.
Статья рассчитана на новичков. Для понимания текста потребуется минимальный набор знаний – понимание работы синхронного D-триггера и вентилей.
Синхронные схемы
Синхронные цифровые схемы состоят из комбинационных вентилей(gates), цепей (nets) и триггеров (flip-flops). В синхронной схеме есть единственный сигнал синхронизации, который управляет всеми элементами памяти (триггерами).
Формально, синхронную схему можно определить следующим образом:
Синхронная схема — это цифровая схема C состоящая из вентилей, триггеров и цепей распространения сигналов, которая удовлетворяет следующим условиям:
- В схеме существует единственная цепь clk, по которой распространяется сигнал синхронизации (тактовый сигнал, clock signal)
- Сигнал clk управляется входным портом схемы.
- Множество портов, управляемых сигналом clk, эквивалентно множеству входов синхронизации триггеров
- Определим схему C’ следующим образом: Схема C’ получается из схемы C путем: (1) удаления цепи clk, (2) удаления входного порта, управляющего сигналом clk, (3) заменой всех триггеров на выходной порт (вместо входа D) и входной порт (вместо выхода Q). Полученная схема C’ должна быть комбинационной
Пример синхронной схемы показан на рисунке:
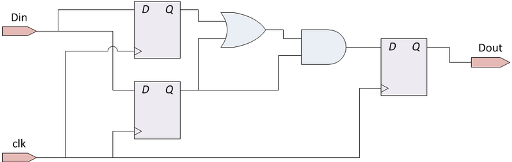
А вот несколько примеров схем, не являющихся синхронными:
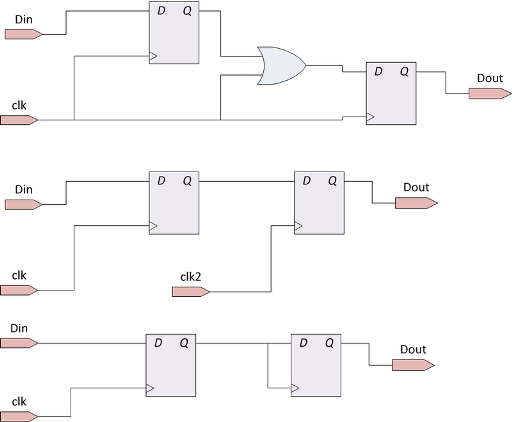
Практически все существующие цифровые схемы являются синхронными, либо состоят из нескольких синхронных схем, взаимодействующих через асинхронные каналы. Причина популярности синхронных схем — в простоте анализа времени распространения сигналов. Временной анализ (англ. Timing analysis) — тема для отдельной статьи, но кратко коснуться этого вопроса все-таки надо.
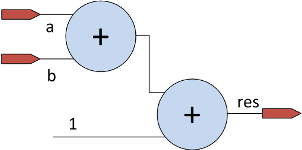
Рассмотрим следующую схему, реализующую функцию R = A+B+1:
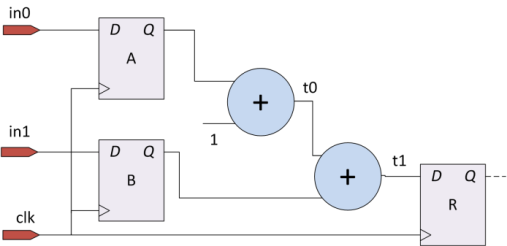
Регистры A, B и R сохраняют значения на входах D по переднему фронту сигнала синхронизации (clk), т.е. в тот момент времени, когда значение clk изменяется из 0 в 1.
Сигналы распространяются через сумматоры (и другие комбинационные элементы) не мгновенно, а с задержкой, зависящей от длины самого большого пути из вентилей (критического пути), т.е. от сложности элемента. К примеру, критический путь в сумматоре будет проходить через сигналы переноса в старший разряд (представьте себе вычисление суммы “столбиком”).
Предположим, что сначала во всех регистрах был записан 0. А на входы in0, in1 сначала подаются значения 1 и 4, а потом 2 и 1. Тогда временная диаграмма для нашей схемы может выглядеть следующим образом:
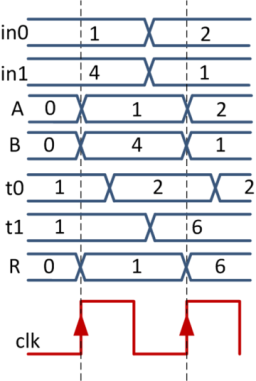
По первому фронту clk значения 1 и 4 будут записаны в регистры A и B. После того как сигнал распространится через сумматоры, значение результата 1 + 4 + 1 = 6 появится на проводе t1. Затем, по второму фронту clk результат будет записан в регистр R, а новые входные значения в регистры A и B.
Теперь представим, что период сигнала clk уменьшился в два раза. Тогда второй фронт сигнала clk появится на регистре R до того, как на t1 появятся правильные данные. Т.е. схема будет работать неверно!
Отсюда следует основное правило корректности работы синхронной схемы:
Задержка через критический путь в схеме должна быть меньше периода сигнала синхронизации.
Под критическим путем понимается самый длинный путь в схеме, от выхода до входа регистра. Из этого правила выводится следствие, которое характеризует один из самых больших недостатков синхронных схем:
Синхронная схема работает на частоте, определяемой критическим путем в схеме.
Представьте, что в схеме тысячи комбинационных путей с задержкой в 1 наносекунду. И один путь с задержкой в 2 наносекунды. Из-за этого единственного пути схема должна тактироватся на частоте в 500 МГц, хотя могла бы работать на гигагерце. Поэтому, при проектировании синхронных схем длинные комбинационные цепочки разбивают регистрами на конвейерные стадии. К примеру, в процессоре AMD Bulldozer средняя длина комбинационного пути – 12-14 FO4 эквивалентных вентилей (задержка, эквивалентная инвертору единичного размера, нагруженному 4-мя инверторами).
Несмотря на этот недостаток, синхронные схемы стали очень популярны. Синхронные схемы без труда поддаются автоматическому временному анализу, т.е. частота, на которой схема может корректно работать, определяется программой (временным анализатором) автоматически. Когда разработчик может отстраниться от этих деталей, синхронную схему можно специфицировать набором пересылок между регистрами. Такой подход к описанию схем – Register Transfer Logic (RTL) стал мэйнстримом в описании логики работы цифровых схем. К примеру, схему из нашего примера можно описать следующими пересылками:
A = in0
B = in1
R = A+B+1
На каждом такте в регистр А записывается in0, в регистр B записывается in1, а в регистр R значение A + B + 1. Идея описывать схемы на RTL в виде текста лежит в основе языков описания аппаратуры: Verilog HLD и VHDL. Пришло время познакомиться с одним из них поближе.
Описание синхронных схем на Verilog HDL
Модули
Программа на Verilog, она же описание схемы, состоит из модулей (module), точнее из экземпляров модулей (module instances). Модуль можно представить как “черный ящик” с торчащими из него проводами — портами (ports). Порты бывают трех типов: входные (input), выходные (output) и двунаправленные (inout). В большинстве случаев используются первые два типа портов. Двунаправленные порты нужны для моделирования двунаправленных шин, на базе выходов с тремя состояниями и открытым стоком. Их мы рассматривать не будем.
Список портов описывается в заголовке модуля. К примеру, рассмотрим этот пустой модуль:
module blackbox // module - ключевое слово, blackbox - имя модуля
(
input a, b, c // входные порты a,b,c
input [7:0] bus, // входной порт bus - 8-разрядная шина
output [7:0] bus_out // выходной порт bus_out, также 8-разрядный
);
// Здесь добавляется тело модуля
endmodule // endmodule - конец описания модуля, ключевое слово
В теле модуля описывается его функциональность. Этот модуль пустой, его порты никуда не подключены. Перед тем как перейти к описанию функциональности модулей, познакомимся с основными типами данных в Verilog.
Типы данных
В Verilog существуют два класса типов: типы для моделирования аппаратуры и стандартные арифметические типы данных, скопированные из языка Си. Мы будем рассматривать только первый из классов, т.к. именно он используется для моделирования сигналов в схеме.
В Verilog сигнал может принимать 4 значения:
- 0 – логический ноль, или ложь
- 1 – логическая единица, или истина
- x – неопределенное значение. К примеру, значение регистра в начальный момент симуляции (до сброса или первой записи в регистр)
- z – состояние с высоким импедансом. Чаще всего сигнал принимает это значение, если он никуда не подключен – “обрыв провода”
В большинстве модулей на Verilog используются 2 основных типа данных – wire и reg. Из названия может показаться, что wire моделирует провод, а reg – регистр, но, как будет показано далее, это не совсем так. Наличие двух типов это скорее баг в дизайне языка, в SystemVerilog – современной версии Verilog, есть универсальный тип logic, который может использоваться во всех случаях.
Рассмотрим каждый из типов по отдельности.
Wires
Тип wire служит для моделирования сигналов, которые не могут “хранить” состояние. К примеру, значение на выходе комбинационной схемы полностью определяется значениями на входах. Если значения на входе меняются, меняется и значение на выходе, т.е. состояние не хранится. Тип wire используется вместе с операцией непрерывного присваивания — assign. При непрерывном присваивании, всякий раз когда меняется значение переменных в правой части присваивания, обновляется значение переменной в левой части. К примеру, простую комбинационную схему можно описать следующим образом:
module comb
(
input wire [7:0] a,b,
output [7:0] res // тип wire устанавливается по-умолчанию, но можно написать output wire [7:0] res
);
assign res = a+b+1;
endmodule
Сигналы можно объявлять и внутри тела модуля:
module comb
(
input wire [7:0] a,b,
output [7:0] res
);
wire [3:0] x,y;
assign x = a[3:0] + b[3:0]; // складываются 4 младших разряда на шинах а и b
assign y = a[7:4] + b[7:4]; // складываются 4 старших разряда на шинах а и b
assign res = x+y;
endmodule 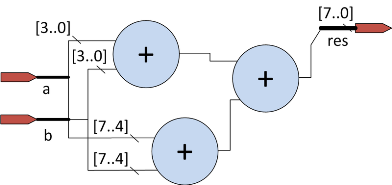
Regs
Тип reg может хранить значение и используется в процедурных блоках. Процедурный блок в Verilog – процедура, срабатывающая по определенному событию. К примеру, этим событием может быть фронт тактового сигнала или начало симуляции. В процедурных блоках могут использоваться Си-подобные управляющие конструкции:
- if… else..
- for
- do… while..
- case (аналог switch)
Процедурные блоки могут моделировать как синхронные схемы (схемы с памятью), так и комбинационные схемы. К примеру, рассмотрим описание схемы двоичного счетчика:
module counter
(
input clk, reset,
output [7:0] data
);
reg [7:0] counter;
assign data = counter;
always @(posedge clk) // процедурный блок срабатывает по положительному фронту clk
begin
if (reset)
counter = 0;
else
counter = counter + 1;
end
endmodule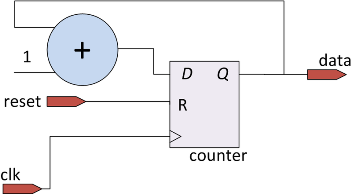
Строка always @(posedge clk) называется списком чувствительности. Она определяет события, по которым выполняется процедурный блок. Данный блок выполняется по каждому положительному фронту (positive edge) сигнала синхронизации. Таким образом, блок моделирует логику работы счетчика, сигнал counter будет просинтезирован как регистр.
Процедурные блоки могут моделировать и комбинационные схемы. К примеру, следующий код просинтезируется в комбинационный сумматор:
wire [7:0] a,b;
reg [7:0] res;
always @*
begin
res = a+b;
end
Здесь список чувствительности always @* означает, что процедурный блок выполняется каждый раз, когда изменяются значения сигналов в правой части операций присваивания. В данном случае процедурный блок срабатывает каждый раз, когда изменяются сигналы a и b. Эквивалентном этой строчке, будет следующий список чувствительности:
always @(a or b) // блок срабатывает каждый раз, когда меняется a или b
При описании комбинационной схемы с помощью процедурного блока always необходимо помнить, что значения всех изменяемых в блоке сигналов, должны полностью определятся сигналами в списке чувствительности. В противном случае синтезатору придется вставить в схему элементы памяти — защелки (latches).
К примеру, рассмотрим следующий процедурный блок:
wire a,b;
reg res;
always @*
begin
if(a & b) res = 1;
else if (!a & b) res = 0;
end
В процедурном блоке не описано, что будет в случае если b = 0. Если b = 0 значение res не должно меняться, не зависимо от значения a. Поэтому будет просинтезирована следующая схема:
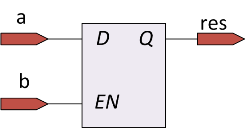
Как правило, появление защелок в схеме означает ошибку в коде.
Неблокирующие присваивания
Все присваивания, которые мы использовали в примерах с процедурными блоками, в Verilog называются «блокирующими» присваиваниями. Они работают привычным программисту образом.
Помимо блокирующих присваиваний, в Verilog есть еще один тип присваивания, используемый в процедурных блоках — неблокирующее присваивание, обозначаемое оператором "<=". Неблокирующее присваивание выполняется не сразу, в том месте где объявлено, а откладывается до выхода из процедурного блока. Рассмотрим пример:
reg a,b;
always @(posedge clk)
begin
a <= b;
b <= a;
end
В этом примере на каждом такте сигналы a и b будут обмениватся значениями. Синтезированная схема будет выглядеть следующим образом:

Неблокирующие присваивания обычно используют при описании логики работы регистров. Блокирующие присваивания чаще используются для описания комбинационных схем.
Заключение
На этом небольшое введение в Verilog заканчивается. Надеюсь, кому-то оно было полезно.
Тем кто хочет познакомиться с Verilog и проектированием цифровых схем немного глубже, могу порекомендовать эти две книжки для начинающих:

