Недавно я публиковал здесь свой слайдкаст с рассказом о 6-сигмах, контрольных картах Шухарта и людях снежинках, где достаточно простым языком, местами злоупотребляя сквернословием, под 20-ти минутный хохот слушателей рассказывал о том, как отделить системные вариации от вариаций, вызванных особыми причинами.
Теперь хочу подробно разобрать пример построения контрольной карты Шухарта на основе реальных данных. В качестве реальных данных я взял историческую информацию о завершенных личных задачах. Эта информация у меня есть благодаря адаптации под себя модели личной эффективности Дэвида Аллена Getting Things (про это у меня тоже есть старый слайдкаст в трех частях: Часть 1, Часть 2, Часть 3 + Excel-табличка с макросами для анализа задач из Outlook ).
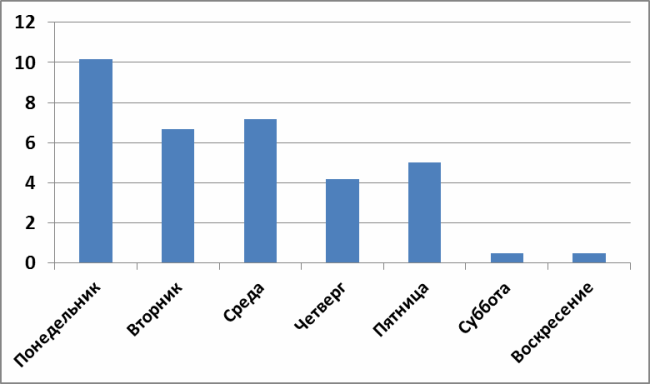
Постановка задачи выглядит так. У меня имеется распределение среднего числа завершенных задач в зависимости от дня недели (ниже на графике) и нужно ответить на вопрос: «есть ли что-то особенное в понедельниках или это всего лишь погрешность системы?»
Ответим на этот вопрос при помощи контрольной карты Шухарта – основного инструмента статистического управления процессами.
Итак, критерий Шухарта наличия особой причины вариации достаточно прост: если какая-то точка выходит за контрольные пределы, рассчитанные особым образом, то она свидетельствует об особой причине. Если точка лежит внутри этих пределов, то отклонение обусловлено общими свойствами самой системы. Грубо говоря, является погрешностью измерений.
Формула для вычисления контрольных пределов выглядит так:
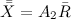
Где
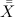 — среднее значение средних значений по подгруппе,
— среднее значение средних значений по подгруппе,
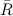 — средний размах,
— средний размах,
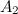 — некоторый инженерный коэффициент, зависящий от размера подгруппы.
— некоторый инженерный коэффициент, зависящий от размера подгруппы.
Все формулы и табличные коэффициенты можно найти, например, в ГОСТ 50779.42-99, где кратко и понятно изложен подход к статистическому управлению (честно, сам не ожидал, что есть такой ГОСТ. Более подробно тема статистического управления и его места в оптимизации бизнеса раскрыта в книге Д. Уилера).
В нашем случае мы группируем количество выполненных задач по дням недели – это и будет подгруппами нашей выборки. Я взял данные о числе завершенных задач за 5 недель работы, то есть, размер подгруппы равен 5. При помощи таблицы 2 из ГОСТа находим значение инженерного коэффициента:
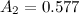
Вычисление среднего значения и размаха (разницы между минимальным и максимальным значениями) по подгруппе (в нашем случае по дню недели) задача достаточно простая, в моем случае результаты такие:
Центральной линией контрольной карты будет являться среднее групповых средних, то есть:

Так же вычисляем средний размах:
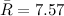
Теперь мы знаем, что нижний контрольный предел для числа выполненных задач будет равен:
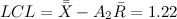
То есть, те дни, в которые я в среднем завершаю меньшее число задач, с точки зрения системы являются особенными.
Аналогично получаем верхний контрольный предел:

Теперь нанесем на график центральную линию (красная), верхний контрольный предел (зеленая) и нижний контрольный предел (фиолетовая):
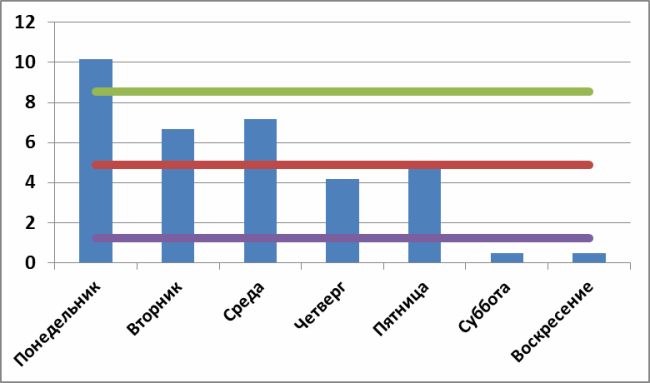
И, о, чудо! Мы видим три явно особенные группы, выходящие за контрольные пределы, в которых присутствуют явно не системные причины вариаций!
По субботам и воскресеньям я не работаю. Факт. А понедельник оказался действительно особенным днем. И теперь можно думать и искать что же такого реально особенного в понедельниках.
Однако если бы среднее число выполненных в понедельник задач находилось внутри контрольных пределов и пусть даже сильно выделялось на фоне остальных точек, то с точки зрения Шухарта и Деминга искать какие-то особенности в понедельниках было бы бессмысленным занятием, так как подобное поведение обуславливается исключительно общими причинами. Например, я построил контрольную карту для других 5-ти недель в конце прошлого года:
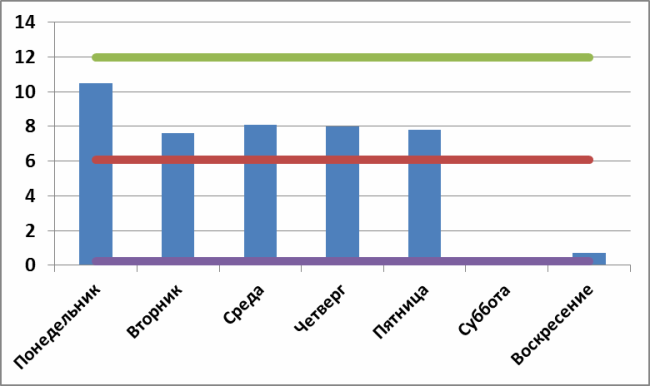
И вроде как есть какое-то ощущение того, что понедельник как-то выделяется, но согласно критерию Шухарта — это всего-лишь флуктуация или погрешность самой системы. Согласно Шухарту, в данном случае можно сколь угодно долго исследовать особые причины понедельников — их просто нет. С точки зрения статистического управления, на этих данных понедельник ничем не отличается от любого другого рабочего дня (даже воскресенья).
Теперь хочу подробно разобрать пример построения контрольной карты Шухарта на основе реальных данных. В качестве реальных данных я взял историческую информацию о завершенных личных задачах. Эта информация у меня есть благодаря адаптации под себя модели личной эффективности Дэвида Аллена Getting Things (про это у меня тоже есть старый слайдкаст в трех частях: Часть 1, Часть 2, Часть 3 + Excel-табличка с макросами для анализа задач из Outlook ).
Постановка задачи выглядит так. У меня имеется распределение среднего числа завершенных задач в зависимости от дня недели (ниже на графике) и нужно ответить на вопрос: «есть ли что-то особенное в понедельниках или это всего лишь погрешность системы?»
Ответим на этот вопрос при помощи контрольной карты Шухарта – основного инструмента статистического управления процессами.
Итак, критерий Шухарта наличия особой причины вариации достаточно прост: если какая-то точка выходит за контрольные пределы, рассчитанные особым образом, то она свидетельствует об особой причине. Если точка лежит внутри этих пределов, то отклонение обусловлено общими свойствами самой системы. Грубо говоря, является погрешностью измерений.
Формула для вычисления контрольных пределов выглядит так:
Где
— среднее значение средних значений по подгруппе, — средний размах, — некоторый инженерный коэффициент, зависящий от размера подгруппы.Все формулы и табличные коэффициенты можно найти, например, в ГОСТ 50779.42-99, где кратко и понятно изложен подход к статистическому управлению (честно, сам не ожидал, что есть такой ГОСТ. Более подробно тема статистического управления и его места в оптимизации бизнеса раскрыта в книге Д. Уилера).
В нашем случае мы группируем количество выполненных задач по дням недели – это и будет подгруппами нашей выборки. Я взял данные о числе завершенных задач за 5 недель работы, то есть, размер подгруппы равен 5. При помощи таблицы 2 из ГОСТа находим значение инженерного коэффициента:
Вычисление среднего значения и размаха (разницы между минимальным и максимальным значениями) по подгруппе (в нашем случае по дню недели) задача достаточно простая, в моем случае результаты такие:
| День недели | Групповое среднее | Размах |
|---|---|---|
| Понедельник | 10.2 | 8 |
| Вторник | 6.7 | 10 |
| Среда | 7.2 | 11 |
| Четверг | 4.2 | 9 |
| Пятница | 5.0 | 10 |
| Суббота | 0.5 | 2 |
| Воскресенье | 0.5 | 3 |
Центральной линией контрольной карты будет являться среднее групповых средних, то есть:
Так же вычисляем средний размах:
Теперь мы знаем, что нижний контрольный предел для числа выполненных задач будет равен:
То есть, те дни, в которые я в среднем завершаю меньшее число задач, с точки зрения системы являются особенными.
Аналогично получаем верхний контрольный предел:
Теперь нанесем на график центральную линию (красная), верхний контрольный предел (зеленая) и нижний контрольный предел (фиолетовая):
И, о, чудо! Мы видим три явно особенные группы, выходящие за контрольные пределы, в которых присутствуют явно не системные причины вариаций!
По субботам и воскресеньям я не работаю. Факт. А понедельник оказался действительно особенным днем. И теперь можно думать и искать что же такого реально особенного в понедельниках.
Однако если бы среднее число выполненных в понедельник задач находилось внутри контрольных пределов и пусть даже сильно выделялось на фоне остальных точек, то с точки зрения Шухарта и Деминга искать какие-то особенности в понедельниках было бы бессмысленным занятием, так как подобное поведение обуславливается исключительно общими причинами. Например, я построил контрольную карту для других 5-ти недель в конце прошлого года:
И вроде как есть какое-то ощущение того, что понедельник как-то выделяется, но согласно критерию Шухарта — это всего-лишь флуктуация или погрешность самой системы. Согласно Шухарту, в данном случае можно сколь угодно долго исследовать особые причины понедельников — их просто нет. С точки зрения статистического управления, на этих данных понедельник ничем не отличается от любого другого рабочего дня (даже воскресенья).

