Все мы помним хрестоматийное объяснение «что такое индексы в БД и как они облегчают задачи поиска нужных строк». Уверен, у большинства из вас перед глазами встаёт нечто подобное:
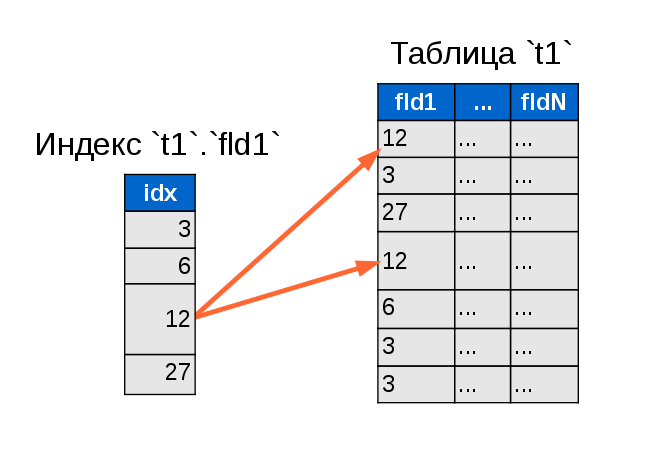
И сразу становится очевидно, насколько меньше данных нужно перелопатить для поиска двух-трёх нужных строк. Гениально. Просто. Понятно.
И лично мне всегда казалось, что улучшать эту схему некуда… Пока я не познакомился с кластерными индексами. Оказалось, что всё не так уж радужно с «обычными» индексами.
Итак, что же такое кластерный индекс, чем он лучше некластерного, и как с ним обстоит дело у MySQL.
Чтобы не запутаться, до поры до времени будем рассматривать простой индекс по одному полю. Упрощённо некластерный индекс можно представить как отдельную таблицу, каждая строка в которой ссылается на одну или несколько строк в таблице с данными. Строки в индексной таблице упорядочены и сгруппированы по значениям ключевых полей. Представим элементарный запрос:
Совсем без индексации будет прочитана и проверена каждая строка, и неудовлетворяющие условию строки просто не попадут в результат. Но прочитаны они будут.
При использовании «обычного», некластерного индекса, задача поиска сильно ускоряется. Во-первых, индексная таблица весит много меньше таблицы с данными, а значит элементарно может быть прочитана быстрее. Во-вторых, СУБД чаще всего стараются кешировать индексы в оперативную память, которая сама по себе много шустрее жёсткого диска*. В-третьих, в индексах отсутствуют дублирующиеся строки. А значит, как только мы нашли первое значение, поиск можно прекращать — оно же и последнее. В-четвёртых, данные в индексе отсортированы. А в-третьих и в-четвёртых вместе позволяют использовать алгоритм бинарного поиска (он же метод деления пополам), эффективность которого многократно превосходит простой перебор.
* Если ресурсы позволяют, таблицу данных тоже можно (и нужно) кешировать в оперативную память. Однако индексам и месту для них в оперативной памяти, по понятным причинам, принято уделять больше внимания.
Индексация — великая сила. Но если представить все указатели индексной таблицы на строки в таблице данных ОДНОВРЕМЕННО, получится достаточно сложная «паутина»:
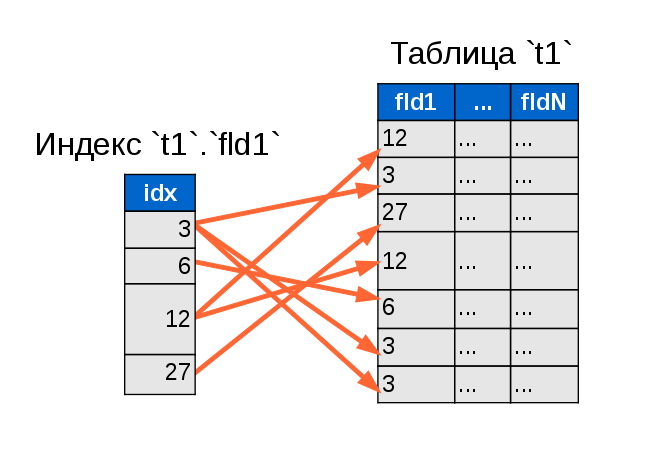
И эта паутина, со множеством пересекающихся стрелок, подводит нас к проблеме (просто таки наглядно её демонстрирует), которую создаёт некластерный индекс.
Оптимизатор MySQL может принять решение вообще не использовать индексы для поиска по небольшим таблицам (до пары десятков записей — зависит от конкретной структуры данных и индекса). Почему? Потому что поиск простым перебором читает данные последовательно. А указатель в индексе ссылается на разрозненные участки данных. И прыжки по ссылкам из индекса в конечном итоге могут стоить дороже полного перебора.
Итак, что мы имеем на данном этапе эволюции индексирования. Представьте большую, фрагментированную с точки зрения индексации, таблицу. Как данные приходили хаотичными и неотсортированными, так они и сохранялись. Теперь представьте индексную таблицу к ней. И наш старый добрый запрос:
Что происходит? Находится значение в индексе — это быстро и просто — и из таблицы данных читаются строки, на которые этот индекс ссылается. Естественно, при большой фрагментированности таблицы накладные расходы на чтение из разных её частей становятся ощутимыми.
И вот тут-то нам и пригодятся…
Кластерные индексы отличаются от некластерных точно так же, как оглавление книги отличается от алфавитного указателя. Алфавитный указатель (некластерный индекс) для точного слова (значения) даёт точные номера страниц (строки в БД). Оглавление же указывает диапазон страниц, соответствующих определённой главе, в которой уже найдётся искомое слово. Причём каждая глава, если она достаточно велика, может содержать собственное оглавление.
Кластерный индекс — это древовидная структура данных, при которой значения индекса хранятся вместе с данными, им соответствующими. И индексы, и данные при такой организации упорядочены. При добавлении новой строки в таблицу, она дописывается не в конец файла*, не в конец плоского списка, а в нужную ветку древовидной структуры, соответствующую ей по сортировке.
* В разных движках и при разных настройках это может быть вовсе и не конец, и вовсе и не файла. Слово файл здесь означает «некую единицу измерения данных, соответствующую одной таблице», а «конец файла» употребляется как символ последовательной, линейной записи.
Один из самых мощных и производительных движков для MySQL — InnoDB. Тому много причин, и одна из них — кластерные индексы. Проще всего понять как устроены кластерные индексы, если представить их в динамике: как они разрастаются по мере добавления данных, и как начинает ветвиться таблица.
Данные в InnoDB хранятся страницами по 16 Кб. Размер одной страницы — это предельный размер узла нашей древовидной структуры, от которого зависит в какой момент начнётся ветвление. Если вся таблица помещается в одну страницу, то она хранится в виде плоского списка, отсортированного по ключевому полю, без отдельной индексной таблицы.
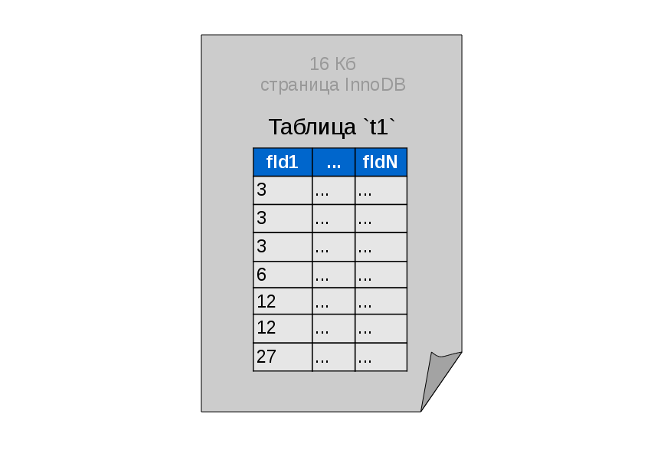
Точно такими же маленькими табличками в будущем будут представлены все наши данные, а соединять их в дерево будут цепочки индексных страниц.
Когда данные перестают помещаться в одну страницу, список превращается в дерево. Страница с данными разделяется на две, причём в том узле (на той странице), где раньше были данные, теперь располагается индекс, охватывающий обе новые страницы. Конкретный узел такого дерева обязан включать в себя индексы всех дочерних узлов или конечные данные, если узел последний. Узлы могут ссылаться друг на друга только в одном направлении: от родителя к потомку.
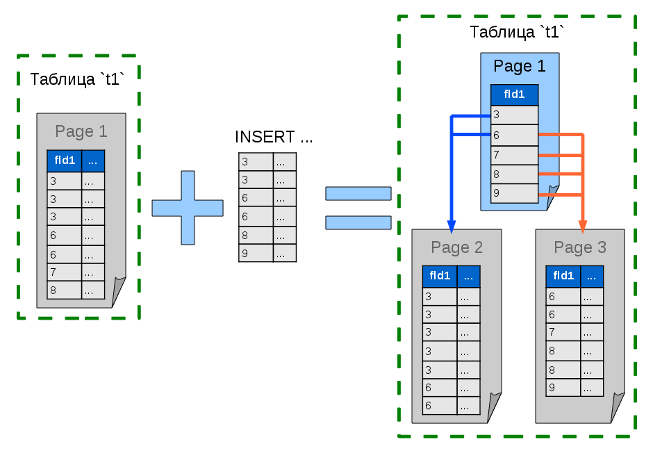
По мере добавления всё новых и новых данных, дерево будет усложняться и углубляться. И чем больше оно будет и ветвистее, тем больший выйгрышь даст такая схема хранения данны.

Серые страницы идентичны странице первого этапа — это просто отсортированные данные, листья (конечные узлы) нашего дерева. Голубые страницы — это промежуточные узлы дерева, содержащие только индекс и не содержащие данных. Стрелками помечены пути поиска определённых значений ключа.
Вспомним наш запрос (зелёная стрелка):
Обращаясь к таблице, запрос попадает на первую страницу и получает индекс, тут же отправляющий его на конечную страницу с данными, где находятся строки, удовлетворяющие критериям поиска. Страница уже прочитана на этапе поиска, все данные собраны, БД может вернуть ответ.
Однако индекс, указывающий на другую страницу, не обязательно ведёт сразу на страницу с данными. Индекс может указывать на страницу с промежуточным индексом. Возможно, при больших объёмах таблицы, БД придётся провести больше итераций поиска, но каждая такая итерация включает минимальный объём данных, а потому в целом всё равно поиск проходит быстрее.
Здесь действует простое правило, актуальное для любого типа индекса: чем разнообразнее данные, тем эффективнее использовать индекс для поиска конкретных значений.
Поскольку данные являются частью индекса, отсортированы и целенаправленно фрагментированы, очевидно что для одной таблицы может использоваться только один кластерный ключ. Из такой, достаточно сложной логики хранения индексов и данных, есть ещё одно важное следствие: операции записи, а особенно изменение имеющихся данных ключевых полей — крайне ресурсоёмкий процесс. Старайтесь использовать для кластерных индексов редко изменяемые поля.
Что касается сложных (составных) кластерных ключей, для них действует абсолютно такая же схема, только сортировка данных осуществляется по двум полям. Сам же индекс мало отличается от некластерного составного ключа.
Здесь всё просто. Каждая таблица InnoDB имеет кластерный ключ. Каждая. Без исключения.
Гораздо интереснее, какие поля для этого выбираются.
До третьего пункта лучше не доводить свой многострадальный сервер, и добавить таки ID самостоятельно.
И не забывайте, что InnoDB во вторичных ключах хранит полный набор значений полей кластерного ключа в качестве ссылки на конечную строку в таблице. Чем больше первичный ключ, тем больше вторичные ключи.
И сразу становится очевидно, насколько меньше данных нужно перелопатить для поиска двух-трёх нужных строк. Гениально. Просто. Понятно.
И лично мне всегда казалось, что улучшать эту схему некуда… Пока я не познакомился с кластерными индексами. Оказалось, что всё не так уж радужно с «обычными» индексами.
Итак, что же такое кластерный индекс, чем он лучше некластерного, и как с ним обстоит дело у MySQL.
Некластерные индексы
Чтобы не запутаться, до поры до времени будем рассматривать простой индекс по одному полю. Упрощённо некластерный индекс можно представить как отдельную таблицу, каждая строка в которой ссылается на одну или несколько строк в таблице с данными. Строки в индексной таблице упорядочены и сгруппированы по значениям ключевых полей. Представим элементарный запрос:
SELECT * FROM `t1` WHERE `fld1` = 12;
Совсем без индексации будет прочитана и проверена каждая строка, и неудовлетворяющие условию строки просто не попадут в результат. Но прочитаны они будут.
При использовании «обычного», некластерного индекса, задача поиска сильно ускоряется. Во-первых, индексная таблица весит много меньше таблицы с данными, а значит элементарно может быть прочитана быстрее. Во-вторых, СУБД чаще всего стараются кешировать индексы в оперативную память, которая сама по себе много шустрее жёсткого диска*. В-третьих, в индексах отсутствуют дублирующиеся строки. А значит, как только мы нашли первое значение, поиск можно прекращать — оно же и последнее. В-четвёртых, данные в индексе отсортированы. А в-третьих и в-четвёртых вместе позволяют использовать алгоритм бинарного поиска (он же метод деления пополам), эффективность которого многократно превосходит простой перебор.
* Если ресурсы позволяют, таблицу данных тоже можно (и нужно) кешировать в оперативную память. Однако индексам и месту для них в оперативной памяти, по понятным причинам, принято уделять больше внимания.
Индексация — великая сила. Но если представить все указатели индексной таблицы на строки в таблице данных ОДНОВРЕМЕННО, получится достаточно сложная «паутина»:
И эта паутина, со множеством пересекающихся стрелок, подводит нас к проблеме (просто таки наглядно её демонстрирует), которую создаёт некластерный индекс.
Фрагментация
Оптимизатор MySQL может принять решение вообще не использовать индексы для поиска по небольшим таблицам (до пары десятков записей — зависит от конкретной структуры данных и индекса). Почему? Потому что поиск простым перебором читает данные последовательно. А указатель в индексе ссылается на разрозненные участки данных. И прыжки по ссылкам из индекса в конечном итоге могут стоить дороже полного перебора.
Итак, что мы имеем на данном этапе эволюции индексирования. Представьте большую, фрагментированную с точки зрения индексации, таблицу. Как данные приходили хаотичными и неотсортированными, так они и сохранялись. Теперь представьте индексную таблицу к ней. И наш старый добрый запрос:
SELECT * FROM `t1` WHERE `fld1` = 12;
Что происходит? Находится значение в индексе — это быстро и просто — и из таблицы данных читаются строки, на которые этот индекс ссылается. Естественно, при большой фрагментированности таблицы накладные расходы на чтение из разных её частей становятся ощутимыми.
И вот тут-то нам и пригодятся…
Кластерные индексы
Кластерные индексы отличаются от некластерных точно так же, как оглавление книги отличается от алфавитного указателя. Алфавитный указатель (некластерный индекс) для точного слова (значения) даёт точные номера страниц (строки в БД). Оглавление же указывает диапазон страниц, соответствующих определённой главе, в которой уже найдётся искомое слово. Причём каждая глава, если она достаточно велика, может содержать собственное оглавление.
Кластерный индекс — это древовидная структура данных, при которой значения индекса хранятся вместе с данными, им соответствующими. И индексы, и данные при такой организации упорядочены. При добавлении новой строки в таблицу, она дописывается не в конец файла*, не в конец плоского списка, а в нужную ветку древовидной структуры, соответствующую ей по сортировке.
* В разных движках и при разных настройках это может быть вовсе и не конец, и вовсе и не файла. Слово файл здесь означает «некую единицу измерения данных, соответствующую одной таблице», а «конец файла» употребляется как символ последовательной, линейной записи.
Один из самых мощных и производительных движков для MySQL — InnoDB. Тому много причин, и одна из них — кластерные индексы. Проще всего понять как устроены кластерные индексы, если представить их в динамике: как они разрастаются по мере добавления данных, и как начинает ветвиться таблица.
Первый этап: плоский список
Данные в InnoDB хранятся страницами по 16 Кб. Размер одной страницы — это предельный размер узла нашей древовидной структуры, от которого зависит в какой момент начнётся ветвление. Если вся таблица помещается в одну страницу, то она хранится в виде плоского списка, отсортированного по ключевому полю, без отдельной индексной таблицы.
Точно такими же маленькими табличками в будущем будут представлены все наши данные, а соединять их в дерево будут цепочки индексных страниц.
Второй этап: дерево
Когда данные перестают помещаться в одну страницу, список превращается в дерево. Страница с данными разделяется на две, причём в том узле (на той странице), где раньше были данные, теперь располагается индекс, охватывающий обе новые страницы. Конкретный узел такого дерева обязан включать в себя индексы всех дочерних узлов или конечные данные, если узел последний. Узлы могут ссылаться друг на друга только в одном направлении: от родителя к потомку.
По мере добавления всё новых и новых данных, дерево будет усложняться и углубляться. И чем больше оно будет и ветвистее, тем больший выйгрышь даст такая схема хранения данны.
Серые страницы идентичны странице первого этапа — это просто отсортированные данные, листья (конечные узлы) нашего дерева. Голубые страницы — это промежуточные узлы дерева, содержащие только индекс и не содержащие данных. Стрелками помечены пути поиска определённых значений ключа.
Вспомним наш запрос (зелёная стрелка):
SELECT * FROM `t1` WHERE `fld1` = 12;
Обращаясь к таблице, запрос попадает на первую страницу и получает индекс, тут же отправляющий его на конечную страницу с данными, где находятся строки, удовлетворяющие критериям поиска. Страница уже прочитана на этапе поиска, все данные собраны, БД может вернуть ответ.
Однако индекс, указывающий на другую страницу, не обязательно ведёт сразу на страницу с данными. Индекс может указывать на страницу с промежуточным индексом. Возможно, при больших объёмах таблицы, БД придётся провести больше итераций поиска, но каждая такая итерация включает минимальный объём данных, а потому в целом всё равно поиск проходит быстрее.
Здесь действует простое правило, актуальное для любого типа индекса: чем разнообразнее данные, тем эффективнее использовать индекс для поиска конкретных значений.
Поскольку данные являются частью индекса, отсортированы и целенаправленно фрагментированы, очевидно что для одной таблицы может использоваться только один кластерный ключ. Из такой, достаточно сложной логики хранения индексов и данных, есть ещё одно важное следствие: операции записи, а особенно изменение имеющихся данных ключевых полей — крайне ресурсоёмкий процесс. Старайтесь использовать для кластерных индексов редко изменяемые поля.
Что касается сложных (составных) кластерных ключей, для них действует абсолютно такая же схема, только сортировка данных осуществляется по двум полям. Сам же индекс мало отличается от некластерного составного ключа.
Кластерные ключи в InnoDB
Здесь всё просто. Каждая таблица InnoDB имеет кластерный ключ. Каждая. Без исключения.
Гораздо интереснее, какие поля для этого выбираются.
- Если в таблице задан PRIMARY KEY — это он
- Иначе, если в таблице есть UNIQUE (уникальные) индексы — это первый из них
- Иначе InnoDB самостоятельно создаёт скрытое поле с суррогатным ID размером в 6 байт
До третьего пункта лучше не доводить свой многострадальный сервер, и добавить таки ID самостоятельно.
И не забывайте, что InnoDB во вторичных ключах хранит полный набор значений полей кластерного ключа в качестве ссылки на конечную строку в таблице. Чем больше первичный ключ, тем больше вторичные ключи.

