disclaimer Так получилось, что последний месяц я разбираюсь с ZooKeeper, и у меня возникло желание систематизировать то, что я узнал, собственно пост об этом, а не о сервисе блокировок, как можно было подумать исходя из названия. Поехали!
При переходе от многопоточного программирования к программированию распределенных систем многие стандартные техники перестают работать. Одной из таких техник являются блокировки (synchronized), так как область их действия ограничена одним процессом, следовательно, они не только не работают на разных узлах распределенной системы, но так же не между разными экземплярами приложения на одной машине; получается, что нужен отдельный механизм для блокировок.
От распределенного сервиса блокировок разумно требовать:
Создать подобный сервис нам поможет ZooKeeper
 В википедии написано, что ZooKeeper — распределенный сервис конфигурирования и синхронизации, не знаю как вам, но мне данное определение мало что раскрывает. Оглядываясь на свой опыт, могу дать альтернативное определение ZooKeeper, это распределенное key/value хранилище со следующими свойствами:
В википедии написано, что ZooKeeper — распределенный сервис конфигурирования и синхронизации, не знаю как вам, но мне данное определение мало что раскрывает. Оглядываясь на свой опыт, могу дать альтернативное определение ZooKeeper, это распределенное key/value хранилище со следующими свойствами:
Знакомство с незнакомой системой нужно начинать прежде всего с API, которое она предлагает, итак
Эти операции можно разделить по следующим группам
Callback — read-only операции, к которым можно указать коллбеки, коллбек сработает, когда запрашиваемая сущность измениться. Коллбек сработает не более одного раза, в случае, когда нужно постоянно мониторить значение, в обработчике события нужно постоянно переподписываться.
CAS — write запросы. Проблема конкурентного доступа в ZooKeeper'е решена через compare-and-swap: с каждым znode храниться его версия, при изменении её нужно указывать, если znode уже был изменен, то версия не совпадает и клиент получит соответственное исключение. Операции из этой группы требуют указания версии изменяемого объекта.
create — создает новый znode (пару ключ/значение) и возвращает ключ. Кажется странным, что возвращается ключ, если он указывается как аргумент, но дело в том, что ZooKeeper'у в качестве ключа можно указать префикс и сказать, что znode последовательный, тогда к префиксу добавиться выровненное число и результат будет использоваться в качестве ключа. Гарантируется, что создавая последовательные znode с одним и тем же префиксом, ключи будут образовывать возрастающую (в лексико-графическом смысле) последовательность.
Помимо последовательных znode, можно создать эфемерные znode, которые будут удалены, как только клиент их создавший отсоединиться (напоминаю, что соединение между кластером и клиентом в ZooKeeper держится открытым долго). Эфемерные znode не могут иметь детей.
Znode может одновременно быть и эфемерным, и последовательным.
sync — синхронизует узел кластера, к которому подсоединен клиент, с мастером. По хорошему не должен вызываться, так как синхронизация происходит быстро и автоматически. О том, когда её вызывать, будет написано ниже.
На основе последовательных эфемерных znode и подписках на их удаление можнобез проблем создать систему распределенных блокировок.
На самом деле все придумано до нас — идем на сайт ZooKeeper в раздел рецептов и ищем там алгоритм блокировки:
Так как, в случае падения любой операции при работе ZooKeeper мы не можем узнать прошла операция или нет, нам нужно выносить эту проверку на уровень приложения. Guid нужен как раз для этого: зная его и запросив детей, мы можем легко определить создали мы новый узел или нет и операцию стоит повторить.
Кстати я не говорил, но думаю вы уже догадались, что для вычисления суффикса для последовательного znode используется не уникальная последовательность на префикс, а уникальная последовательность на родителя, в котором будет создан znode.
В теории можно было бы и закончить, но как показала практика, начинается самое интересное — wtf'ки. Под wtf'ами я имею ввиду расхождение моих интуитивных представлений о системе с её реальном поведением, внимание, wtf не несет оценочного суждения, кроме того я прекрасно понимаю, почему создатели ZooKeeper'а пошли на такие архитектурные решения.
Любой метод API может кинуть checked exception и обязать вас его обработать. Это не привычно, но правильно, так как первое правило распределенных систем — сеть не надежна. Одно из исключений, которое может полететь — пропажа соединения (моргание сети). Не стоит путать пропажу соединения с узлом кластера (CONNECTIONLOSS), при который клиент сам его восстановит с сохраненной сессией и коллбеками (подключится к другому или будет ждать), и принудительное закрытие соединения со стороны кластера и потерей всех коллбеков (SESSIONEXPIRED), в данном случае задача по восстановлению контекста ложится на плечи программиста. Но мы отошли от темы…
Как обрабатывать подмигивания? На самом деле при открытии соединения с кластером мы указываем коллбек, который вызывается многократно, а не только раз, как остальные, и который доставляет события о потери соединения и его восстановлении. Получается при потери соединения нужно приостановить вычисления и продолжить их, когда придет нужное событие.
Вам это ничего не напоминает? C одной стороны — события, с другой — необходимость «играть» с потоком выполнения программы, по-моему где-то рядом continuation и монады.
В общем, я оформил шаги программы в виде:
где Executor
Добавив нужные комбинаторы можно строить следующие программы, где-то используя идемпотентность шагов, где-то явно подчищая мусор:
Реализовывая Executor, я добавил в него функции обертки над классом ZooKeeper так, что он сам является обработчиком всех событий и сам решает, какой Watcher (обработчик события вызвать). Внутри реализации я поместил три BlockingQueue и три потока, которые их читают, в итоге получилось так, что при приходе события оно добавляется в eventQueue, тем самым поток практически моментально возвращается во внутренности ZooKeeper, кстати, внутри ZooKeeper все Watcher'ы работают в одном потоке, поэтому возможна ситуация, когда обработка одного события блокирует все остальные и сам ZooKeeper. Во вторую очередь taskQueue добавляются Task'и вместе с аргументами. На обработку этих очередей (eventQueue и taskQueue) отведено по потоку, eventThread и taskThread соответственно, эти потоки читают свои очереди и заворачивают каждый поступивший объект в Job'у и кладет в jobQueue, с который связан свой поток, собственно и запускающий код таски или обработчик сообщения. В случае падения соединения поток taskThread приостанавливается, а в случае поднятия сети возобновляется. Выполнение кода тасок и обработчиков в одном потоке позволяет не беспокоиться о блокировках и облегчает бизнес-логику.
Можно сказать, что в ZooKeeper сервер (кластер) является главным, а у клиентов практически нет прав. Иногда это доходит до абсолюта, например… В конфигурации ZooKeeper есть такой параметр как session timeout, он определяет на сколько максимум может пропадать связь между кластером и клиентом, если максимум превышен, то сессия этого клиента будет закрыта и все эфемерные znode этого клиента удаляться; если связь все-таки восстановиться — клиент получит событие SESSIONEXPIRED. Так вот, клиент при пропажи соединения (CONNECTIONLOSS) и превышении session timeout тупо ждет и нечего не делает, хотя, по идеи он мог догадаться о том, что сессия сдохла и сам своим обработчикам кинуть SESSIONEXPIRED.
Из-за такого поведения разработчик в какие-то моменты рвать на себе волосы, допустим вы подняли сервер ZooKeeper и пытаетесь к нему подключиться, но ошиблись в конфиге и стучитесь не по тому адресу, или не по тому порту, тогда, согласно описанному выше поведению, вы просто будете ждать, когда клиент перейдет в состояние CONNECTED и не получите никакого сообщения об ошибке, как это было бы в случае с MySQL или чем-нибудь подобным.
Интересно, что такой сценарий позволяет безболезненно обновлять ZooKeeper на продакшене:
Кстати, именно из-за такого поведения я передаю в Executor Timer, который отменяет выполнение Task'и, если мы слишком долго не можем подключиться.
Допустим вы реализовали блокировки согласно описанному выше алгоритме и запустили это дело в highload продакшен, где, допустим вы берете 10MM блокировок в день. Где-то через год вы обнаружите, что попали в ад — блокировки перестанут работать. Дело в том, что через год у znode _locknode_ счетчик cversion переполниться и нарушиться принцип монотонно возрастающей последовательности имен последовательных znode, а на этом принципе основана наша реализация блокировок.
Что делать? Нужно периодически удалять/создавать заново _locknode_ — при этом счетчик ассоциированный с ним сброситься и принцип монотонной последовательности снова нарушится, но дело в том, что znode можно удалить только когда у него нет детей, а теперь сами догадайтесь, почему сброс cversion у _locknode_, когда в нем нет детей не влияет на алгоритм блокировки.
Когда ZooKeeper вернул ОК на запрос записи это означает что данные записались на кворум (большинство машин в кластере, в случае 3х машин, кворум состоит из 2х), но при чтении пользователь получает данные с той машины, к которой он подключился. То есть возможна ситуация, когда пользователь получает старые данные.
В случае, когда клиенты не общаются иначе как только через ZooKeeper это не составляет проблемы, так как все операции в ZooKeeper строго упорядочены и тогда нет возможности узнать о том, что событие произошло кроме, как дождаться его. Догадайтесь сами, почему из того следует, что все хорошо. На самом деле, клиент может знать, что данные обновились, даже если никто ему не сказал — в случае, когда он сам произвел изменения, но ZooKeeper поддерживает read your writes consistency, так что и это не проблема.
Но все-же, если один клиент узнал об изменении части данных через канал связи все ZooKeeper, ему может помочь принудительная синхронизация — именно для этого нужна команда sync.
Большинство распределенных key/value хранилищ используют распределенность для хранения большого объема данных. Как я уже писал, данные которые хранит в себе ZooKeeper не должны превышать размер оперативной памяти, спрашивается, зачем ему распределенность — она используется для обеспечения надежности. Вспоминая про необходимость набрать кворум на запись, не удивительно падение производительности на 15% при использовании кластера из трех машин, по сравнению с одной машиной.
Другая особенность ZooKeeper состоит в том, что он обеспечивает персистентность — за неё тоже нужно так как во время обработки запроса включено время записи на диск.
И последний удар по производительности происходит из-за строгой упорядоченности запросов — чтобы её обеспечить все запросы на запись идут через одну машину кластера.
Тестировал я на локальном ноуте, да-да это сильно напоминает:
но очевидно, что ZooKeeper лучше всего себя показывает в в конфигурации из одной ноды, с быстрым диском и на небольшом кол-ве данных, поэтому мой X220 c SSD и i7 идеально для этого подходил. Тестировал я преимущественно запросы на запись.
Потолок по производительности был где-то около 10K операций в секунду при интенсивной записи, на запись уходит от 1ms, следовательно, с точки зрения одного клиента, сервер может работать не быстрее 1K операций в секунду.
Что это значит? В условиях, когда мы не упираемся в диск (утилизация ssd на уровне 10%, для верности попробовал так же разместить данные в памяти через ramfs — получил небольшой прирост в производительности), мы упираемся в cpu. Итого, у меня получилось, что ZooKeeper всего в 2 раза медленнее, чем те числа, которые указали на сайте его создатели, что не плохо, если учесть, что они знают, как из него выжать все.
Не смотря на все, что я здесь написал, ZooKeeper не так плох, как может показаться. Мне нравится его лаконичность (всего 7 команд), мне нравиться то, как он подталкивает и направляет своим API программиста к правильному подходу при разработке распределенных систем, а именно, в любой момент все может упасть, потому каждая операция должна оставлять систему в консистентном состоянии. Но это мои впечатления, они не так важны, как то, что ZooKeeeper хорошо решает задачи, для которых он был создан, среди которых: хранение конфигов кластера, мониторинг состояние кластера (кол-во подключенных нод, статус нод), синхронизация нод (блокировки, барьеры) и коммуникация узлов распределенной системы (a-la jabber).
Перечислю еще раз то, что стоит иметь ввиду при разработке с помощью ZooKeeper:
Возвращаясь к алгоритму блокировки, описанному выше, могу сказать, что он не работает, точнее работает ровно до тех пор, пока действия внутри критической секции происходят над тем же и только тем же кластером ZooKeeper, что используется для блокировки. Почему так? — Попробуйте догадаться сами. А в следующей статье я напишу как сделать распределенные блокировки более честными и расширить класс операций внутри критической секции на любое key/value хранилище с поддержкой CAS.
zookeeper.apache.org
outerthought.org/blog/435-ot.html
highscalability.com/zookeeper-reliable-scalable-distributed-coordination-system
research.yahoo.com/node/3280
При переходе от многопоточного программирования к программированию распределенных систем многие стандартные техники перестают работать. Одной из таких техник являются блокировки (synchronized), так как область их действия ограничена одним процессом, следовательно, они не только не работают на разных узлах распределенной системы, но так же не между разными экземплярами приложения на одной машине; получается, что нужен отдельный механизм для блокировок.
От распределенного сервиса блокировок разумно требовать:
- работоспособность в условиях моргания сети (первое правило распределенных систем —
никому не говорить о распределенных системахсеть ненадежна) - отсутствие единой точки отказа
Создать подобный сервис нам поможет ZooKeeper
В википедии написано, что ZooKeeper — распределенный сервис конфигурирования и синхронизации, не знаю как вам, но мне данное определение мало что раскрывает. Оглядываясь на свой опыт, могу дать альтернативное определение ZooKeeper, это распределенное key/value хранилище со следующими свойствами:- пространство ключей образует дерево (иерархию подобную файловой системе)
- значения могут содержаться в любом узле иерархии, а не только в листьях (как если бы файлы одновременно были бы и каталогами), узел иерархии называется znode
- между клиентом и сервером двунаправленная связь, следовательно, клиент может подписываться как изменение конкретного значения или части иерархии
- возможно создать временную пару ключ/значение, которая существует, пока клиент её создавший подключен к кластеру
- все данные должны помещаться в память
- устойчивость к смерти некритического кол-ва узлов кластера
Знакомство с незнакомой системой нужно начинать прежде всего с API, которое она предлагает, итак
Поддерживаемые операции
| exists | проверяет существование znode и возвращает его метаданные |
| create | создает znode |
| delete | удаляет znode |
| getData | получает данные ассоциированные с znode |
| setData | ассоциирует новые данные с znode |
| getChildren | получает детей указанного znode |
| sync | дожидается синхронизации узла кластера, к которому мы подсоединены, и мастера. |
Эти операции можно разделить по следующим группам
| callback | CAS | |
| exists | delete | |
| getData | setData | |
| getChildren | create | |
| sync |
Callback — read-only операции, к которым можно указать коллбеки, коллбек сработает, когда запрашиваемая сущность измениться. Коллбек сработает не более одного раза, в случае, когда нужно постоянно мониторить значение, в обработчике события нужно постоянно переподписываться.
CAS — write запросы. Проблема конкурентного доступа в ZooKeeper'е решена через compare-and-swap: с каждым znode храниться его версия, при изменении её нужно указывать, если znode уже был изменен, то версия не совпадает и клиент получит соответственное исключение. Операции из этой группы требуют указания версии изменяемого объекта.
create — создает новый znode (пару ключ/значение) и возвращает ключ. Кажется странным, что возвращается ключ, если он указывается как аргумент, но дело в том, что ZooKeeper'у в качестве ключа можно указать префикс и сказать, что znode последовательный, тогда к префиксу добавиться выровненное число и результат будет использоваться в качестве ключа. Гарантируется, что создавая последовательные znode с одним и тем же префиксом, ключи будут образовывать возрастающую (в лексико-графическом смысле) последовательность.
Помимо последовательных znode, можно создать эфемерные znode, которые будут удалены, как только клиент их создавший отсоединиться (напоминаю, что соединение между кластером и клиентом в ZooKeeper держится открытым долго). Эфемерные znode не могут иметь детей.
Znode может одновременно быть и эфемерным, и последовательным.
sync — синхронизует узел кластера, к которому подсоединен клиент, с мастером. По хорошему не должен вызываться, так как синхронизация происходит быстро и автоматически. О том, когда её вызывать, будет написано ниже.
На основе последовательных эфемерных znode и подписках на их удаление можно
Система распределенных блокировок
На самом деле все придумано до нас — идем на сайт ZooKeeper в раздел рецептов и ищем там алгоритм блокировки:
- Создаем эфемерный последовательный znode используя в качестве префикса "_locknode_/guid-lock-", где _locknode_ — имя ресурса, который блокируем, а guid — свежесгенерированный гуид
- Получаем список детей _locknode_ без подписки на событие
- Если созданный на первом шаге znode в ключе имеет минимальный числовой суффикс: выходим из алгоритма — мы захватили ресурс
- Иначе сортируем список детей по суффиксу и вызываем exists с коллбеком на znode, который в полученном списке находиться перед тем, что создан нами на шаге 1
- Если получили false переходим на шаг 2, иначе ждем события и переходим на шаг 2
Для проверки усвоения материала попробуйте понять самостоятельно, по убыванию или по возрастанию нужно сортировать список в шаге 4.
Так как, в случае падения любой операции при работе ZooKeeper мы не можем узнать прошла операция или нет, нам нужно выносить эту проверку на уровень приложения. Guid нужен как раз для этого: зная его и запросив детей, мы можем легко определить создали мы новый узел или нет и операцию стоит повторить.
Кстати я не говорил, но думаю вы уже догадались, что для вычисления суффикса для последовательного znode используется не уникальная последовательность на префикс, а уникальная последовательность на родителя, в котором будет создан znode.
WTF
В теории можно было бы и закончить, но как показала практика, начинается самое интересное — wtf'ки. Под wtf'ами я имею ввиду расхождение моих интуитивных представлений о системе с её реальном поведением, внимание, wtf не несет оценочного суждения, кроме того я прекрасно понимаю, почему создатели ZooKeeper'а пошли на такие архитектурные решения.
WTF #1 — выворачиваем код на изнанку
Любой метод API может кинуть checked exception и обязать вас его обработать. Это не привычно, но правильно, так как первое правило распределенных систем — сеть не надежна. Одно из исключений, которое может полететь — пропажа соединения (моргание сети). Не стоит путать пропажу соединения с узлом кластера (CONNECTIONLOSS), при который клиент сам его восстановит с сохраненной сессией и коллбеками (подключится к другому или будет ждать), и принудительное закрытие соединения со стороны кластера и потерей всех коллбеков (SESSIONEXPIRED), в данном случае задача по восстановлению контекста ложится на плечи программиста. Но мы отошли от темы…
Как обрабатывать подмигивания? На самом деле при открытии соединения с кластером мы указываем коллбек, который вызывается многократно, а не только раз, как остальные, и который доставляет события о потери соединения и его восстановлении. Получается при потери соединения нужно приостановить вычисления и продолжить их, когда придет нужное событие.
Вам это ничего не напоминает? C одной стороны — события, с другой — необходимость «играть» с потоком выполнения программы, по-моему где-то рядом continuation и монады.
В общем, я оформил шаги программы в виде:
public interface Task { Task continueWith(Task continuation); // объединяем шаги в цепочку void run(Executor context, Object arg); // нормальное выполнение void error(Executor context, Exception error); // вместо того, чтобы кидать исключение - передаем его }
где Executor
public interface Executor { void execute(Task task, Object arg, Timer timeout); // timeout ограничивает время выполнения таски передавая/кидая TimeoutException в error таски, создавая мягкий real-time }
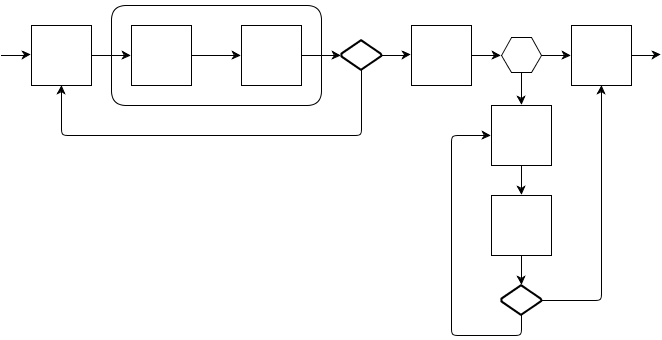
Добавив нужные комбинаторы можно строить следующие программы, где-то используя идемпотентность шагов, где-то явно подчищая мусор:
- квадрат — полезная операция, а стрелка — поток выполнения и/или поток ошибок
- ромб — комбинатор, которые игнорирует указанные ошибки и повторяет последнюю полезную операцию
- сота — комбинатор, которые выполняет операцию A в случае нормального потока выполнения, и операцию B в случае указанной ошибки
- скругленный параллелепипед — комбинатор который успешный поток выполнения пускает в себя, а ошибочный сразу прокидывает дальше
Реализовывая Executor, я добавил в него функции обертки над классом ZooKeeper так, что он сам является обработчиком всех событий и сам решает, какой Watcher (обработчик события вызвать). Внутри реализации я поместил три BlockingQueue и три потока, которые их читают, в итоге получилось так, что при приходе события оно добавляется в eventQueue, тем самым поток практически моментально возвращается во внутренности ZooKeeper, кстати, внутри ZooKeeper все Watcher'ы работают в одном потоке, поэтому возможна ситуация, когда обработка одного события блокирует все остальные и сам ZooKeeper. Во вторую очередь taskQueue добавляются Task'и вместе с аргументами. На обработку этих очередей (eventQueue и taskQueue) отведено по потоку, eventThread и taskThread соответственно, эти потоки читают свои очереди и заворачивают каждый поступивший объект в Job'у и кладет в jobQueue, с который связан свой поток, собственно и запускающий код таски или обработчик сообщения. В случае падения соединения поток taskThread приостанавливается, а в случае поднятия сети возобновляется. Выполнение кода тасок и обработчиков в одном потоке позволяет не беспокоиться о блокировках и облегчает бизнес-логику.
WTF #2 — сервер главный
Можно сказать, что в ZooKeeper сервер (кластер) является главным, а у клиентов практически нет прав. Иногда это доходит до абсолюта, например… В конфигурации ZooKeeper есть такой параметр как session timeout, он определяет на сколько максимум может пропадать связь между кластером и клиентом, если максимум превышен, то сессия этого клиента будет закрыта и все эфемерные znode этого клиента удаляться; если связь все-таки восстановиться — клиент получит событие SESSIONEXPIRED. Так вот, клиент при пропажи соединения (CONNECTIONLOSS) и превышении session timeout тупо ждет и нечего не делает, хотя, по идеи он мог догадаться о том, что сессия сдохла и сам своим обработчикам кинуть SESSIONEXPIRED.
Из-за такого поведения разработчик в какие-то моменты рвать на себе волосы, допустим вы подняли сервер ZooKeeper и пытаетесь к нему подключиться, но ошиблись в конфиге и стучитесь не по тому адресу, или не по тому порту, тогда, согласно описанному выше поведению, вы просто будете ждать, когда клиент перейдет в состояние CONNECTED и не получите никакого сообщения об ошибке, как это было бы в случае с MySQL или чем-нибудь подобным.
Интересно, что такой сценарий позволяет безболезненно обновлять ZooKeeper на продакшене:
- выключаем ZooKeeper — все клиенты переходят в состояние CONNECTIONLOSS
- обновляем ZooKeeper
- включаем ZooKeeper, связь с сервером восстановилась, но сервер не посылает SESSIONEXPIRED, так как относительно сервера время на время отключения было остановлено
Кстати, именно из-за такого поведения я передаю в Executor Timer, который отменяет выполнение Task'и, если мы слишком долго не можем подключиться.
WTF #3 — переполняется int
Допустим вы реализовали блокировки согласно описанному выше алгоритме и запустили это дело в highload продакшен, где, допустим вы берете 10MM блокировок в день. Где-то через год вы обнаружите, что попали в ад — блокировки перестанут работать. Дело в том, что через год у znode _locknode_ счетчик cversion переполниться и нарушиться принцип монотонно возрастающей последовательности имен последовательных znode, а на этом принципе основана наша реализация блокировок.
Что делать? Нужно периодически удалять/создавать заново _locknode_ — при этом счетчик ассоциированный с ним сброситься и принцип монотонной последовательности снова нарушится, но дело в том, что znode можно удалить только когда у него нет детей, а теперь сами догадайтесь, почему сброс cversion у _locknode_, когда в нем нет детей не влияет на алгоритм блокировки.
WTF #4 — quorum write, но не read
Когда ZooKeeper вернул ОК на запрос записи это означает что данные записались на кворум (большинство машин в кластере, в случае 3х машин, кворум состоит из 2х), но при чтении пользователь получает данные с той машины, к которой он подключился. То есть возможна ситуация, когда пользователь получает старые данные.
В случае, когда клиенты не общаются иначе как только через ZooKeeper это не составляет проблемы, так как все операции в ZooKeeper строго упорядочены и тогда нет возможности узнать о том, что событие произошло кроме, как дождаться его. Догадайтесь сами, почему из того следует, что все хорошо. На самом деле, клиент может знать, что данные обновились, даже если никто ему не сказал — в случае, когда он сам произвел изменения, но ZooKeeper поддерживает read your writes consistency, так что и это не проблема.
Но все-же, если один клиент узнал об изменении части данных через канал связи все ZooKeeper, ему может помочь принудительная синхронизация — именно для этого нужна команда sync.
Производительность
Большинство распределенных key/value хранилищ используют распределенность для хранения большого объема данных. Как я уже писал, данные которые хранит в себе ZooKeeper не должны превышать размер оперативной памяти, спрашивается, зачем ему распределенность — она используется для обеспечения надежности. Вспоминая про необходимость набрать кворум на запись, не удивительно падение производительности на 15% при использовании кластера из трех машин, по сравнению с одной машиной.
Другая особенность ZooKeeper состоит в том, что он обеспечивает персистентность — за неё тоже нужно так как во время обработки запроса включено время записи на диск.
И последний удар по производительности происходит из-за строгой упорядоченности запросов — чтобы её обеспечить все запросы на запись идут через одну машину кластера.
Тестировал я на локальном ноуте, да-да это сильно напоминает:
 DevOps Borat |
Big Data Analytic is show 90% of devops which are use word 'benchmark' in sentence are also use word 'laptop' in same sentence. |
Потолок по производительности был где-то около 10K операций в секунду при интенсивной записи, на запись уходит от 1ms, следовательно, с точки зрения одного клиента, сервер может работать не быстрее 1K операций в секунду.
Что это значит? В условиях, когда мы не упираемся в диск (утилизация ssd на уровне 10%, для верности попробовал так же разместить данные в памяти через ramfs — получил небольшой прирост в производительности), мы упираемся в cpu. Итого, у меня получилось, что ZooKeeper всего в 2 раза медленнее, чем те числа, которые указали на сайте его создатели, что не плохо, если учесть, что они знают, как из него выжать все.
Резюме
Не смотря на все, что я здесь написал, ZooKeeper не так плох, как может показаться. Мне нравится его лаконичность (всего 7 команд), мне нравиться то, как он подталкивает и направляет своим API программиста к правильному подходу при разработке распределенных систем, а именно, в любой момент все может упасть, потому каждая операция должна оставлять систему в консистентном состоянии. Но это мои впечатления, они не так важны, как то, что ZooKeeeper хорошо решает задачи, для которых он был создан, среди которых: хранение конфигов кластера, мониторинг состояние кластера (кол-во подключенных нод, статус нод), синхронизация нод (блокировки, барьеры) и коммуникация узлов распределенной системы (a-la jabber).
Перечислю еще раз то, что стоит иметь ввиду при разработке с помощью ZooKeeper:
- сервер главный
- клиент получает уведомление о записи, только когда данные попали на диск
- quorum write + read your writes consistency
- строгая упорядоченность
- в любой момент времени все может упасть, поэтому после каждого изменения система должна находиться в консистентном состоянии
- в случае пропажи связи мы находимся в состоянии, в котором состояние последней операции записи неизвестно
- явная обработка ошибок (по мне лучшая стратегия — использовать CPS)
О распределенных блокировках
Возвращаясь к алгоритму блокировки, описанному выше, могу сказать, что он не работает, точнее работает ровно до тех пор, пока действия внутри критической секции происходят над тем же и только тем же кластером ZooKeeper, что используется для блокировки. Почему так? — Попробуйте догадаться сами. А в следующей статье я напишу как сделать распределенные блокировки более честными и расширить класс операций внутри критической секции на любое key/value хранилище с поддержкой CAS.
Несколько ссылок на информацию по ZooKeeper
zookeeper.apache.org
outerthought.org/blog/435-ot.html
highscalability.com/zookeeper-reliable-scalable-distributed-coordination-system
research.yahoo.com/node/3280

